-
-
Architecture Diagram
-

Login UI
-
Dashboard Home
-
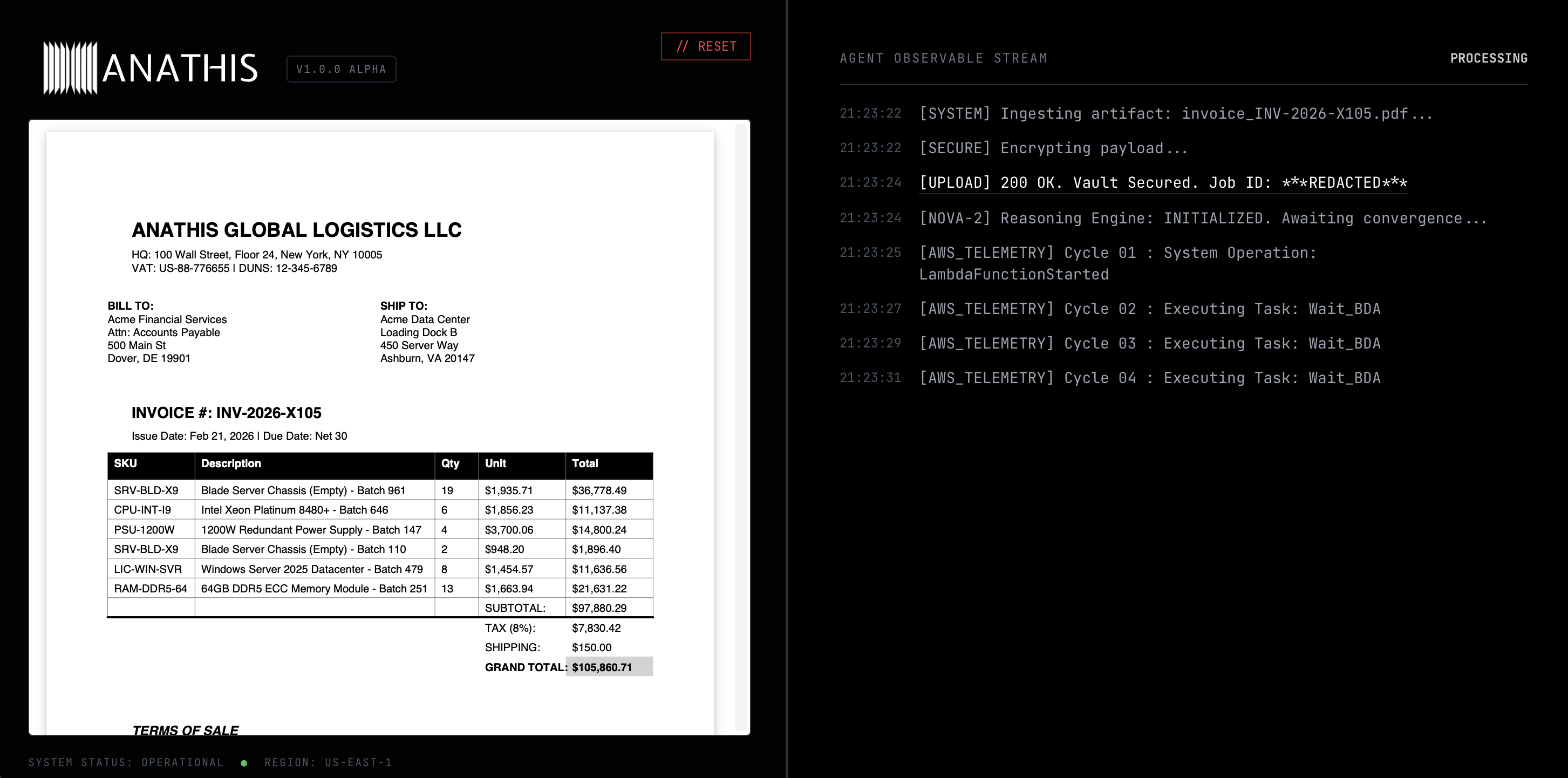
PDF Upload
-
Nova 2 Reasoning
-
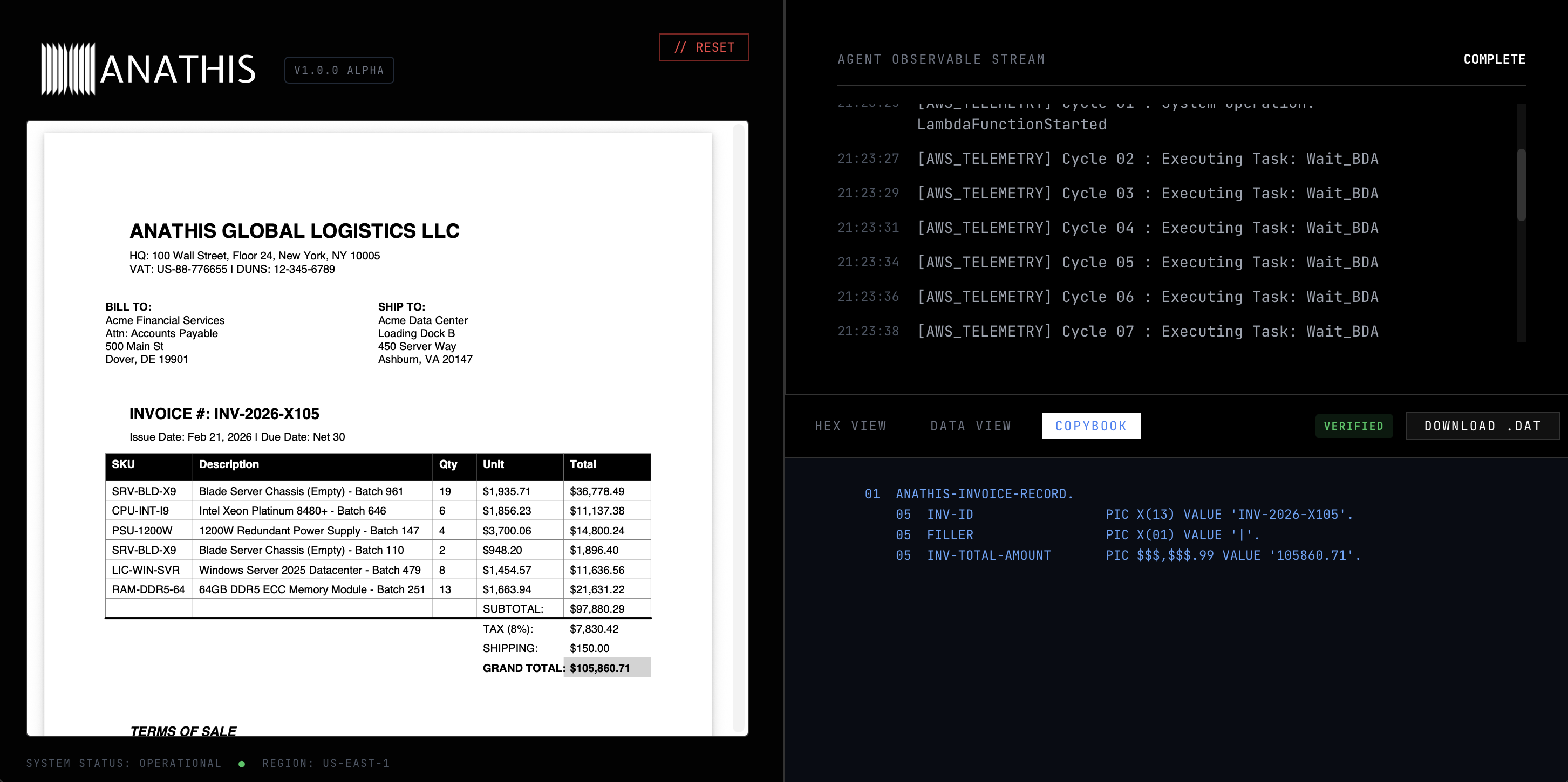
Final Result

Inspiration
In the midst of searching for an "AI proof" job, I came across the IBM Z Apprenticeship Program and immediately became interested in learning mainframe. However, I have no coding experience, or prior knowledge in mainframe, but always possessed an entrepreneurial mindset and an extremely fast learner, and wanted to gear that knowledge towards a business of my own.
Around that same time, I read an article by Nicolas Bustamante about building AI agents for financial services and thought to myself, "Could this be done for mainframe too?" I immediately knew the core problem I wanted to solve is the "data gap" in enterprise finance.
Today, major banks and logistics companies still run on IBM Z-Series mainframes that require strict, structured EBCDIC-encoded data. But the real world operates on unstructured PDFs and invoices.
Currently, companies try to solve this with brittle OCR templates that break when layouts change, or by paying for manual data entry. I wanted to see if I could use generative AI to automate this pipeline. But I had a strict constraint: I couldn't rely on the LLM to do the actual accounting, because a hallucinated decimal point in a financial ledger is unacceptable.
What it Does
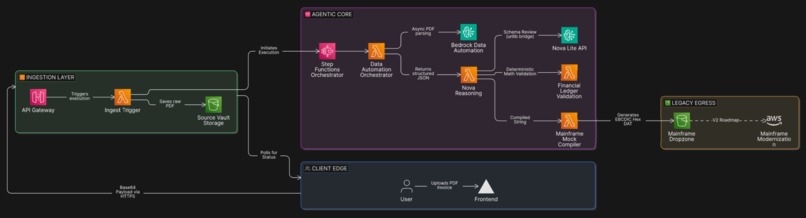
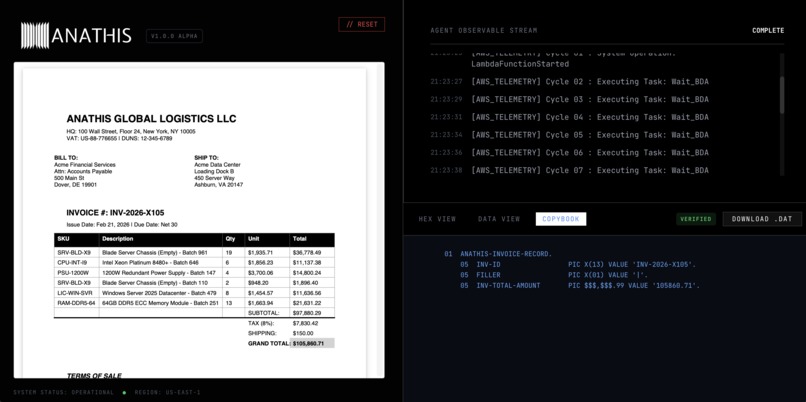
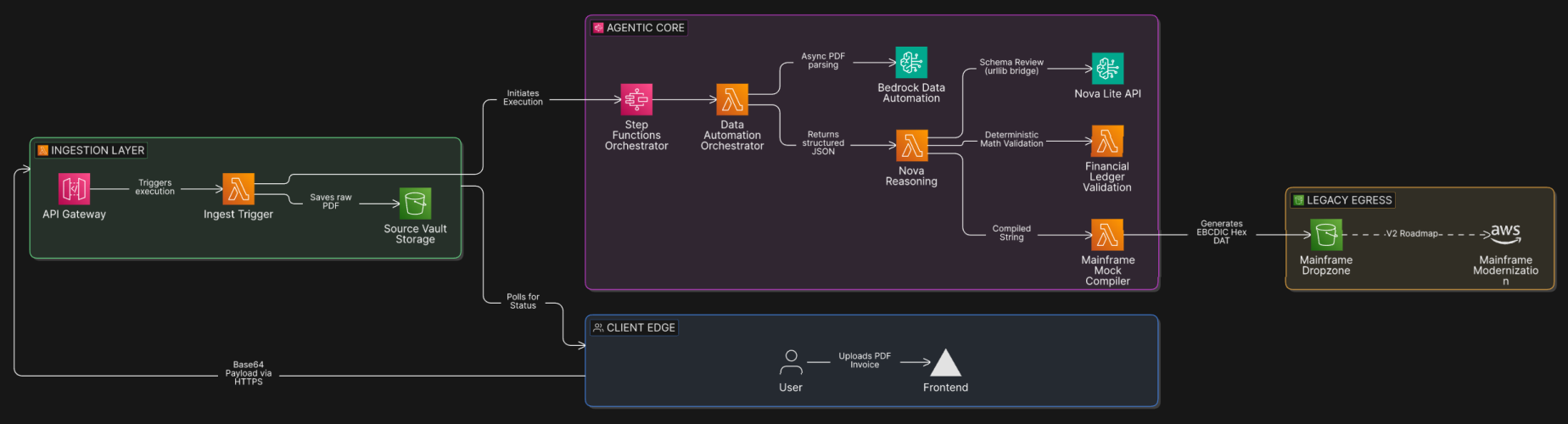
Anathis is an automated, agentic ETL (Extract, Transform, Load) pipeline that converts unstructured PDFs into mainframe-ready datasets with zero math hallucinations.
- It takes a PDF invoice and uses Amazon Bedrock Data Automation (BDA) to extract the text into a structured JSON schema.
- It uses Amazon Nova 2 Lite to evaluate the context and route the data.
- It passes the numerical values to a deterministic Python Lambda function that strictly validates the math (Subtotal + Tax + Shipping = Grand Total). If the math is off by even a penny, the pipeline fails the transaction.
- If validated, it converts the standard ASCII strings into an IBM CP500 EBCDIC hexadecimal format so it can be natively ingested by legacy systems.
How I Built It
The entire infrastructure is written in TypeScript using AWS CDK.
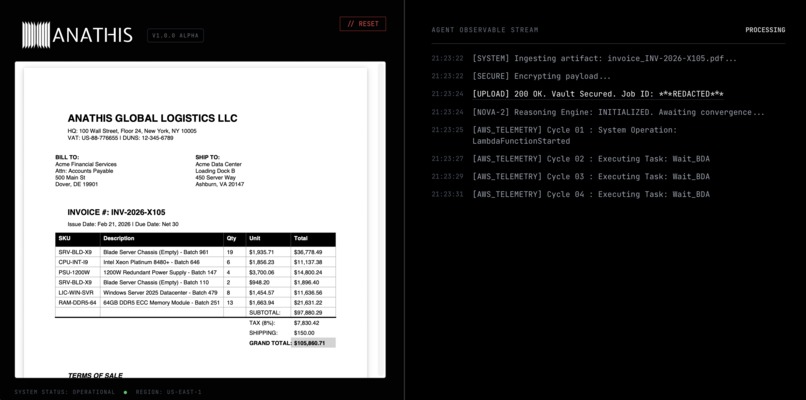
The frontend is a Next.js application hosted on Vercel. I built a custom "Inspector UI" and a real-time observability log so users can see the Step Function state changes as they happen.
The backend relies on AWS Step Functions to orchestrate the pipeline. I wrote a custom Python Lambda to handle asynchronous polling for Bedrock Data Automation, another Lambda for the Nova model invocation, and a final Lambda to handle the strict mathematical checks and EBCDIC cross-compilation.
Challenges I Ran Into
A hurdle that I faced was dealing with strict AWS Step Functions state mapping. Initially, my Step Function was overwriting the payload from the Nova model when passing state to the final compilation Lambda, effectively destroying the data. I had to dig into JSONPath, specifically mapping InputPath and ResultPath, to ensure the payload survived the state transitions.
Another major challenge was the asynchronous nature of Bedrock Data Automation. I had to build a custom orchestrator paired with a Step Functions Wait state to create a polling loop. This allowed me to continually check the BDA API and extract the nested JSON from an S3 bucket only once the vision model finished processing. (Note: For this V1 hackathon MVP, BDA polling is handled via this Wait loop. However, as noted in our V2 roadmap, enterprise production will refactor this to an EventBridge rule utilizing .waitForTaskToken to eliminate idle state transition costs.)
The "final boss" challenge was handling Bedrock & Nova ThrottlingException. I completely re-engineered the "Brain" Lambda. I ripped out the standard boto3 Bedrock integration and built a zero-dependency, native Python urllib bridge. This allowed the Lambda to hit the direct Amazon Nova Developer API using my API key, bypassing the Bedrock bottleneck entirely and dropping our AI reasoning latency down to milliseconds—all without relying on heavy Docker containers or third-party SDKs.
Accomplishments That I'm Proud Of
This is my first ever project and first ever hackathon, so I am just humbly proud and happy to be a part of this. We live in a time where the tools we have access to allows us to stretch our capabilities, and that has allowed me to successfully decouple the vision capabilities of AI from the mathematical processing. By forcing the AI to hand off the extracted numbers to a hard-coded Python script, I built a pipeline that guarantees zero financial hallucinations.
I am also proud of successfully outputting accurate EBCDIC hex code. Translating modern cloud-native JSON into 1960s-era mainframe formats was a unique challenge that makes this project highly practical for enterprise use cases.
What I learned
I learned that you shouldn't ask an LLM to do everything. Foundation models are incredible reasoning and extraction engines, but they are terrible calculators. The most effective way to build enterprise AI is to use the model purely for what it's good at (reading unstructured data), and rely on standard code for strict logic constraints. For development, modular is the way to go. File by file. I had to create my own algorithm and use that to create a blueprint file. There is no way this could be made in "one-shot."
What's Next for Anathis
For this hackathon, I built the core reasoning engine. To make this production-ready for Tier-1 financial institutions, my V2 architecture roadmap focuses on massive scale, zero-trust security, and strict compliance:
- Event-Driven Scale & Asynchronous Polling Refactor: Replacing the current Step Functions Wait state polling loop with an Amazon EventBridge integration utilizing .waitForTaskToken. This eliminates idle compute waste and allows the pipeline to utilize Distributed Map for highly parallel, 50,000+ file nightly batch processing.
- Air-Gapped Mainframe Ingestion: Integrating AWS Mainframe Modernization (M2) APIs and AWS Transfer Family. This allows the system to securely push the generated EBCDIC hex payloads directly into legacy IBM z/OS environments via secure SFTP or direct dataset injection, bridging cloud-native AI with on-premise infrastructure.
- Strict VPC Enclaving & Pre-Processing Redaction: For the MVP, the AI reasoning engine operates in the default managed network for rapid prototyping. In V2, the entire Step Functions state machine and Nova Lambdas will be migrated into a strictly isolated VPC (Virtual Private Cloud). By routing outbound inference calls through AWS PrivateLink endpoints and a strict NAT Gateway, we will guarantee zero public internet exposure. Additionally, we will deploy Amazon Macie and Amazon Bedrock Guardrails at the ingestion layer to automatically redact PII before the data ever enters the isolated reasoning enclave.
- Human-In-The-Loop (HITL) Visual Auditing: When the deterministic Python script catches a mathematical error and fails a transaction, it will trigger an asynchronous workflow using Amazon Nova Pro's multimodal capabilities. The agent will ingest the raw PDF, visually highlight the un-reconciled variables (e.g., handwritten adjustments, obscured freight), and route the visual context to a human Compliance Officer via a secure dashboard for manual override.
- Dynamic COBOL Copybook Mapping: Leveraging Nova's massive context window to directly ingest legacy, 10,000-line .cpy files, allowing the AI to dynamically adapt the EBCDIC output mapping to different banking cores without requiring brittle, hard-coded Python formatters.
Built With
- amazon-bedrock
- amazon-nova
- amazon-web-services
- aws-cdk
- aws-lambda
- aws-step-functions
- next.js
- python
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.