-
-
Final Poster
An Image is Worth 16x16 Letters
By Dhruv Kharabanda (dkharaba), Jon Kim (jkim377), Sami Bou Ghanem (sboughan), and Serge Berlin (sbelin)
Final Writeup
Here is a link to the final writeup: https://docs.google.com/document/d/1Oxhb8DjVQXeZDL4f3XCTcVHo1KMe48VPqEEy61HS2hc/edit
Project Check-in #1
Introduction
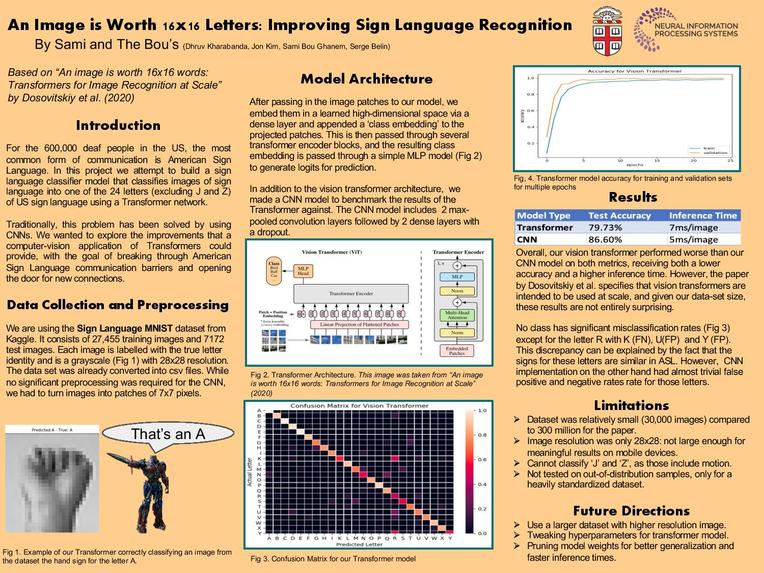
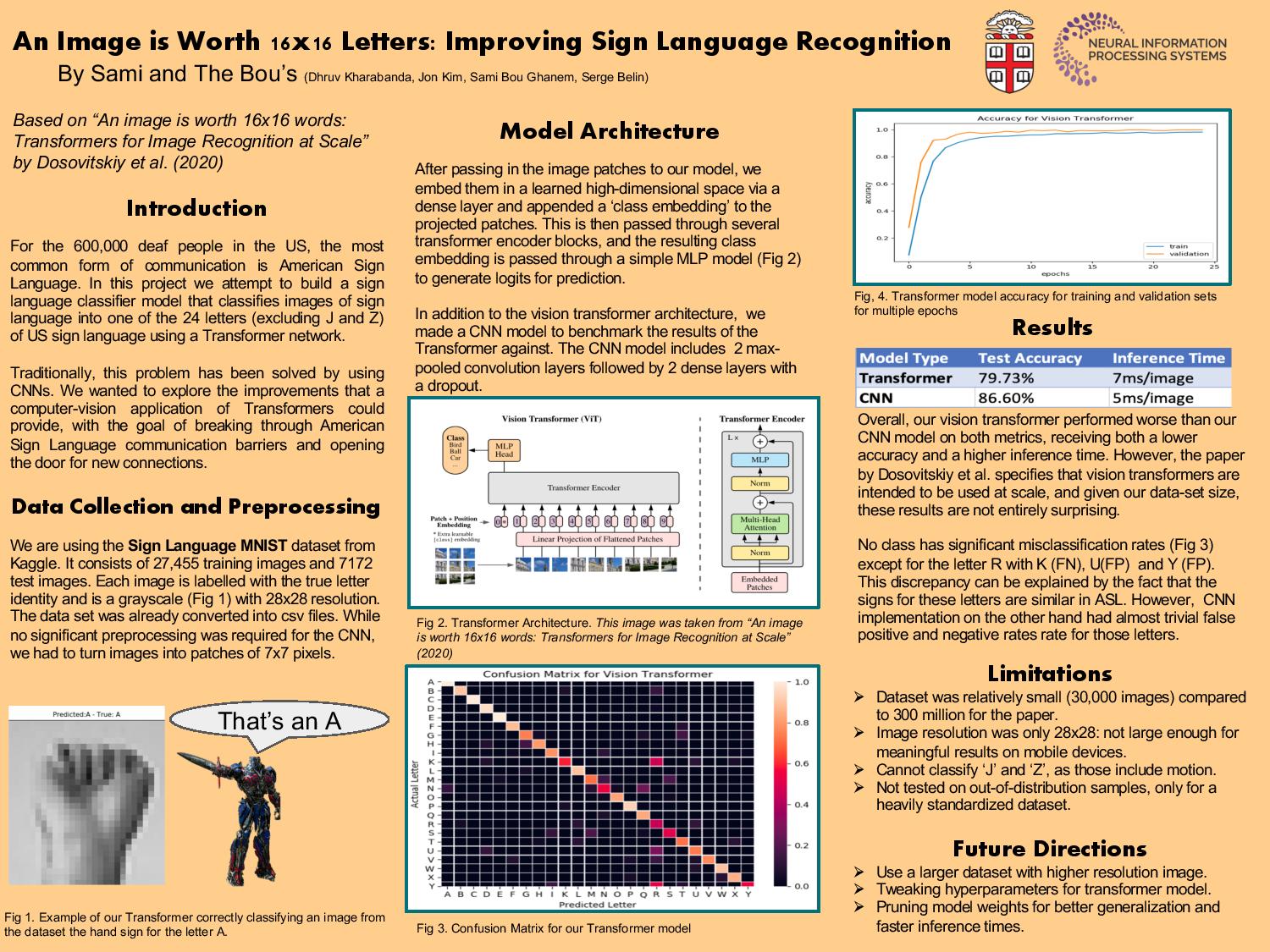
We are trying to create an image classifier that classifies images of sign language into one of the 24 letters of US sign language. but using Transformers instead of CNNs. Our work is inspired by the anonymously authored paper ‘An Image is Worth 16x16 Words’. We arrived at this topic because we wanted to improve on existing efforts to solve a common social issue using novel deep learning and computer vision techniques, and exploring potential improvements to this problem via this new approach to computer vision. Transformers are a relatively new creation compared to deep convolutional neural networks, and are only just being applied to computer vision tasks. We wanted to incorporate this in image classification as this has been a proposed use-case for transformers that is relatively unexplored.
Related Work:
There are multiple existing approaches to this classification problem, but all of them use CNNs, or CNNs and some RNN for temporal data in cases where it involves real-time classification. Our approach is inherently different, because we are trying to leverage the transformer encoder architecture in computer vision (as seen in the ‘An Image is Worth 16x16 Words’ paper) and explore its performance within this problem.
Data:
We will be using a Kaggle dataset found here: link This dataset consists of 27,455 images for training and 7172 images for testing in csv format. There is not significant preprocessing that needs to be done as the two sets of data have already been converted into csv files. Each image is already in the format of the label followed by a value between 0-255 that represents the grayscale intensity. The images are all 28x28.
Methodology:
We are training the model on image data (more detail in the previous section). Our architecture will involve a patch embedding (which linearly embeds patches of an image into a higher dimensional space), and feeding those embeddings into a standard transformer encoder architecture. There are also some additional modifications we need to make to the transformer architecture to make it more conducive to image classification, such as prepending a learnable embedding to the sequence of embedded patches. I believe the hardest part will be linearly embedding the image patches.
Metrics:
To test our model, we will perform image classification on our testing set. We want to achieve >75% accuracy on the validation set as a base, >85% accuracy as a target and >90% accuracy as a stretch. There are no complicated definitions of accuracy we need to consider, as this is a classification problem, however, getting a 75% accuracy does not mean that our model makes 25% of mistakes uniformly across the classes of images. For example, it might perform especially badly on certain letters, or on images featuring people with a different skin tone. These are things that we should try to avoid, and we can do this by plotting a confusion matrix and ensuring that all values on the diagonal are relatively similar in magnitude.
Ethics:
Approximately, 600,000 people in the US are deaf. This is 600,000 people who cannot communicate through speech and so require other methods to be understood. A model that can quickly identify sign language letters allows these people an opportunity to communicate with any other English speaking person, regardless of whether they know American Sign Language or not.
The major “stakeholders” in this problem are people who communicate using sign language and people who wish to communicate with people who can only use sign language. Any mistakes made by our algorithm would lead to miscommunications between parties. Frequent miscommunications can cause frustration for both sides and get in the way of well-meaning attempts to communicate with one another, especially when communication for deaf people is already difficult. Therefore, it is important to try and achieve as high an accuracy as possible so that we can facilitate communication between people effectively. Moreover, this can be a step towards automatic, real-time translation from audio to sign language and vice versa.
Division of Labor:
Serge will be responsible for evaluating the model’s accuracy on different classes by creating the appropriate data visualisations. Sami will be responsible for creating the Transformer Encoder architecture, while Dhruv will create a method to create image patches and their embeddings. Jon will be working on visualising self-attention on different inputs inspecting the vision transformer.
Project Check-in #2 Reflection
Here is a link to the reflection: https://docs.google.com/document/d/1Cs5OCa_FF_GR30zPzMgZfvd3G46IKNhXGqwjAW_rj8g/edit?usp=sharing
Built With
- keras
- python
- scikit-learn
- seaborn
- tensorflow



{kind=link}
Log in or sign up for Devpost to join the conversation.