
Inspiration
With the rise of ‘fake news’ and increasing distrust of the media, there exists a growing need for more consistent and reliable metrics to judge and evaluate news sources, particularly those that report information on events in the political realm. Local newspapers have remained relatively reliable in the public eye due to their accessibility and relevance to people’s daily lives; however, local news organizations are also susceptible to political bias despite their smaller, more personal focus. In addition, there are an alarming number of local stations operating under a larger umbrella (such as those owned by Sinclair Broadcasting Group) that, though have a high degree of accessibility, deliver standardized, biased news. We hope to provide a tool that counteracts the negative effects of biased news by empowering readers to understand the partiality of the articles they read and form more informed political stances, potentially encouraging them to vote.
What it does
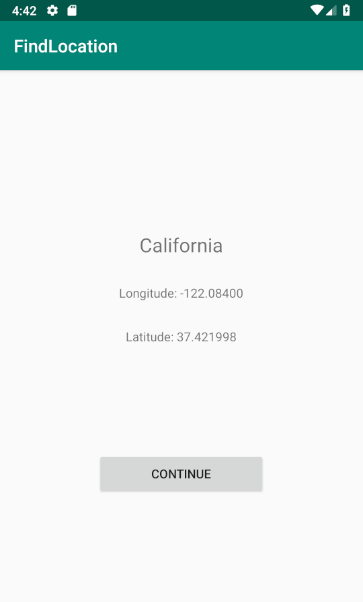
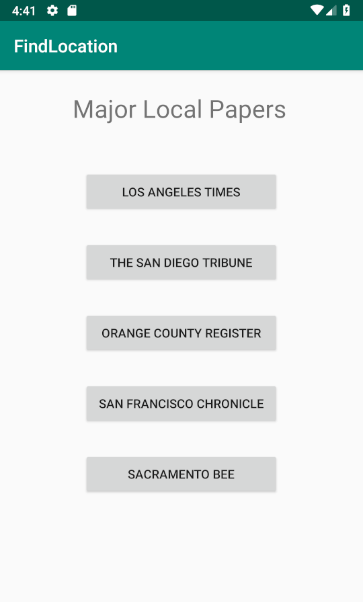
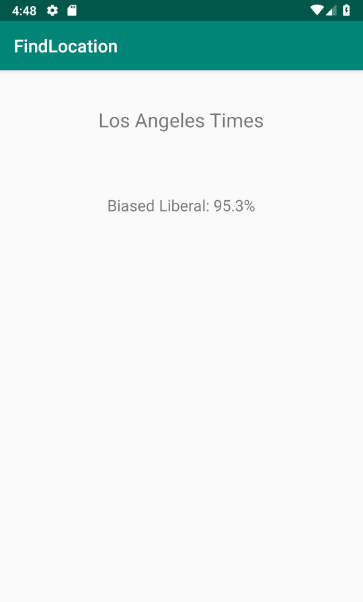
Our app categorizes local newspapers by general political affiliation based on the bias presented in articles from each respective newspaper. Based on the location of the user, several local newspapers are presented along with an average ‘affiliation’ rating from political articles scraped from their websites. Users can click to learn more about the newspapers and the issues and articles on which the rating was based on. Users can also submit links to custom articles to receive a political affiliation associated with that article.
How we built it
We used Android Studio and Java to build the app, relying on Google Cloud Services for data storage and their AutoML Natural Language processing models. We trained our models using self-identified conservative and liberal articles collected from a variety of sources.
Challenges we ran into
Our ideation process took several sharp turns, culminating in a restart-from-scratch late in the first day. Additionally, we noticed several ways we could improve the NLP model, including capabilities of detecting sarcasm and minimizing the effect of article length on the ‘affiliation’ rating.
Accomplishments that we're proud of
We gained experience working with Android Studio, implementing Google Cloud APIs, and learned more about natural language processing and sentiment analysis.
What we learned
This was the first time any of our members went through a development process, and as a consequence we had to adapt a lot on the fly.
What's next for AMBIAS
We hope to create a more robust NLP model by using a more diverse set of articles in our training process, in addition to the ideas mentioned above. We also hope to refine the interaction between the app and the machine learning model, as well as the user interface.

Log in or sign up for Devpost to join the conversation.