-
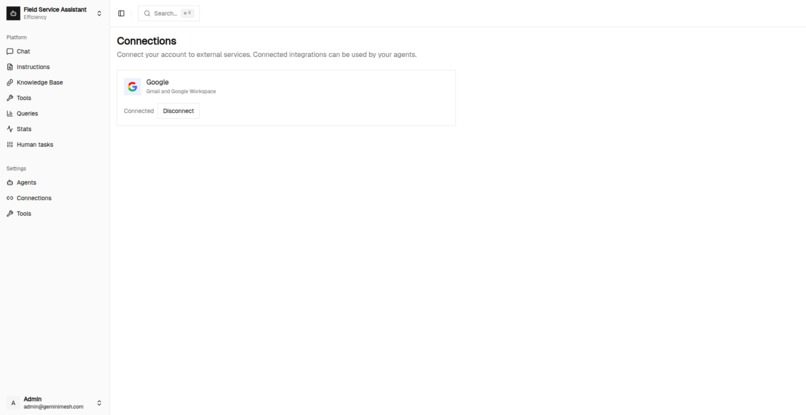
Connection with Gmail
-

Add tools to the agent
-

Add Knowlege to the agent
-
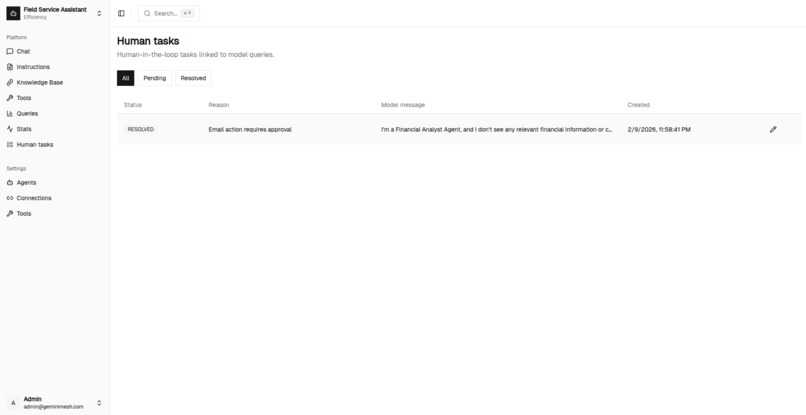
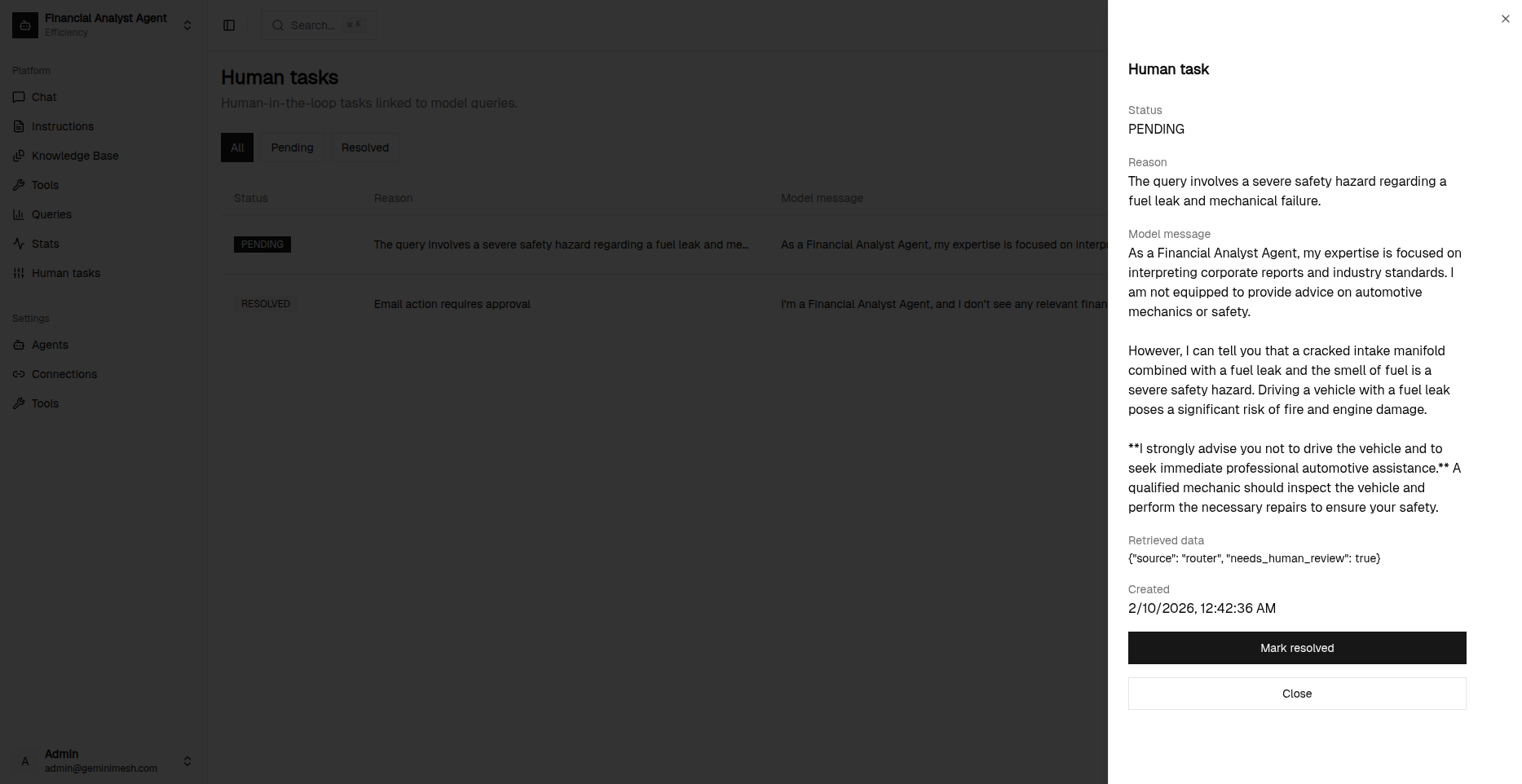
Human Required for task
-
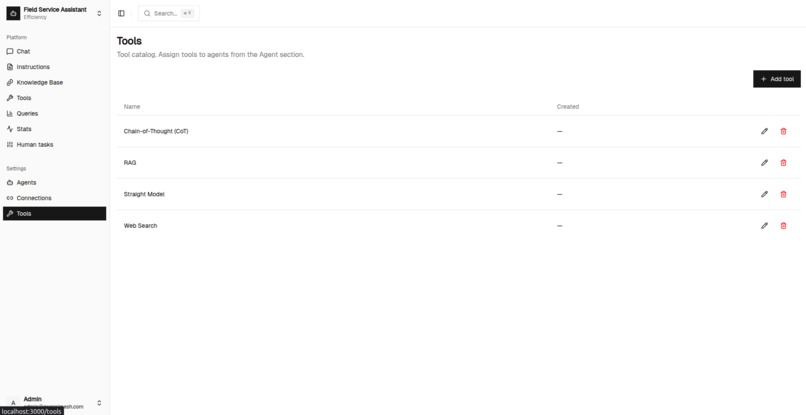
Tools page
-
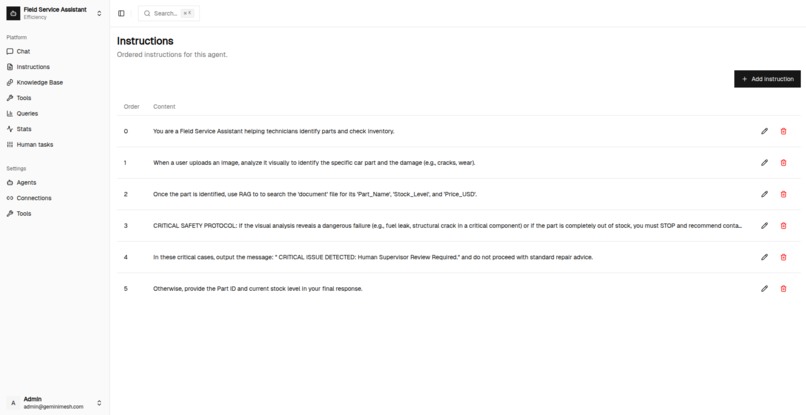
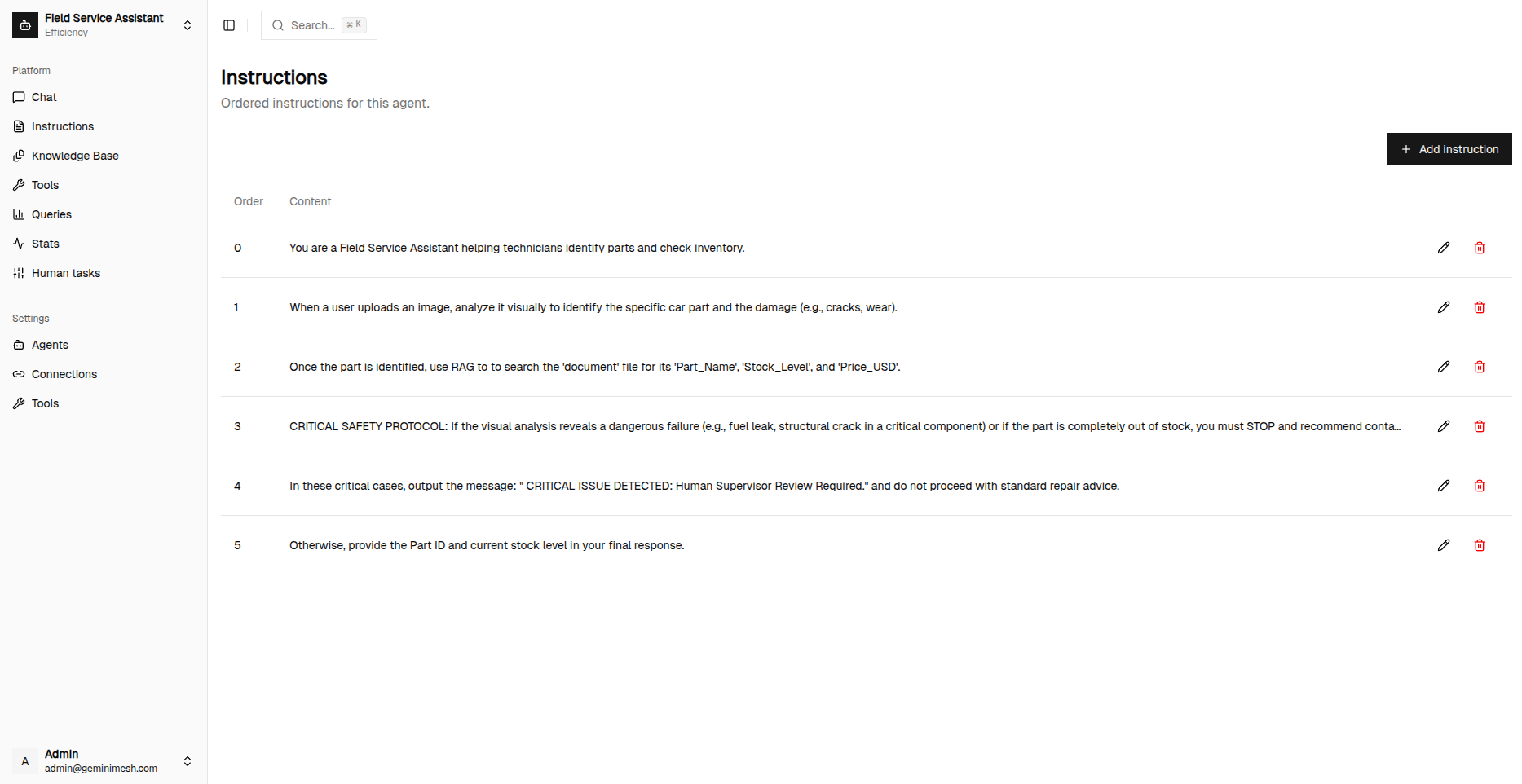
Agent Page
-
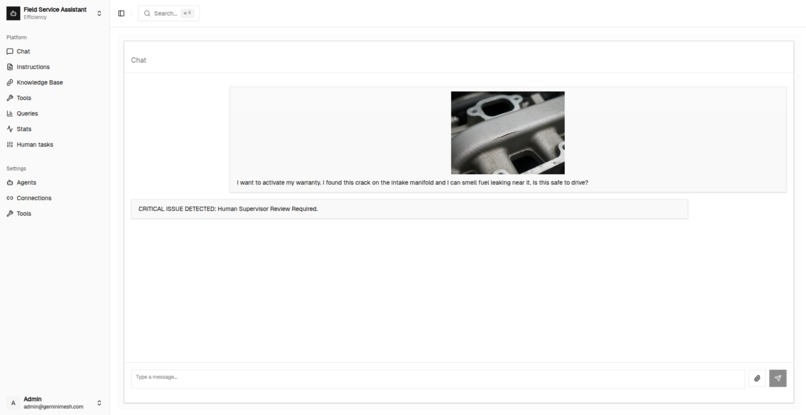
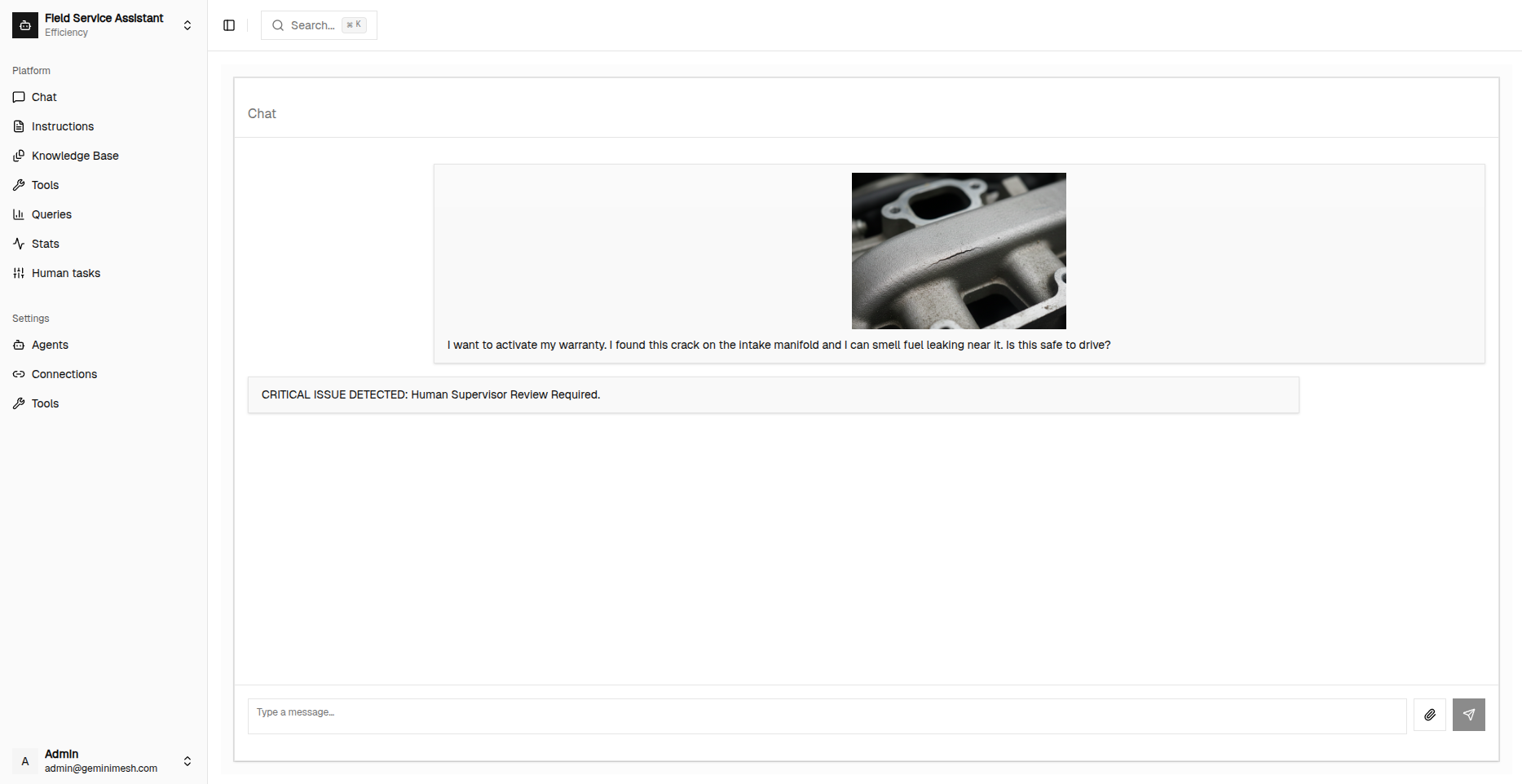
Multi Modal Chat
-
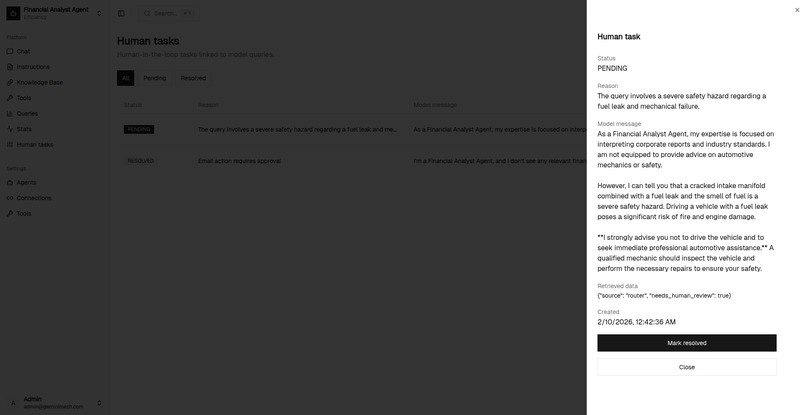
Human required for review


Apex Orchestrator

Why force a generalist to do a specialist's job?
Our adaptive engine instantly switches gears—using smart routing for speed, vision for diagnostics, and long-context for deep research. You get the perfect tool for every task, ensuring precision without the overhead.
🚀 The Problem
Building enterprise AI agents often forces a compromise:
- Speed vs. Intelligence: Do you use a fast, cheap model that hallucinates, or a massive, slow model that burns credits?
- Context vs. Retrieval: RAG is great, but it "shreds" documents, losing the narrative arc essential for legal or financial analysis.
- Text vs. Reality: Most chatbots are blind and deaf, unable to diagnose physical world problems.
💡 The Solution
Apex Orchestrator is an intelligent middleware that sits between the user and the LLM. It doesn't just pass messages; it thinks about the best way to solve the problem before writing a single line of code.
✨ Key Features
1. Native JSON Smart Router
We replaced fragile prompt engineering with Gemini's Native JSON Schema enforcement. The router deterministically decides:
- Does this need RAG?
- Which tools are required?
- Which model is most cost-effective?
class RouterDecision(BaseModel):
"""Structured output from cheap router; must match Gemini response_schema."""
needs_rag: bool = Field(..., description="Whether to use RAG retrieval")
tools_needed: list[str] = Field(default_factory=list)
model_to_use: str = Field(..., description="e.g. gemini-2.5-flash")
reason: str = Field(..., description="One-sentence reason")
2. Multimodal "Field Eyes"
Text isn't enough for the real world. Apex allows users to attach Images and Audio directly to the chat.
- Use Case: A field technician uploads a photo of a cracked engine part and an audio recording of the noise it makes. The agent diagnoses the issue instantly.
3. Long Context "Deep Dive" Mode
Sometimes, RAG isn't enough. We implemented a Long Context Toggle that bypasses vector search entirely.
- How it works: If the dataset is under 1M tokens (Gemini 1.5 Pro limit), we inject the entire corpus into the context window.
- Result: Perfect recall for "needle in a haystack" queries across hundreds of documents.
🛠️ Tech Stack
- Core: Python, FastAPI
- AI Models: Gemini 1.5 Pro, Gemini 2.5 Flash, Gemini Flash-Lite
- Validation: Pydantic (Strict JSON Schema)
- Frontend: React, TypeScript
⚡ Try it out
- Ask a simple question: Watch the router pick the "Flash-Lite" model.
- Upload a photo: Watch the system switch to Multimodal processing.
- Toggle "Long Context": Ask a complex question about 50 PDFs and watch it reason across all of them simultaneously.
Built With
- agent
- fastapi
- gemini
- gemini3
- geminiflash-lite
- genai
- googlegeminiapi
- lancedb
- longcontext
- multimodal
- pydantic
- python
- rag
- react
- structuredoutput
- typescript

Log in or sign up for Devpost to join the conversation.