-
-

Landing
-
Agent Social Simulation
-
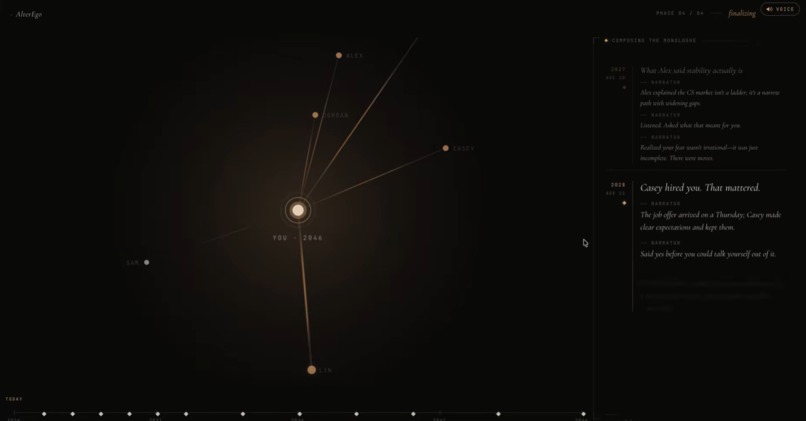
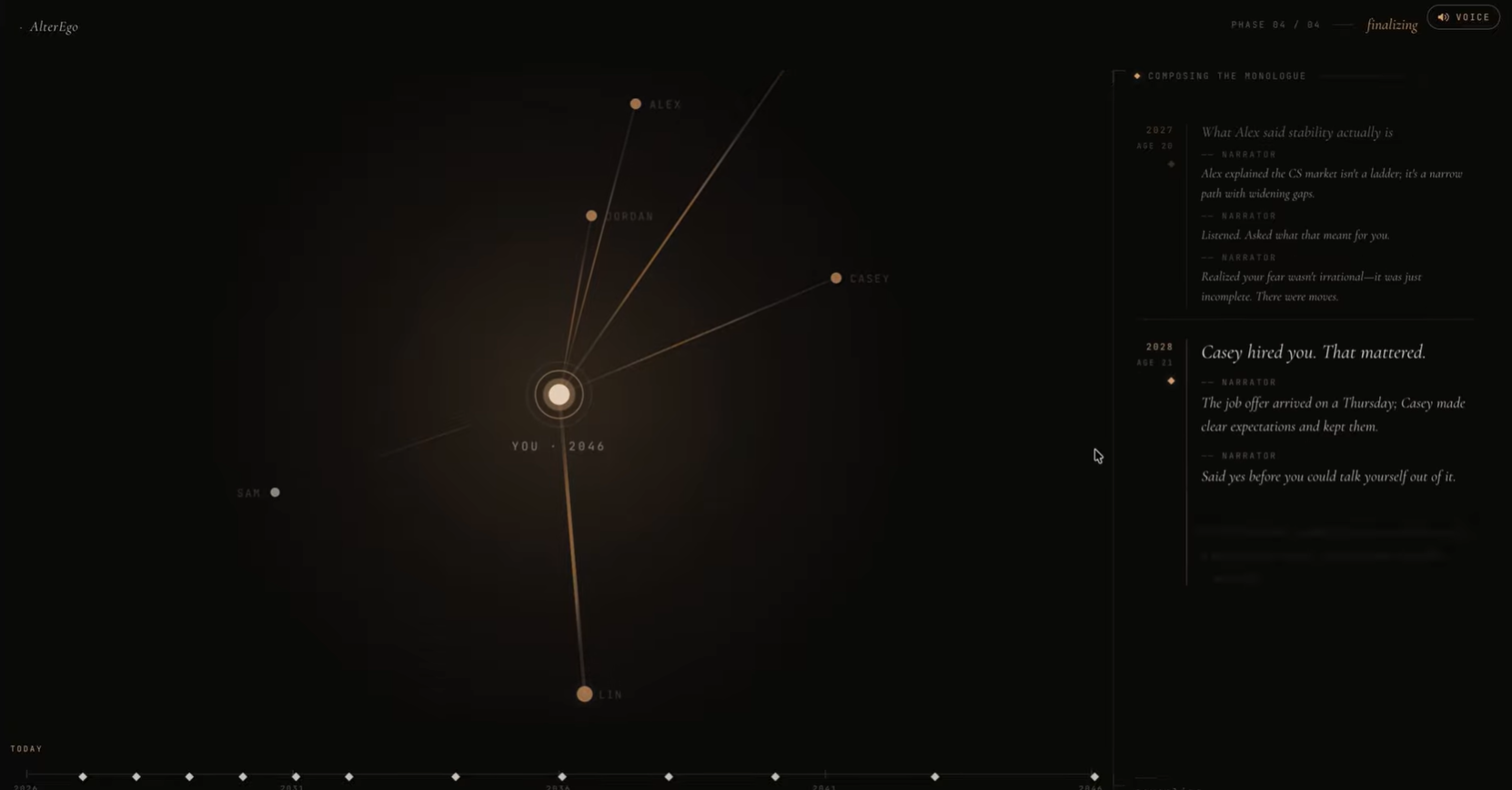
Timeline
-

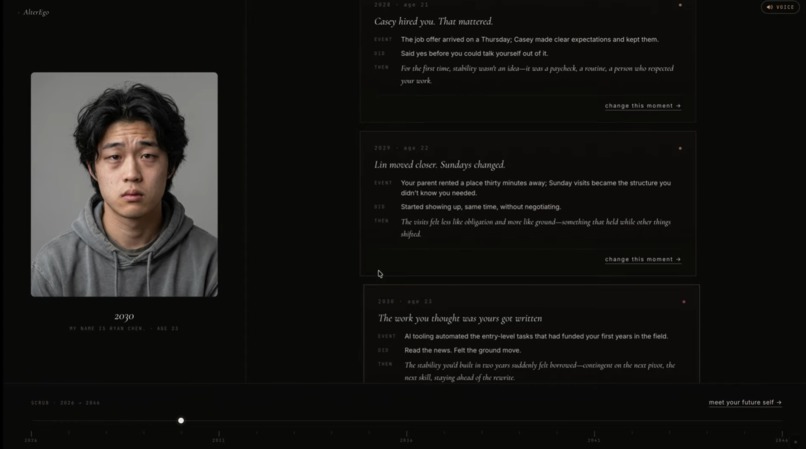
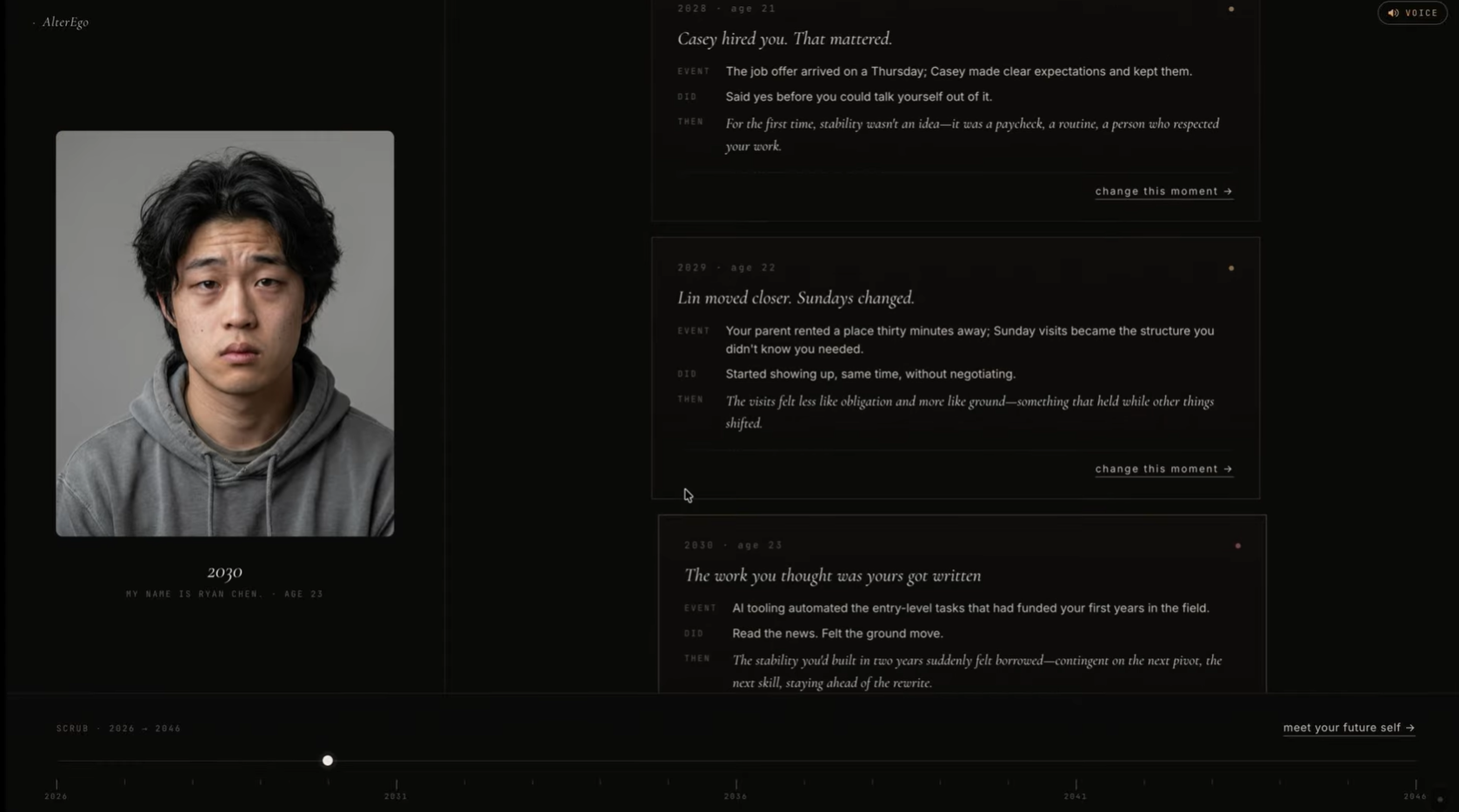
Health Card


AlterEgo
You don't get to meet your future self. So we built one and let you talk to it.
Inspiration
People optimize their lives the same way they optimize code: greedily, locally, against whatever metric is loudest this quarter. The 65-hour weeks. The "I'll call my sister next month." The promotion nobody really wanted. Each decision is rational in isolation. The trajectory it traces is not.
The thesis behind AlterEgo is simple: we make better decisions when we have a memory of where they lead. We don't get one. So we built one: a simulator that takes seven honest answers about your present, projects your life out twenty years, and lets you sit across from the person you become if nothing changes. Aged by Gemini. Voice cloned by ElevenLabs from your intake answers. Not motivational. Just what happened.
What we built
Eight screens, one pipeline, one quiet conversation:
Landing → Selfie → Intake → Processing → Reveal → Chat → Timeline → End
Under the hood, every step streams:
/simulateruns a four-phase NDJSON pipeline: count the people in your life → lay out the years → write the moments → stitch it together. Six checkpoints across the chosen horizon, each grounded in an 8-dimensional state model./simulate/branchlets you intervene at any year ("I would refuse the promotion") and re-streams the trajectory from that point forward, preserving everything before./chatis a stateless free-form interview with Future You./tts,/stt,/voice/clonewrap ElevenLabs Scribe + IVC + Turbo so you can speak your answers and hear yourself answer back./simulateportrait fan-out sends the selfie and per-checkpoint context to Gemini so each year of your life has a face.
The state model
Each life is an evolving vector \(\mathbf{s}_t \in \mathbb{R}^8\) across the dimensions
$$ \mathbf{s} = \big(\text{work}, \text{finance}, \text{isolation}, \text{family}, \text{health}, \text{career}, \text{meaning}, \text{relationship}\big) $$
A curated event pool E holds candidate moments with threshold predicates \(\theta_e(\mathbf{s})\). At each year t we sample from
$$ E_t = {\, e \in E \mid \theta_e(\mathbf{s}_t) \text{ holds} \,} $$
and let Claude pick which one fires and write the narrative around it. The optimistic-trajectory slider exposes the model directly:
$$ p(\text{optimistic}) = \text{clamp}!\left(1 - \frac{h - 30}{60},\; 0.12,\; 0.92\right) $$
where $h$ is hours worked per week. Pull the slider down, watch the portrait warm.
How we built it
| Layer | Stack |
|---|---|
| Brain | Claude Opus 4.7 (orchestration) · Sonnet 4.6 (high-signal NPCs) · Haiku 4.5 (peers) · Groq Llama 3.1 (background noise) |
| Voice | ElevenLabs Scribe (STT) + IVC (per-session voice clone) + Turbo v2.5 (streaming TTS) |
| Vision | Gemini for selfie-conditioned aged portraits at every checkpoint |
| Backend | FastAPI, Pydantic, NDJSON streaming, multipart upload |
| Frontend | Vite + React + TypeScript, MediaRecorder + Web Audio for live mic levels, blob-URL playback synced to a typewriter-streamed text hook |
The orchestrator is tier-routed: a Tier enum (FUTURE_SELF, HIGH_SIGNAL, PEERS, NOISE) maps to whichever model fits the cost/quality budget, so models can be swapped at demo time without touching prompt code. Same for inference plans — Plan A (local on an ASUS GX10) and Plan B (hosted APIs) live behind a single router.
What we learned
- Tone is harder than capability. Claude wants to be inspiring. The product depends on it not being. The TONE_BLOCK prefixing every prompt — "honest, contemplative, never motivational" — went through more revisions than any other piece of code.
- Streaming is a UX primitive. Every wait got rewritten as a stream. Six checkpoints arrive one at a time so users watch their lives appear; portraits fan out behind the scenes; TTS plays the first byte before the last word renders.
- Voice cloning is uncannier than animation. Hearing the future self speak in your own voice lands harder than any portrait. Cloning runs in parallel with
/simulateso it's ready by Reveal — the latency budget for the whole twist is whatever the simulation already costs. - Empty responses are valid. Learned this the hard way (see below).
Challenges we faced
- The "no transcript is still a transcript" bug. The
/sttendpoint treated an empty Scribe response — what you get from silence or a half-second tap — as a server error and 502'd. Frontend stuck on "Transcribing…" forever. The fix was a one-liner; finding it meant adding stderr instrumentation to the route and reading bytes-on-the-wire to confirm Scribe was happy and we were the problem. - Browser autoplay gating. TTS auto-plays the future self's monologue, but browsers won't play audio without a prior user gesture. A
primedboolean threads through context, flipped only by the voice toggle click. - Cloning latency vs. flow latency. ElevenLabs IVC takes 10-15s; so does the heaviest simulation tier. Running them sequentially would have doubled the wait.
/voice/clonekicks off in parallel with/simulatefrom the Processing screen, with a 45s ceiling and graceful fallback to a default voice. - Merging mid-flight. Four feature branches ran in parallel — selfies, aged portraits, scrolling refactor, voice. Reconciling required surgical resolution of a JSX bug that had silently shipped to
main(two interleaved landing screens). Typecheck before declaring a merge done. - "Honest, not motivational" at the prompt layer. Easy to say. Hard to enforce. Opus slipped into hopeful platitudes during finalization and needed an explicit anti-pattern in the system prompt: "do not offer encouragement, do not name lessons, do not predict resilience."
What's next
PVC instead of IVC for higher-fidelity voices. A persistence layer so the trajectory can be revisited a year later, against the actual life that happened. And a longer horizon — fifty years, maybe — for anyone brave enough to look that far.
Built With
- anthropic
- elevenlabs
- nextjs
- python






Log in or sign up for Devpost to join the conversation.