-

Physicians are also able to customize the GPT-3 question generation prompts to improve utility and harmonize with their personal care style.
-

In the Amanuensis web app, patients are able to view their EHR profile, schedule new appointments, and review previous medical encounters.
-

In the Amanuensis web app, physicians are able to view all (here, synthetically-generated) information about patients under their care.
-

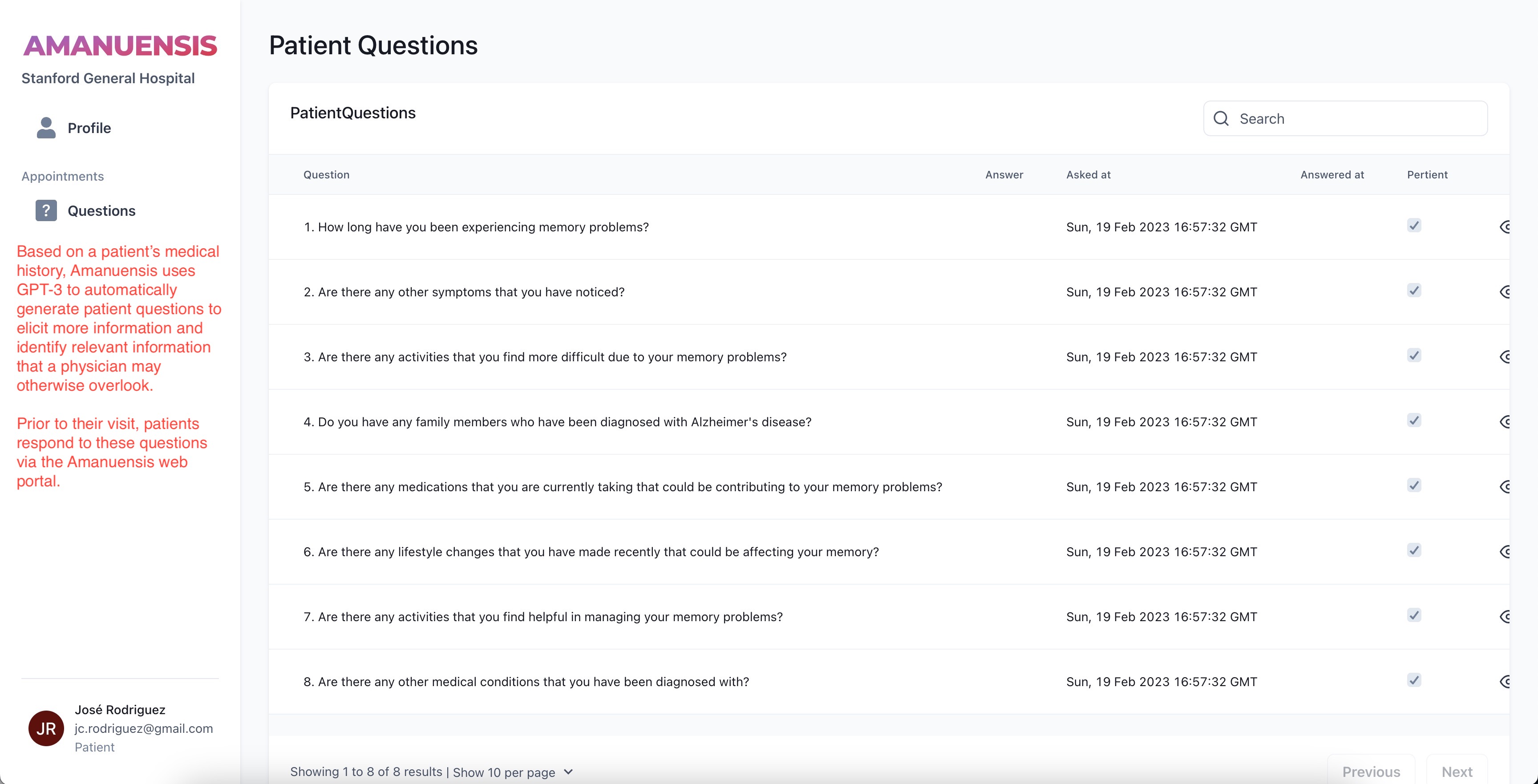
Amanuensis uses AI to generate clinically relevant questions for patients. Responses are then shared with their treating physician.
-

In the Amanuensis web app, physicians can view GPT-generated summaries of each patient's medical history and clinical profile.





Problem Statement 💡
The modern electronic health record (EHR) encompasses a treasure trove of information across patient demographics, medical history, clinical data, and other health system interactions (Jensen et al.). Although the EHR represents a valuable resource to track clinical care and retrospectively evaluate clinical decision-making, the data deluge of the EHR often obfuscates key pieces of information necessary for the physician to make an accurate diagnosis and devise an effective treatment plan (Noori and Magdamo et al.). Physicians may struggle to rapidly synthesize the lengthy medical histories of their patients; in the absence of data-driven strategies to extract relevant insights from the EHR, they are often forced to rely on intuition alone to generate patient questions. Further, the EHR search interface is rarely optimized for the physician search workflow, and manual search can be both time-consuming and error-prone.
The volume and complexity of the EHR can lead to missed opportunities for physicians to gather critical information pertinent to patient health, leading to medical errors or poor health outcomes. It is imperative to design tools and services to reduce the burden of manual EHR search on physicians and help them elicit the most relevant information from their patients.
About Amanuensis 📝
Amanuensis is an AI-enabled physician assistant for automated clinical summarization and question generation. By arming physicians with relevant insights collected from the EHR as well as with patient responses to NLP-generated questions, we empower physicians to achieve more accurate diagnoses and effective treatment plans. The Amanuensis pipeline is as follows:
Clinical Summarization: Through our web application, physicians can access medical records of each of their patients, where they are first presented with a clinical summary: a concise, high-level overview of the patient's medical history, including key information such as diagnoses, medications, and allergies. This clinical summary is automatically generated by Amanuensis using Generative Pre-Trained Transformer 3 (GPT-3), an autoregressive language model with a 2048-token-long context and 175 billion parameters. The clinical summary may be reviewed by the physician to ensure that the summary is accurate and relevant to the patient's health.
Question Generation: Next, Amanuensis uses GPT-3 to automatically generate a list of questions that the physician can ask their patient to elicit more information and identify relevant information in the EHR that the physician may not have considered. The NLP-generated questions are automatically sent to the patient prior to their appointment (e.g., once the appointment is scheduled); then, the physician can review the patient's responses and use them to inform their clinical decision-making during the subsequent encounter. Importantly, we have tested Amanuensis on a large cohort of high-quality simulated EHRs generated by SyntheaTM.
By guiding doctors to elicit the most relevant information from their patients, Amanuensis can help physicians improve patient outcomes and reduce the incidences of all five types of medical errors: medication errors, patient care complications, procedure/surgery complications, infections, and diagnostic/treatment errors.
Building Process 🏗
To both construct and validate Amanuensis, we used the SyntheaTM library to generate synthetic patients and associated EHRs (Walonoski et al.). SyntheaTM is an open-source software package that simulates the lifespans of synthetic patients using realistic models of disease progression and corresponding standards of care. These models rely on a diverse set of real-world data sources, including the United States Census Bureau demographics, Centers for Disease Control and Prevention (CDC) prevalence and incidence rates, and National Institutes of Health (NIH) reports. The SyntheaTM package was developed by an international research collaboration involving the MITRE Corporation and the HIKER Group, and is in turn based on the Publicly Available Data Approach to the Realistic Synthetic EHR framework (Dube and Gallagher). We customized the SyntheaTM synthetic data generation workflow to produce the following 18 data tables (see also the SyntheaTM data dictionary):
| Table | Description |
|---|---|
Allergies |
Patient allergy data. |
CarePlans |
Patient care plan data, including goals. |
Claims |
Patient claim data. |
ClaimsTransactions |
Transactions per line item per claim. |
Conditions |
Patient conditions or diagnoses. |
Devices |
Patient-affixed permanent and semi-permanent devices. |
Encounters |
Patient encounter data. |
ImagingStudies |
Patient imaging metadata. |
Immunizations |
Patient immunization data. |
Medications |
Patient medication data. |
Observations |
Patient observations including vital signs and lab reports. |
Organizations |
Provider organizations including hospitals. |
Patients |
Patient demographic data. |
PayerTransitions |
Payer transition data (i.e., changes in health insurance). |
Payers |
Payer organization data. |
Procedures |
Patient procedure data including surgeries. |
Providers |
Clinicians that provide patient care. |
Supplies |
Supplies used in the provision of care. |
To simulate an EHR system, we pre-processed all synthetic data (see code/construct_database.Rmd) and standardized all fields. Next, we constructed a PostgreSQL database and keyed relevant tables together using primary and foreign keys constructed by hand. In total, our database contains 199,717 records from 20 patients across 262 different fields. However, it is important to note that our data generation pipeline is scalable to tens of thousands of patients (and we have tested this synthetic data generation capacity).
Finally, we coupled the PostgreSQL database with the RedwoodJS full stack web development framework to build a web application that allows:
- Physicians: Physicians to access the clinical summaries and questions generated by Amanuensis for each of their patients.
- Patients: Patients to access the questions generated by Amanuensis and respond to them via a web form.
To generate both clinical summaries and questions for each patient, we used the OpenAI GPT-3 API. In both cases, GPT-3 was prompted with a subset of the EHR record for a given patient inserted into a prompt template for GPT-readability. Other key features of our web application include:
- Authentication: Users can log in with their email addresses; physicians are automatically redirected to their dashboard upon login, while patients are redirected to a page where they can respond to the questions generated by Amanuensis.
- EHR Access: Physicians can also access the full synthetic EHR for each patient as well as view autogenerated graphs and data visualizations, which they can use to review the accuracy of the clinical summaries and questions generated by Amanuensis.
- Patient Response Collection: Prior to an appointment, Amanuensis will automatically collect the patient's responses to the NLP-generated questions and send them to the physician. During an appointment, physicians will be informed by these responses which will facilitate better clinical decision-making.
Future Directions 🚀
In the future, we hope to integrate Amanuensis into existing EHR systems (e.g., Epic, Cerner, etc.), providing physicians with a seamless, AI-powered assistant to help them make more informed clinical decisions. We also plan to enrich our NLP pipeline with real patient data rather than synthetic EHR records. In concert with gold-standard annotations generated by physicians, we intend to fine-tune our question generation and clinical summarization models on real-world data to improve the sophistication and fidelity of the generated text and enable more robust clinical reasoning capabilities.
Development Team 🧑💻
This project was completed during the TreeHacks 2023 hackathon at Stanford University.
Award Descriptions 🏆
Below, we provide descriptions of specific prizes at TreeHacks 2023 which we believe Amanuensis is a strong candidate for. Please note that this list is non-exhaustive. We thank the sponsors and judges for their consideration.
Patient Safety Technology Challenge
By guiding physicians to make more informed clinical decisions, Amanuensis will help reduce medical errors and improve patient safety. We anticipate that Amanuensis is well poised to avert patient harm and reduce the indidence of medical across the continuum of care, including:
- Medication errors: Through AI-based summarization of the medication history and identification of key risk factors for adverse drug events, potential drug-drug interactions, drug-allergy reactions, and drug-disease contraindications, Amanuensis will help physicians prescribe safer medications.
- Procedural/surgical errors: With access to patient responses to relevant AI-generated questions, physicians will be more prepared for procedures and surgeries, and will be able to identify potential complications and risks.
- Diagnostic errors: By providing physicians with a summary of the patient's medical history, relevant clinical findings, and most salient symptoms, Amanuensis will help physicians make more accurate diagnoses and avoid treatment errors.
We thank Dr. Paul Tang for his time and guidance throughout the hackathon.
Best Startup and Most Likely to Become a Business
The EHR industry is ripe for disruption. Among hospitals with over 500 beds, the two dominant EHR systems, Epic and Cerner, hold 85% market share: Epic’s market share is 58%, and Cerner’s market share is 27%. Yet, physicians consistently express frustration with antiquated and inefficient interface. By contrast, Amanuensis offers a unique value proposition to physicians: a seamless, AI-powered assistant that may integrate with or supplant existing EHR systems. We believe that Amanuensis will be well positioned to disrupt the EHR industry and become a leading provider of AI-powered clinical decision support tools.
Best Use of Data
Amanuensis is undergirded by careful and nuanced analysis of large electronic medical datasets. To construct and validate Amanuensis, we generated a dataset with 199,717 records from 20 patients across 262 different fields; further, our synthetic EHR data generation pipeline can scale to tens of thousands of patients. Our deep understanding of the data enabled us to construct a large relational database with explicit foreign and primary keys; we later exploit these relations to efficiently query the database in JavaScript. Finally, informed by our high-quality dataset, we used leading large language models like GPT-3 from OpenAI to generate clinical summaries and questions for each patient, and designed a user interface for clinicians to both access and validate this information.
Best Hack for a Real World Use Case
We carefully designed our solution to address a real-world problem: the need for more efficient and effective clinical decision support tools. Further, we iterated on our solution throughout the hackathon, incorporating feedback from physicians such as Dr. Paul Tang and other stakeholders to ensure that our solution is both feasible, impactful, and closely aligned with physician needs.
Most Ethically Engaged Hack
Patient privacy and safety are at the core of our hack. Thus, we invested significant effort in generating synthetic data records, which we provided to downstream language models in our web application. We also designed our web application to leave the database unexposed, and we plan to integrate Amanuensis into existing EHR systems to ensure that patient data is stored securely and is only accessible to authorized users.
References 📚
Noori, A. et al. Development and Evaluation of a Natural Language Processing Annotation Tool to Facilitate Phenotyping of Cognitive Status in Electronic Health Records: Diagnostic Study. Journal of Medical Internet Research 24, e40384 (2022).
Jensen, P. B., Jensen, L. J. & Brunak, S. Mining electronic health records: towards better research applications and clinical care. Nat Rev Genet 13, 395–405 (2012).
Walonoski, J. et al. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. Journal of the American Medical Informatics Association 25, 230–238 (2018).
Dube, K. & Gallagher, T. Approach and Method for Generating Realistic Synthetic Electronic Healthcare Records for Secondary Use. in Foundations of Health Information Engineering and Systems (eds. Gibbons, J. & MacCaull, W.) 69–86 (Springer, 2014). doi:10.1007/978-3-642-53956-5_6.
Built With
- biogpt
- chakraui
- chatgpt
- graphql
- node.js
- postgresql
- prisma
- r
- react
- redwood
- synthea
- typescript


Log in or sign up for Devpost to join the conversation.