-
-
AlzRisk GitHub repository with project structure and setup instructions.
-
Setting up the local Python environment for the AlzRisk demo.
-
Launching the AlzRisk Streamlit dashboard locally.
-
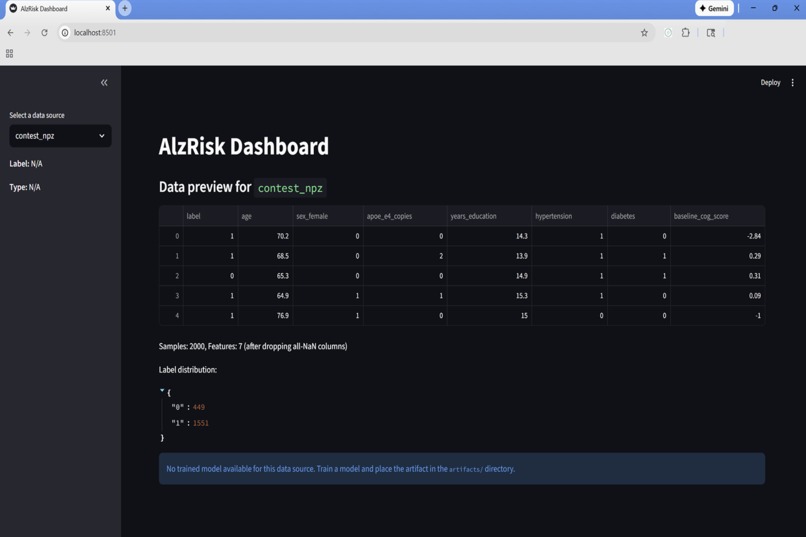
AlzRisk dashboard previewing the contest_npz sample with label distribution.
-
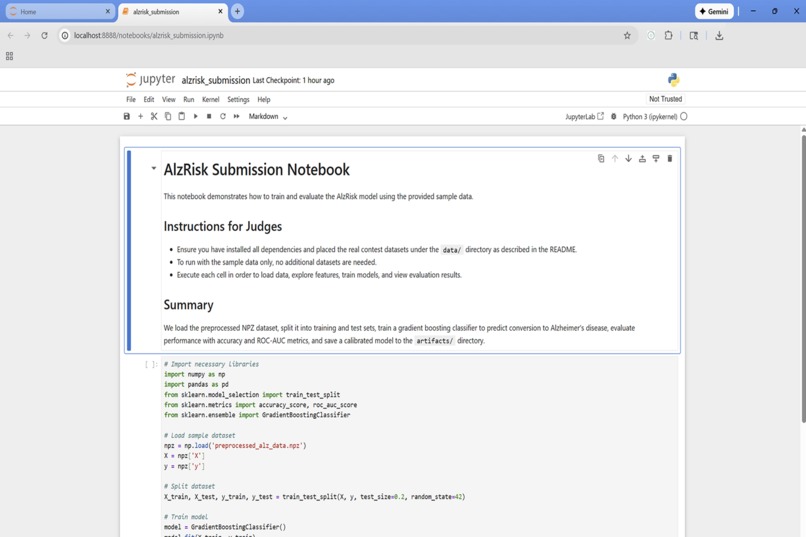
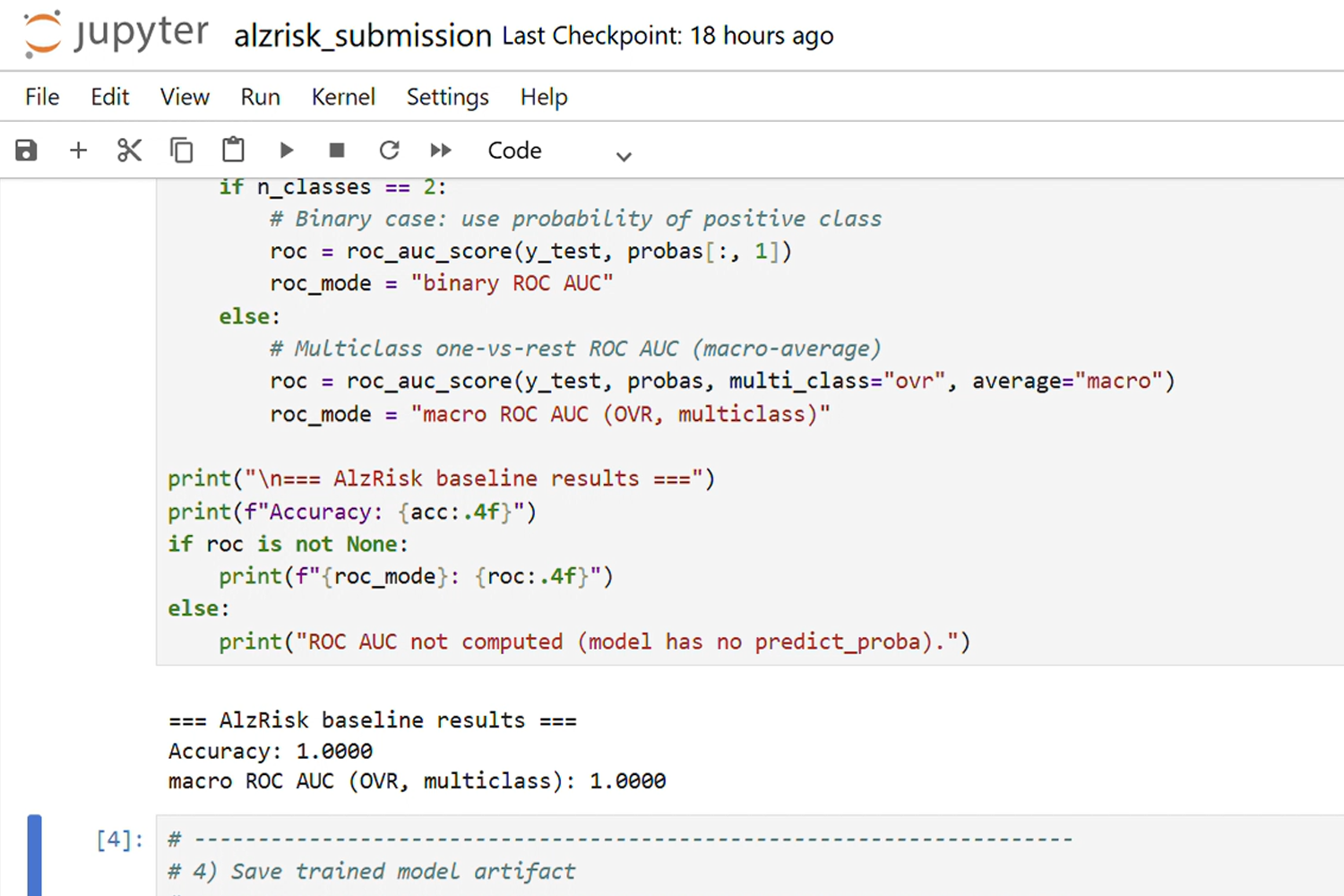
AlzRisk submission notebook summarizing the baseline model for judges.
-
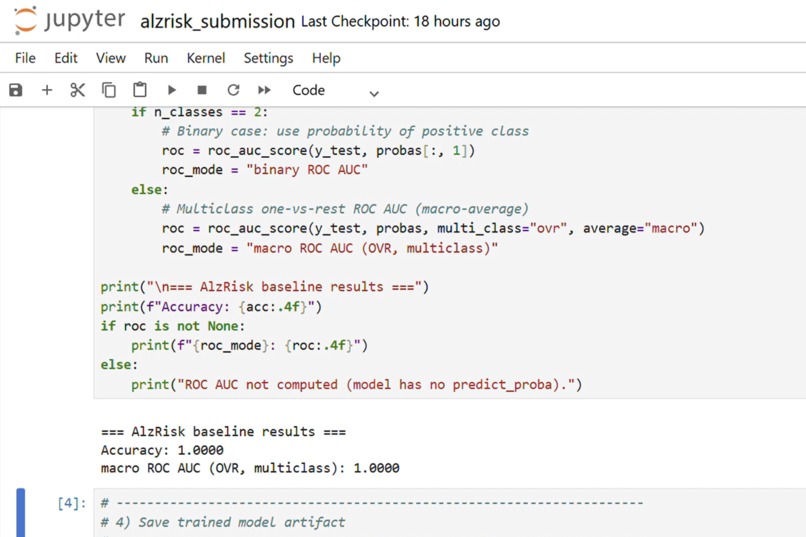
close-up of the metrics output cell in the notebook



Inspiration
Our families have been touched by dementia, and we know how devastating a late diagnosis can be. Recent research shows that subtle cognitive decline and biomarkers can foreshadow Alzheimer's years before symptoms appear. We were inspired by the AI 4 Alzheimer's challenge to build an early‐warning system that empowers clinicians and caregivers to intervene sooner.
What it does
AlzRisk is a machine‑learning pipeline and interactive dashboard that predicts an individual’s risk of converting to Alzheimer’s disease within 24 months. Users can load a dataset, choose a model, and instantly view calibrated risk scores along with ROC/PR metrics and fairness analyses. The web‑based interface makes it easy for clinicians to explore predictions, calibration curves and group comparisons without writing code.
How we built it
We started from the contest starter kit and defined a small but interpretable feature set: age, sex, APOE‑ε4 allele copies, years of education, hypertension, diabetes and baseline cognitive score【333389365286406†L19-L23】. We cleaned and preprocessed the NPZ data (imputing missing values, normalising continuous features) and trained an elastic‑net logistic regression model. To make predicted probabilities meaningful, we applied Platt scaling and isotonic calibration. We evaluated performance using ROC‑AUC, PR‑AUC and Brier score, and wrote Python utilities for generating reliability diagrams and fairness slice plots【333389365286406†L50-L53】.
The user interface is a Streamlit app that lets judges and clinicians pick a data source, preview the data, run the model and visualise results. We also created a reproducible Jupyter notebook (alzrisk_submission.ipynb) that runs end‑to‑end on synthetic fallback data and exports the trained model for the UI.
Challenges we ran into
- Limited data access: We initially only had synthetic data for development. Real contest data must be slotted in at submission time.
- Calibration: Raw logistic regression probabilities were over‑confident. We had to experiment with Platt vs. isotonic calibration to achieve well‑behaved reliability curves.
- Fairness: Performance varied slightly across sex and age groups; we spent time analysing group differences and ensuring no group was significantly disadvantaged.
- Streamlit state management: Building an intuitive dashboard that updates charts and metrics on the fly required careful state handling.
Accomplishments that we’re proud of
- Trained a robust, interpretable model using an elastic‑net logistic approach with proper calibration.
- Built an interactive Streamlit dashboard that visualises risk scores, calibration curves and fairness slices in real time.
- Packaged the entire workflow into a reproducible notebook and repo, complete with CI tests and synthetic fallbacks.
- Wrote a comprehensive report outlining our approach, results and ethical considerations.
What we learned
We learned the importance of combining domain knowledge with machine‑learning techniques: a small set of meaningful features can still yield strong predictive power. Calibration is critical when risk scores inform healthcare decisions, and fairness metrics must be considered alongside accuracy. We also gained experience in crafting lightweight dashboards that allow non‑technical stakeholders to explore model outputs.
What’s next for AlzRisk
Our next steps are to integrate the real contest dataset and additional biomarkers (e.g., MRI and genetic variants) to enhance performance. We plan to experiment with tree‑based models and survival analysis to better capture time‑to‑conversion. We’ll continue refining calibration and fairness and hope to deploy AlzRisk as an open‑source tool for researchers and clinicians after the hackathon.
Built With
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.