-
-

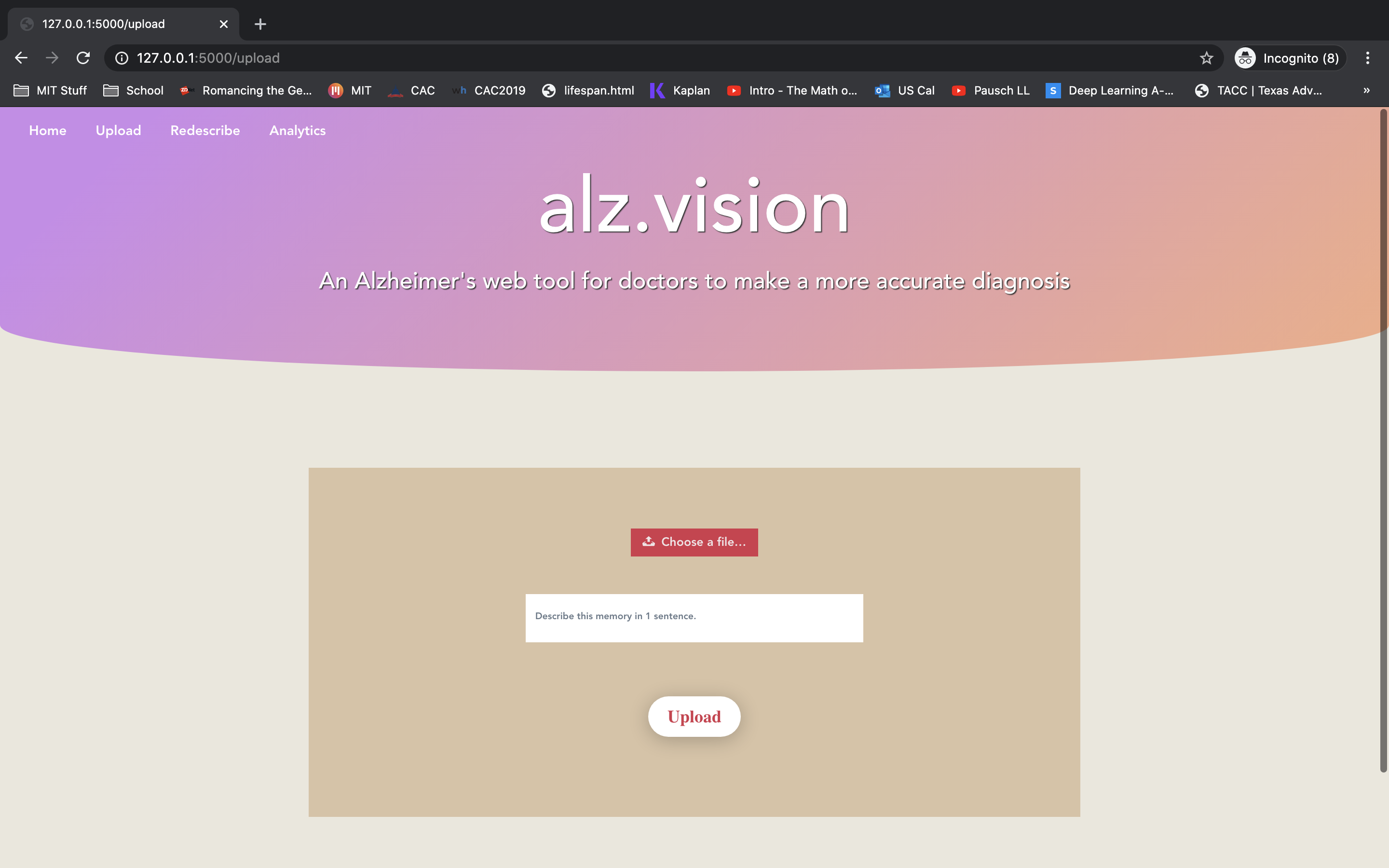
Updated Website: Upload Memories
-
Log In Screen
-
User Information Screen
-
Task Screen
-

Make A Memory Screen
-
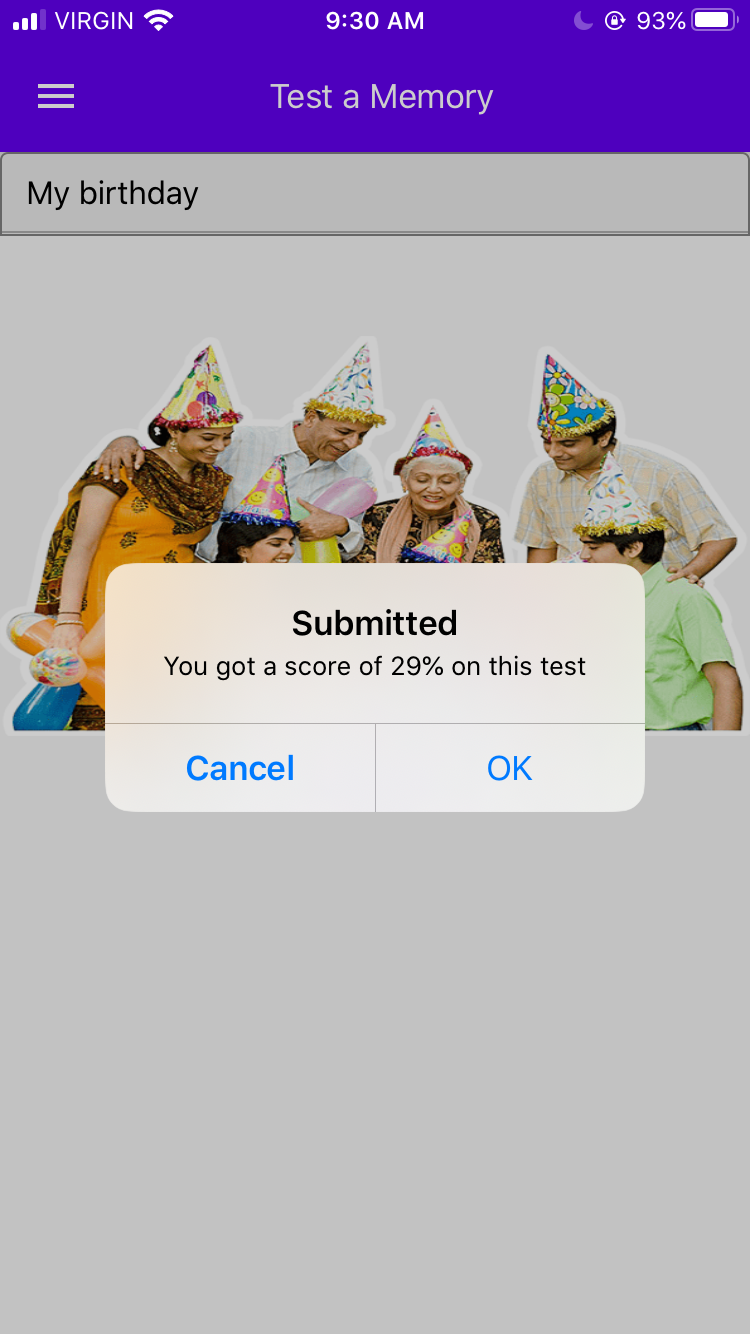
Test Your Memory Screen
-
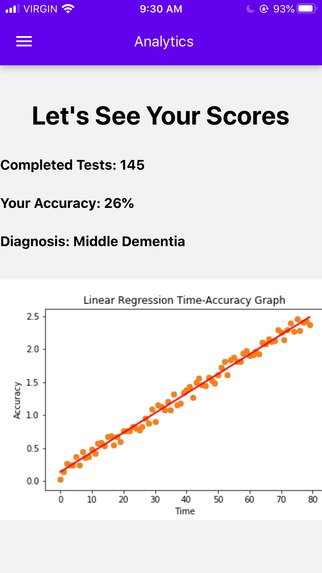
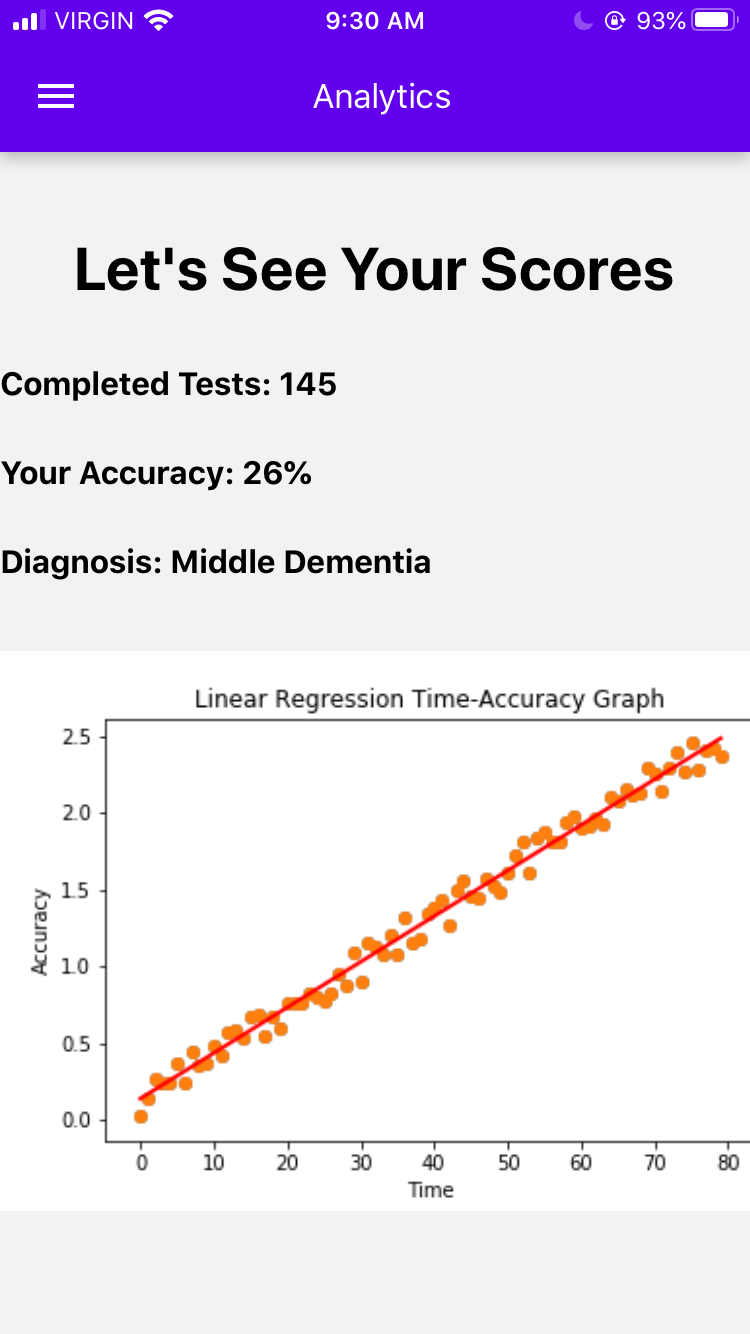
Analytics Screen
-
Frequently Asked Questions Screen
-
Did You Know Screen
-
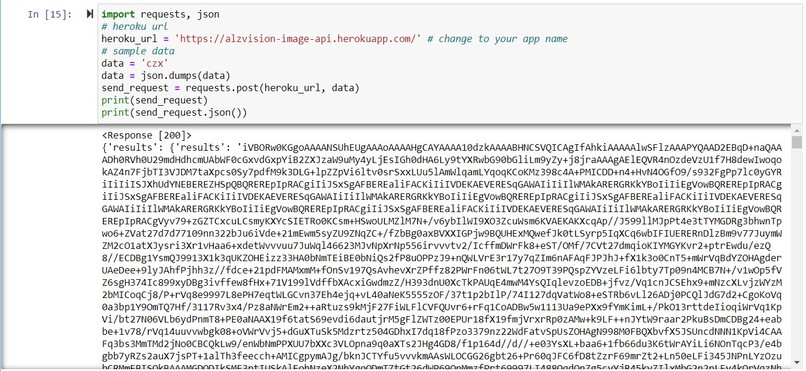
Demo Of Flask API Working
-

Website
-
Website
-
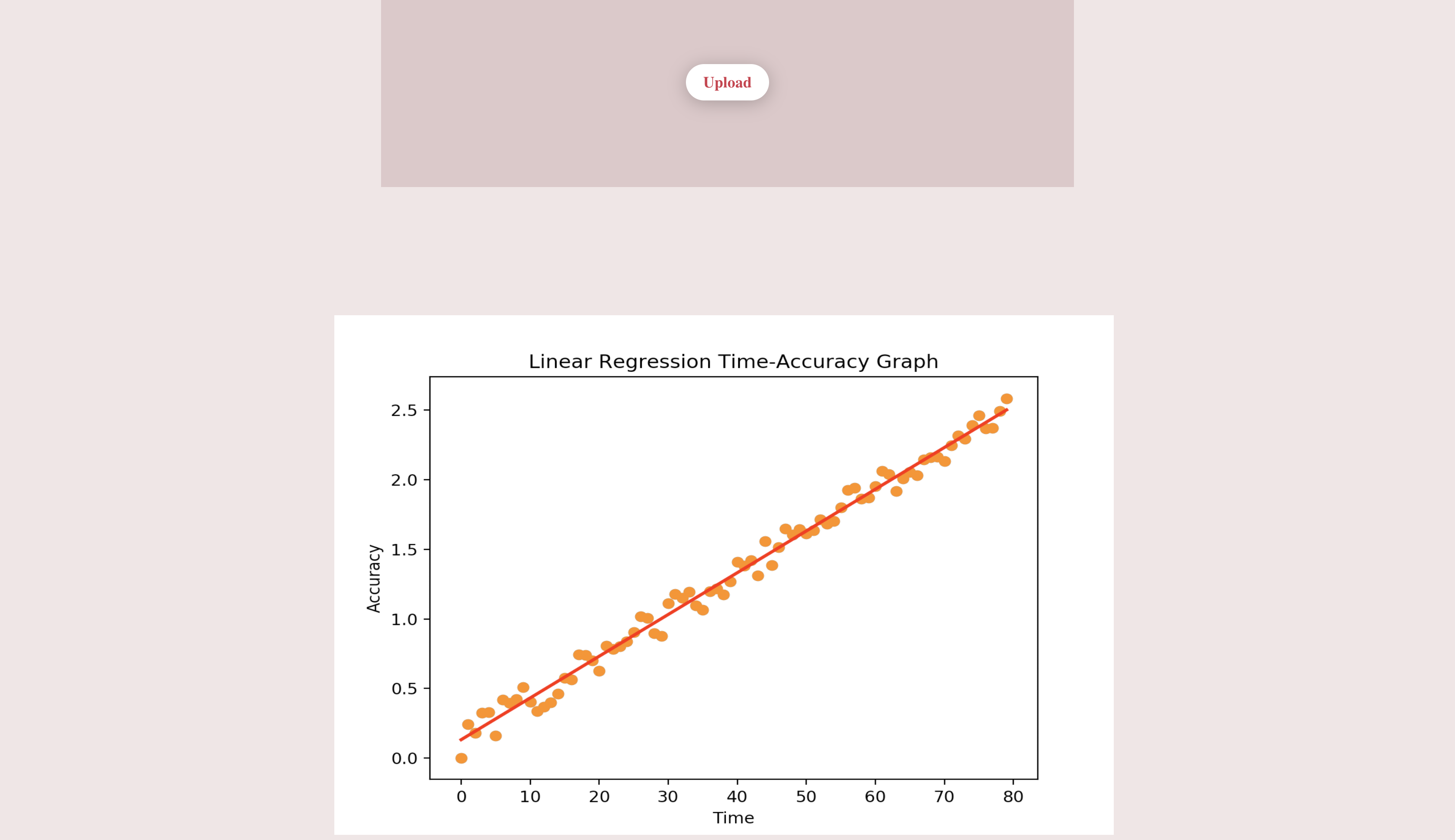
Updated Website: Graphs
-
Updated Website: Home Page
-
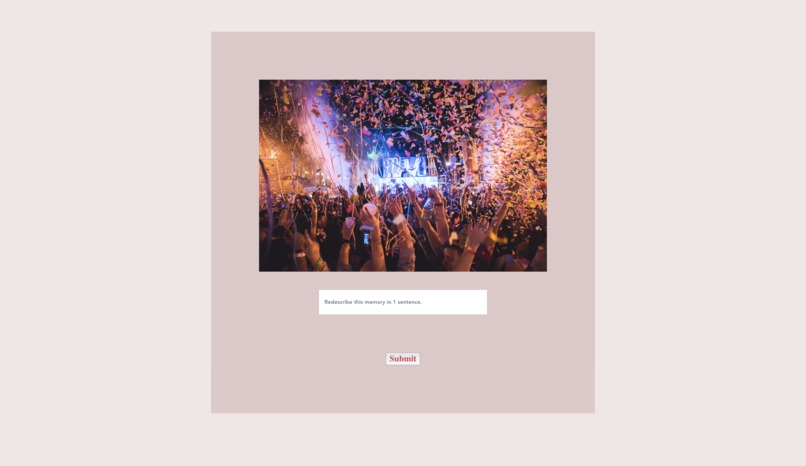
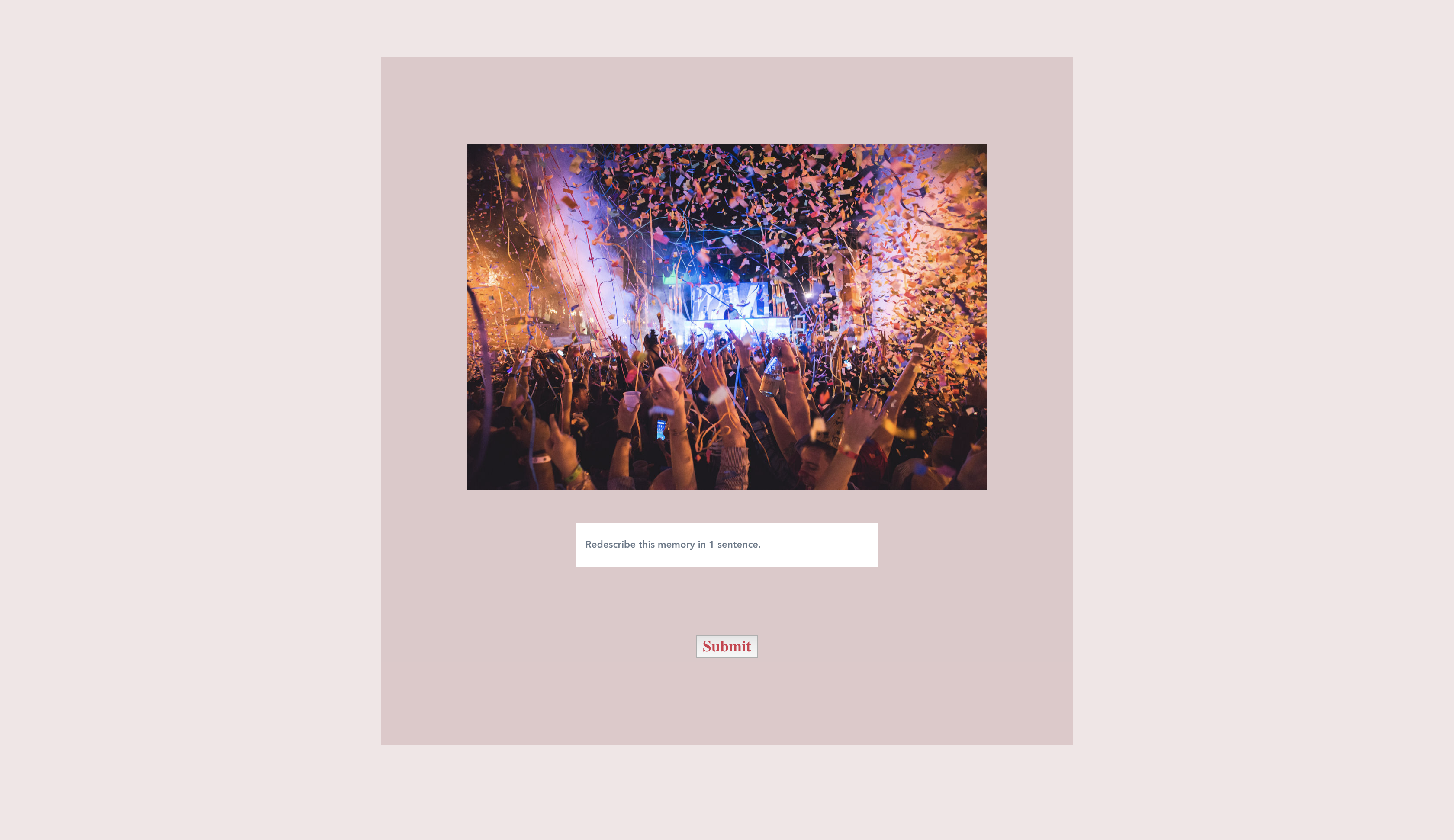
Updated Website: Redescribe
Inspiration
Nearly 3 million people in the US alone fall victim to memory impairments such as dementia and Alzheimer's. We personally have met people who struggle with Alzheimer's and have forgotten critical information and cherished memories, even going as far as forgetting a loved one.
Nowadays, when doctors diagnose patients, they don't personally know the person and have never met them before. They rely on mental tests and interviewing the family members. They don't have any real, concrete historical data their memories or any data on their decline of their memory. We hope to provide a data-analysis tool for doctors to better get an idea of each patient.
What it does
Our app hopes to provide doctors with data on users to help them better diagnose Alzheimer's. The user can upload photos and videos to the application. For each photo and video, the user will write a one-sentence description of the event portrayed. The user will also be prompted to later (after days, weeks, months, or even years) re-write the description. Our algorithm will rate (from 0-1) the description to how similar the new sentence is to the original sentence. Each of these scores are plotted on a time (number of days) x accuracy graph. With each memory, a linear or non-linear regression is performed (based on which produces the biggest R^2). The weights are then extracted (slope, y-intercept, and other factors) and an Isolation Forest outlier detection is performed. In the end, the algorithm will provides graphs and visual aids to show a user's memory decline. In addition, it will search for any potential outliers in their memory loss and common keywords associated with those outliers.
Version 2.0 (May 23rd, 2020 - May 24th, 2020)
Accomplishments that we're proud of
We finally got the app together! We were really proud of how our application is currently more or less functional. We can successfully upload memories and display them for redescribing. Also, our machine learning analysis is integrated into our app, so we're really happy about how everything is coming together. After one more sprint, we believe that we can start pitching our ideas and continuing with the design process.
How we built it
We used Flask only for this MVP, and we redesigned our original website. We used Flask-Mongodb instead of Mongodb and we used MongoDB Atlas. For the frontend, we used HTML/CSS/JS with Bootstrap. We used the same machine learning algorithms from our last sprint.
Challenges we ran into and What we learned
It was particularly difficult for us to upload images through MongoDB and we learned a lot about images with MongoDB and that there was a library which handled MongoDB with Flask (we were originally using only the original MongoDB library).
Next Steps
We want to work more on the UI to enhance user experience. We hope to share our app with local doctors to get their feedback on our app. We will adjust accordingly and then continue the design process to create a finished product. We especially want their feedback on how to display the data which will be most convenient to them. Then, we will pitch this product to local hospitals and clinics and hopefully collaborate with them to make this product a tool for patients to collect data to help doctors to diagnose Dementia and Alzheimer's better.
Version 1.0 (May 16th, 2020 - May 17th, 2020)
Accomplishments that we're proud of
We were able to create functional machine learning algorithms to find similarity and analyse the text. In addition, we have the start on our UI both for a mobile application and for a Flask app.
How we built it
We built our app with a mobile app and a basic website for the front end, a Flask API to allow us to access the machine learning models, and a MongoDB Atlas for the backend. We built the app using React Native, and we built the website using HTML/CSS/JS and Flask. For the machine learning in the analysis, we used StringMatcher and SequenceMatcher to rate each sentence and regressions and Isolation Forest to find outliers, and the charts were made using matplotlib.pyplot. Then, we used MongoDB Atlas to store each user's memories and descriptions that our front ends could use.
Challenges we ran into
For both the outlier detection and the sentence similarity scores, we tested a few models before reaching our final decision on the model which worked best. It was our first time using MongoDB Atlas and mongod, so it took some time to learn about the API. It was also a little difficult to work together online, but we used Discord as our platform and was sure to periodically check-in on each other.
What we learned
First, from a non-technical standpoint, our team learned a lot about Alzheimer's. We spent two weeks researching the disease to learn more about how it is diagnose and listening to real user stories. From a technical standpoint, two of our teammates learned how to use React Native and all our teammates learned MongoDB Atlas.
What's next for Dement.ai
We hope to be able to put the app together to form a final product.



Log in or sign up for Devpost to join the conversation.