-
-
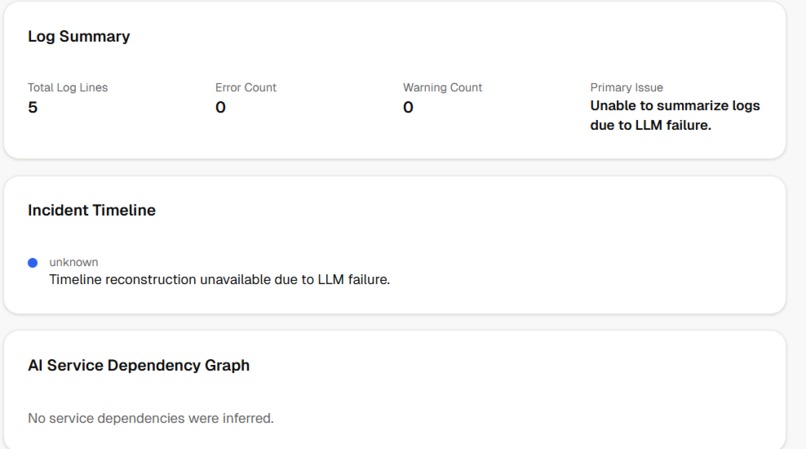
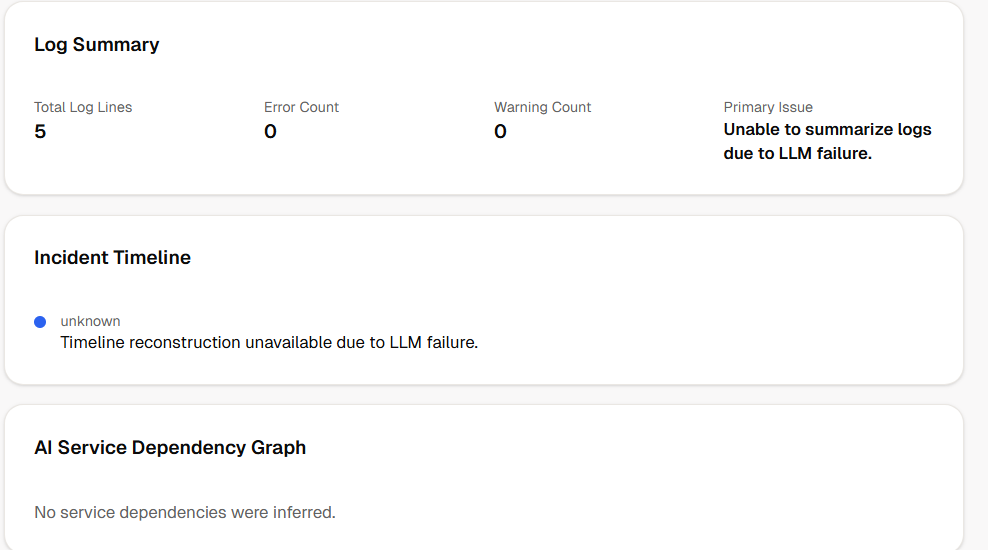
log timeline
-
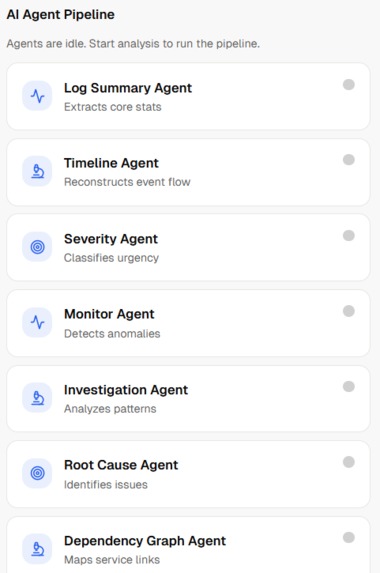
Working Agents
-
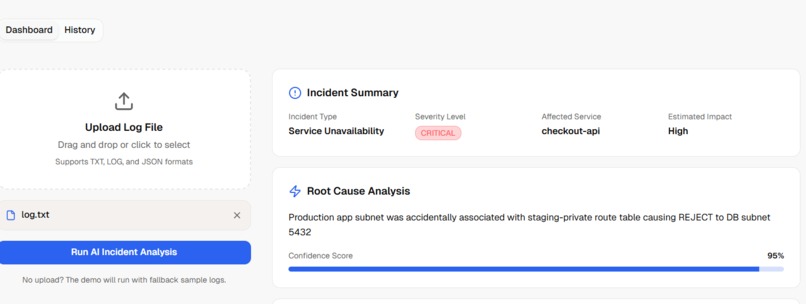
Log input
-
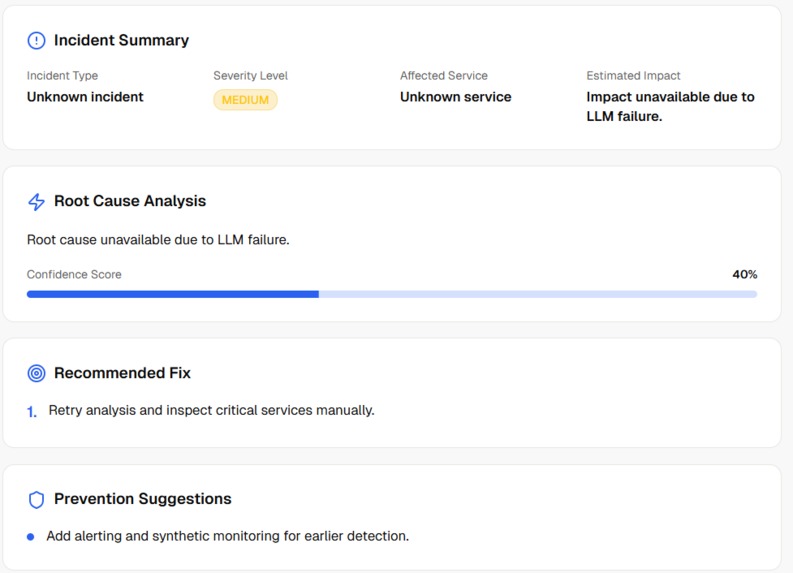
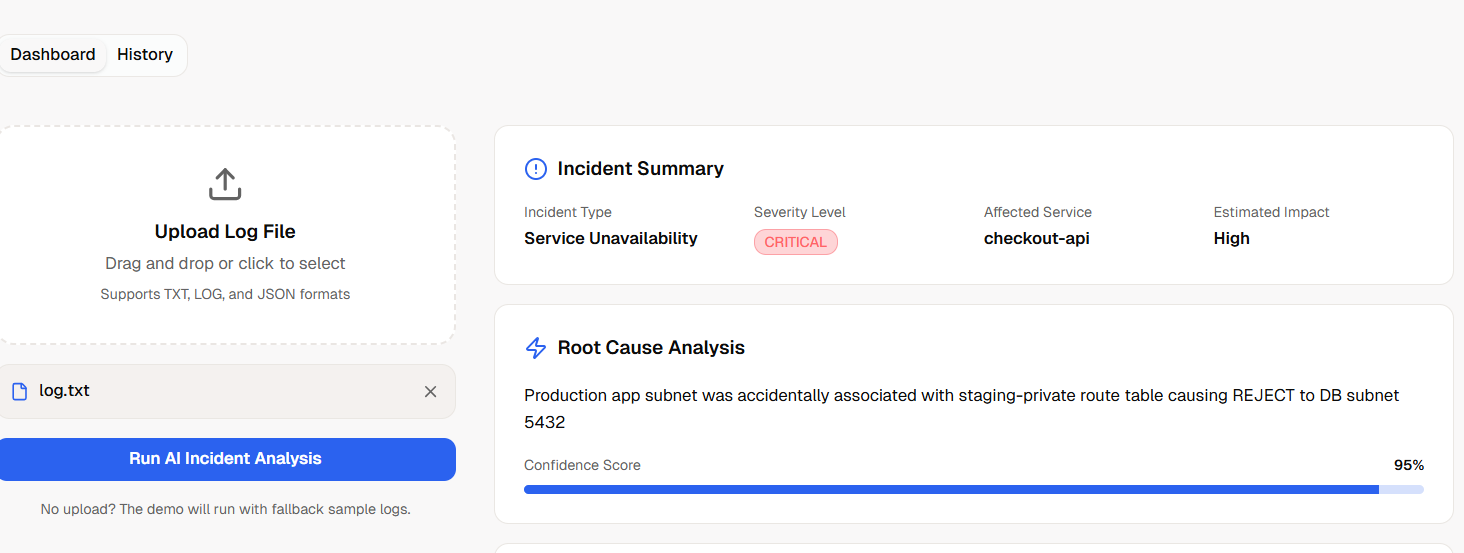
Incident information
-
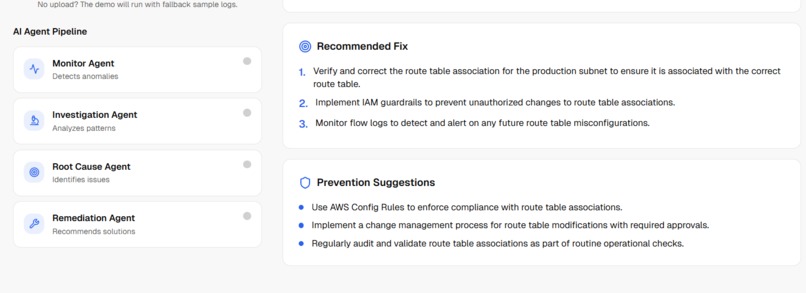
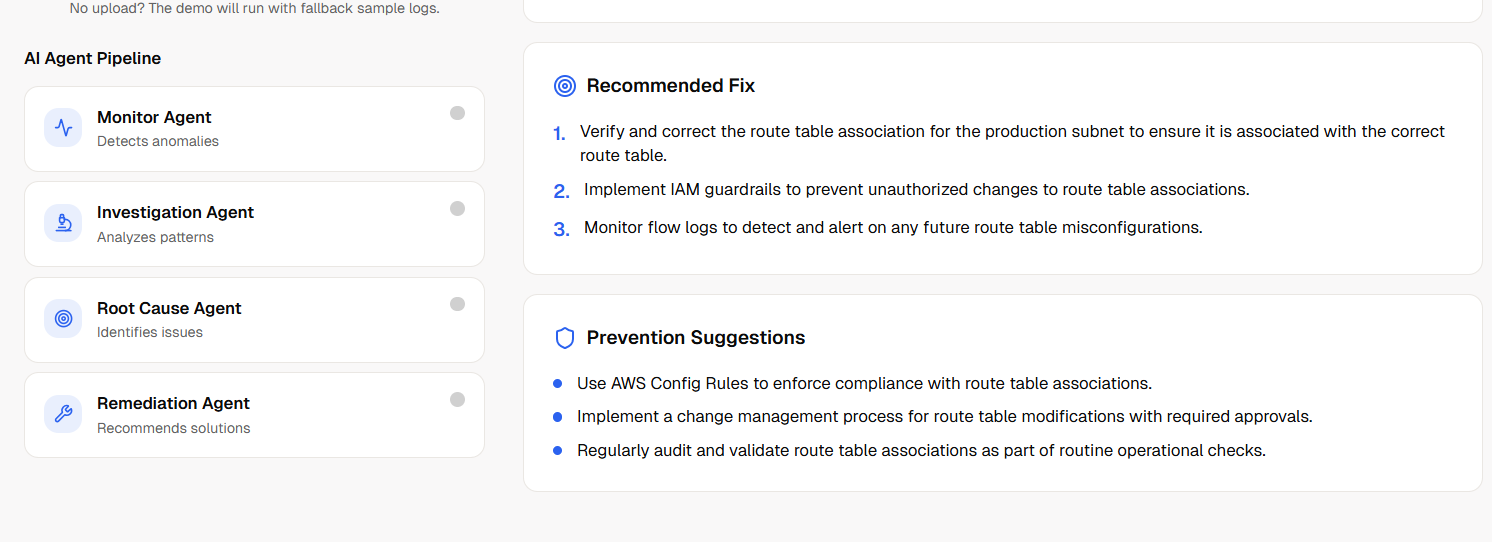
Nova Recommendation
-
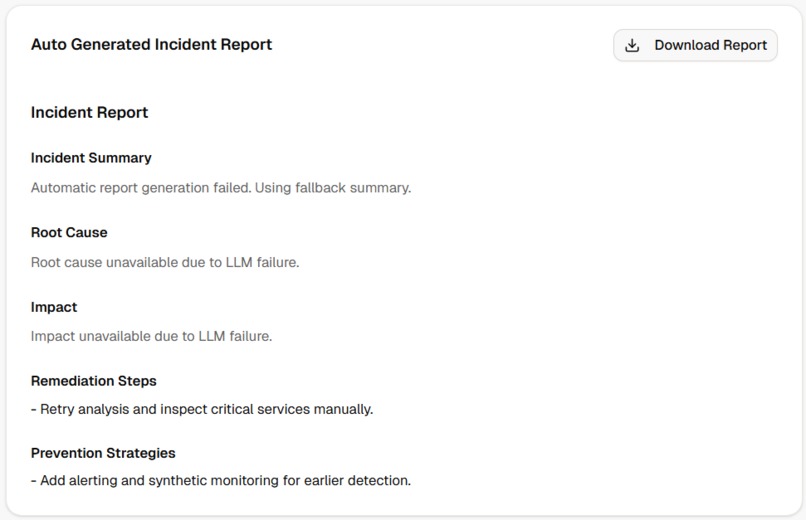
Overall Report Generation
-
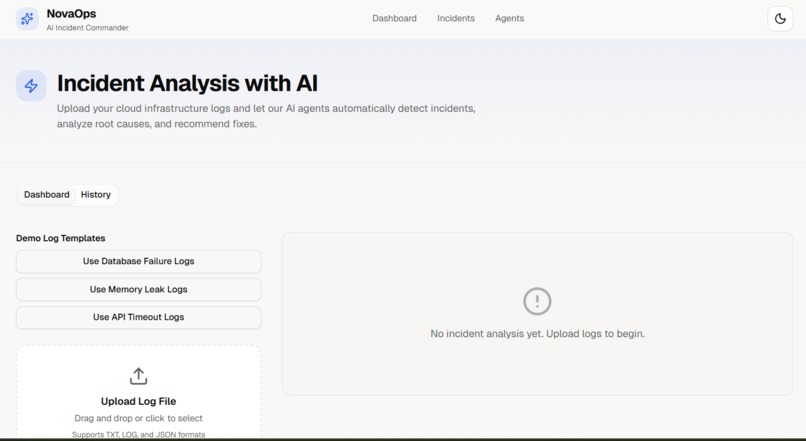
Log Input
Inspiration
Cloud incidents are noisy, stressful, and expensive. Most teams still jump between dashboards, raw logs, and chat threads while trying to answer the same urgent questions: What broke? How bad is it? What do we do now? We built NovaOps to turn that chaos into a guided AI incident command flow: upload logs, run specialized AI agents, and get a clear incident narrative with actions.
What it does
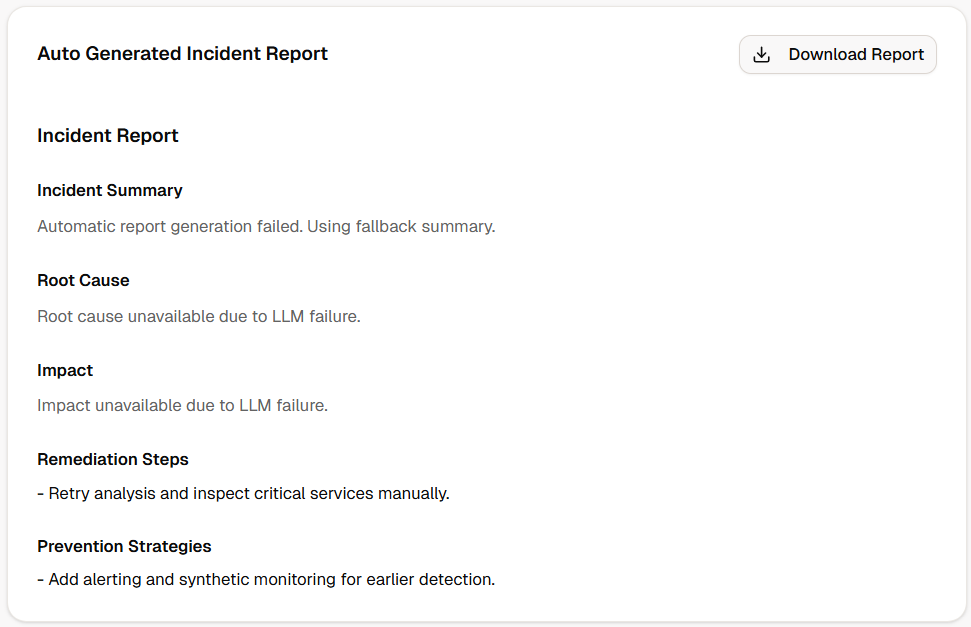
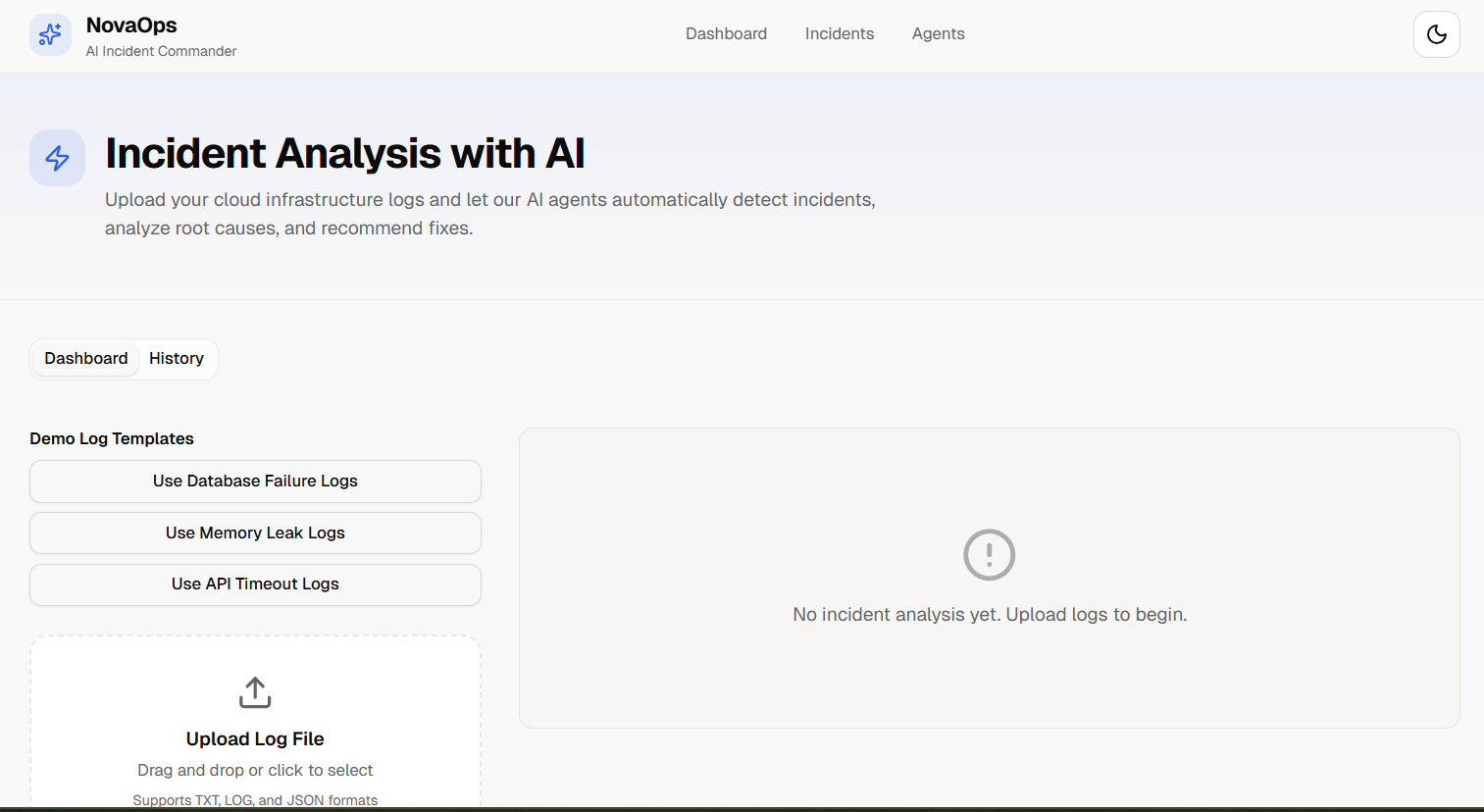
NovaOps — AI Cloud Incident Commander analyzes infrastructure/app logs and returns a full incident intelligence package: Detects anomalies and likely incident type Classifies severity (critical, high, medium, low) Reconstructs a timeline of major events Infers service dependency relationships Identifies probable root cause with confidence score Recommends remediation and prevention steps Generates a downloadable markdown incident report Tracks real incident history in-app Includes demo log templates for instant testing
How we built it
We built NovaOps as a Next.js 16 App Router application with a modular backend + polished frontend: Frontend: React, TailwindCSS, shadcn/ui Backend/API: Next.js route handlers (/api/analyze-incident) LLM Layer: AWS Bedrock Runtime client with Amazon Nova (configurable provider/model) Agent Orchestration: Multi-agent pipeline in lib/agents.ts - Log Summary, Timeline Reconstruction, Severity Classification, Monitoring, Investigation, Root Cause, Dependency Graph, Remediation, Report Generation Visualization components: Log Summary Card, Incident Timeline, Service Dependency Graph, Incident Report viewer + download , Agent pipeline progress/trace UI Deployment readiness: Vercel-ready config, env templates, health endpoint (/api/health)
Challenges we ran into
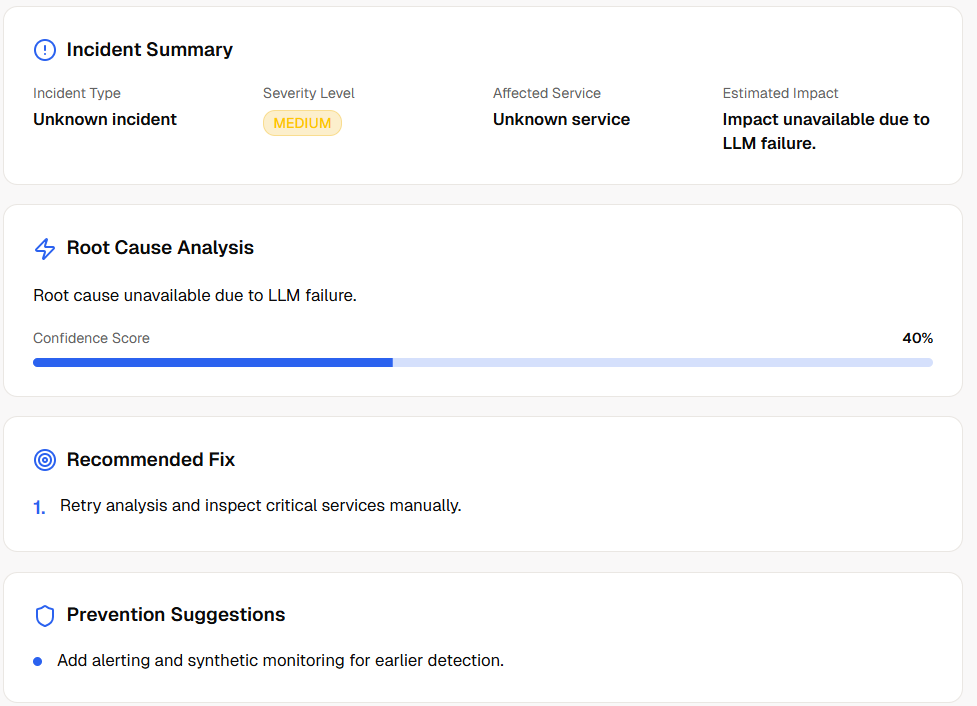
Model invocation constraints: Amazon Nova required inference profile handling in our environment (not just direct model ID). LLM output reliability: Generative output can drift, so we enforced strict JSON prompts and robust fallback parsing. UX trust factor: A spinner alone feels fake; users needed to see what each agent did, so we added per-agent trace summaries. Type consistency at speed: Expanding schema across API, orchestrator, and UI required careful shared typing. Production readiness: We hardened runtime behavior, timeout handling, and health checks for dependable deployment demos.
Accomplishments that we're proud of
Built a real multi-agent incident pipeline (not a single prompt wrapper) Added meaningful AI visual outputs: timeline + dependency graph + structured report Delivered end-to-end flow from log input to actionable incident response Implemented graceful fallback behavior when partial agent calls fail Made the app demo-friendly with template logs and persistent history Prepared the project for Vercel deployment with health monitoring
What we learned
Multi-agent decomposition makes incident reasoning clearer and more controllable. Deterministic prompts + defensive parsing are essential for production-like LLM systems. Visual storytelling (timeline/graph/report) is as important as model accuracy in incident tooling. Shared typed contracts dramatically reduce breakage as features scale quickly. “Demo reliability” requires explicit resilience design, not just model quality.
What's next for NovaOps
Live log stream ingestion (instead of file-only uploads) Real-time collaboration and incident commander workflows RAG with runbooks, postmortems, and service docs Smarter dependency graph layout + interactive drill-down Alert integration (CloudWatch/Datadog/Prometheus) as optional connectors SLA-aware impact estimation and automated post-incident summaries Role-based access + audit trail for enterprise readiness


Log in or sign up for Devpost to join the conversation.