Inspiration
I noticed many new singers/ rappers make simple mistakes when creating new music that holds back their popularity- i.e. odd pauses in their songs, poor transitions, etc. In building Ampalyze, I aimed to identify and help an artist correct these. (This, of course, is an extremely subjective way to look at this problem. To even suggest music can have mistakes is a mistake in itself- but I've left the outputs in a pure data form (no critique of my own) and this is aimed more at artists purely focused on popularity and success)
What it does
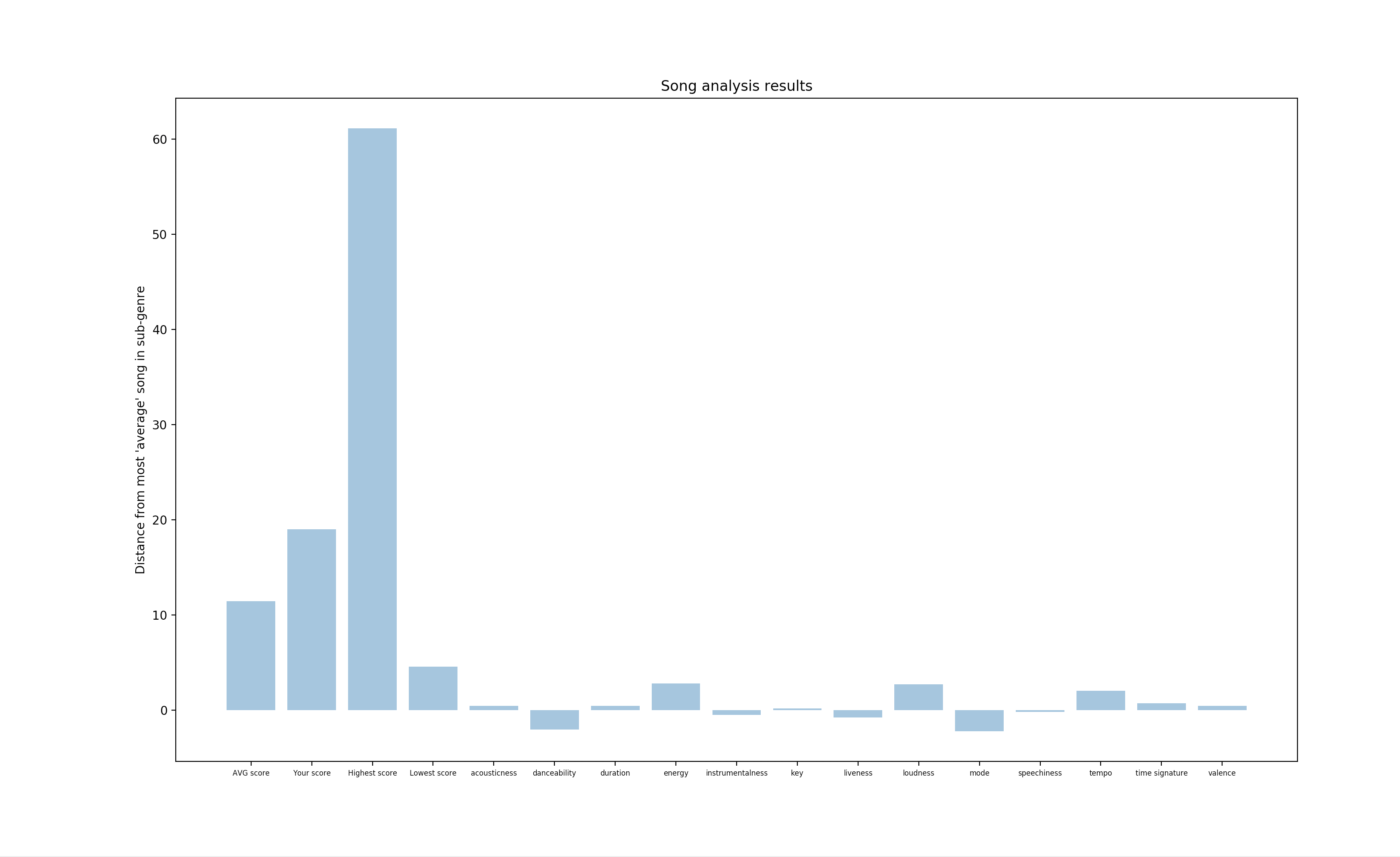
I scrape the top 50 rap songs from spotify, classify them into sub-genres of rap (hype, drill, etc) and then compare the 'new' song to its nearest sub-genre. Songs are compared with data from spotify's song info API- data including 'acousticness', 'danceability', 'duration_ms', 'energy', 'instrumentalness', 'key', 'liveness', 'loudness', 'mode', 'speechiness', 'tempo', 'time_signature', 'valence'
How I built it
scikitlearn's k-means grouping algorithm, and then comparing euclidian distances for the final analysis

Log in or sign up for Devpost to join the conversation.