-
-

Our model solves both Predictive Medicine and Resource Allocation at the hospitals.
-
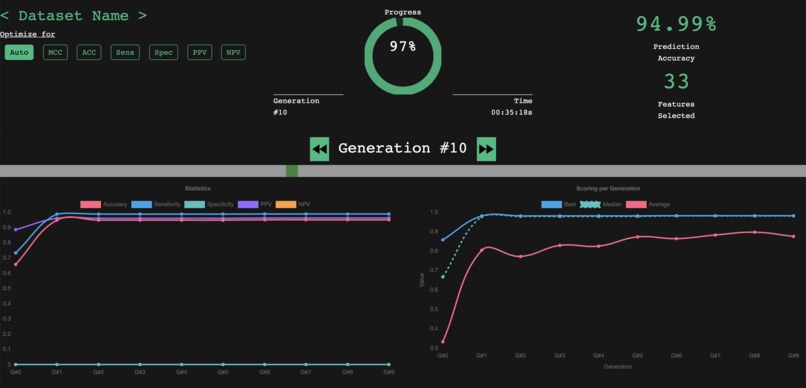
94.55% Accuracy and 80% Precision at predicting the treatment efficacy for a given patient.
-

Explanation of how the model makes the predictions.
-
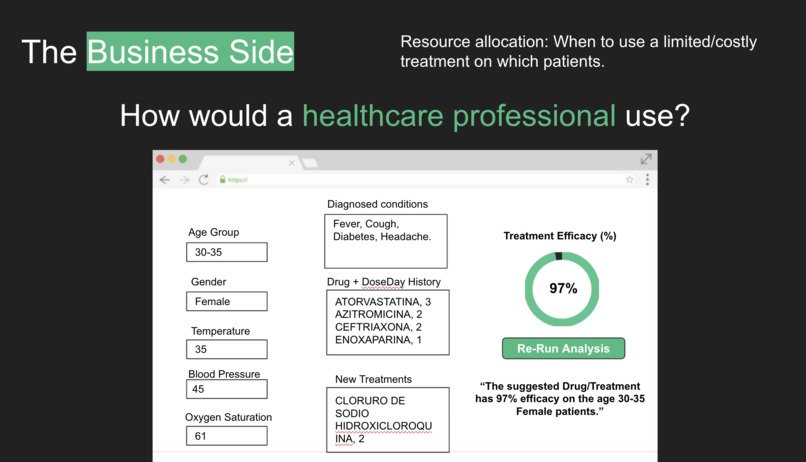
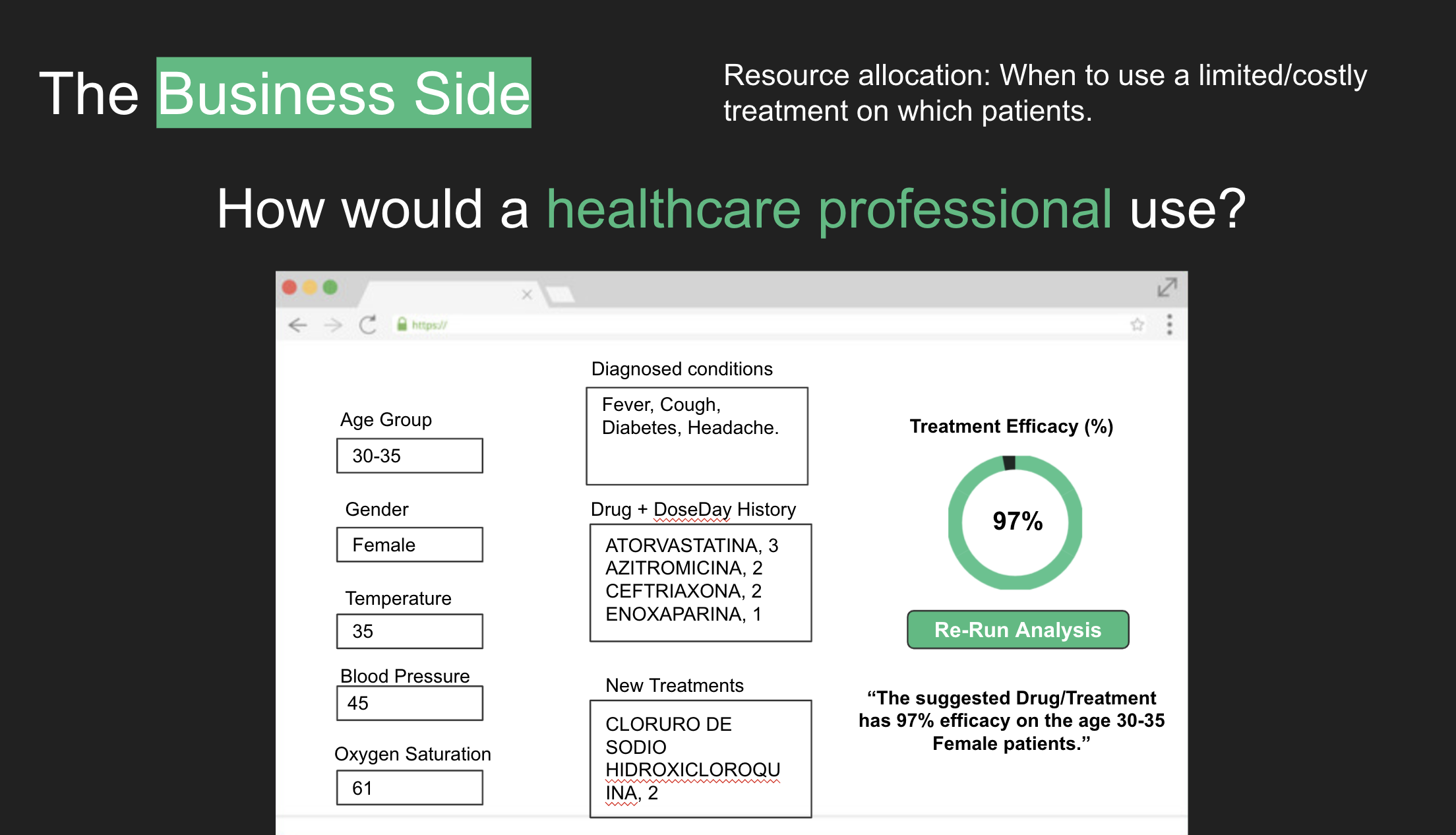
Proposed web interface for healthcare professionals to use our tool.
-

Parameters we used to predict the most efficient treatment for a patient.
-

Our prediction targets. We will predict the Patient Death/Healing chance by analysing the Demographics+Drug/Treatment given.





TRACK: PREDICTIVE MEDICINE - Challenge 1
Conclusion
During the hackathon, we managed to create a model which can solve both predictive medicine and hospital resource allocation.
We are able to predict with 94.99% Accuracy and 80% Precision the efficacy of a treatment for a given patient.
Our model was trained using the Patient Demographics data, the Drugs given to the patient, and the Lab Results during the treatment, given by the HM Hospitals and Sanitas.
The resulting model can be reused for Three use-cases.

Proposed web interface for healthcare professionals to use our tool.

Propose Solution
We are creating a predictor for hospitals to estimate the following items: a) List the options of treatments for a given patient demographic; b) Likelihood of survival of a patient on the current treatment; c) Transparency on which variables (symptoms, lab results) affect the treatment efficacy for each patient demographic (age groups/gender).
Our technology stacks consists of a GPU-powered Neuroevolution architecture, which is able to find the best neural network model out of 20 Billion combinations, openly explaining which parameters were chosen and how the prediction is made - avoiding the ML blackbox.
Our Story Background
Making humanity evolve faster than viruses. Helping scientists and health professionals to use data intelligence to deliver more efficient treatments and discover novel drugs.
Our initial idea of AI in Healthcare was born after winning 5 Hack The Crisis hackathons during 2020. We had a solution of a Citizen Science Game, enabling people to help scientists find vaccine formulas by playing a game - helping to label datasets for epitope protein-based vaccine prediction. https://www.analysismode.com/aminocrush/














Log in or sign up for Devpost to join the conversation.