-
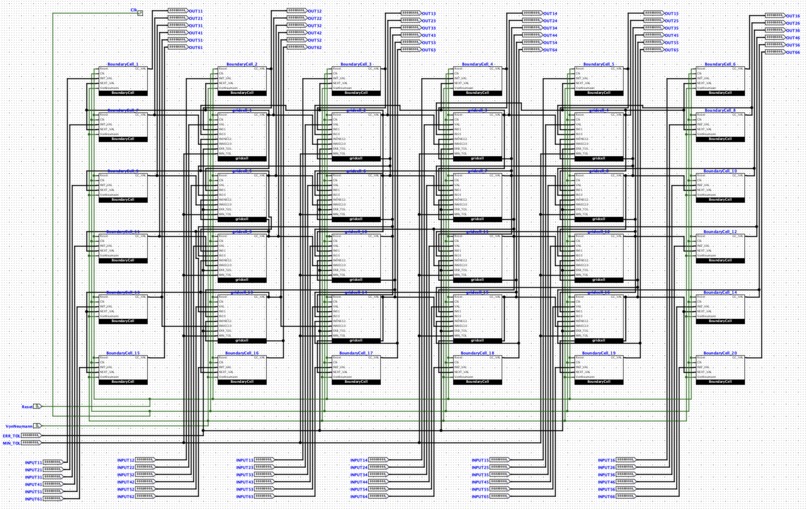
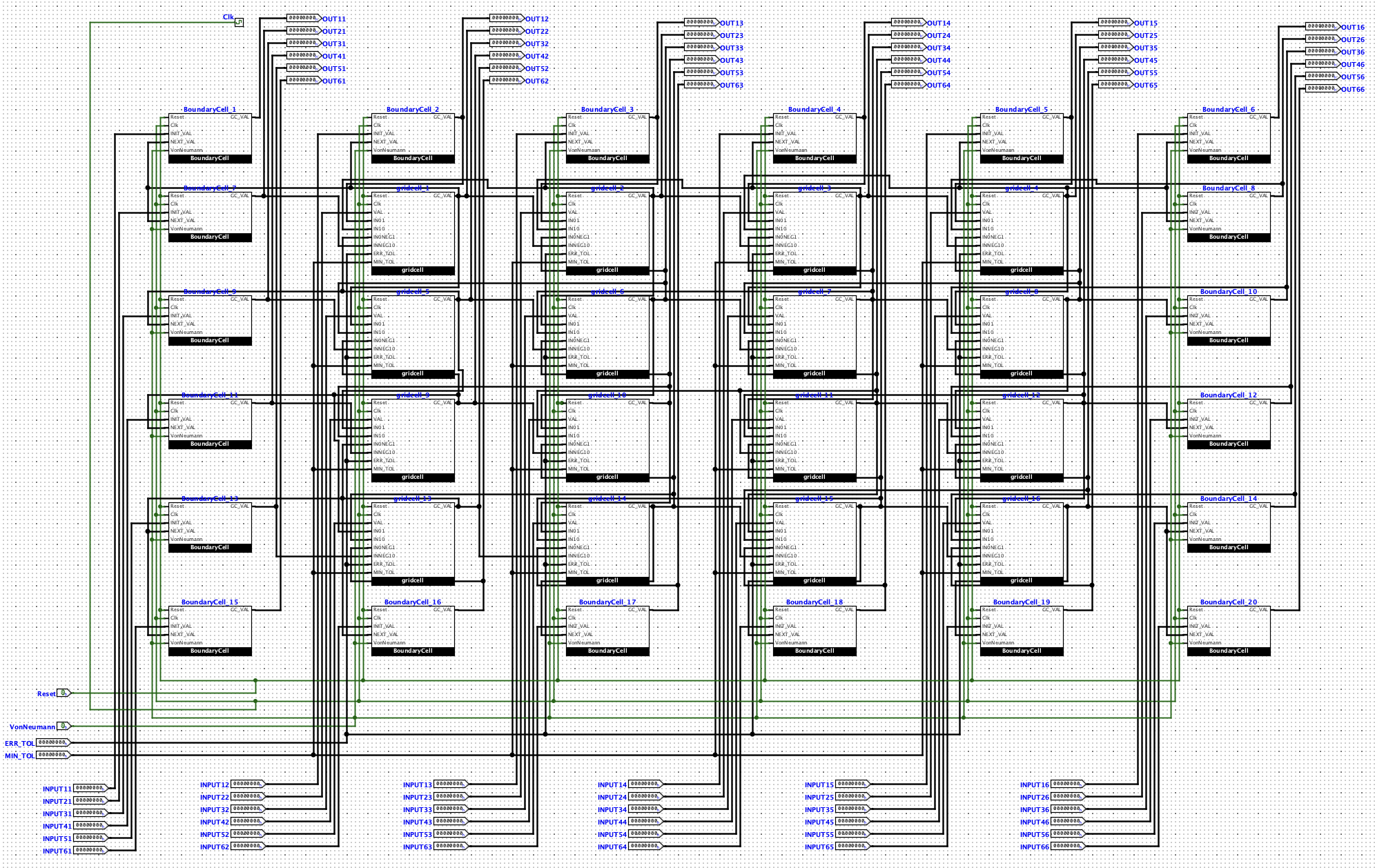
The structure of the ASIC
Inspiration
Grid-based simulations are ubiquitious and indispensable in many areas of Physics, from lattice simulations to Computational Fluid Dynamics (CFD). These simulations often have a high degree of parallelism; however, even GPUs may encounter issues with such simulations.
Problems such as inconsistent latencies between grid cells, instabilities arising from limited floating-point precision, and inefficient calculations due to the lack of "hardware-level convergence checkers", may slow down convergence and contribute to inaccurate results.
What it does
Our project aims to address these issues arising from standard hardware with a custom RTL Accelerator for such grid-based simulations. In GPUs, calculations carried out on grid cells that are close to one another (or even next to each other) might be distributed across compute cells that are far from each other, leading to increased iteration times and reduced efficiency.
Our ASIC design is comprised of a grid of computation cells that are directly connected to their neighbours, making it highly suitable for grid-based simulations. Given initial and boundary conditions, the ASIC iteratively calculates the solution to the equation specified by the ALU subunit, implementing the Jacobi method on a hardware level. The design of the ASIC is highly modular; the grid size, the equation to be solved, and the initial conditions can all be changed by swapping submodules.
How we built it
The project was designed and validated using the Logisim-evolution software. Further validation was carried out on the Verilog project files on GitHub. The main components of the circuit are the interconnected grid cells, each of which consists of two shift-load registers, an ALU, a custom RTL "Convergence Checker", and a finite state machine.
Challenges we ran into
The main challenge we encountered during the project was the Tiny Tapeout size limitation. One of the three main problems related to such simulations is the instability caused by limited floating-point precision in "conventional" hardware. Even though this problem could easily be fixed by making the ASIC architecture 32 (or even 64) bit, we weren't able to implement this feature within the constraints imposed by the Tiny Tapeout template.
Accomplishments that we're proud of
Despite that, we were able to address two of the main issues related to grid-based simulations, namely, inconsistent latencies between grid cells and inefficient calculations due to a lack of hardware-level convergence checks.
What we learned
Thanks to this project, we were able to gain experience with Application-Specific Integrated Circuits (ASICs) and various hardware validation techniques.
What's next for "An RTL Accelerator for Grid-Based Physics Simulations"
A next step for the project would be to address the final issue of limited floating-point precision by upgrading the architecture of the accelerator. Moreover, provided there are no "tiny" (badum-tss) size restrictions, it is very possible to enhance the functionality of the ASIC by including different ALU submodules in each grid cell, granting the accelerator the ability to solve all kinds of different equations using grid-based methods.
Built With
- github
- logisim
- verilog


Log in or sign up for Devpost to join the conversation.