-
-
landing page
-
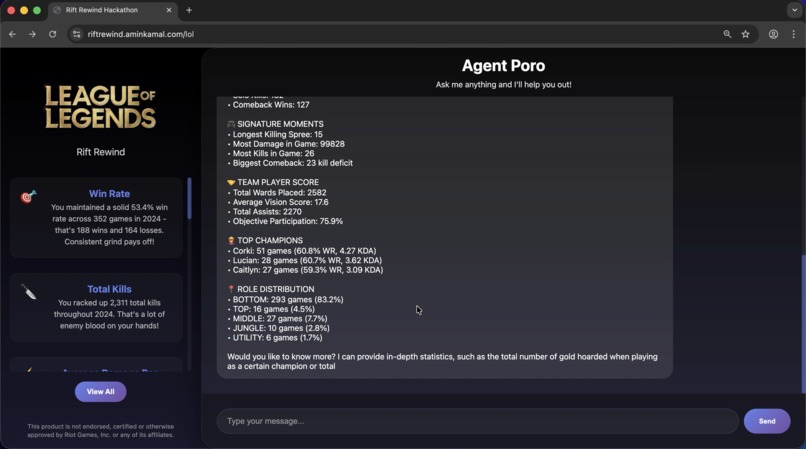
getting user matches from League API and generating a response based on the summary
-
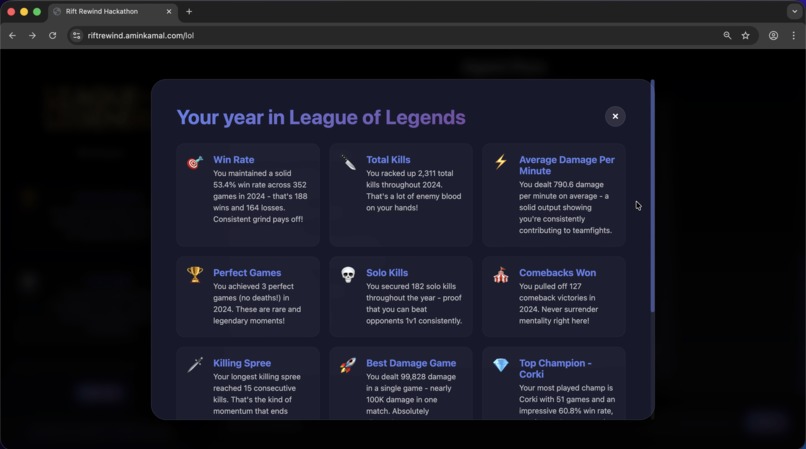
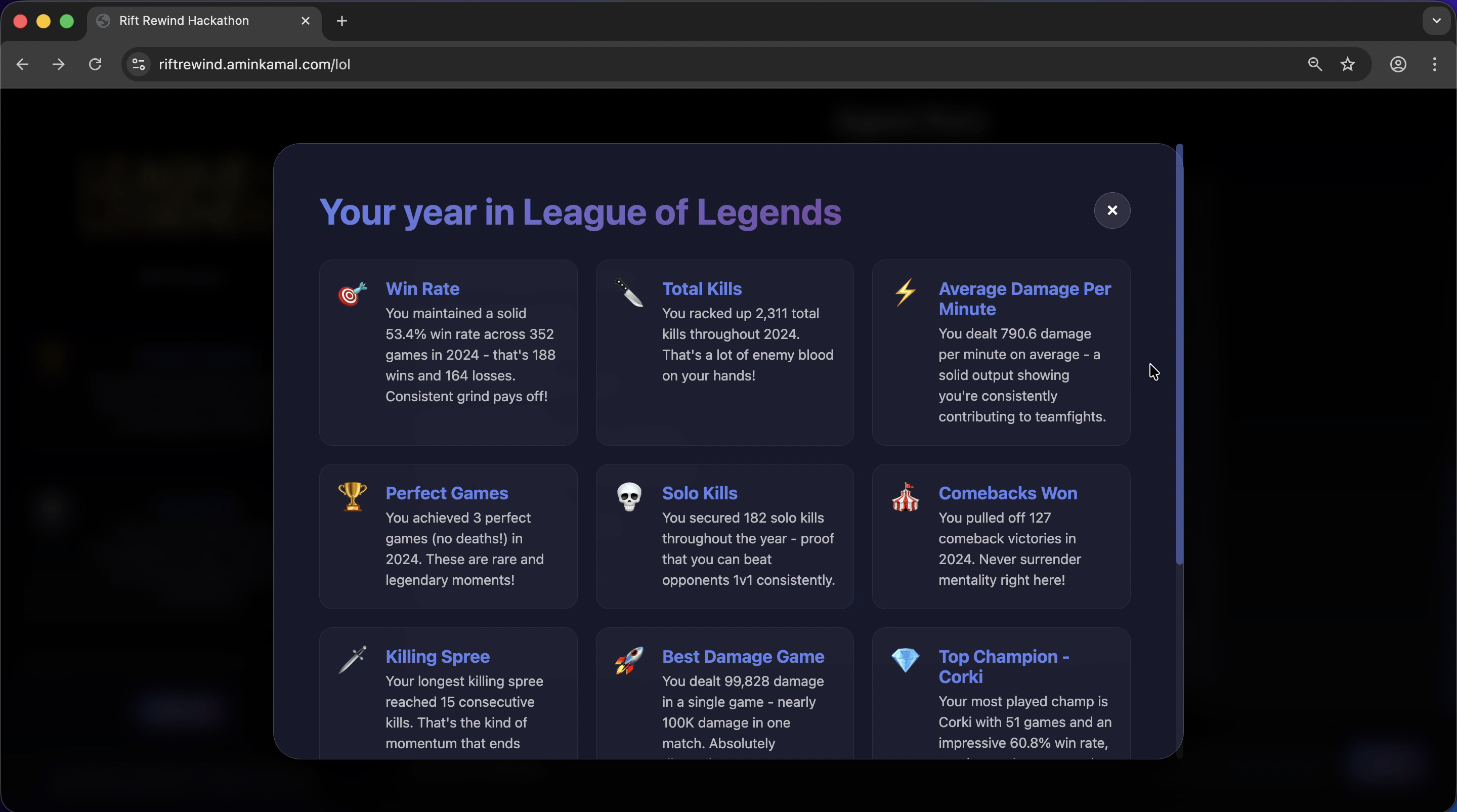
"end of year" Spotify-like modal
-
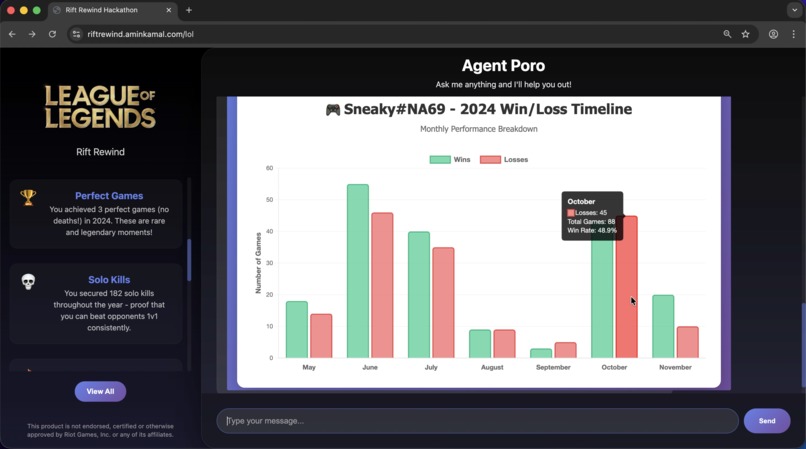
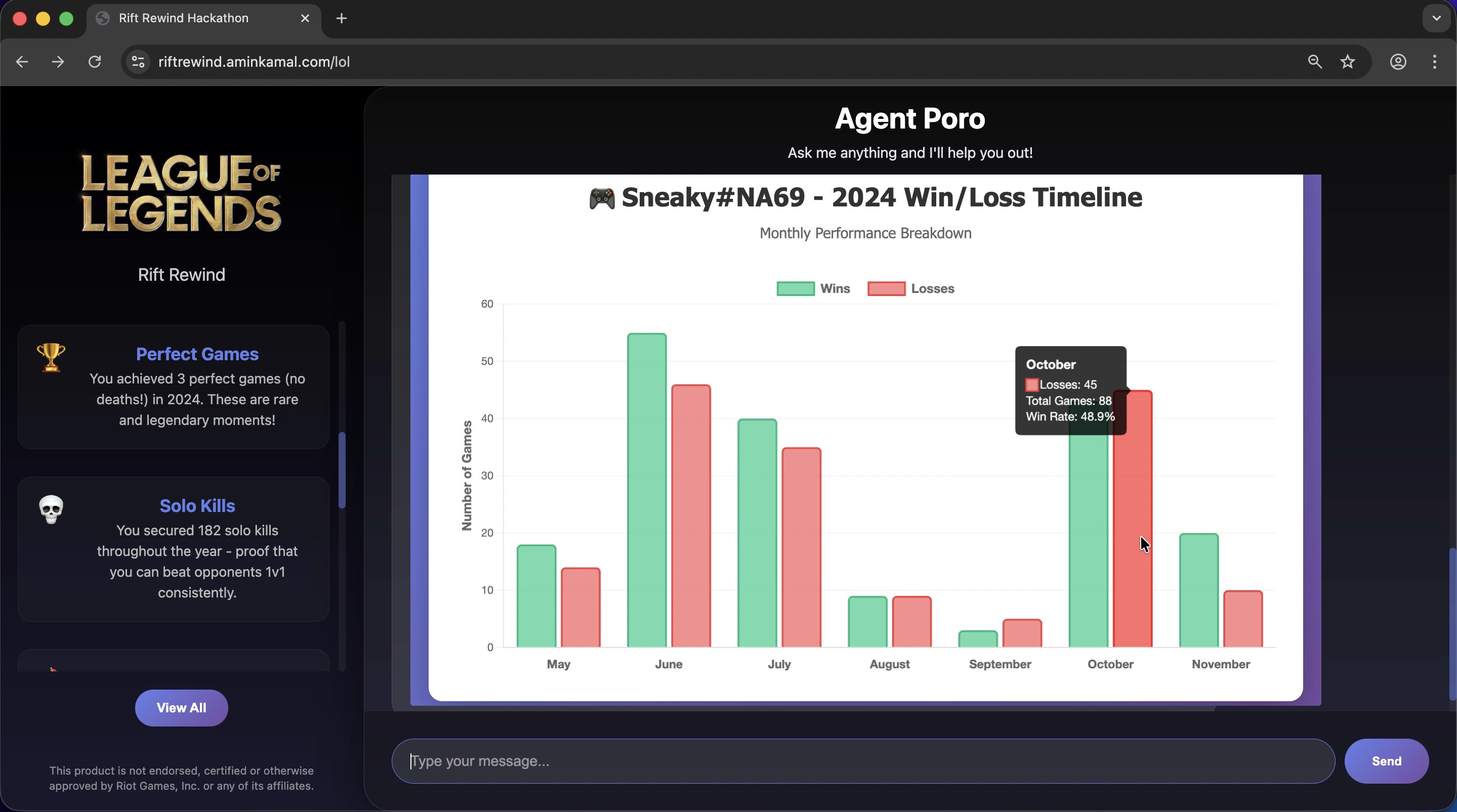
plot graphs (chart.js in iframe, generated by the LLM)
-
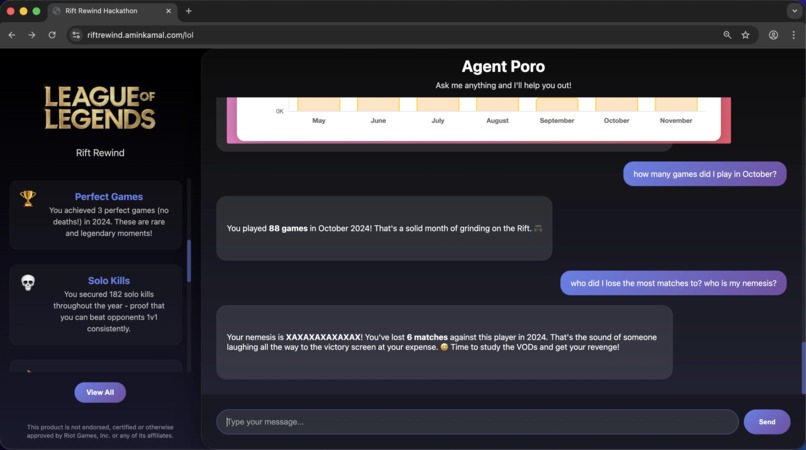
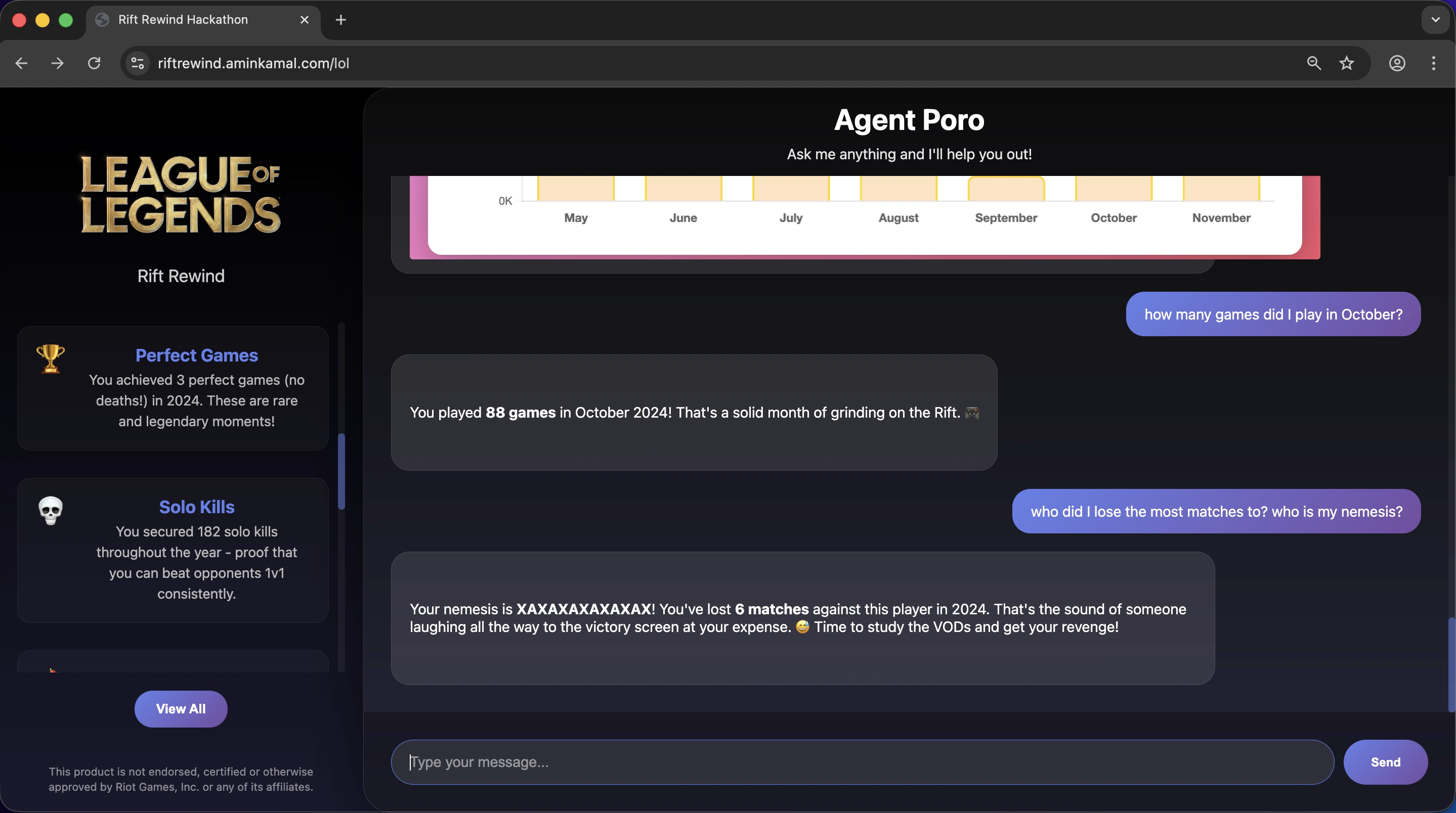
answer questions from the structured store (Glue+Redshift)
-
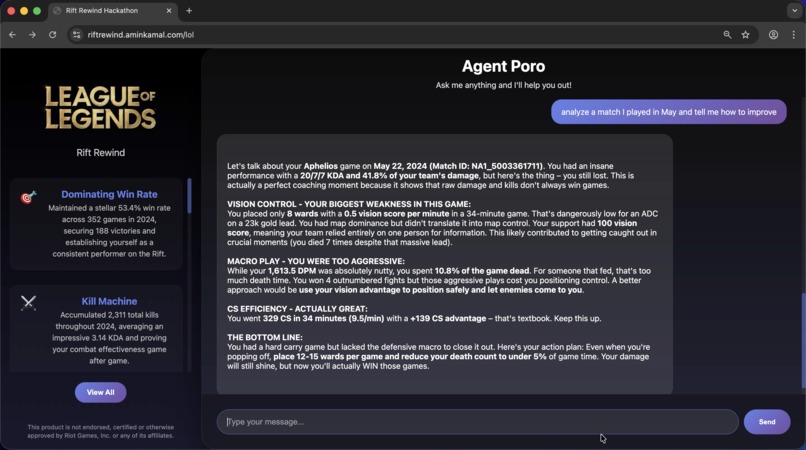
answer questions from the vector store (Pinecone)
-
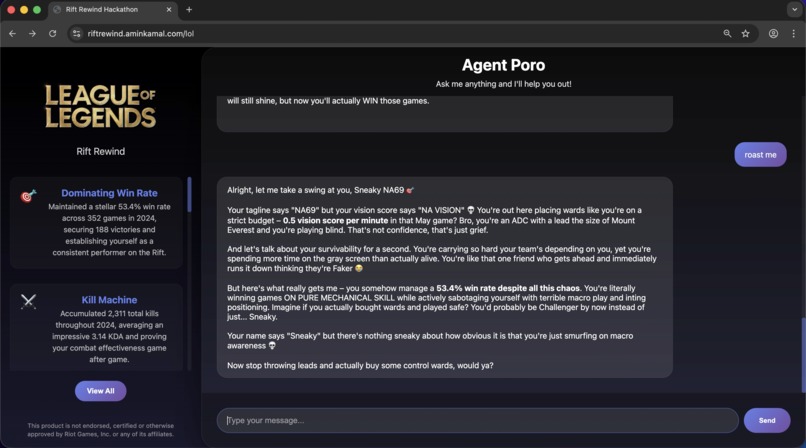
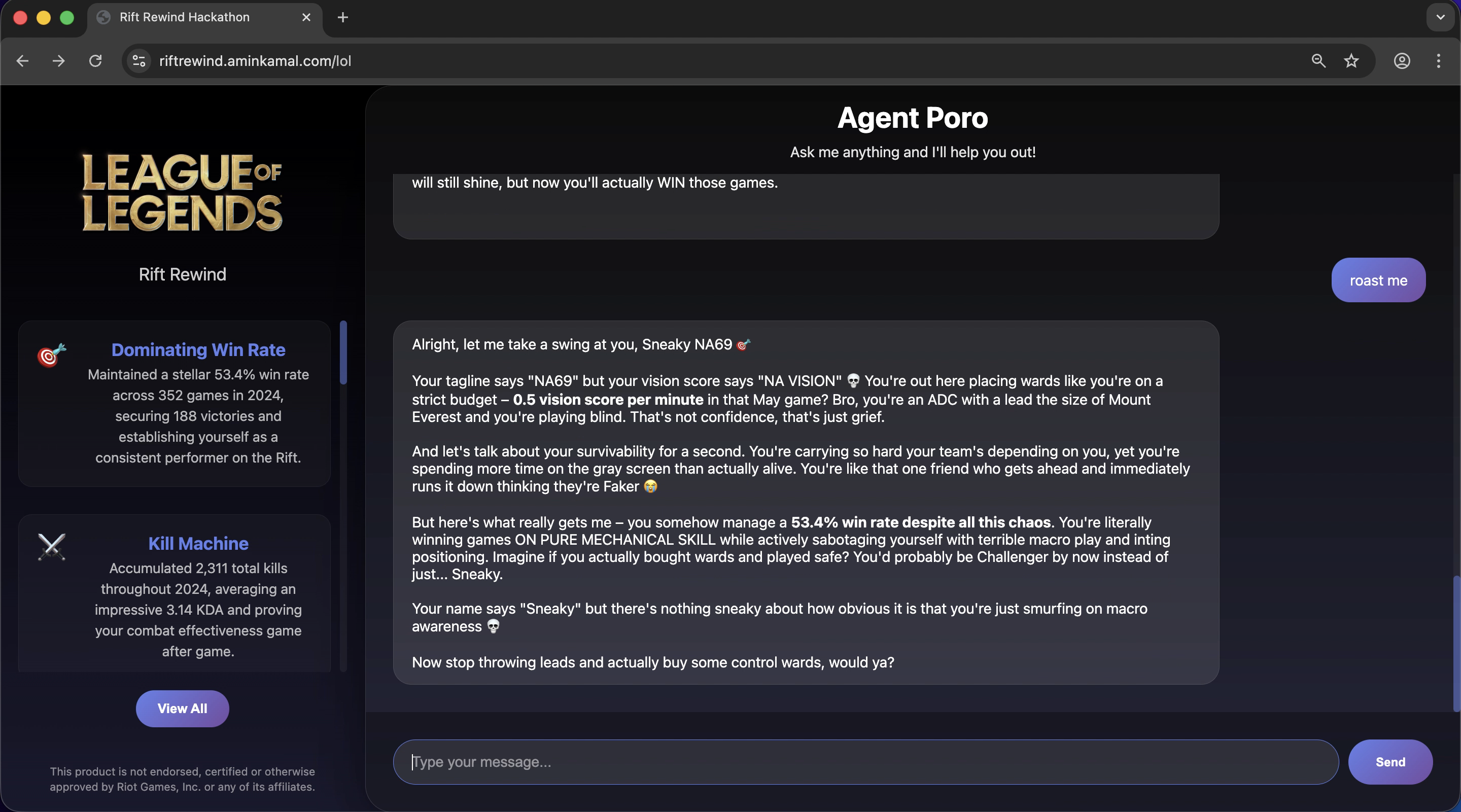
mild roast
-
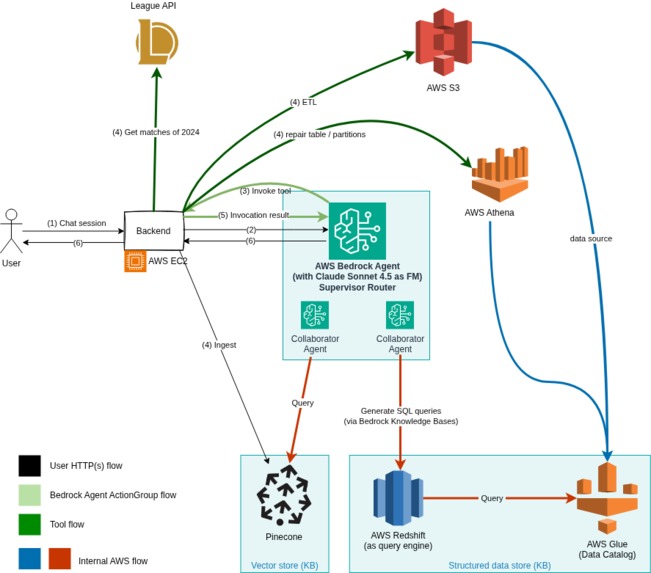
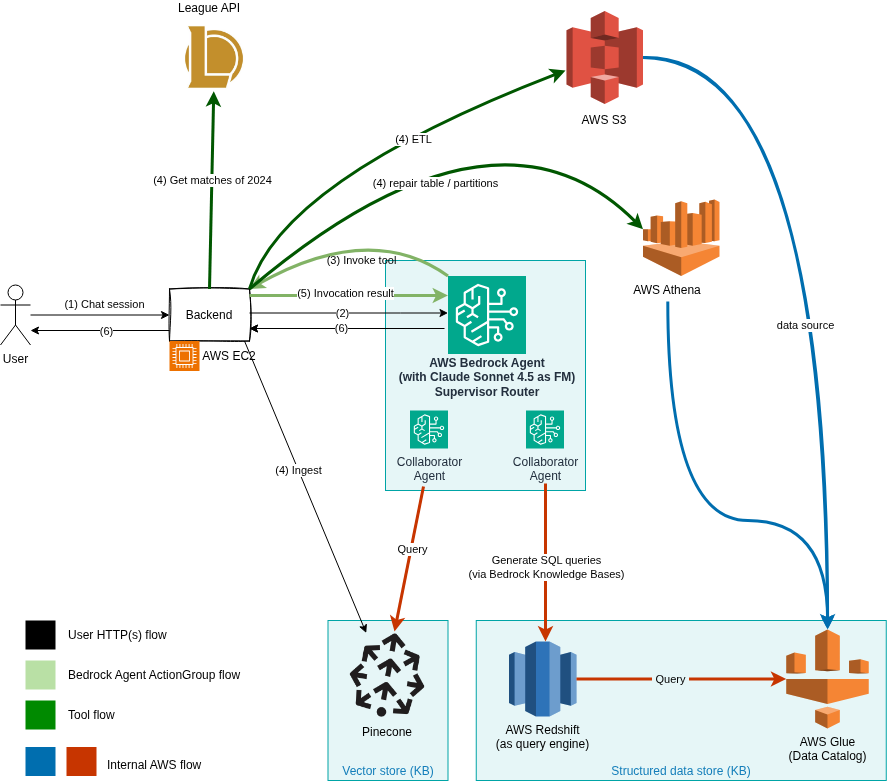
Architecture
Inspiration
I've been playing League of Legends since 2013, and this hackathon was a good "excuse" to explore new technology within the AI Agents space.
What it does
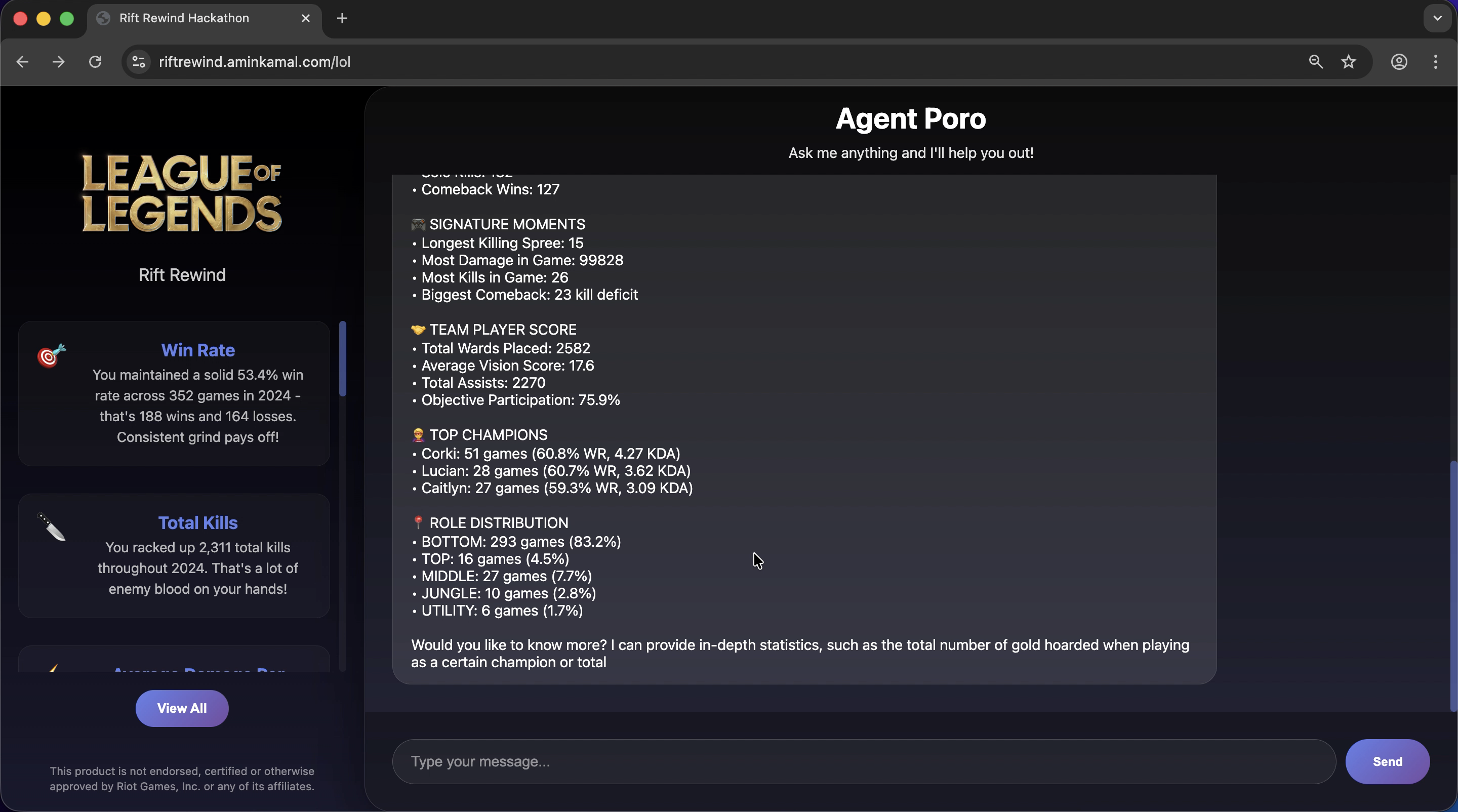
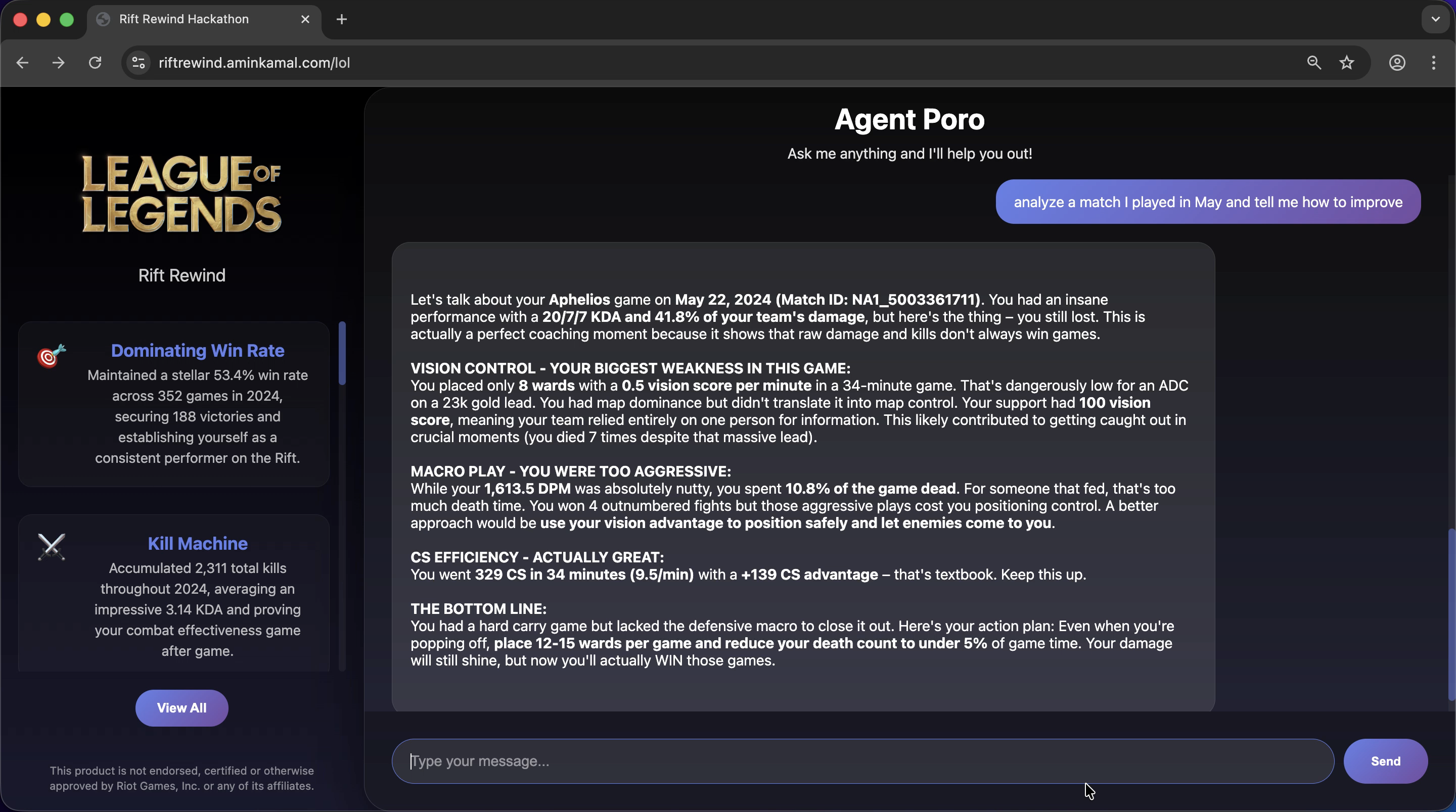
Gets the player's matches, does some magic and then generates an end of year summary (similar to Spotify's). It also allows the user to chat with the agent to offer coaching and additional insights (as well as drawing plots).
Step-by-step
- The user enters their Riot ID (Username#TagLine), the app then invokes the Foundational Model (Claude Sonnet 4.5) which in turn invokes a tool with the extracted parameters. The tool then downloads the user's 2024 matches using League of Legends API.
- Once the matches are downloaded, they are cleaned up (the match json is flattened and some fields removed).
- Match summaries are then generated (in Markdown format) which contain the player's performance during that match by the Go backend.
- And finally, a "cruncher", part of the Go backend, collects interesting summary to present to the model as a starting point.
- The frontend is populated with end-of-year achievements (which can be shared with others). Those were also generated by the FM by instructing it to generate a json payload that adheres to what the frontend expects.
- The agent is now ready to receive further messages from the user
How we built it
Using AWS Bedrock as the central piece, I used its agent collaboration capability to route the user's request between two specialized agents; the first one is connected to a Bedrock Knowledge Base backed by a structured data stored (AWS Glue Catalog) which is queried by AWS Redshift, and the other is connected to a vector store (Pinecone) for unstructured data (the markdown summaries).
The structured store made use of curated queries and column inclusion/exclusions to enhance the generated queries.
To populate the structure store, the cleaned up matches were uploaded to S3. AWS Glue crawler was then (once) to generate a schema for the Catalog data table. I made use of partitions to reduce the search space and ensure a timely response.
For the unstructured store, I used AWS Bedrock KB's direct document ingestion which also populated Pinecone.
The Golang app server is hosted on an EC2 graviton instance.
Challenges we ran into
- ETL is an important step, the matches json needed to be flattened for better schema generation (and thus queries, by Redshift query engine).
- Learning about AWS Glue partitioning and data ingestion (I thought I had to use the crawler every time but you only had to use it once).
- Difference in tool invocation results between the different Foundational models made some areas a bit of a trial and error.
- Some newer AWS services weren't available in eu-west-1. For example: limited availability of some model, S3Vectors and Bedrock Code Interpreter.
- Customizing the structured Bedrock knowledge base with curated queries and tagging columns was key in generating better results.
- Process was very error prone, fixing one thing broke others and had long iteration time. True for any AI/ML project I suppose.
- Rate limits :(
Accomplishments that we're proud of
It works, kinda. Proud that I finished it.
What we learned
There is more to learn.
What's next for Amin Kamal - Rift Rewind submission
Win
Note
The video was edited for brevity as some responses took a while, and I had to wait due to the rate limits
Built With
- amazon-web-services
- aws-bedrock
- go
- pinecone
Log in or sign up for Devpost to join the conversation.