🧠 Inspiration
We built Alzora because families caring for older adults—especially those with early cognitive decline—need practical, reliable tools that reduce day-to-day friction and increase safety. Forgetting where things were placed, wandering episodes, and uncertainty about early symptoms are stressful for both patients and caregivers. We wanted a focused, implementable hackathon solution that blends real-time vitals monitoring, semantic memory assistance, and exploratory MRI image retrieval — all while being explicit that this is a research/demo tool, not a diagnostic product.
What it does
Alzora is a web-first system that helps patients and caregivers in three core ways:
Safe-zone monitoring & alerts
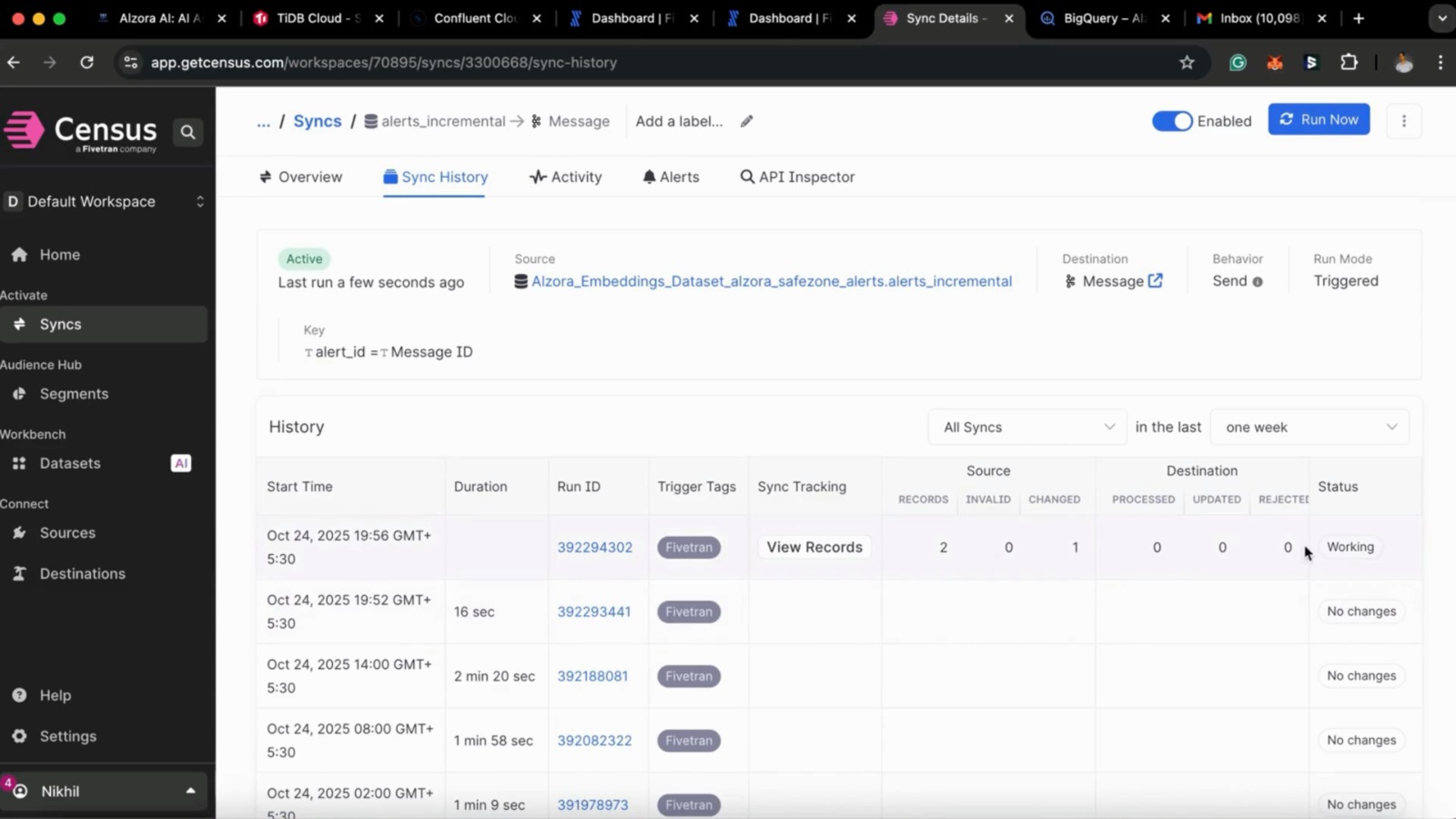
- Ingests watch vitals (heart rate, SpO₂, GPS) streamed via Kafka → Fivetran → BigQuery.
- For each patient, finds the latest GPS point and computes geodesic distance to the patient’s configured safe center. If the distance exceeds
safe_radius_meters, Alzora flags an alert and records it in an alerts table. - From here, we use Census for reverse ETL of these alerts to Kafka. Then, from Kafka our consumer consumes the alerts and sends the emails to the respective caretakers.
Memory assistant (text + image)
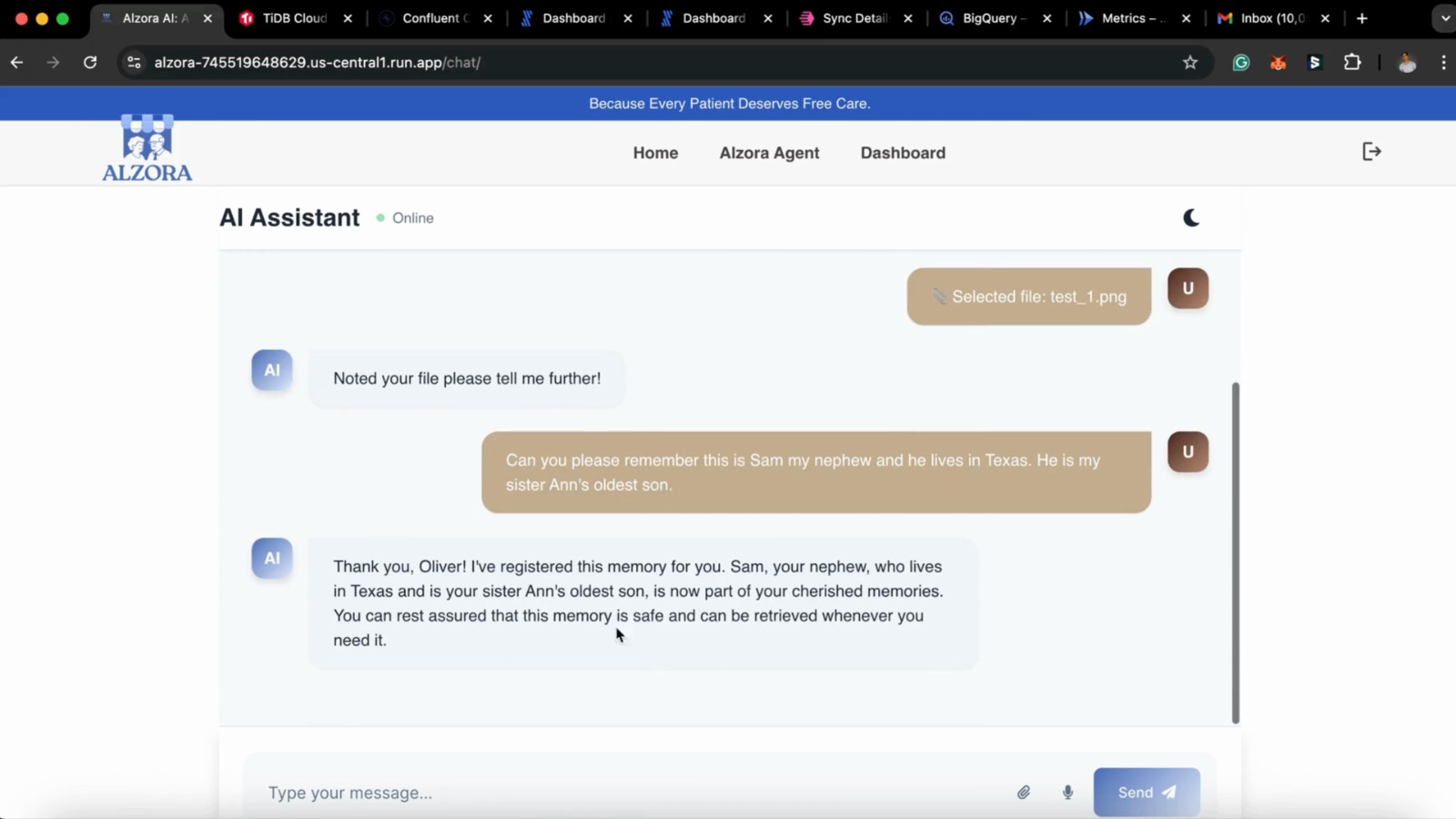
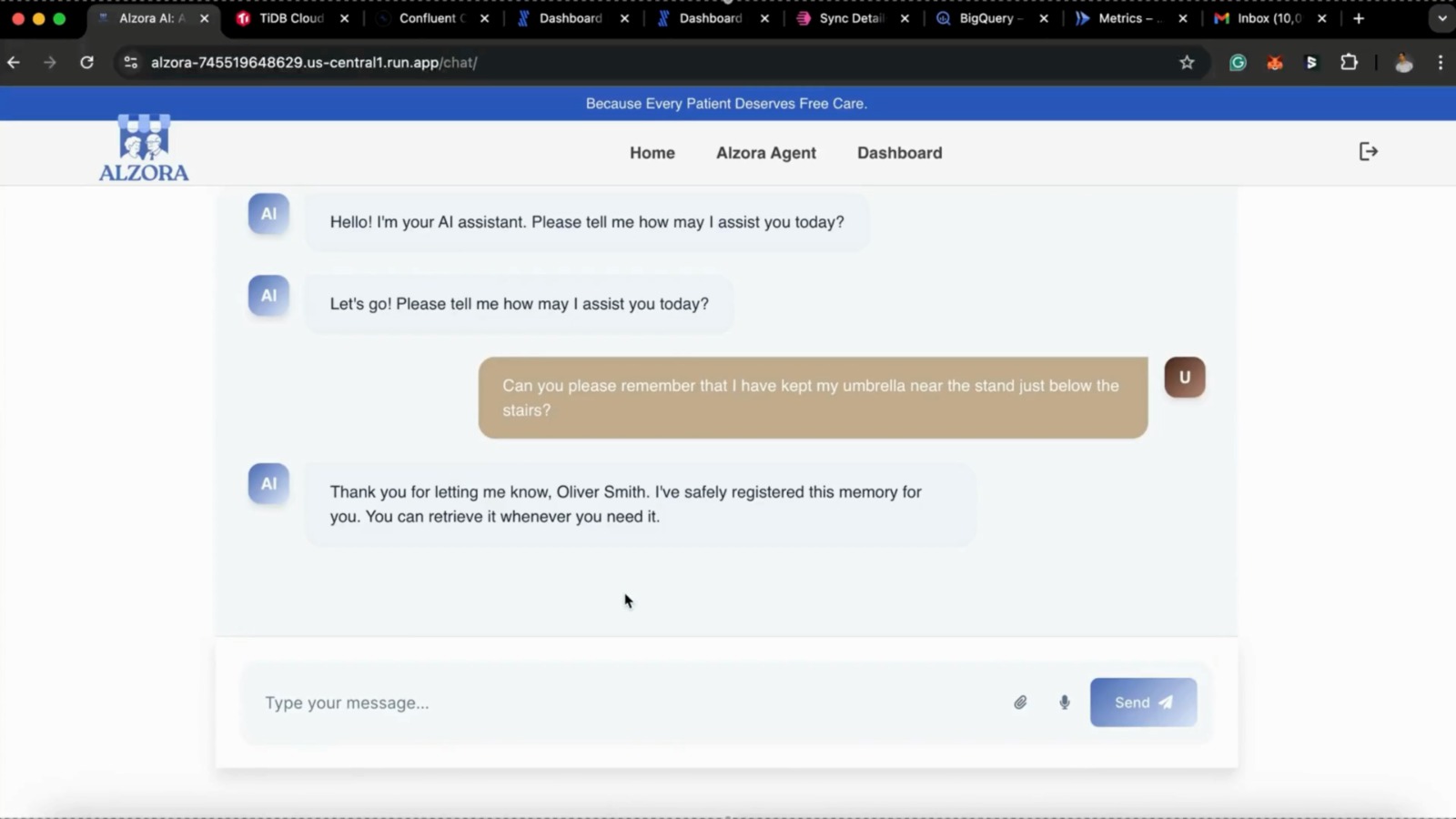
- Patients can store “memories” such as “I kept my glasses in the blue cupboard.” Those memos are embedded and stored as vectors so a chatbot can semantically answer “Where did I keep X?” even if wording differs.
MRI semantic search
- Upload an MRI scan image; the system detects the condition by performing an image vector search on the existing vector index.
- Asks a few analysis questions and provides a detailed summary of the analysis.
How we built it
Architecture

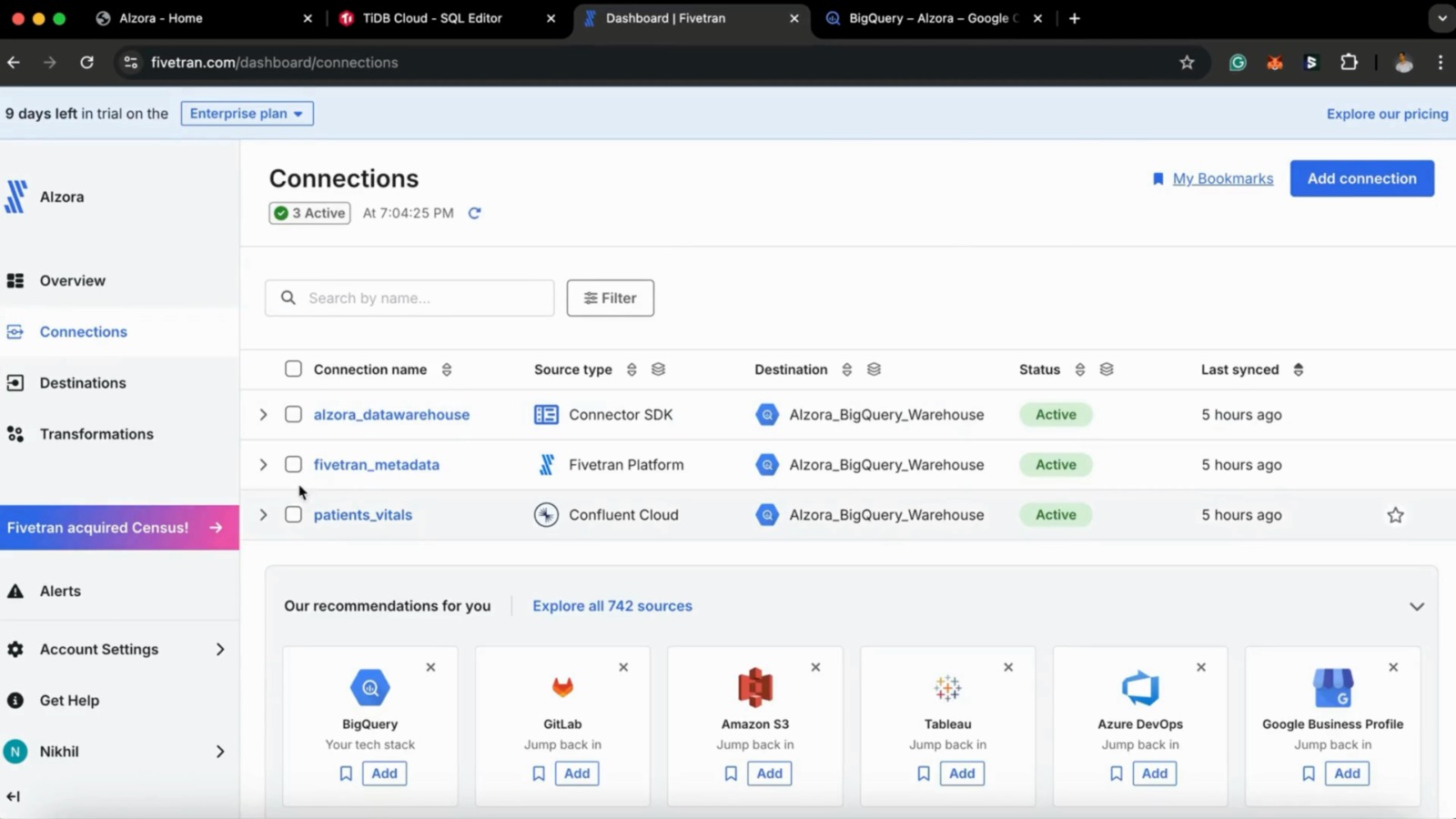
We built Alzora on a scalable and robust architecture, with Fivetran at the center of our data management strategy. The project's data flow begins with a Kafka Streaming pipeline and TiDB database. The data is then efficiently sunk into a Bigquery using Fivetran automated pipelines. To maintain a more robust architecture we have implemented reverse ETL using census and transformations using dbt core jobs.
Key components and Flows

We built a TiDB custom connector for Fivetran to reliably stream and upsert operational TiDB data into BigQuery, preserving table schemas and primary-key semantics so downstream analytics stay consistent. It handles timezone normalization, efficient incremental syncs (stateful checkpoints) and safe parsing of JSON/vector payloads so embeddings and structured data arrive ready for analysis. The connector removes the manual ETL pain—automating change capture, schema mapping, and retries—so teams get fresh, queryable BigQuery datasets without custom pipeline maintenance. Finally, it’s designed to scale from small proof-of-concept loads to larger production volumes, making it easy to add vector-aware tables and evolve the schema over time.

The Vector Transformation dbt job prepares and manages all the AI embedding data used by Alzora. It converts patient memories — including text and images — into numerical “vector” representations that the AI can understand. These embeddings power features like memory similarity search and context-based recall, helping Alzora connect related experiences or images even when they aren’t an exact match. In short, this job is what gives Alzora its “understanding” of patient memories.

The Safe Zone Alerts dbt job continuously analyzes patients’ real-time GPS data and compares their current location with their defined safe zone radius. If a patient moves outside this boundary, the system automatically flags a breach event and creates an alert entry. This ensures caregivers or family members are immediately aware when someone may be wandering or in potential danger. It’s a safety layer designed to bring peace of mind through proactive, location-based monitoring.

Once the Safe Zone Alerts dbt job detects that a patient has moved outside their defined safe area, the resulting alert records are stored in BigQuery. Using Census, these alerts are then automatically synced (Reverse ETL) from BigQuery to Kafka, which acts as a real-time event streaming system. From Kafka, a lightweight consumer service listens for new alert messages. Whenever a new alert event arrives, it triggers an email notification to the assigned caretaker — instantly informing them about the patient’s potential safety breach. This end-to-end flow ensures that insights generated in the data warehouse are immediately actionable, bridging analytics and real-world response in real time.
Google ADK

🧠 alzora_agent
The central controller that coordinates specialized sub-agents responsible for patient memory, condition, anxiety, vitals, and report management. It delegates complex requests to relevant expert agents and ensures smooth orchestration of patient-specific tasks.
🗂️ memory_registration_agent
Handles registering new patient memories and related metadata into the memory database.
- Tool:
register_memory— securely stores new memory entries along with contextual embeddings.
🔍 memory_retriever_agent
Responsible for recalling past memories and retrieving contextual information when requested by the patient or caretaker.
Sub-Agents:
- semantic_search_agent → performs deep vector search across memory embeddings.
- Tool:
search_memory— searches for semantically similar memories. - usual_spot_search_agent → retrieves familiar locations or routine items.
- Tool:
get_available_items— lists accessible items based on context. - finalizer_agent → refines and formats retrieved results for clarity.
- Tool:
get_item_spots— provides precise spatial details of items.
🩺 condition_analyser_agent
Analyzes patient medical condition trends, especially cognitive or neurological data.
Sub-Agents:
- mri_detection_agent → processes MRI data to detect anomalies.
- Tool:
mri_search— searches MRI scans for pattern matches. - summarizer_agent → generates concise summaries of condition reports.
❤️ vitals_info_agent
Tracks and interprets vital signs like heart rate, sleep patterns, and activity data. Integrates with condition analyses to identify early warning signals or irregularities.
🌿 anxiety_reducer_agent
Focuses on reducing patient anxiety through calming interactions and emotional grounding.
- Tool:
query_information_database— fetches reassuring information or reminders to comfort the patient.
📄 report_generation_agent
Compiles health summaries and behavioral insights for caretakers or medical staff.
Tools:
patient_python_code_execution— runs analysis scripts dynamically.set_patient_information— updates patient data before generating reports.
Challenges we ran into
- Embedding and storage format mismatch (TiDB ↔ BigQuery)
- Fivetran does not support vectors; dbt transform had to reliably convert those JSON arrays to
ARRAY<FLOAT64>for BigQuery. We added defensive parsing and testing in dbt.
- API response shapes & Vertex versions
- Vertex REST response formats vary across versions; we wrote a robust parser for
imageEmbedding/embedding/nested responses to avoid brittle failures.
Accomplishments that we're proud of
- End-to-end pipeline: We demonstrated a full flow from simulated watch → Kafka → Confluent → Fivetran → BigQuery → dbt → alerts table, with a live demo showing an alert triggered by a wandering GPS point.
- Vector-aware storage & sync: Implemented and validated the TiDB vector connector and dbt transforms that convert TiDB JSON vectors into BigQuery vector arrays usable by VECTOR_SEARCH.
- Multimodal demo: Built an MRI image semantic search MVP (upload image → top-k similar images) using Vertex multimodal embeddings and BigQuery vector search.
- Practical product UX: Memory assistant to store & retrieve informal memory notes and a caregiver onboarding flow.
- Data engineering maturity: Incremental dbt alerts model, partitioning/clustering in BigQuery, and tests.
What we learned
We gained a deeper understanding of building scalable, real-time applications using a managed ETL pipeline. We learned how to leverage Fivetran's unique features, such as its custom connector creation, transformation capabilities and its support for dbt jobs as well as internal connectivity with census. We also learned how to effectively manage complex AI workflows using a multi-agent architecture and how to handle data streaming from kafka into a structured flow.
Contribution to Fivetran Repo:
https://github.com/fivetran/fivetran_connector_sdk/pull/318
Credentials for Testing
username: aishux07 password: Hello@1234
What’s next for Alzora
- Mobile app & passwordless login — add a caregiver-managed mobile app, use passwordless login (PIN or magic link) for patients who may forget credentials. Provide caregiver delegation & emergency contact flows.
- Improve vitals anomaly detection — add lightweight ML models (edge-friendly) for fall detection and anomaly scoring; feed model alerts to caregivers and clinicians.
- Clinical feedback loop — partner with clinicians to gather feedback and tune the MRI retrieval UX.
Technical stack
- Streaming: Confluent Kafka (producer/consumer), Kafka → Fivetran pipeline
- Operational DB: TiDB (with vector column handling)
- Analytics & Vector Indexing: BigQuery (VECTOR_SEARCH / vector indexes)
- Transformations: dbt core
- Embeddings: Vertex multimodal embeddings;
- Agents / Orchestration: Google ADK agents
- Reverse ETL: Census
- Languages / tools: Python, PyTiDB / pymysql, google-cloud libs, Jinja/dbt macros
Built With
- census
- dbt
- fivetran
- gcp
- kafka
- tidb







Log in or sign up for Devpost to join the conversation.