-
-
-

Dataloader
-
Model Declaration
-
Model Evaluation



Inspiration
As you order items from Amazon, a section lower on the screen suggests other items that might be of interest. Similarly, your video-viewing choices on Netflix influence the videos suggested to you for future viewing.
All this is possible because of the availability of data-collection systems and improvements in recommendation engine algorithms.
There are a few ways to deal with the challenge of designing recommendation engines. One is to have your own team of engineers and data scientists, all highly trained in machine learning, to custom design recommenders to meet your needs.
However, this approach is not feasible for smaller companies and startups as it is quite resource-intensive and might not be suitable in the initial stages.
To tackle this problem, we built a tool that will help developers who do not have a machine learning background, easily build and deploy a recommendation engine in their application or product.
What it does
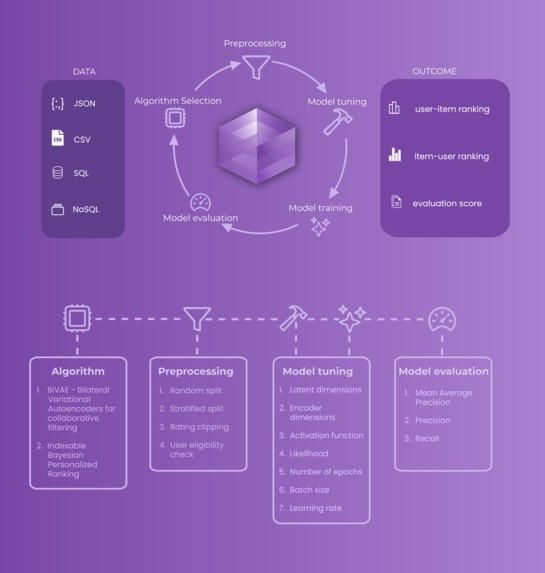
Amethyst is a low-code, easy-to-use, GPU-powered recommender engine generator based on PyTorch. It requires only three parameters to rank/predict the best items for users and vice-versa
User ID (a unique identifier for each user) Item ID (a unique identifier for each item) User-Item Ratings (user-item rating/interaction scores) Since all the underlying data operations are being handled by Pandas, amethyst supports a wide variety of database/data storage formats like SQL, NoSQL, CSV, TSV, etc.
The resultant recommendation scores are also obtained as a Pandas Dataframe, which helps in a flexible integration with your application.
Getting Started
This is an example of how you can generate your own collaborative recommendation engine. To get a local copy up and running follow these simple example steps.
Prerequisites
- Python>=3.7
Installation
- Clone the repo
sh git clone https://github.com/radioactive11/amethyst.git - Create and activate virtual environment
sh python3 -m venv venv source venv/bin/activate - Install the tool
sh python3 setup.py install
Usage
A recommendation engine can be generated in 4 easy steps:
- Import the data
- Select an algorithm
- Train the model
- Evaluate the model's performance
Data Split ⚗️
from amethyst.dataloader import split
df = pd.read_csv("./movielens100k.csv")
df_train, df_test = split.stratified_split(
df,
0.8,
user_col='userID',
item_col='itemID',
filter_col='item'
)
Load Data 📥
from amethyst.dataloader import dataset
df = pd.read_csv("movielens100k.csv")
# from Data Split
df_train, df_test = split.stratified_split(df)
train = dataset.Dataloader.dataloader(df_train.itertuples(index=False))
test = dataset.Dataloader.dataloader(df_test.itertuples(index=False))
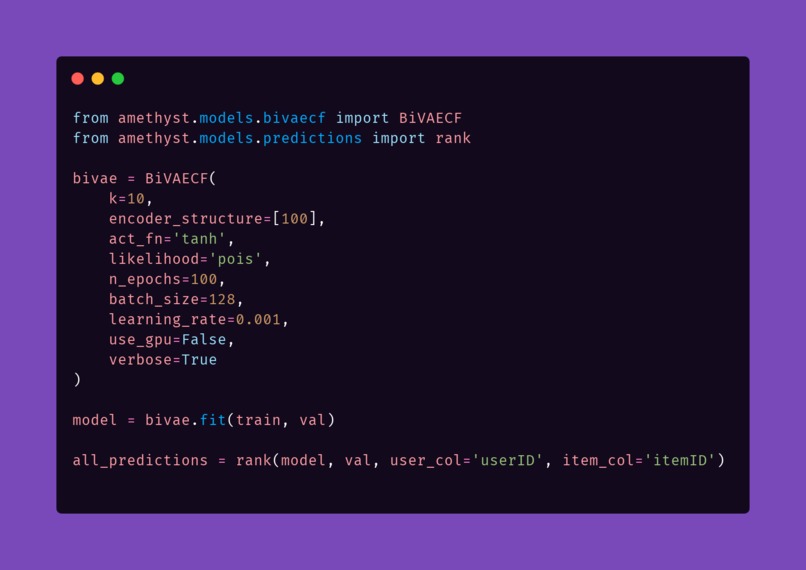
Train (BiVAECF) ⚙️
from amethyst.models.bivaecf.bivaecf import BiVAECF
import torch
bivae = BiVAECF(
k=50,
encoder_structure=[100],
act_fn=["tanh"],
likelihood="pois",
n_epochs=500,
batch_size=256,
learning_rate=0.001,
seed=42,
use_gpu=torch.cuda.is_available(),
verbose=True
)
bivae.fit(train, test)
bivae.save("model.pkl")
Train (IBPR) ⚙️
from amethyst.models.ibpr.ibprcf import IBPR
import torch
ibpr = IBPR(
k=20,
max_iter=100,
alpha_=0.05,
lambda_=0.001,
batch_size=100,
trainable=True,
verbose=False,
init_params=None)
ibpr.fit(train, test)
ibpr.save("model.pkl")
Predict/Rank 📈
from amethyst.models.predictions import rank
from amethyst.models.bivaecf.bivaecf import BiVAECF
bivae = BiVAECF(
k=50,
encoder_structure=[100],
act_fn=["tanh"],
likelihood="pois",
n_epochs=500,
batch_size=256,
learning_rate=0.001,
seed=42,
use_gpu=torch.cuda.is_available(),
verbose=True
)
bivae.load("mode.pkl")
predictions = rank(bivae, test, user_col='userID', item_col='itemID')
# predictions is a Pandas Dataframe
predictions.to_csv("predictions.csv", index=False)
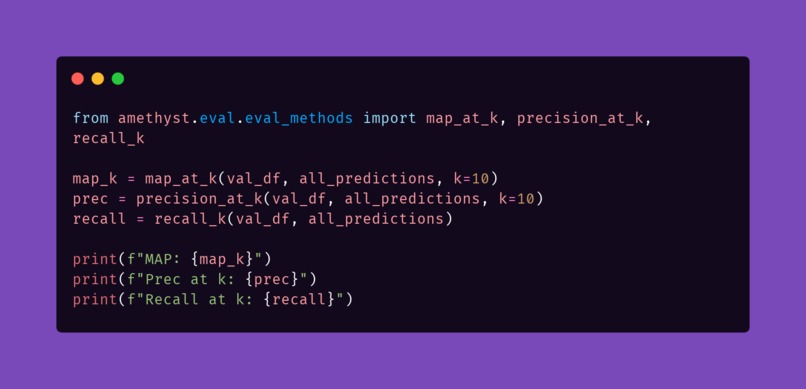
Evaluate 📈
from amethyst.models.predictions import rank
from amethyst.eval.eval_methods import map_at_k, precision_at_k, recall_k
bivae = BiVAECF(
k=50,
encoder_structure=[100],
act_fn=["tanh"],
likelihood="pois",
n_epochs=500,
batch_size=256,
learning_rate=0.001,
seed=42,
use_gpu=torch.cuda.is_available(),
verbose=True
)
bivae.load("mode.pkl")
predictions = rank(bivae, test, user_col='userID', item_col='itemID')
eval_map = map_at_k(test, predictions, k=10)
pk = precision_at_k(test, predictions, k=10)
rk = recall_k(test, predictions)






Log in or sign up for Devpost to join the conversation.