Inspiration
The idea for Amber, quite hilariously, grew out of an earlier idea for a hackathon project which took a video of a lava lamp as input and passed positions and sizes of blobs as parameters to an additive synthesis, such that the motion of the blobs would translate into slow morphing of the sound of the synth, for use as a virtual software tool for music creation. When we started to think about how we could generalize the process so that we could feed any video as an input, so that physical phenomena in one area of the video corresponded to changes in a certain frequency range in the synth, we realized that the method we had come up with for doing this had a completely different and completely unexpected application in the area of assistive technology, which eventually became our project, Amber.
What it does
Amber is a novel assistive technology which allows access to information contained in a visual field (in our project’s case, depth calculations from a stereographic video stream) via information embedded in the stereo timbre of a software synthesizer. This technology was developed in the context of making an assistive device for visually impaired people to be able to “see” by listening to fluctuations in the harmonics of a drone instrument (meaning constant pitch) which uniquely correspond to gradient information in a 2D visual field such as the light level across an entire scene or the depth of objects in the scene from the observer, which would be gathered using a stereo camera embedded in a wearable device. This would possibly allow for visually impaired users (whether this works in practice, we don’t know - this would require additional research) to develop an intuition over time for how to “read” the information embedded in the amplitudes of the harmonics in the stereo timbres which would grant users a form of partial vision.
How we built it
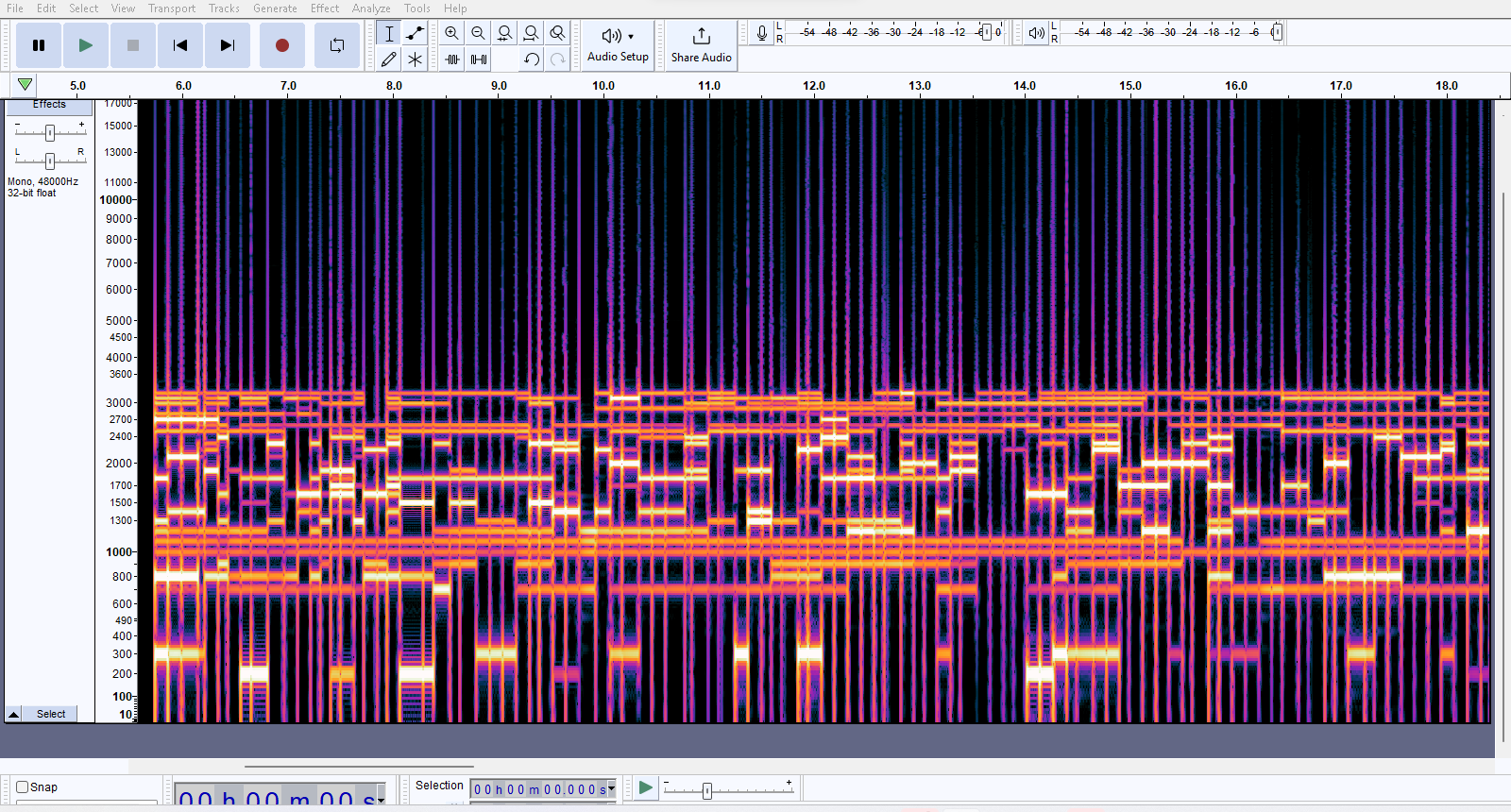
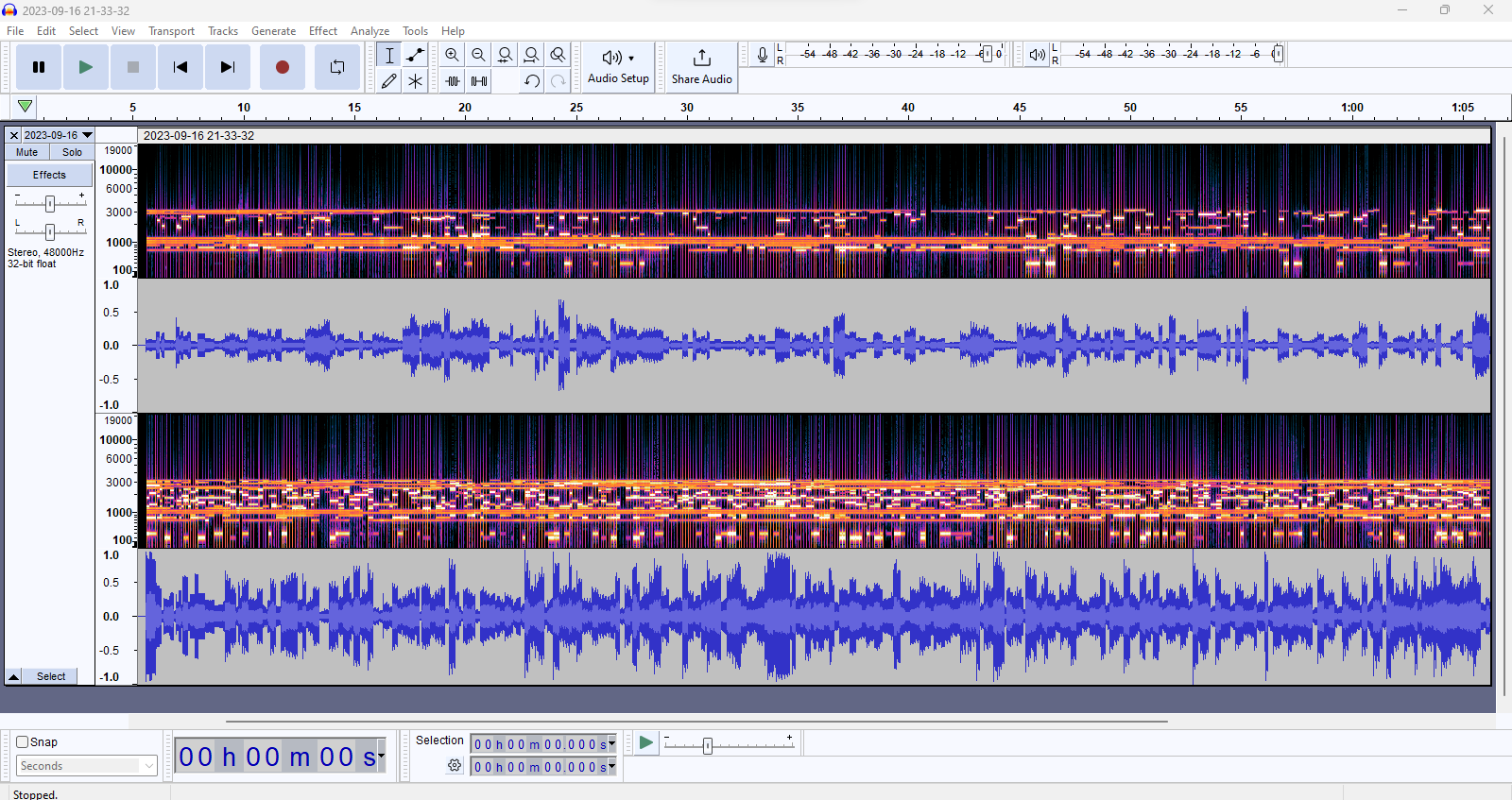
The technology receives a stereo video stream and information from a control surface - in our case this is a GUI - in the context of our intended use, this would be a physical controller linked via Bluetooth or similar to a wearable hardware device consisting of a stereo camera worn on the face via e.g. blackout glasses, a microphone for audio transparency (as ambient auditory information is still essential to general functioning for those with vision impairments), and stereo earbuds with a good frequency response. We take the video and calculate our desired information (for depth, using a block matching algorithm), rescale the output to a resolution such that all coordinates can uniquely correspond to an individually distinguishable harmonic of the drone, map the 2D space into a 1D array by splitting the image into halves (one for each ear) and using two Hilbert curves stitched together to cover each half (so that rough positions in the 2d space correspond to rough positions in the 1d space - which is to say similar areas sound similar when lit.) We then normalize the array so that the information contained fits with the range of a minimum and maximum amplitude per cell, use the normalized information to produce an amplitude for each harmonic, generate the individual harmonics and play them simultaneously using a signal processing library with rolling updates as the field of the desired information (in this case depth information per area on the screen) is updated in real time.
Challenges we ran into
When originally designing the program, we attempted to perform a depth calculation on input from a single camera, which, while possible, is extremely computationally expensive in practice and nowhere close to real time. We had to modify the design to take binocular video input (which we did not have the hardware to gather) which meant we had to use preexisting stereo video such as videos meant for playback in VR - however, because these are meant for VR, the video is distorted towards the edges which negatively impacted our ability to produce an accurate depth calculation on the input we had access to (we would need the proper hardware to produce such an input.) The team also experienced challenges given that the project was attempting to do something that had no obvious analogue - making sure that everyone was on the same page so that we could begin to break the project down into subtasks and delegate accordingly was by far the hardest part of the project and we had to push past impulses to scrap the project for something simpler.
Accomplishments that we're proud of
Given the project was, as far as we can tell, completely unique in its approach for finding a general solution for communicating image features to end users via sound with high information bandwidth, regardless of the potential it might have, we consider it a major success that we were able to orchestrate and implement the project as a team in the time span that we had, also given that we had to change the design of the project midway through and we did not have the hardware that we needed to be able to test it with a live feed.
What we learned
One of the most important reminders we received when working on the project was to have persistence and know when to push past the initial impulse to give up in the face of difficulties that may initially seem impossible to overcome. In our case, when we realized that trying to calculate an image depth with a monocular lens using ML was going to be too computationally expensive to do anywhere close to real time, we were considering scrapping the project - then we considered constructing a hardware device with two cameras in the configuration we needed for a short while before we realized we didn’t have the resources accessible, then we settled finally for using an existing video for the sake of the demo as our video stream. In the end we were able to complete the project with some slight modifications in scope and all of the important parts intact which we consider a success.
What's next for Amber: Color the World With Sound
What will come next for Amber is contingent on a few key things which we will need to research: those being the degree to which humans can distinguish between these harmonics in practice (affecting our potential information bandwidth), the degree to which people can learn to use the information provided effectively and develop a sense for what it corresponds to in the real world (i.e. can they “learn the language”) and the degree to which this technology, if it can exist, would actually be useful to people with visual impairment in practice. All of these things will inform where we go with the project - in any event we all have confidence that the project has potential, and is well worth continuing.








Log in or sign up for Devpost to join the conversation.