-
-

sad guy being hacker meme
-

user login screen in the android application
-

user sign up screen in the android application
-

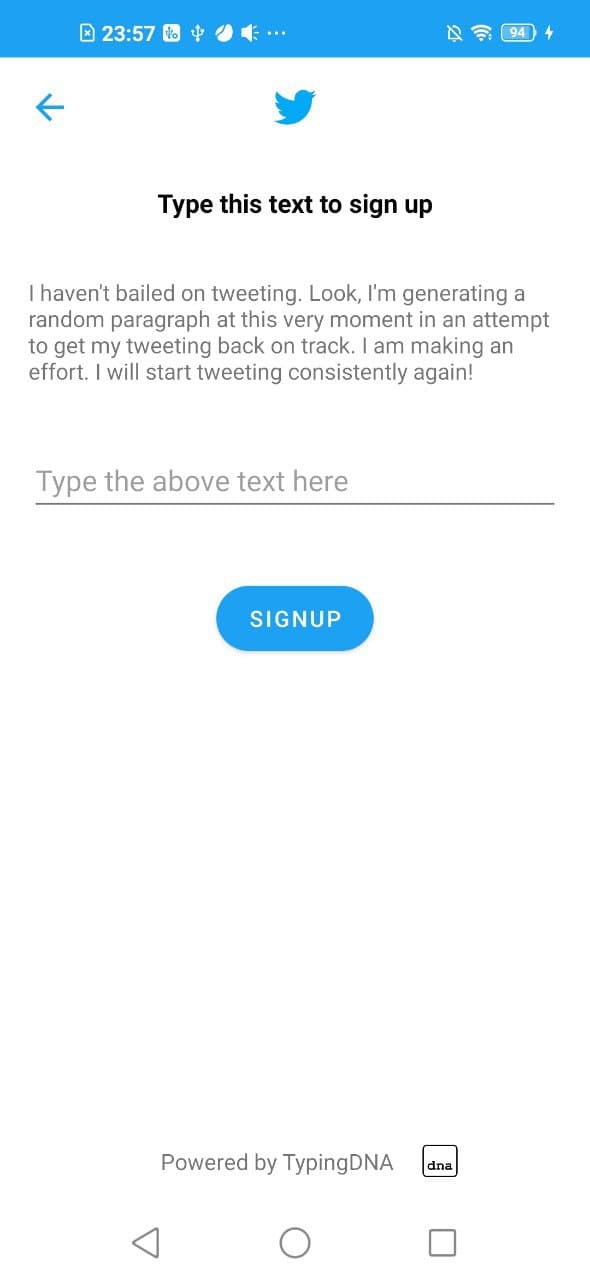
android app screen for collecting user onboarding pattern just after signup
-

user feed for existing tweets, showing other users tweets.
-

uset tweet posting screen in the android application
-

email confirmation sent to the user if UNVERIFIED is happening.
-

use case 1, which displays all the user tweets which are verified from the user
-

use case 2, which brings up fake accounts if a tweet is flagged or suspicious.
-

use case 3, finding the hacker who posted btc scam tweets from bezos and trump user accounts.
-

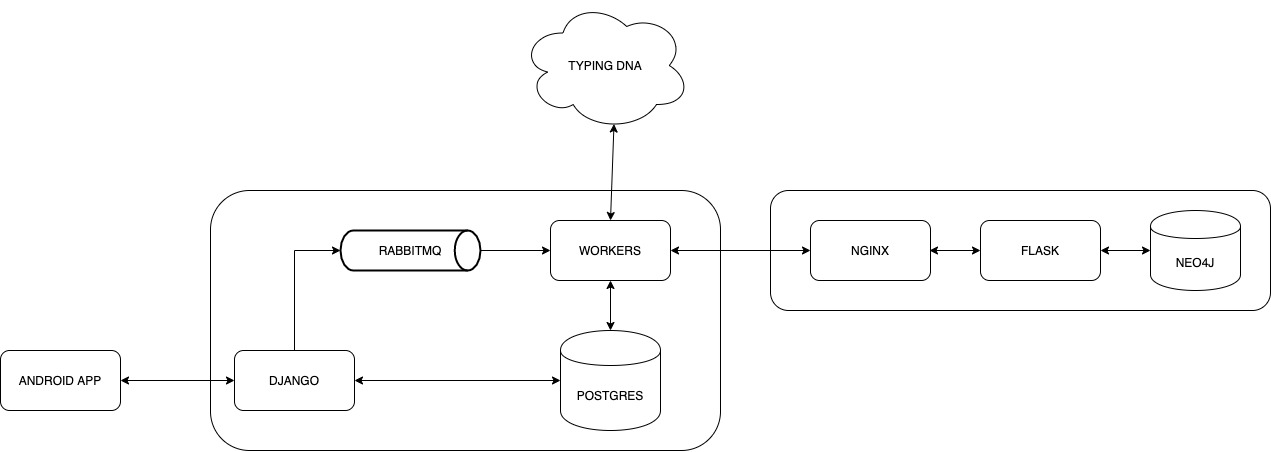
system architecture of among us.
-

btc scam tweet meme
-

me and my boys chilling after having bread and butter of typingDNA









Inspiration
The possibility of taking an authentication process and applying it for the scale of social media. It's similar to identifying criminals using NSA's facial recognition database but using typing patterns.
What it does
This platform enables:
- Authenticating Tweets.
- Finding fake accounts of a particular User.
- Identifying impostors who are impersonating other people and tweeting wrong information.
Everything using TypingDNA
How we built it
We capture User's onboarding pattern (type 0) while they sign-up on the platform, and it is used to verify every tweet-pattern (type 0) coming from that user's account.
We used TypingDNARecorder-Android SDK to record typing pattern from the Android client.
The Django Backend stores the typingDNA patterns in postgreSQL. A plethora of events are triggered based on user actions. It is handled using celery which uses rabbitmq as a message broker. The celery background workers handle the jobs and submit their results from typingDNA API to a neo4j database.
So lets get into the graph:
We have two types of nodes:
- User node
- Tweet node
User node:
Contains user_id, user_name
Tweet node:
Contains tweet_id, user_id, node_number, flagged
We have four types of relationships:
- USER_SIMILAR_RELATIONSHIP
- VERIFIED_RELATIONSHIP
- UNVERIFIED_RELATIONSHIP
- TWEET_SIMILAR_RELATIONSHIP
USER_SIMILAR_RELATIONSHIP
When a new user signs up, his onboarding pattern captured above is compared against every user's onboarding-pattern using TypingDNA's /match API endpoint which is bread and butter of our platform. Based on TypingDNA's results we create a relationship USER_SIMILAR amongst these users saying that they are likely the same person.
VERIFIED_RELATIONSHIP
When the user tweets from his phone we vet it against their onboarding pattern to verify if the tweet actually came from original user or not using TypingDNA's /match API endpoint. If yes, a relationship called VERIFIED is created from the user node to this tweet node.
UNVERIFIED_RELATIONSHIP
When the user tweets from his phone we vet it against their onboarding pattern to verify if the tweet actually came from original user or not using TypingDNA's /match API endpoint. If no, a relationship called UNVERIFIED is created from the user node to this tweet node and an email is sent to registered email id to inform about this anomaly. If it was a false positive the user can report it in the email that we sent. This pattern will now be considered as a verified pattern and it will be useful to compare against the future tweet patterns.
TWEET_SIMILAR_RELATIONSHIP
We generally compare every tweet pattern with all users onboarding patterns. This will create a relation between user and the tweets which are mentioned above as VERIFIED or UNVERIFIED. In addition to this, the tweets will now also point to inidvidual users. In case an impostor tweets from your account (identity theft) we can directly pin point the user(s) who might have tweeted it. This relationship is identified as TWEET_SIMILAR relationship.
This is the tweet-user network graph we built using neo4j which can be queried using CQL. We have built four types of relationships using these two types of nodes. More types of nodes and relationships can be established as per the needs.
Let's understand this better -
- Use case #1
yaswant is an ordinary user who is casually using his phone to tweet his own tweets which are being verified using TypingDNA.
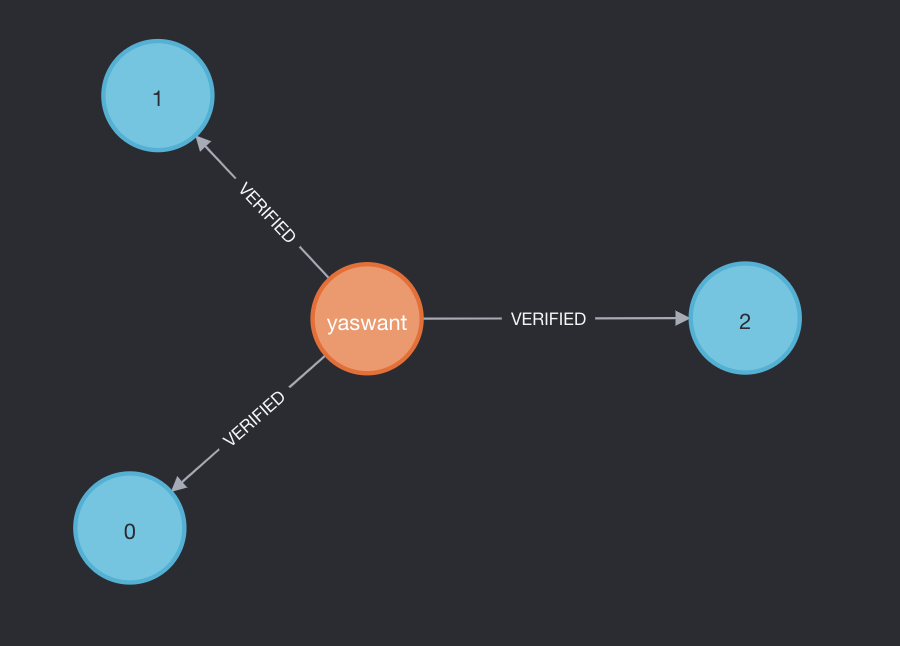
MATCH (n:User {name: "yaswant"})-[r]-(t:Tweet) RETURN n, r, t
Analysts can query using cypher query language in order to visualize the original user’s tweets, we can see that the ‘yaswant’ tweets here are verified because it came from his actual phone and account. It was typed by him and it got verified using TypingDNA with the confidences between his tweet patterns and onboarding patterns shown.
- Use case #2
yaswant and minosai are two users. yaswant has tweeted a tweet represented by node 0. This relationship was established using TypingDNA. Now let's assume yaswant tweet-0 get's flagged for fake news, we can now find all the other accounts that the user has. This will help us to curb fake news.
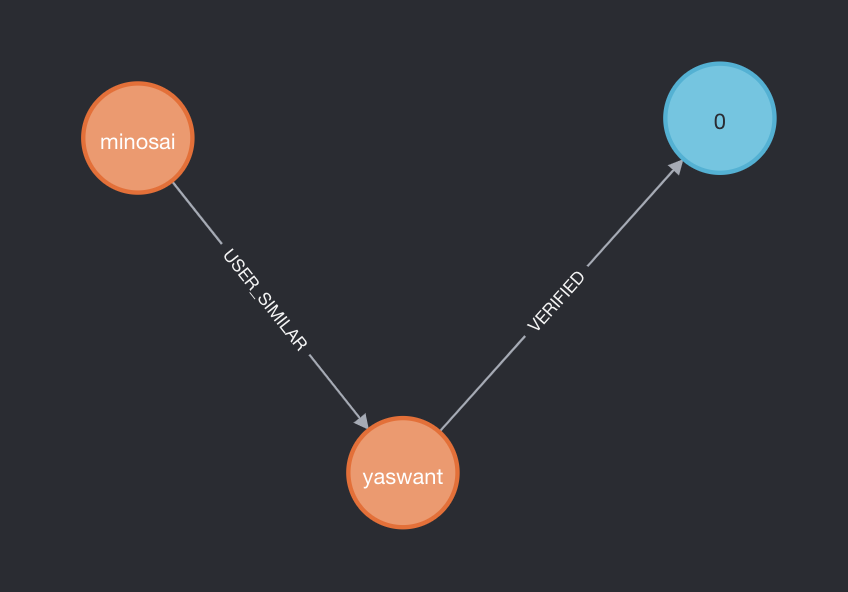
minosai and yaswant are user nodes. 0 is the first tweet by yaswant.
MATCH (n:User {name:"yaswant"})-[:VERIFIED]-(t:Tweet {flagged:true, tweet_id: "1"})
MATCH (u:User)-[:USER_SIMILAR]-(n)
RETURN n, t, u
Analysts can query using cypher query language (CQL) in order to visualize a flagged-and-verified-tweet from yaswant in order to find fake accounts which are used by yaswant. Here minosai and yaswant have a relationship called USER-SIMILAR which identifies them as fake accounts.
- Use case #3
We’ll be making a close attempt of what happened on July 15, 2020 on Twitter. The likes of Apple, Bezos, Musk, Gates, Obama, Trump, Biden all of their accounts were compromised. The suspects of this scam are still on the run as of now.
• Let's there are two verified accounts - trump and bezos .
• Initially trump has two tweets (0 and 1) and bezos has one tweet (0).
• Now a hacker joins our platform and posts a normal tweet.
• He got bored and got access to trump and bezos twitter accounts and just decided to post a BTC scam tweet coz why not.
Now our platform can be used to find the impostor among us.
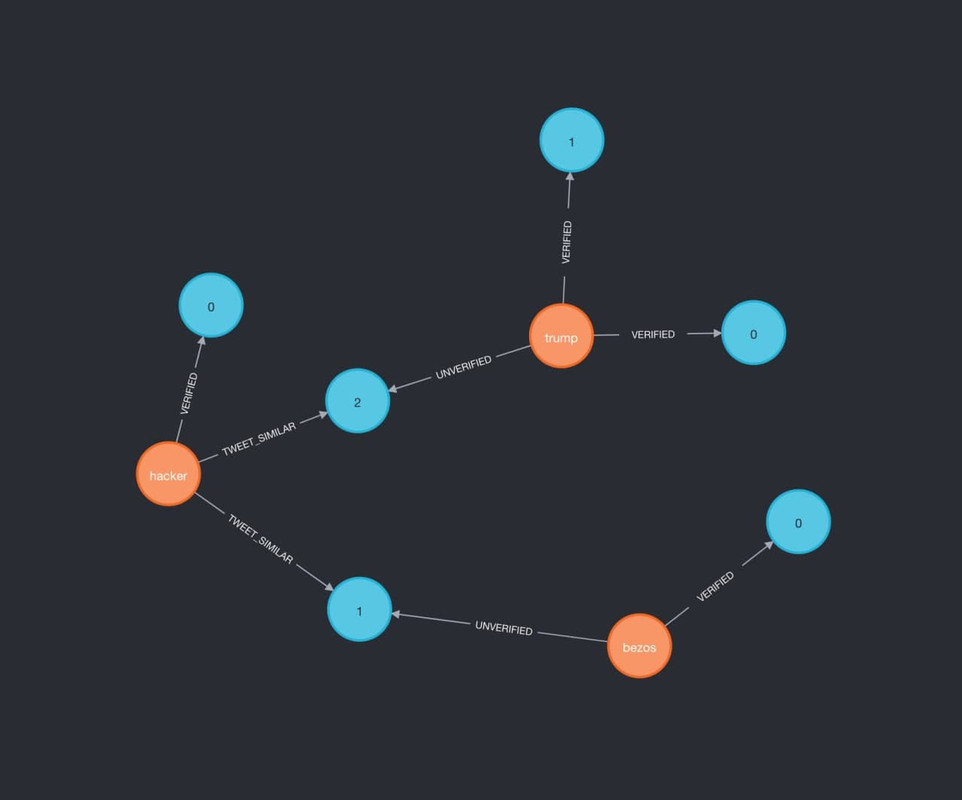
MATCH (t:Tweet {tweet_id:"1"})-[r1:UNVERIFIED]-(u1:User)
MATCH (t)-[r2:TWEET_SIMILAR]-(u2:User)
RETURN t, r1, u1, r2, u2
System Architecture
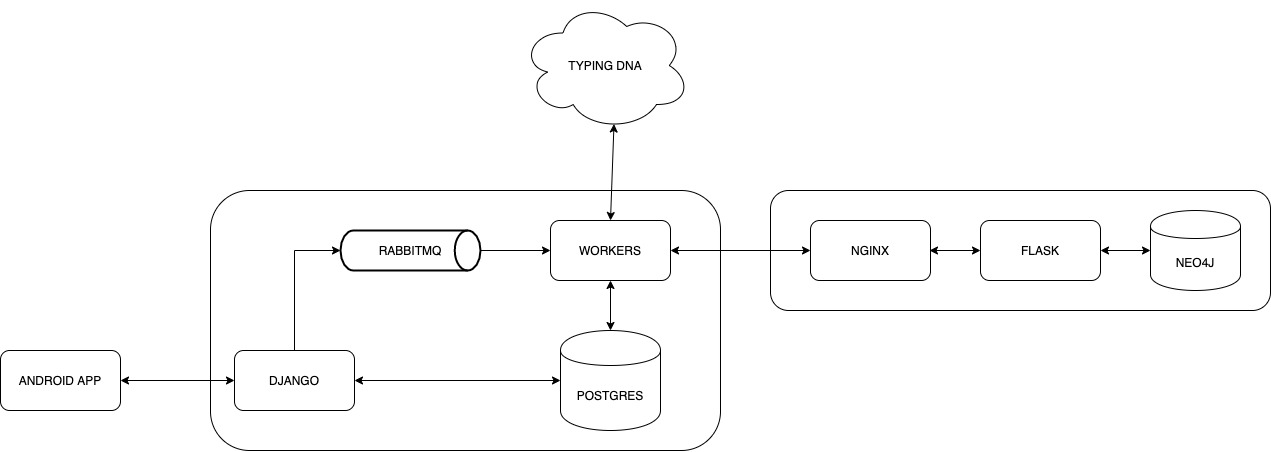
Challenges we ran into
Our platform is primarily an Android application which uses TypingDNA's Android SDK.
- It would've been convenient if the SDK had been published on Maven central repository or such.
- We experienced a lot of false negatives than we expected. Variations caused by Android keyboards, orientation of the phone, dexterity etc. We needed a work around to mitigate that. We had to combine multiple typing patterns of the same user's tweets to get better matches in future.
Remote hackathon:
- Because of the pandemic everyone had to work from their home and it was really difficult coordinating among us (pun intended).
- We had three moving component - Android app, Backend microservice, Graph microservice. Integrating required a lot of communication and planning.
Brainstorming:
It took us a lot of time to come up with ideas which had proper social impact and which were not simple authentication app.
Accomplishments that we're proud of
Our first remote international hackathon as undergraduates.
It rekindled our hackathon spirits during this lockdown. We were all able to communicate and coordinate as and when needed.
What we learned
It was fascinating to experience TypingDNA's authentication methods which are comparable with existing industry leading authentication techniques. We realised the importance of team work, hard work, smort work.
Reality is often disappointing - Thanos.
What's next for Among Us
In future we can expand this same project to cover:
- ML approaches for fact-checking the news information.
- Track fake account communities using Community detection algorithms.
- We can narrow down the search space for finding impostors by the user location, the language they read/write tweets, IP addresses etc.
- Can be extended for more social media platforms.
P.S
- Among US (game) title, idea and solely owned by InnerSloth Developer & Publisher. The name has been borrowed for fictional purposes, for the sake of hackathon only.
- The logos, UI/UX, brand name (Twitter) solely have been borrowed as a fictional entity for the sake of explanation of the idea.
- The Social Dilemma clipping placed in the demo video is for demonstration purposes only. The copyright of those clippings belong only to Netflix and corresponding owners.











Log in or sign up for Devpost to join the conversation.