Inspiration
HIV continues to be a major public health crisis both in the United States and around the world. While major scientific advances have made it easier than ever to prevent and treat HIV, there remains no vaccine or cure, and tens of thousands of people continue to contract HIV every year.
Furthermore, there are a few challenges when it comes to tackling HIV. (1) too few people with HIV are aware of their infection; (2) many people with HIV do not receive proper treatment; In particular, we decided to tackle the second challenge of proper treatment, which my colleague will next elaborate upon.
Using current chemistry databases to analyze molecules related to the causation of HIV, we are able to use ML to find the best compounds that inhibit the spread of HIV in a person.
With our hackathon project, we hope to not only aid current biochem researchers with finding the best HIV treatments, but also to spread awareness and empathy around the HIV epidemic.
What it does
Develop an application using the power of data analysis and machine learning that can assist biochemical scientists in finding effective oral solutions to patients who are currently suffering from HIV.
How we built it
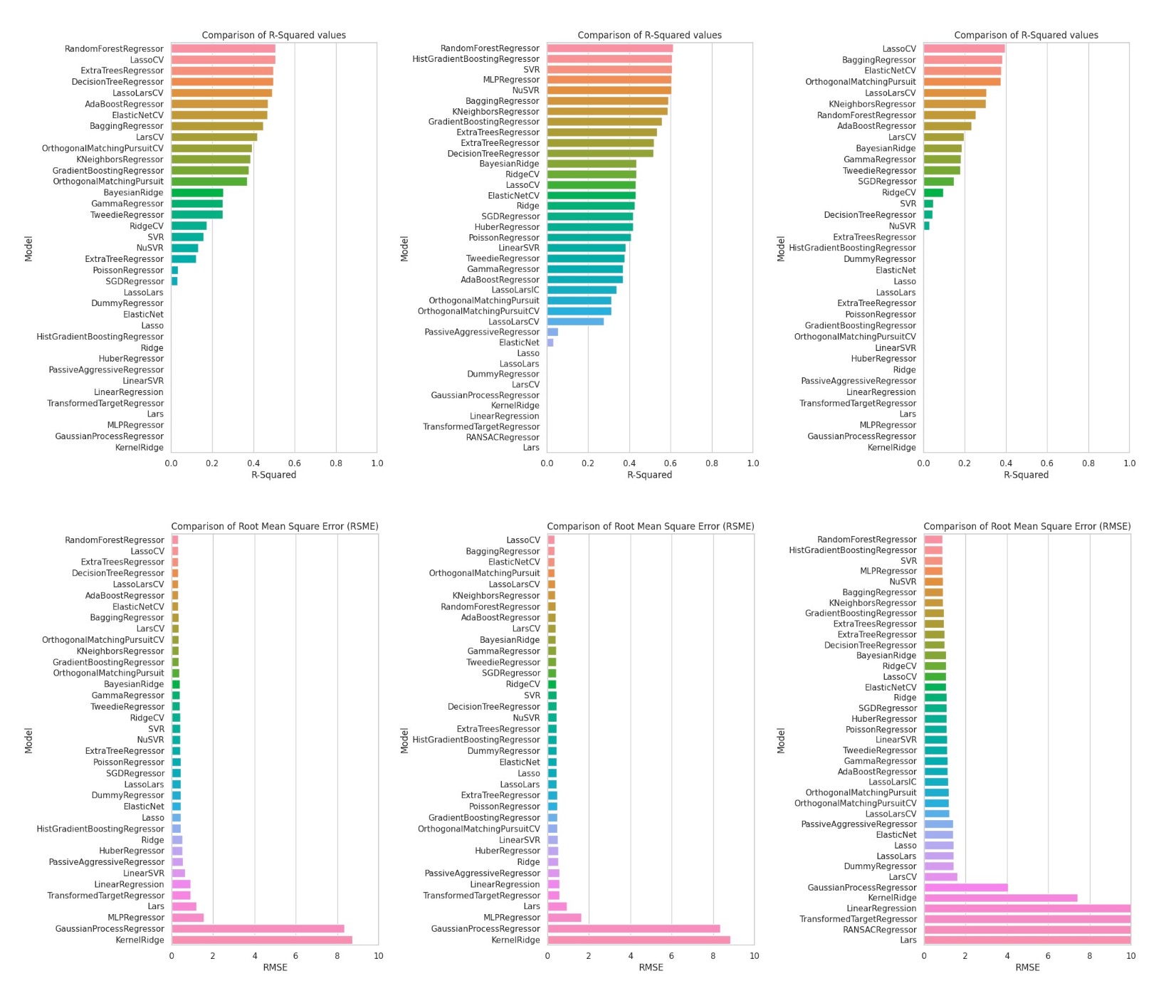
We extract molecule data about HIV from ChEMBL. ChEMBL is a manually curated database of bioactive molecules with drug-like properties. We chose single proteins due to their simplicity. We chose target 0, 4, and 6 (HIV protease, C-C chemokine receptor type 5, and Histone acetyltransferase KAT5) due to the diverse ways they cause HIV proliferation. HIV Protease helps cut large viral precursor polypeptides into smaller functional proteins necessary for HIV to mature and increase its effectiveness. C-C chemokine receptor type 5 (CCR5) is a co-receptor used by the HIV virus to gain entry into cells. Histone acetyltransferase KAT5 has the role of gene expression regulation and is able to enhance viral gene expression (by binding to the promoter regions of viruses), contributing to viral replication and the production of new infectious virions for HIV. Picking a standard bioactivity unit type (IC50, here) makes it so that the drugs that address each target behave in a standardized way, allowing them to be compared easily and evaluated in the same ML algorithms. In each dataframe, the standard value property shows how potent an assay is at addressing/eliminating a target (the lower the standard value, more potent the assay). IC50 refers to there being 50% of a virus uninhibited, so the standard value thus shows how much of an assay is needed to kill 50% of a given amount of HIV viral load. We used LazyPredict in order to find the best regression models that is has a high R^2 value and a low RSME values. After picking our model, we also tested around different parameters for comparable results. We then graphed the relationship between observed and predicted pIC50.
Challenges we ran into
Some challenges that we ran is that we had to learn new packages that were both challenging and that we have to learn new chemistry concepts in order to successfully create our data analysis. Additionally, due to the hackathon being virtual, our team sometimes faced difficulty in coordinating times to meet and planning.
Accomplishments that we’re proud of
Because this STEMist hackathon was conducted over a period of two days, we are especially proud that we were able to come together and build a coherent product that properly utilized machine learning within this relatively short time frame. We are also proud that our product can be seriously used in a socially-benefitting way that can improve the lives of people who are currently suffering from HIV.
What we learned
Through our time while working together on this hackathon project, we not only gained more technical insight into using the latest technology on data analysis as well as machine learning, but also gained a broader view of the social environment surrounding the HIV epidemic. Within the 2-day time limit on our hackathon, we also learned the power of teamwork and management skills to finish all of our required and desired tasks within the timeframe.
What’s next for this project
Image classification is a side we want to use in order to use other forms of data collection in our solution. In addition to this we hope to classify more targets in order to gain insight into the treatment potential of other compounds.
Built With
- matplotlib
- python
- seaborn








Log in or sign up for Devpost to join the conversation.