-
-
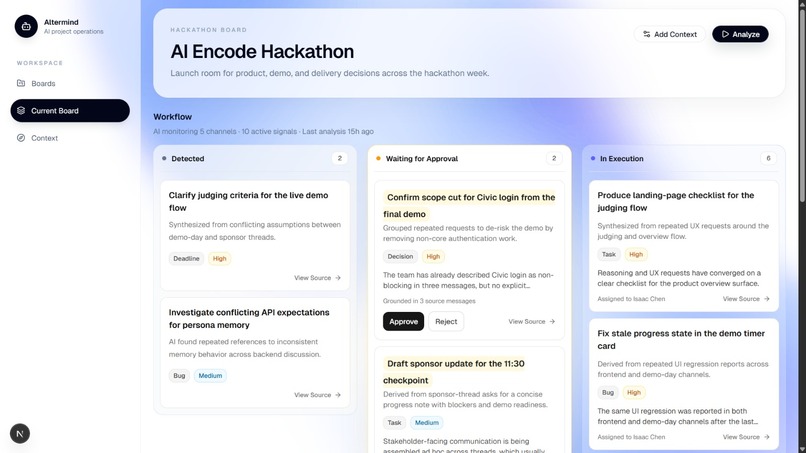
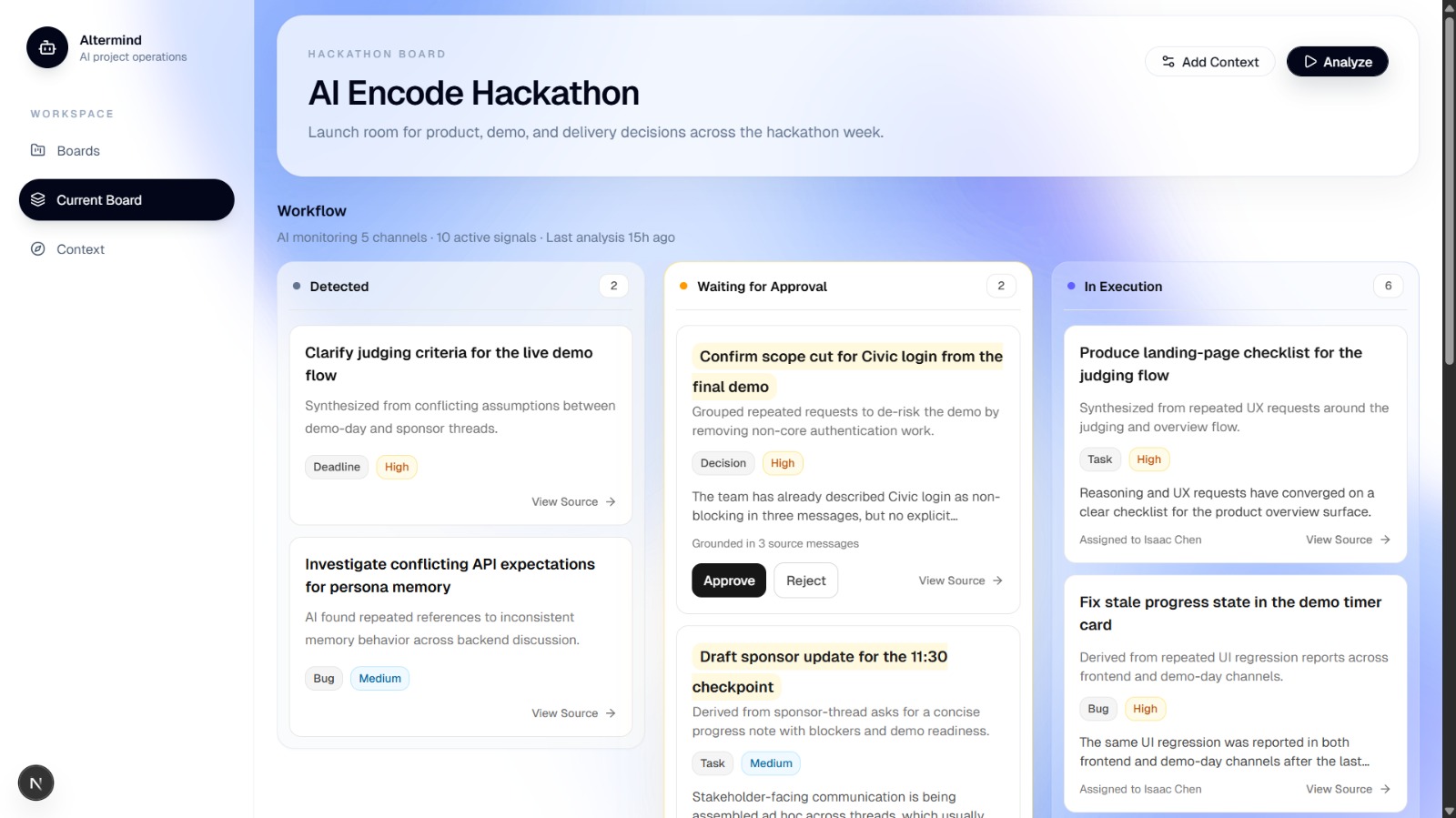
Dashboard of your slack channel's action list
The Problem That Wouldn't Leave Me Alone
Every engineering team I've been part of has the same invisible graveyard: decisions buried in Slack threads, bugs mentioned once and forgotten, deadlines that lived in a message nobody starred. The information existed — it was just never extracted.
Tools like Jira and Linear are great at tracking work you already know about. But the painful part is the work nobody wrote down: the thing Sarah mentioned at 11pm, the dependency Diego flagged in passing, the compliance deadline Kevin buried in a thread from three weeks ago. That's where projects actually fail.
FlowMind is my attempt to close that gap.
How It Works
The core pipeline is three steps:
$$\text{Slack messages} \xrightarrow{\text{Gemini 2.5 Flash}} \text{structured task proposals} \xrightarrow{\text{human approval}} \text{executable action items}$$
Gemini receives up to 120 recent Slack messages as a formatted prompt and returns a responseJsonSchema-constrained JSON array of task proposals — each with a type, priority, confidence score, owner inference, and crucially, source message IDs that trace exactly which messages caused each task. No hallucinated citations.
The human-in-the-loop layer is non-negotiable. AI-generated tasks sit in a waiting for approval column. A reviewer reads the AI's reasoning, sees the source messages, and approves or dismisses. Only then does Gemini generate an execution checklist. No black boxes, no auto-execution.
What I Built
Multi-workspace Slack sync with pagination and author resolution Gemini structured output pipeline using responseMimeType: "application/json" and responseJsonSchema — no function calling, deterministic JSON every time Source message traceability — a task_source_links junction table links every task to the exact Slack messages that caused it, rendered in the UI as collapsible quote cards Analysis run tracking with idempotency — re-running analysis skips messages already processed and deduplicates task titles Demo workspace — judges hit "Try Demo" and see real Gemini-generated tasks from a seeded engineering team Slack channel, no signup required The Hardest Technical Challenge Getting Gemini's structured output to be actually reliable took more iteration than anything else. The naive approach (asking for JSON in the prompt) produces valid JSON about 85% of the time. Using responseJsonSchema gets you to ~99% — but the schema has to be carefully designed.
The key insight was making every field either a constrained enum or a non-nullable string, then doing all the nuanced classification in the prompt rather than in the schema. The schema enforces shape; the prompt drives intelligence.
The confidence score uses a number type with minimum: 0, maximum: 1:
$$\text{confidence} \in [0, 1], \quad \text{where } c > 0.7 \Rightarrow \text{"high signal from explicit messages"}$$
Tasks below 0.4 confidence still surface — they represent implicit signals worth human review — but the UI surfaces confidence visually so reviewers can calibrate their attention.
What I Learned
Async Supabase server clients in Next.js App Router were subtler than expected. The cookies() API is now async in Next.js 16, which means every repository getClient() helper needs to be async — something that silently returns a Promise instead of a SupabaseClient if you forget the await. TypeScript catches it, but only at build time.
Demo UX is a product decision, not an afterthought. Requiring judges to set up a Slack bot token would kill the demo in under 60 seconds. The fixture seed data pipeline — 25 realistic engineering Slack messages analyzed by real Gemini — means any judge can see the full AI loop in under 30 seconds with zero setup.
Removing features is often the right call. The original project had Discord OAuth, a Google Calendar integration, Web3 wallet auth, and an MCP server. Stripping all of that and shipping a focused, working Slack → AI → kanban pipeline made everything else sharper.
Challenges
Schema migration consolidation — collapsing 11 incremental migrations into 2 clean ones while preserving backward compatibility with legacy column names (external_discord_channel_id storing Slack IDs) required careful aliasing at the repository layer Next.js 16 breaking changes — middleware.ts was deprecated in favour of proxy.ts with a renamed export; the build fails silently in dev but hard-errors in production Turbopack builds Rate limiting on Slack's users.info endpoint — resolved with exponential backoff and an in-memory author cache per sync session, reducing API calls by ~80% on typical channel histories
Built With
- civic
- gemini
- next.js
- react
- slack
- supabase
- tailwind
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.