-
architecture diagram
-
pipeline flowchart
-
mind map
Inspiration
India’s ancient civilizations were often described as technologically and intellectually advanced — a land where astronomy, mathematics, medicine, and philosophy flourished. The great universities of Nalanda and Takshashila attracted scholars from China, Persia, and Greece, who marveled at the vast repositories of manuscripts and knowledge systems that existed in India.
Many of these texts were tragically lost when libraries were destroyed or manuscripts deteriorated over centuries. Chinese pilgrims like Xuanzang wrote about Nalanda’s treasure troves of palm-leaf manuscripts, but much of this knowledge has vanished. What survives today are fragile, incomplete manuscripts, often damaged by time and climate.
This led us to ask: What if the surviving archives could be restored, preserved, and made accessible to the world with the help of AI?
What it does
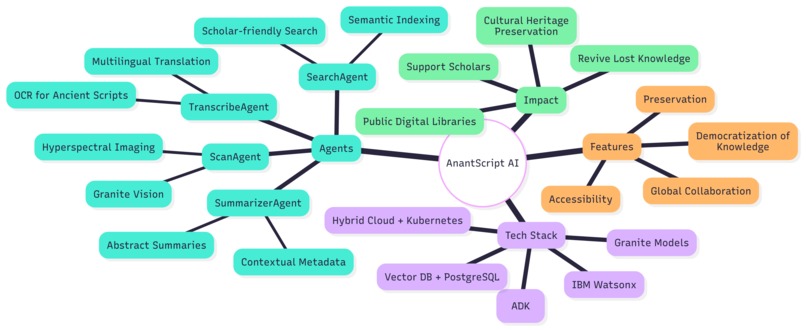
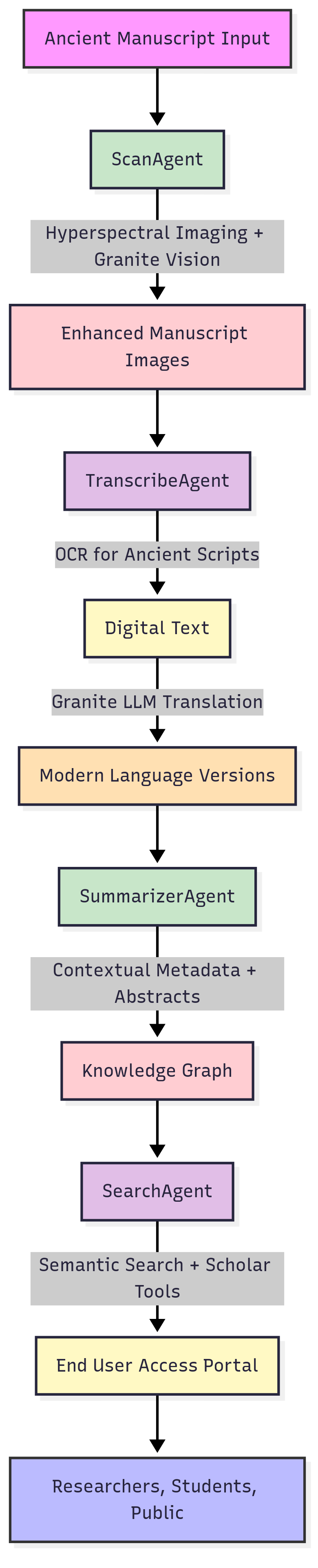
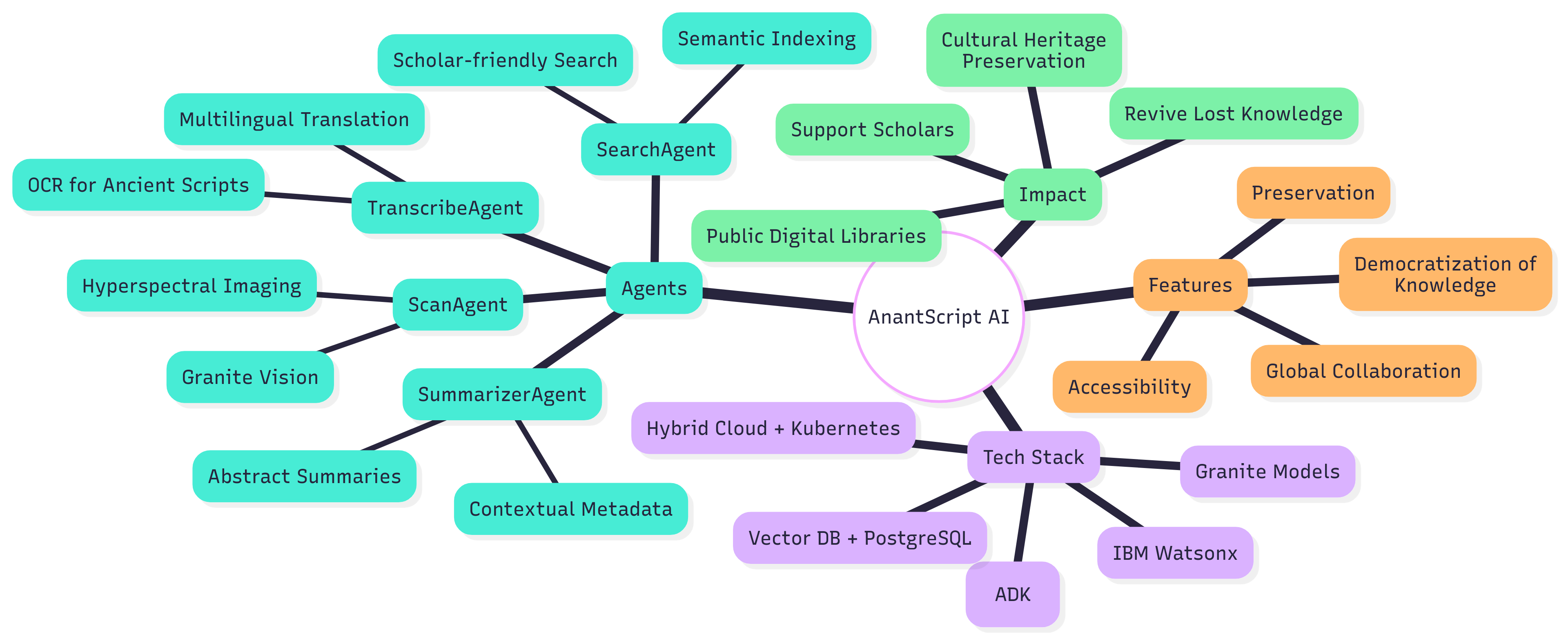
AnantScript AI is an end-to-end Generative AI and Agentic workflow system that restores, transcribes, translates, and democratizes access to ancient Indian manuscripts.
Here’s what the system does step by step:
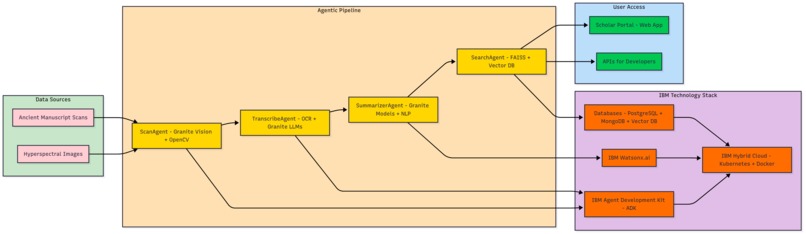
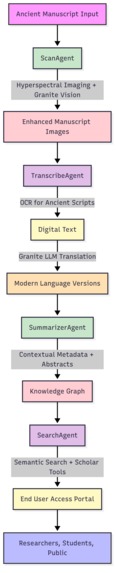
Restoration with ScanAgent
- Uses hyperspectral imaging and Granite Vision models to enhance faded or damaged text.
- Removes noise, reconstructs missing portions, and improves legibility of fragile manuscripts.
- Uses hyperspectral imaging and Granite Vision models to enhance faded or damaged text.
Transcription with TranscribeAgent
- Applies Indic OCR for low-resource scripts like Sanskrit, Pali, Bengali, and Persian.
- Converts ancient scripts into Unicode digital text.
- Automatically translates manuscripts into modern Indian and global languages.
- Applies Indic OCR for low-resource scripts like Sanskrit, Pali, Bengali, and Persian.
Summarization with SummarizerAgent
- Produces summaries, abstracts, and keywords to make manuscripts easier to understand.
- Adds contextual metadata (time period, author, theme) for scholarly research.
- Produces summaries, abstracts, and keywords to make manuscripts easier to understand.
Search & Discovery with SearchAgent
- Builds a semantic search engine powered by FAISS embeddings.
- Enables natural language queries
- Builds a semantic search engine powered by FAISS embeddings.
How we built it
We started by asking ourselves a simple question: How can we make fragile manuscripts readable and useful again?
Our approach was to break the problem into stages and assign an “agent” to each task. Using IBM’s Agent Development Kit (ADK) and Granite models, we stitched together a working pipeline:
- ScanAgent cleaned and enhanced manuscript scans so faded letters became legible.
- TranscribeAgent converted those letters into digital text using OCR, then translated them into English and Indian languages.
- SummarizerAgent added abstracts and metadata so readers could quickly understand what each manuscript contained.
- SearchAgent indexed the texts using semantic embeddings, allowing natural language queries.
Once the pipeline worked on small samples, we deployed it on IBM Hybrid Cloud infrastructure so it could scale to larger archives.
Challenges we ran into
- Ancient scripts are messy → Manuscripts often had missing letters, stains, or irregular handwriting. OCR models struggled.
- Lack of data → Training data for scripts like Modi or Grantha was almost nonexistent. We had to get creative with synthetic augmentation.
- Translations are tricky → Words in Sanskrit or Pali don’t always map neatly to modern languages, leading to context loss.
- Compute bottlenecks → Hyperspectral image processing needed high-performance hardware that slowed down our early tests.
- Earning trust → We realized that scholars won’t just “accept AI output.” They want to see provenance and where AI may have guessed.
Accomplishments that we're proud of
- We managed to build an end-to-end working prototype — from a damaged manuscript scan to a translated, searchable digital entry.
- We improved OCR accuracy by creating synthetic training data and cleaning noisy scans.
- Our semantic search lets users ask natural questions like “Show me texts about ancient astronomy” and actually find relevant manuscripts.
- We designed provenance markers so scholars can see which text was restored by AI and which was confidently transcribed.
- Most importantly, we proved that GenAI can preserve cultural heritage in a trustworthy way.
What we learned
- Technology alone isn’t enough — AI needs human experts in the loop to validate results.
- Synthetic data is a powerful tool for overcoming the lack of annotated manuscripts.
- Preservation is only half the story; making knowledge accessible and searchable is what creates real impact.
- Trust comes from transparency — showing users what the AI restored, translated, or inferred.
What's next for AnantScript AI
Our prototype showed that it’s possible to restore, transcribe, and search manuscripts in an automated way. The next step is to scale and refine the system so it can support real-world archives at national and international levels.
Here’s where we see AnantScript AI going next:
- Expand to more scripts and languages → Extend OCR and translation to cover rare scripts like Sharada, Brahmi, and regional dialects.
- Collaborate with libraries and research centers → Partner with institutions like The Asiatic Society, IITs, and national archives to process large-scale collections.
- Improve explainability → Add features where users can click on a passage and see the original scan, the AI’s confidence, and translation notes.
- Multimodal integration → Incorporate audio readings and cross-linking with archaeological records, maps, and historical commentaries.
- Open access platform → Build a public-facing digital library where students, researchers, and the general public can explore manuscripts easily.
- Community-driven validation → Enable scholars worldwide to validate, annotate, and contribute corrections, creating a collaborative preservation ecosystem.
Our vision is that AnantScript AI will become the foundation of a living digital library, where ancient manuscripts are not just preserved but actively studied, searched, and shared — transforming fragile archives into accessible, enduring knowledge for generations to come.
Built With
- adk
- api
- cloud
- docker
- faiss
- gemini
- github
- granite-vision
- ibm
- ibm-watson
- indic-ocr
- jupyter
- openai
- opencv
- postgresql
- python
- pytorch
- transformers

Log in or sign up for Devpost to join the conversation.