-
-
Anamnesis UI
-
Pipeline Flowchart
Anamnesis
Notes in. FHIR out. Provenance on every fact.
Inspiration
Every clinician knows the feeling: the answer is in the chart, but it's locked inside three different notes from three different specialists — and the most relevant note is often a faxed referral or an outside-clinic PDF that hasn't been indexed at all. The data isn't missing — it's unstructured. We built Anamnesis to close that gap without replacing the EHR: read what's already there (and what the agent can hand us from anywhere else), propose structured additions, let the clinician approve in seconds.
The hackathon framing — MCP + A2A + FHIR — turned out to fit the problem precisely. The reason chart augmentation hasn't shipped at scale is not the model; it's the plumbing: SHARP context propagation, FHIR write semantics, provenance, human-in-the-loop hand-off. Prompt Opinion solved the plumbing. We focused on the augmentation.
The name comes from the medical term for a patient history reconstructed from documentation. Which is what the MCP does.
What it does
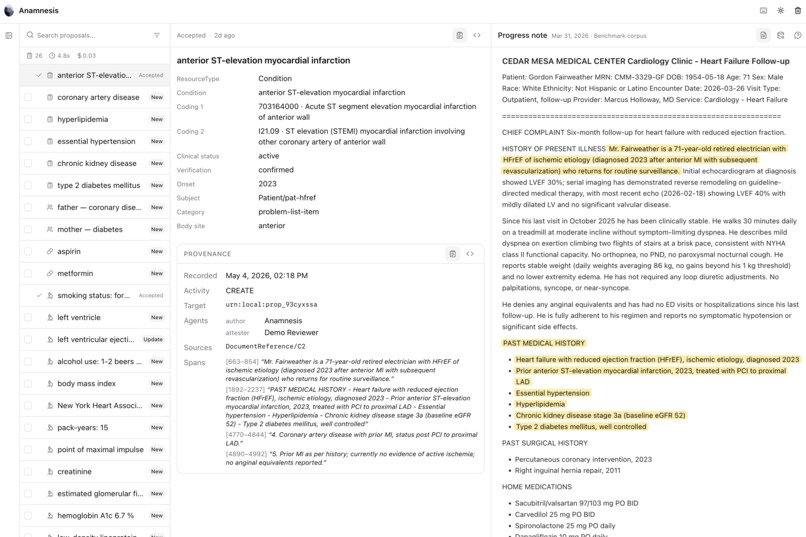
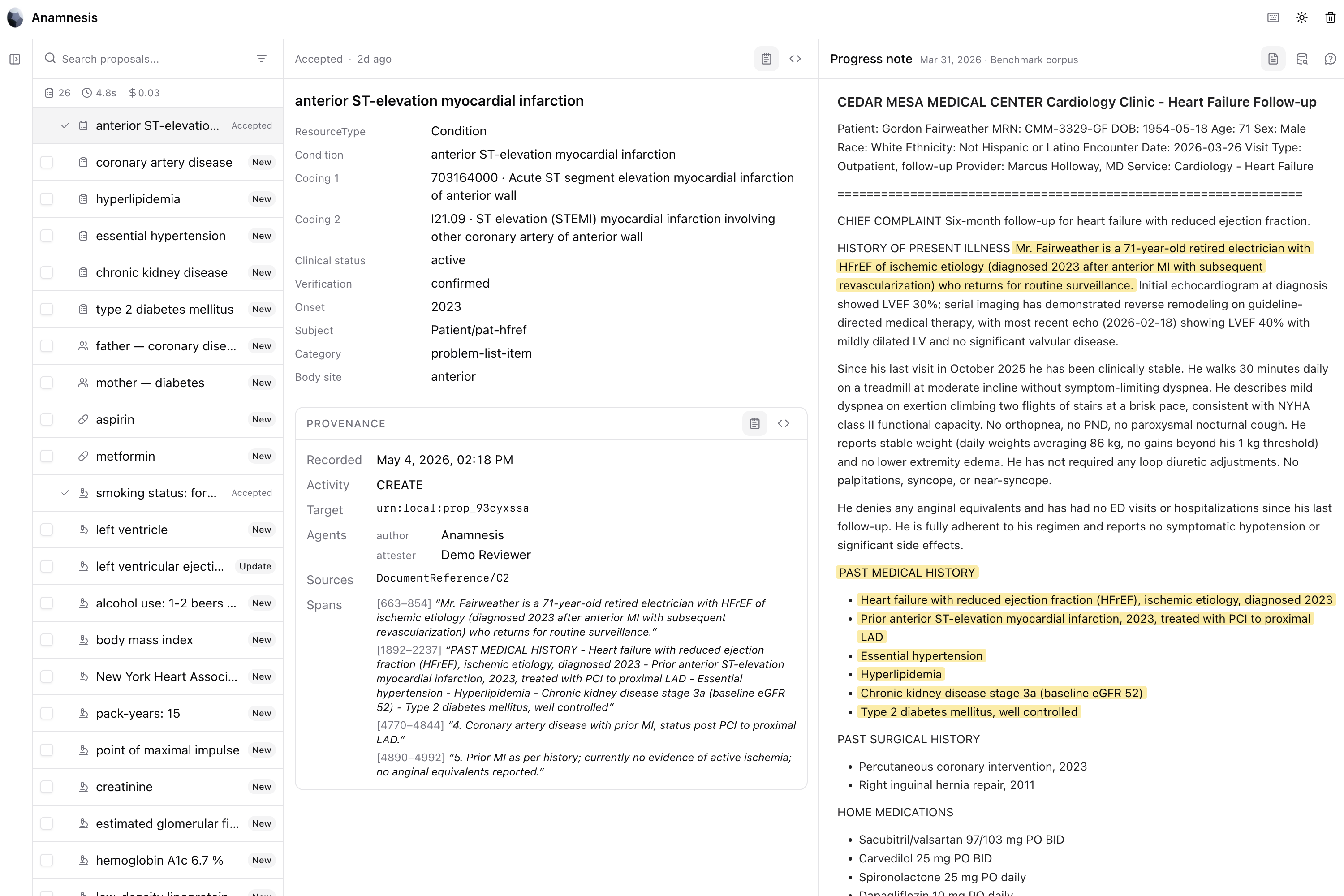
Anamnesis is a FHIR augmentation MCP server. It reads clinical notes against an existing FHIR record, proposes structured additions and corrections with full source provenance, and writes them back to the FHIR server only after a clinician approves them.
We chose Option 1 (Build a Superpower): the MCP is the product. Any agent in the Prompt Opinion ecosystem can pick it up and use it. For the demo, we attach it to a stock Prompt Opinion agent in the platform UI — no A2A code, no custom agent wrapper.
It ships in two pieces:
- MCP server — twelve tools covering patient context, augmentation proposals (chart-resident notes and agent-supplied text), pipeline run status, proposal listing / detail / edit, terminology search across SNOMED, RxNorm, LOINC, and ICD-10, and the accept / reject / reopen lifecycle. Streamable HTTP, SHARP-aware. Self-sufficient — a chat-only agent that has Anamnesis attached can run the full lifecycle without our UI.
- Provider review workspace — a Next.js deep-link surface showing source notes, the chart slice the pipeline reconciled against, the proposed FHIR resource, the classification (NEW / UPDATING / CONFLICTING), the confidence breakdown, and any conflicts. Accept / reject / edit; nothing writes silently.
Two input paths, one pipeline. ProposeAugmentations runs against chart-resident DocumentReferences pulled via SHARP. ProposeAugmentationsFromNotes accepts any text the consuming agent has in hand — extracted PDFs, faxed referrals, outside-clinic notes, emails, mid-encounter transcripts — and runs the same pipeline. Inline source text only enters the chart on accept, minted as a US Core DocumentReference in the same transaction Bundle as the derived finding. This is what closes the interoperability gap that comes up every day in real chart prep: the relevant note often isn't in the FHIR record yet.
The demo persona is a provider doing pre-visit chart catch-up across multi-source notes (cardiology consult, external ER visit, neurology follow-up), with mid-encounter transcript capture as a secondary path.
Why this matters beyond pre-visit prep
Pre-visit prep is the demo. The infrastructure underneath addresses several different problems with the same pipeline.
Research and FDA evidence generation. Clinical research grinds to a halt on chart abstraction. An oncology study that needs structured staging, treatment lines, and biomarker status across thousands of patients spends most of its budget paying nurses or trained abstractors to read notes and fill spreadsheets. The FDA has been working with the healthcare ecosystem to source high-quality structured clinical data for real-world evidence — and FHIR is the standard the agency is converging on. Downstream of FHIR, the dominant common data model for observational research (OMOP, maintained by OHDSI) transforms cleanly through established HL7-OHDSI tooling. Anamnesis produces the structured FHIR upstream, which means both the FDA-aligned evidence pathways and the OMOP analytics warehouses get fed automatically instead of by hand. For specialty research like oncology, where notes are dense and structured fields are sparse, this is the difference between a study that takes eighteen months and one that takes three.
Quality measure reporting. HEDIS, MIPS, and CMS quality measures depend on structured chart data. Hospitals with millions of dollars in value-based-care contracts spend significant effort extracting measure-relevant facts from notes — diabetic foot exams, smoking cessation counseling, depression screening, A1c trends. Augmenting charts from notes is a direct path to defensible quality reporting that auditors and payers can trace back to the source.
Regulatory compliance. CMS-0057-F, the Interoperability and Prior Authorization Final Rule, requires payers to expose four FHIR-based APIs by January 2027, with USCDI v3 conformance for certified EHRs by January 2026. The structured output Anamnesis produces is exactly the shape these APIs need to carry. Health systems that augment charts now are positioned for the regulatory deadlines that are already in motion.
The same plumbing serves all of these. Get the augmentation right, and downstream uses follow.
How we built it
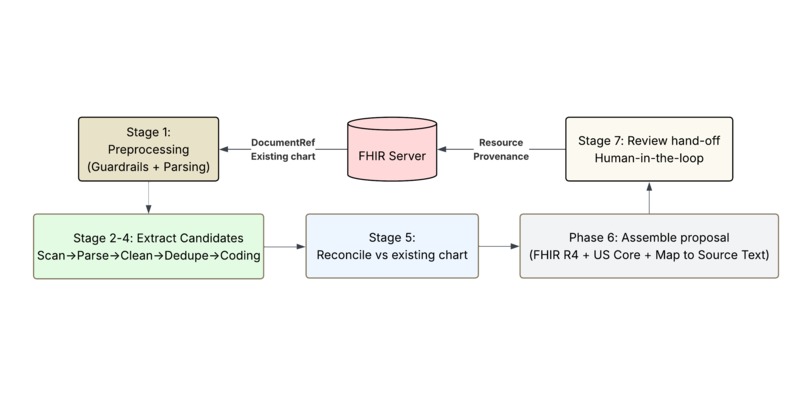
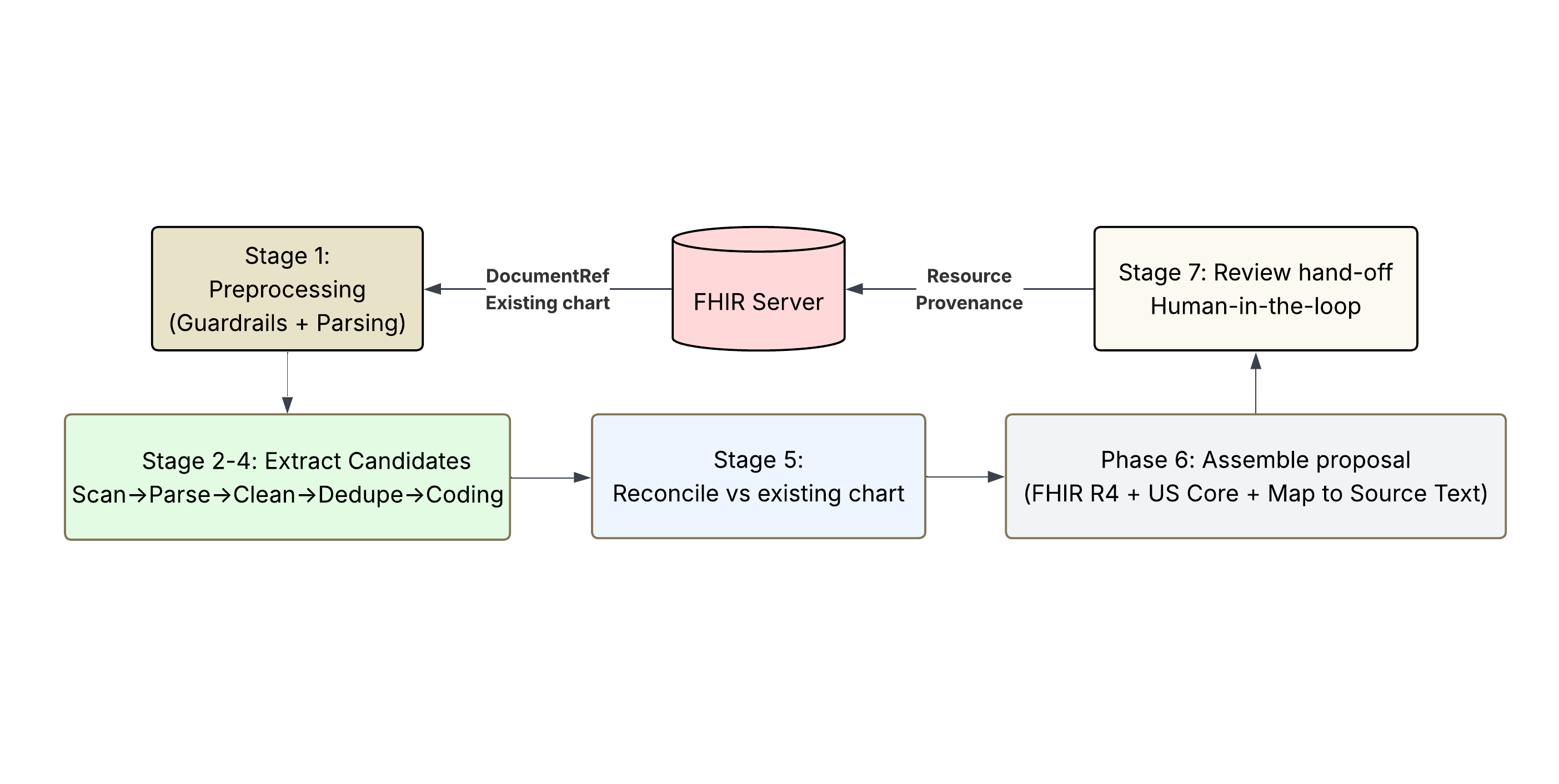
A six-stage augmentation pipeline plus an input guardrail and a deterministic write-back stage. Each stage is a pure function over typed Pydantic schemas; LLM calls are wrapped in telemetry. Deterministic where it can be (sentence splitting, terminology lookup, code matching, FHIR assembly), LLM-driven where it must be (extraction, fuzzy reconciliation).
- Chart load — pull existing chart and notes from the FHIR server using SHARP-propagated tokens.
- Input guardrail — per-doc gate (deterministic checks plus
gpt-5.4-nano, all docs in parallel) that rejects empty, binary, non-clinical, and prompt-injection inputs before the expensive parse spend. - Preprocess — clinical-tuned sentence splitter; every sentence becomes
[N], the universal address every downstream LLM call references. - Extract — scan → parse → clean per resource type, all notes in parallel. Structured Pydantic outputs with source-sentence provenance and a categorical certainty label.
- Cross-note dedupe — deterministic exact-match merge first, LLM adjudication only for fuzzy near-duplicates. Encounter-scoped: patient-level resources dedupe globally; Observations and Procedures dedupe within encounter.
- Terminology coding — described in detail below.
- Reconcile vs chart — deterministic code match first, LLM adjudication only for ambiguous display overlap. Classifies each candidate as NEW / DUPLICATE / UPDATING / CONFLICTING with chart references attached.
- Assemble — pure deterministic transform to FHIR R4 dicts (US Core profiles where they exist), citation char-spans resolved from sentence numbers, and a rule-based pass that detects inter-proposal conflicts (same medication, contradictory actions across providers) and pins them to a shared conflict group.
On accept, write-back emits a single transaction Bundle: the resource, a Provenance with one entity per source document and one source-text-span extension per citation, and — for inline notes — a US Core DocumentReference carrying the source text. UPDATING uses PUT with versionId for optimistic concurrency. CONFLICTING never retires the existing resource: a contradiction is an annotation, not a unilateral correction.
Terminology coding deserves its own section
Most of the engineering effort went into stage 6, because correct codes are the difference between an augmentation that makes the chart usable downstream and one that creates noise.
For each candidate fact, the system runs a multi-step retrieval and selection loop:
- Embed and search. SapBERT-from-PubMedBERT embeddings (768-dim, biomedical-domain) over a FAISS index covering 1,094,646 medical concepts: SNOMED (527k rows), RxNorm (449k rows), LOINC (95k rows), ICD-10 (23k rows). Returns top 10 candidates with similarity scores.
- Context-aware select. An LLM picks from those candidates with the original note context attached — so it picks the code that fits the clinical situation, not just the surface phrase. "Stage IV" in an oncology note and "Stage IV" in a heart-failure note land on different codes, and the model knows which is which because the surrounding sentences are part of the prompt.
- Re-search if needed. If no candidate is a good match, the system asks the LLM to propose 5 better search terms based on the note context, runs another FAISS search, and selects again.
- Mark for review if still nothing. If the second pass also fails, the fact is flagged ATTENTION rather than silently miscoded. A clinician sees it; the system doesn't pretend.
US Core fixed-code short-circuit handles vital signs and tobacco status (where the codes are mandated and don't need lookup). Conditions are dual-coded with both SNOMED and ICD-10. The result is high coding accuracy across heterogeneous note styles without surrendering control to the LLM's surface-form pattern matching.
Confidence is calibrated, not LLM-self-reported
LLMs are unreliable at numeric self-confidence. We split the problem: the LLM contributes a single categorical label at extraction time (definite | probable | uncertain — the kind of judgment LLMs are actually good at). Four deterministic signals do the rest:
- Source corroboration across notes
- Coding quality (FAISS similarity, US Core conformance)
- Reconciliation match type
- A hard CONFLICTING → ATTENTION override
The result is a calibrated tier (CONFIDENT / REVIEW / ATTENTION) and human-readable flags telling the clinician where to look. The composite score moves with correctness now, which the LLM-self-reported version did not.
Benchmark
We built an eval corpus of 18 multi-source clinical notes × 13 patient charts × 77 labeled facts and a multi-run benchmark runner.
| Metric | Value |
|---|---|
| Augmentation accuracy | 90% [87%, 95%] |
| Consistency (correct in ≥4/5 runs) | 88% |
| Provenance coverage | 100% |
| Cost per chart prep (3 notes) | ~$0.13 |
| End-to-end latency | ~20–25s wall-clock |
NEW (93%) and DUPLICATE (92%) — the bulk of real clinical findings — both clear 90% with tight variance. UPDATING and CONFLICTING are thin slices in the corpus; we report wide error bars rather than hide sample size.
Per-tier robustness:
| Tier | Accuracy |
|---|---|
| Clean notes | 94% [90%, 97%] |
| Messy notes | 86% [80%, 90%] |
| Trap cases (deliberately designed to mislead) | 90% [81%, 96%] |
Where errors come from:
| Source | Share |
|---|---|
| Extraction miss (fact never reached the pipeline) | 62% |
| Coding miss (right fact, wrong code) | 32% |
| Reconciler miss (right fact, right code, wrong class) | 5% |
The full benchmark report — with confidence intervals, per-class breakdowns, confusion matrix, consistency histogram, and stable-wrong analysis — ships in the repo at benchmarks/eval-corpus-v1/. Reproducible with one command.
Cost and latency
A 3-note chart prep typically costs about thirteen cents and takes about twenty-two seconds wall-clock. The pipeline runs notes through Stage 2 and Stage 4 with asyncio.gather parallelism, so the per-chart wall is bounded by the slowest single-note pipeline plus the cross-note merge — not the sum of N note pipelines.
A loaded clinician's time is roughly $3/minute. A 10-minute time saving on chart prep represents a 200×+ return on the API cost. Production caching reduces this further: terminology lookups cache across patients, guardrail verdicts cache across re-runs, and the steady-state cost is materially lower than this cold-cache benchmark.
Challenges
- LLM numeric confidence is uncalibrated. Self-reported scores are roughly noise. We split the problem: ask the LLM only what it's good at (categorical certainty), and let deterministic signals do the calibration. The composite score actually moves with correctness now.
- Reconciliation is the hard problem, not extraction. "Hypertension" and "essential hypertension" should merge; "lisinopril 10 mg" and "lisinopril 20 mg" should update; "penicillin allergy" and "NKDA" should conflict. We took a two-tier approach — deterministic code match first, LLM adjudication only for ambiguous display overlap — to keep latency, cost, and behavior predictable.
- Inter-note contradictions had to surface, not hide. Cardiology discontinues a medication; neurology increases its dose a month later. A naive pipeline picks one and silently buries the other. We added a deterministic conflict-detection pass that pins both proposals to a shared group, forces them to the ATTENTION tier, and auto-rejects siblings on accept.
- Provenance had to be FHIR-correct, not just present. Multi-citation
Provenancewith one entity per source document and onesource-text-spanextension per citation; for inline notes, mint theDocumentReferencein the same transaction Bundle so the Provenance entity reference resolves. Getting this right meant US Core profiles, optimistic concurrency on UPDATING, and resisting the temptation to silently retire a resource on CONFLICTING. - Coding the right concept across heterogeneous note styles. Surface-form match is the wrong proxy for semantic correctness. The retry-with-rewritten-search-terms loop in Stage 6 was the engineering piece that moved coding accuracy from "acceptable on clean inputs" to "robust across the full corpus."
Accomplishments
- A self-sufficient MCP that any consumer in the ecosystem can drive end-to-end without ever opening our UI.
- Two input paths through one pipeline: chart-resident notes and any text the agent has — PDFs, outside records, transcripts.
- 100% provenance coverage at 90% accuracy — the auditability story is a benchmark, not a slide.
- Sub-30-second pre-visit chart prep across three multi-source notes for ~$0.13.
- A clean separation: FHIR is the source of truth; the local DB holds only working state. Wipe the DB and you lose history, never clinical data.
- Coverage across the four major terminology systems (SNOMED, RxNorm, LOINC, ICD-10) with a context-aware code-selection loop, not just nearest-neighbor lookup.
What we learned
- Healthcare AI's bottleneck is rarely the model. It's the contract — SHARP propagation, US Core conformance, Provenance correctness, write semantics, human-in-the-loop hand-off. Once those are solved, augmentation is tractable.
- Deterministic stages around LLM stages give you something rare in this space: a calibrated, debuggable, cacheable pipeline. Re-runs are free; retries are idempotent; cost is predictable.
- "Nothing writes silently" is a stronger product principle than it looks. It forces every design decision — confidence scoring, conflict surfacing, edit-before-accept, provenance shape — into a coherent whole.
- The augmentation MCP is upstream of more than chart prep. The same structured FHIR output that makes a clinician's morning easier is what makes research, quality reporting, and regulatory compliance possible. Solving the augmentation problem is solving the input layer for several markets.
What's next
- Broader resource coverage (Immunization, DiagnosticReport, CarePlan).
- Expanded eval corpus, especially on UPDATING and CONFLICTING — the slices where current sample size is thinnest.
- Specialty extensions for oncology (mCODE profiles), behavioral health, and cardiology — each has terminology and structural conventions that pay off when modeled explicitly.
- Production SSO embedding for the review workspace. The deep-link review token is intentionally an alias of the clinician's Prompt Opinion session, designed to drop straight into a real SSO surface.
- A FHIR-to-OMOP transformation path packaged as a sibling MCP, so the same augmentation that updates the chart also flows directly into a research-ready warehouse.
- Composition with other MCPs. Anamnesis pairs naturally with coding-assistant, care-gap, or prior-auth MCPs in the same workspace so a single agent can run augmentation, gap analysis, and care planning as one workflow.
Built With
- a2a
- faiss
- fastapi
- fastmcp
- fhir-r4
- icd-10
- loinc
- mcp
- next.js
- openai
- prompt-opinion
- pydantic
- python
- react
- rxnorm
- sapbert
- shadcn/ui
- sharp
- snomed
- sqlalchemy
- sqlite
- tailwind
- typescript
- us-core

Log in or sign up for Devpost to join the conversation.