

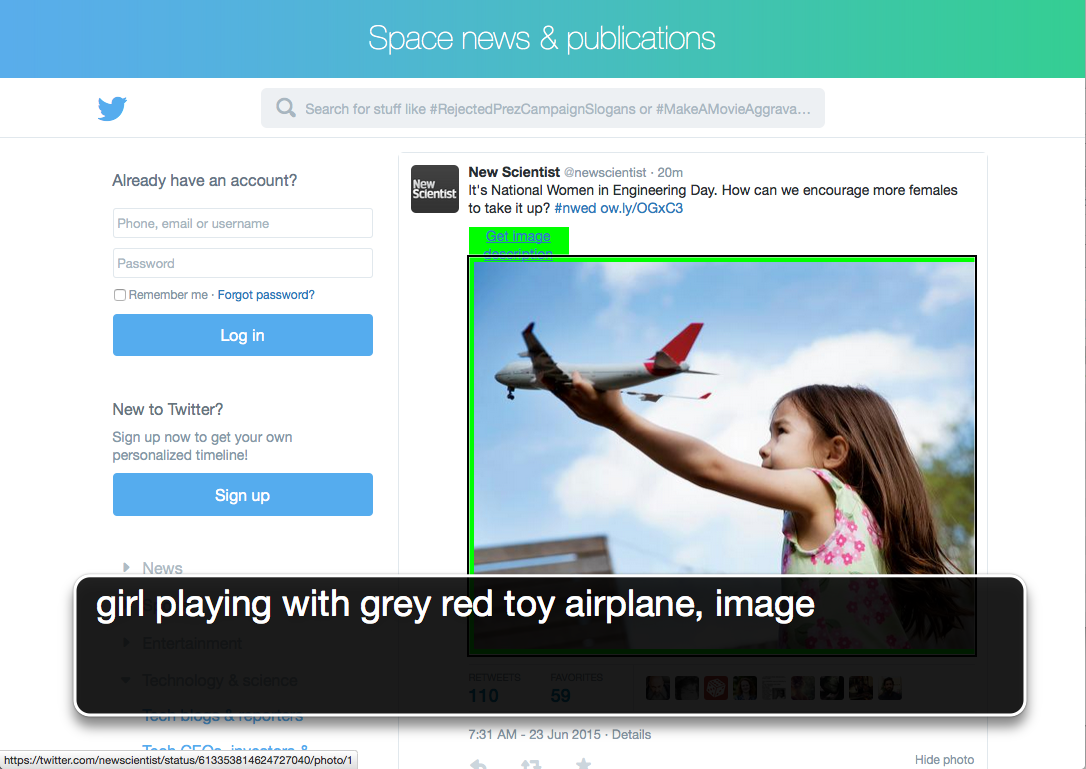
Alt Text Bot is a browser extension that adds descriptions to images on the web for people who are blind, so that their voices can be a part of the online conversation.
The web is centered around in discussion, and everyone should be have a voice. Right now it's not always true. People who are blind are being excluded from conversations on sites like Twitter and Facebook because so much of the content there is images without descriptions. These are blank spaces for blind people that make it harder for them to get involved.
Alt Text Bot helps fill the gap. It uses image recognition technology to add descriptions to images anywhere on the web. It's easy to install and works across multiple platforms and software combinations. The descriptions are highly accurate, and add meaning to conversations that would otherwise be incomplete. In this way, Alt Text Bot gives equal access to people who are blind, and becomes a springboard for connecting with others.
How it works
When a user clicks on an image after installing Alt Text Bot, the extension sends the image URL to the Cloudsight API. While the request is in process, the image is marked as "busy" so screen reader users know that description is in progress. When the API responds, Alt Text Bot attaches the resulting description to the image that was clicked, and the description is announced by the screen reader.
Background
Twitter Bot
The initial version of Alt Text Bot - a Twitter bot that responds to requests - has seen heavy use since it's launch, with upwards of 8,000 image descriptions delivered. I saw people using it to describe images of memes, pictures of friends, get the model number on a Braille reader, and more. I've been excited to see this traction and happy with the results, but I heard a few repeated requests that got me thinking about a different approach, one that would allow descriptions on any page on the web.
Pivoting to a Browser Extension
Feedback is an important and ongoing part of my process. I performed multiple in person usability studies and many more exchanges online to refine Alt Text Bot, from a bot on Twitter to a Firefox extension with screen reader support.
After launching the first version of Alt Text Bot on Twitter, my research showed that people wanted more privacy, functionality across different sites, and on-demand descriptions. I decided to create a browser extension that would work on all sorts of content across the web, in a way that is private and on-demand.
Here is some specific feedback I received:
Have you thought about making it a Firefox extension for alt text on demand for webpages? I guess my Twitter feed is pretty thin on images. - Chancey
I use Facebook more than Twitter, is there any way it could work there? - Gus
I don't want to make my images public. - Walei
Technical Choices
Firefox
I chose Firefox because it's a very popular browser amongst people who are blind, it works on PC and Mac, and because it has good extension development tools.
NVDA
I chose to demo using NVDA screen reader since it has the most robust support for Firefox on Windows.
Cloudsight API
The Cloudsight API is a proven description tool with reliable and accurate descriptions. Accuracy is important so that people using Alt Text Bot can rely on the descriptions being correct.
Technical Implementation
Alt Text Bot is written in vanilla JavaScript and compiled with the Firefox Addon SDK. It uses event handlers to respond to user interaction and API events, and asynchronous requests to get image descriptions. Alt Text Bot relies on ARIA markup to enhance the semantics of elements to improve screen reader support.
When the page loads
- sets ARIA live region attributes on all images so that the description is automatically announced (supported by NVDA)
- adds a red dashed visual border to show that the image has not yet been described (sighted users cannot otherwise know the state of the alt text)
- adds tabindex to images so that they can receive keyboard focus
- adds a button to the page next to each image to support multiple modes of interaction
- in the case of infinite scroll (Twitter, Facebook), reapply the above to new images loaded into the page
When the user clicks an image
- adds an ARIA "busy" flag to the image markup to announce to screen reader users that the image is processing
- updates the border to show sighted users that the image is processing
- temporarily disables clicks for the processing image
- sends the image url to the Cloudsight API
- polls the Cloudsight response endpoint for a description
When the description finishes
- removes the "busy" flag on the image
- updates the image border
- sets the description for the image
Responding to Feedback
Once I pivoted my focus to a browser extension, I looked for feedback every step of the way. Here are some of the changes I made based on interviews and usability sessions:
- better screen reader announcements about the current state of the image
- Readme with step by step instructions
- section on privacy in the Readme
- support for retrying description requests in case the first description is incomplete
Next Steps
Immediate Future
The immediate next steps for my work on Alt Text Bot extension is to build support for concurrent descriptions and to include an audio tutorial in the Readme so people have a better idea of what to expect from their screen readers. Also, I will be accommodating some of the differences between NVDA and JAWS so that the experiences are similar across the two screen readers.
Mid-term
In the mid-term I'm looking at supporting descriptions on mobile browsers and applications. I've done exploratory work with an iOS plugin that looks promising.
Long-term
In the longer term, I'll be looking at ways to improve the descriptions themselves using a call and response mechanism, where someone using Alt Text Bot can ask specific questions about the image.
I'm also in conversation with Twitter to share feedback on what I've learned and to encourage their work on supporting alt text natively.
Impact
By gaining attention and traction, Alt Text Bot can help motivate social product owners, bloggers, and developers to include alt text natively in their applications. In the meantime, Alt Text Bot is there to help fill the gap, making a real difference in the day-to-day experience of blind individuals and the conversations they'll be a part of.




Log in or sign up for Devpost to join the conversation.