-
-

AlphaSurface: A voice-first, spatially aware AI workspace that thinks alongside you, not for you.
-
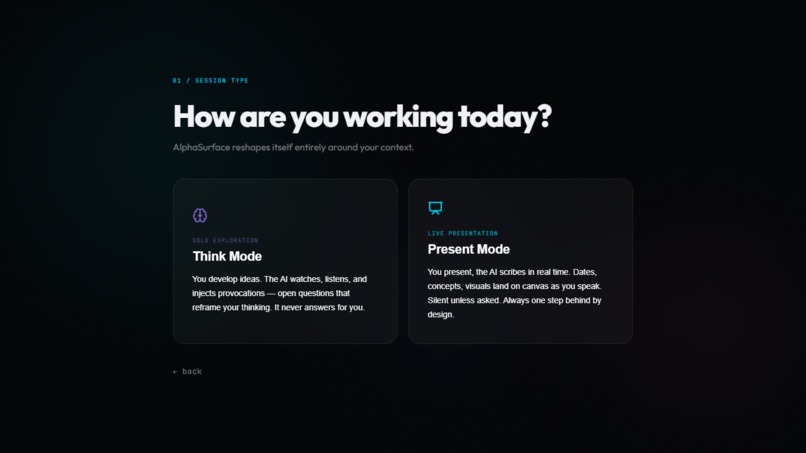
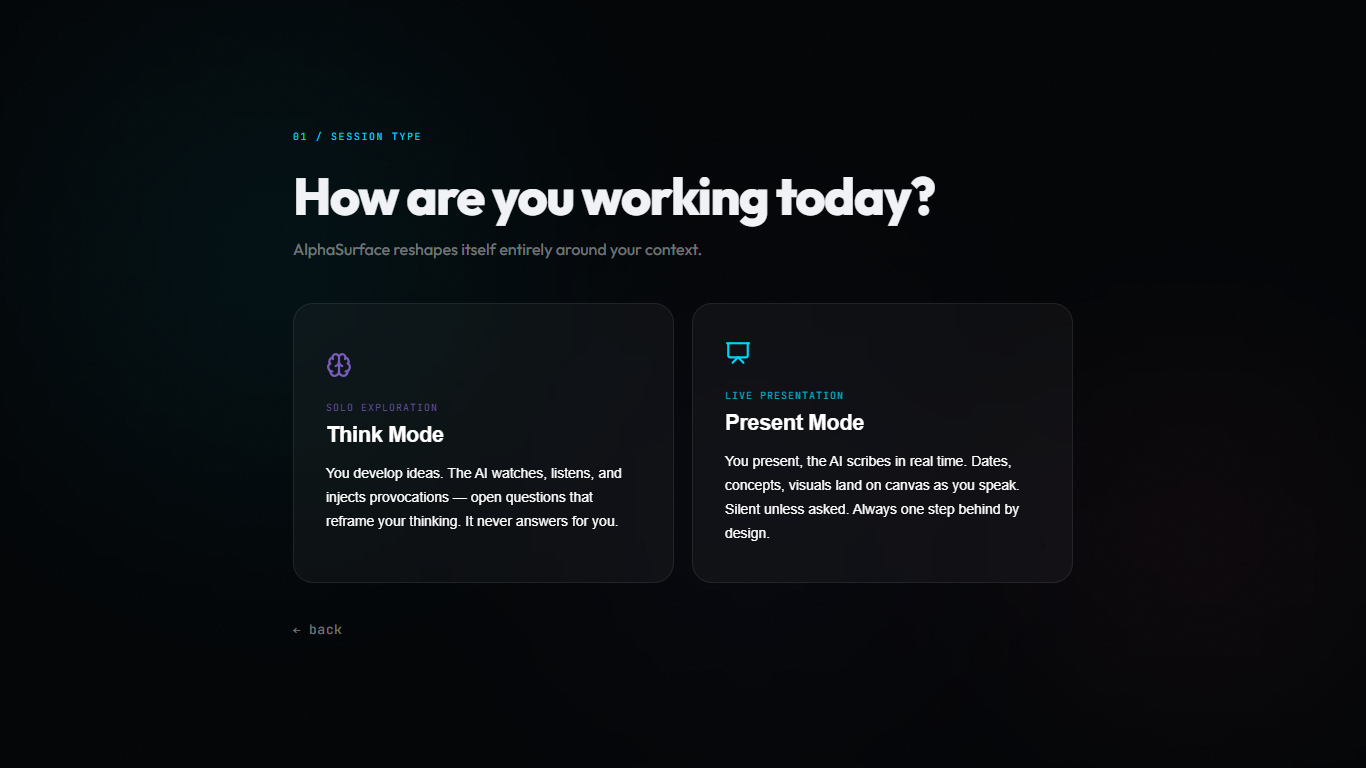
Two modes. One infinite canvas
-
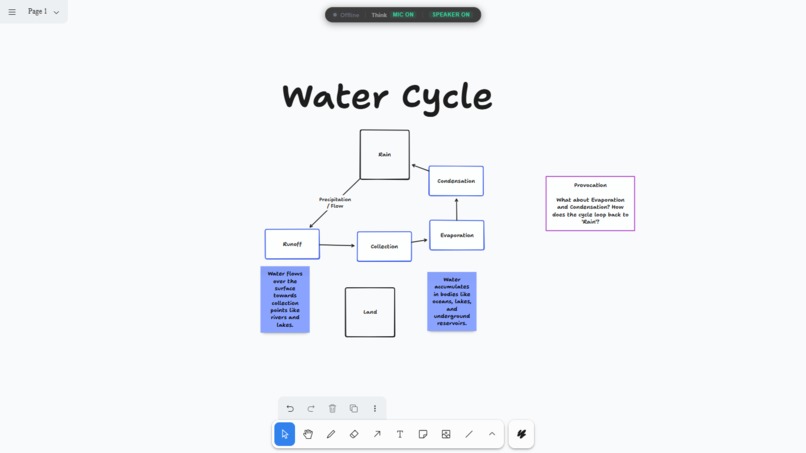
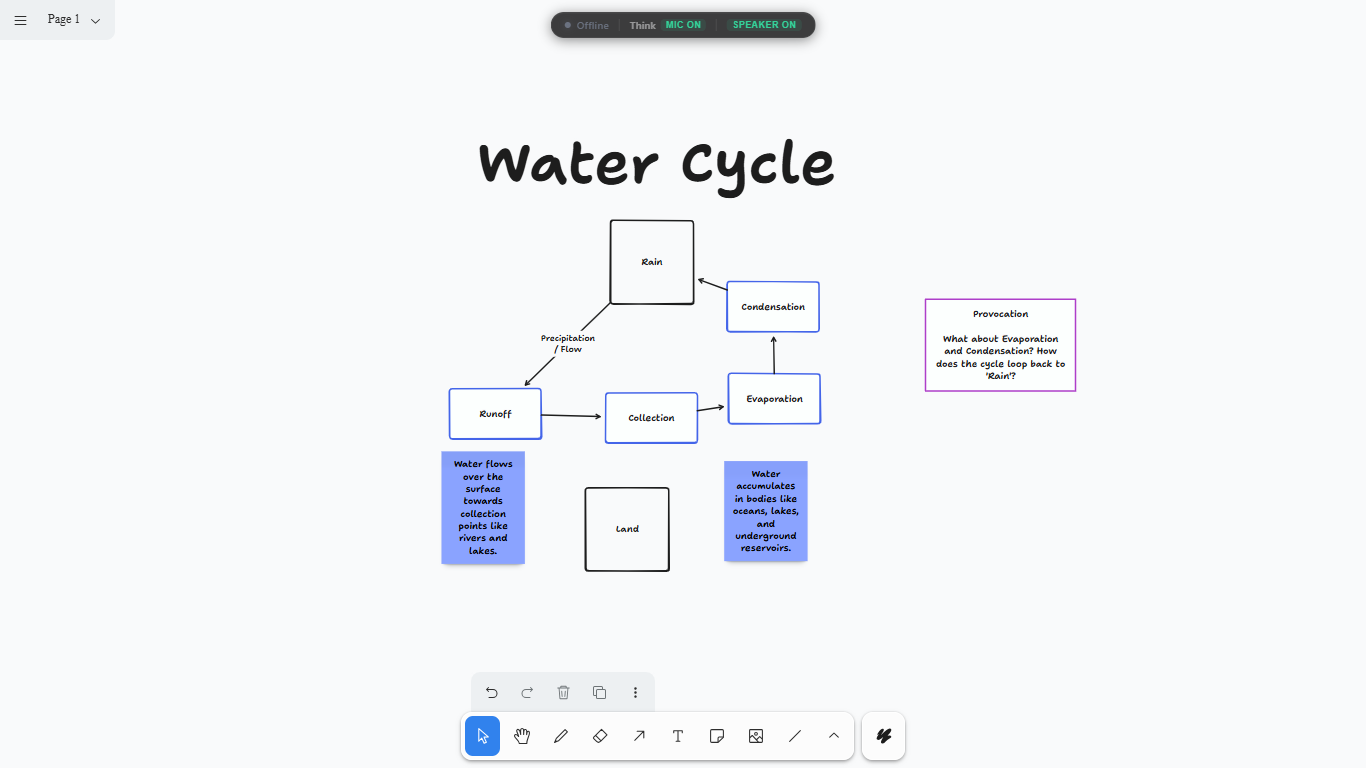
Water Cycle by AlphaSurface
-
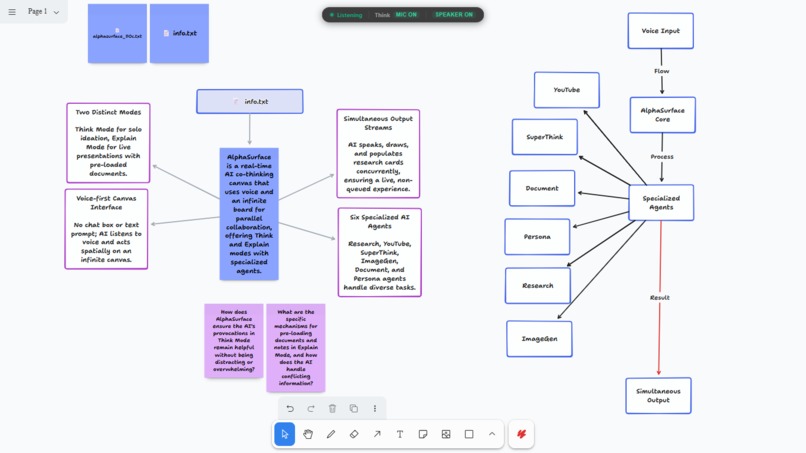
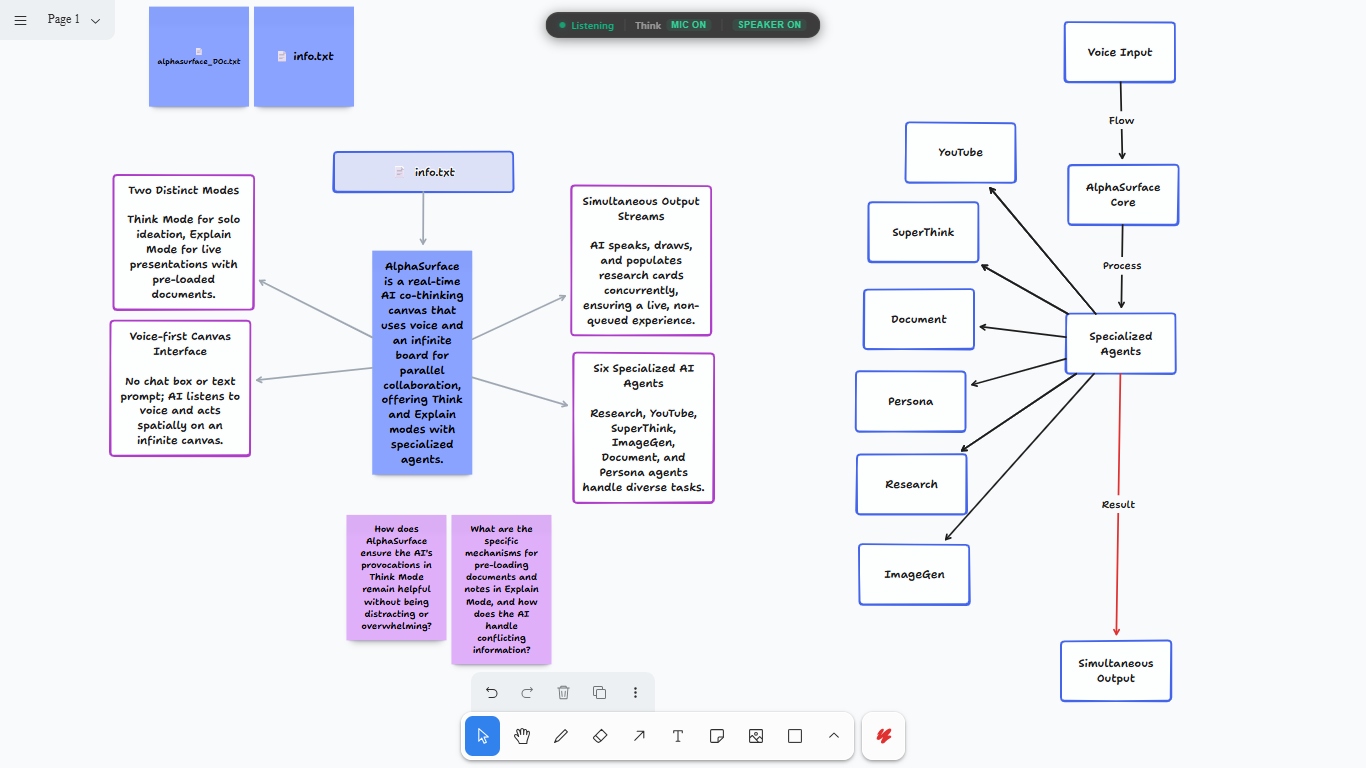
From raw text to a spatial mental model
-
 GIF
GIF
Navigating the control center: seamlessly bridge AI-driven brainstorming with traditional file management and canvas exports.
-
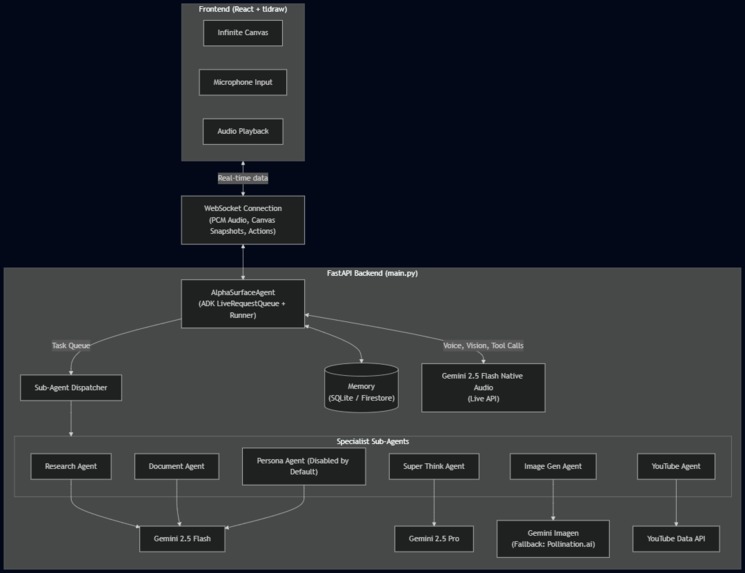
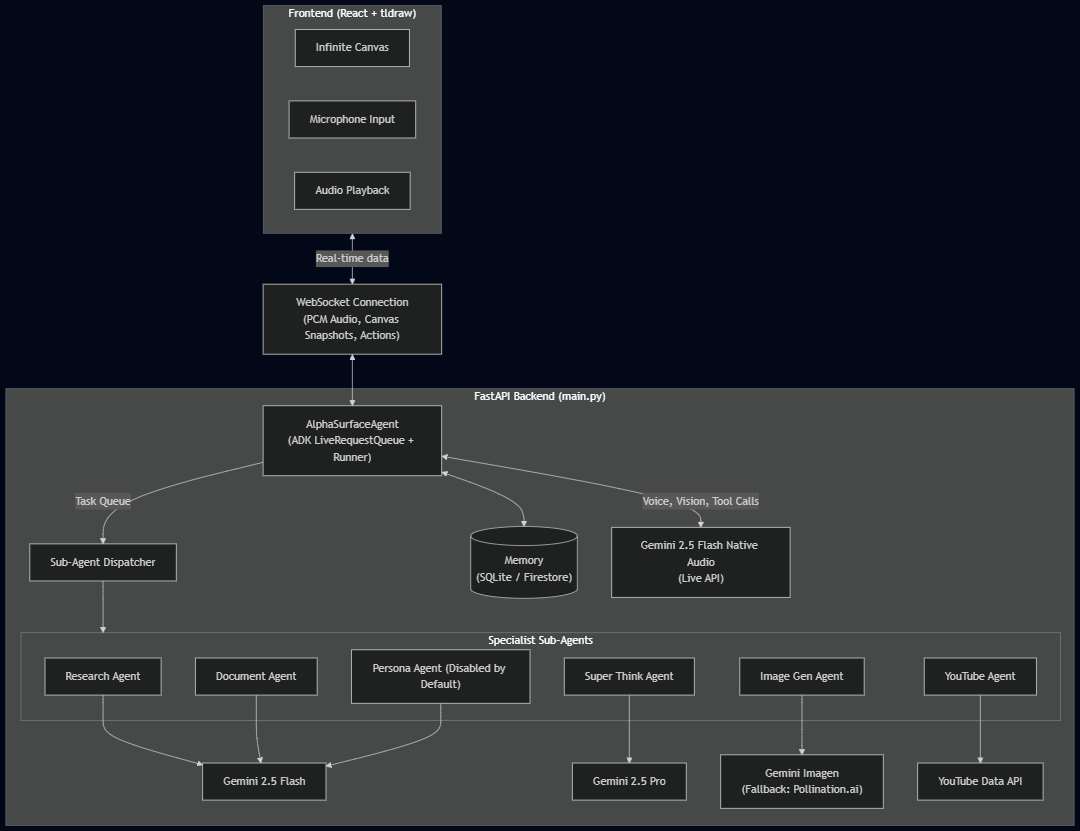
Alphaurface Architecture Diagram

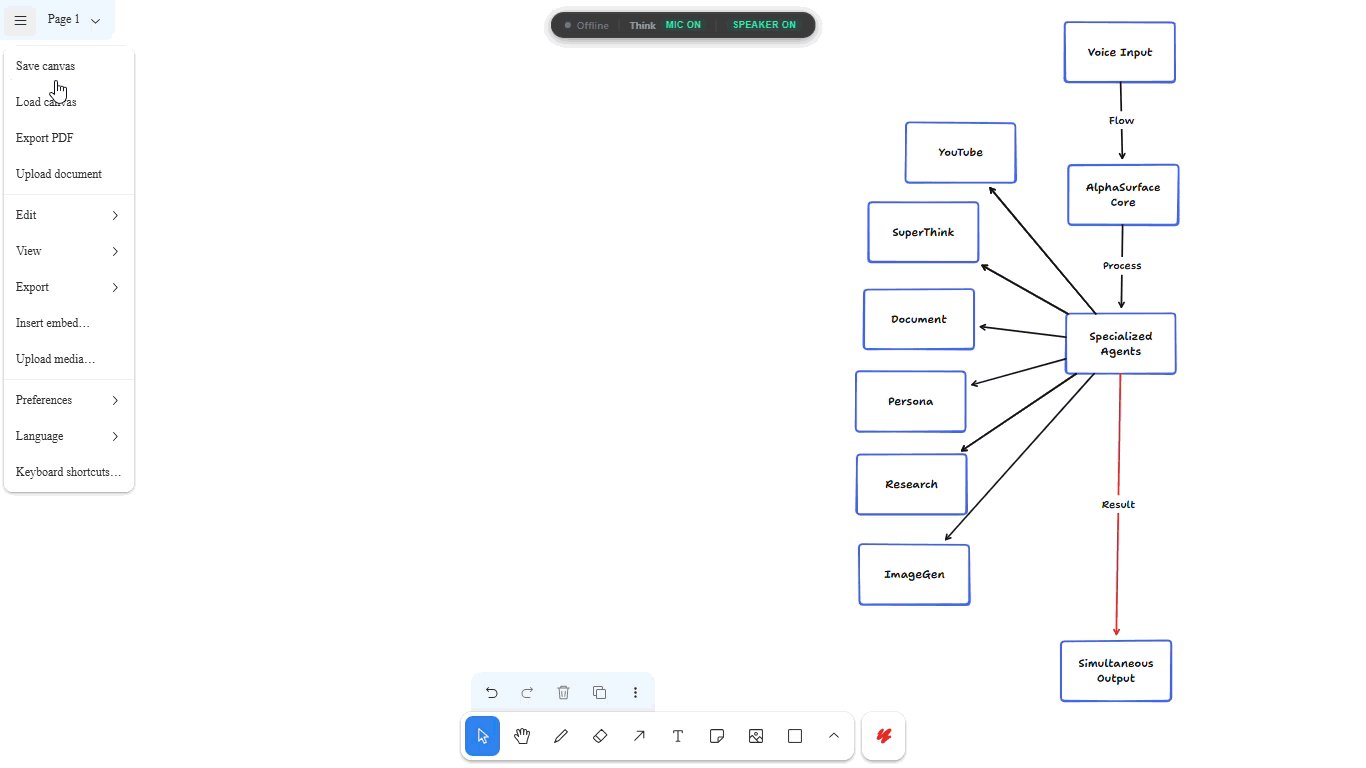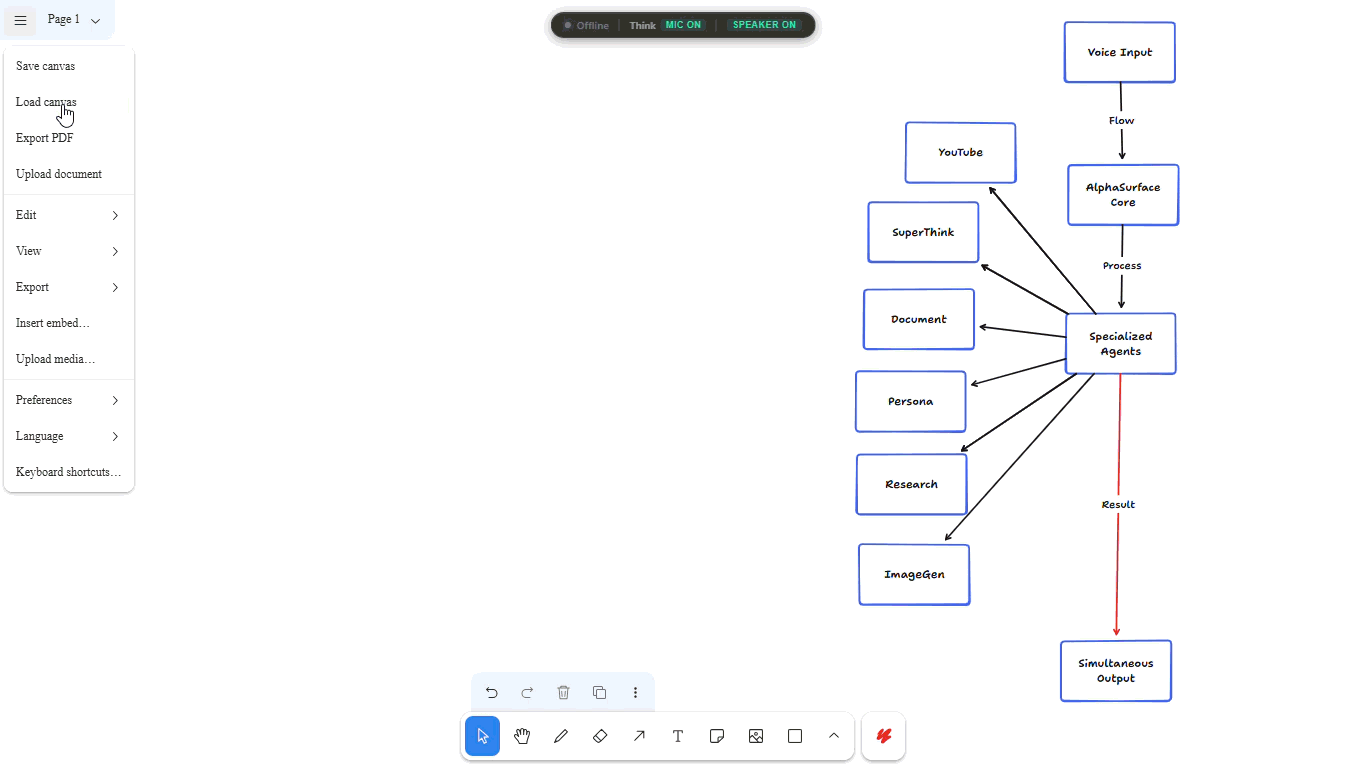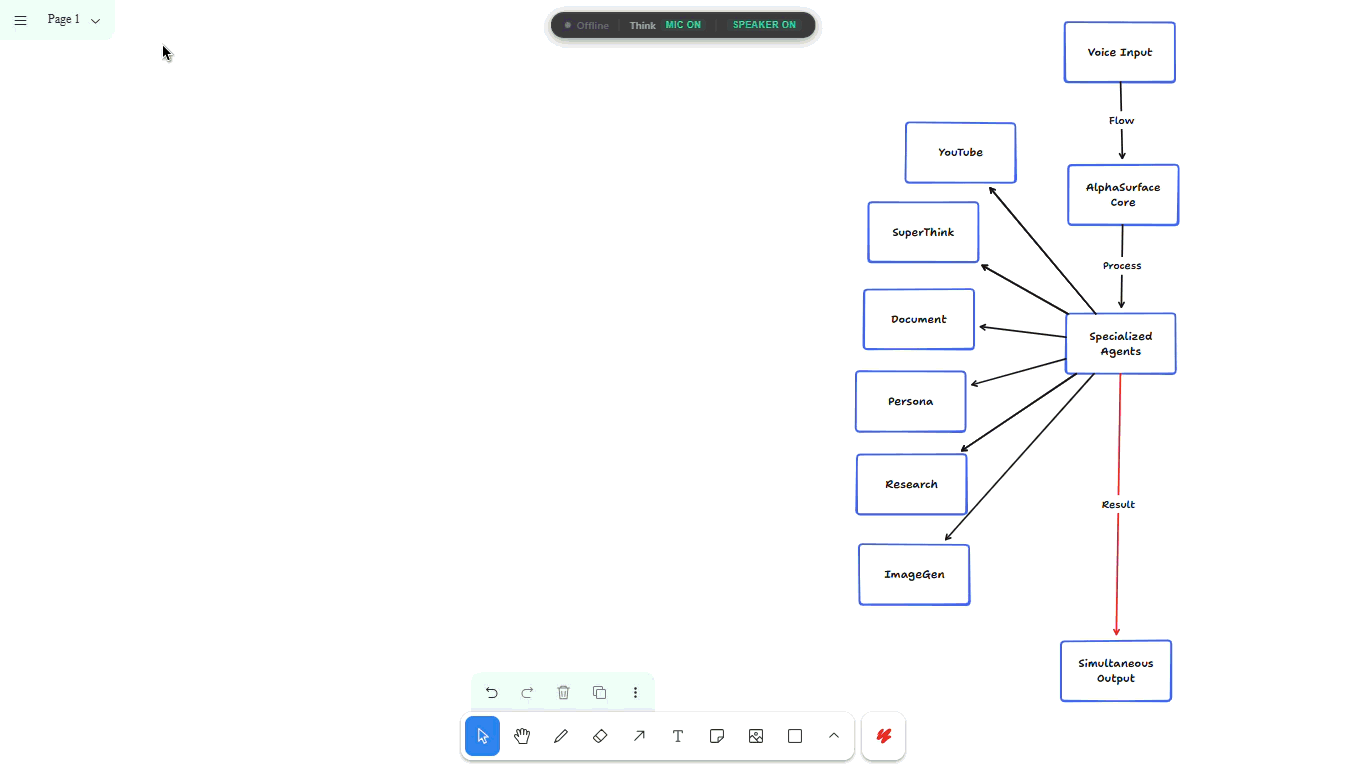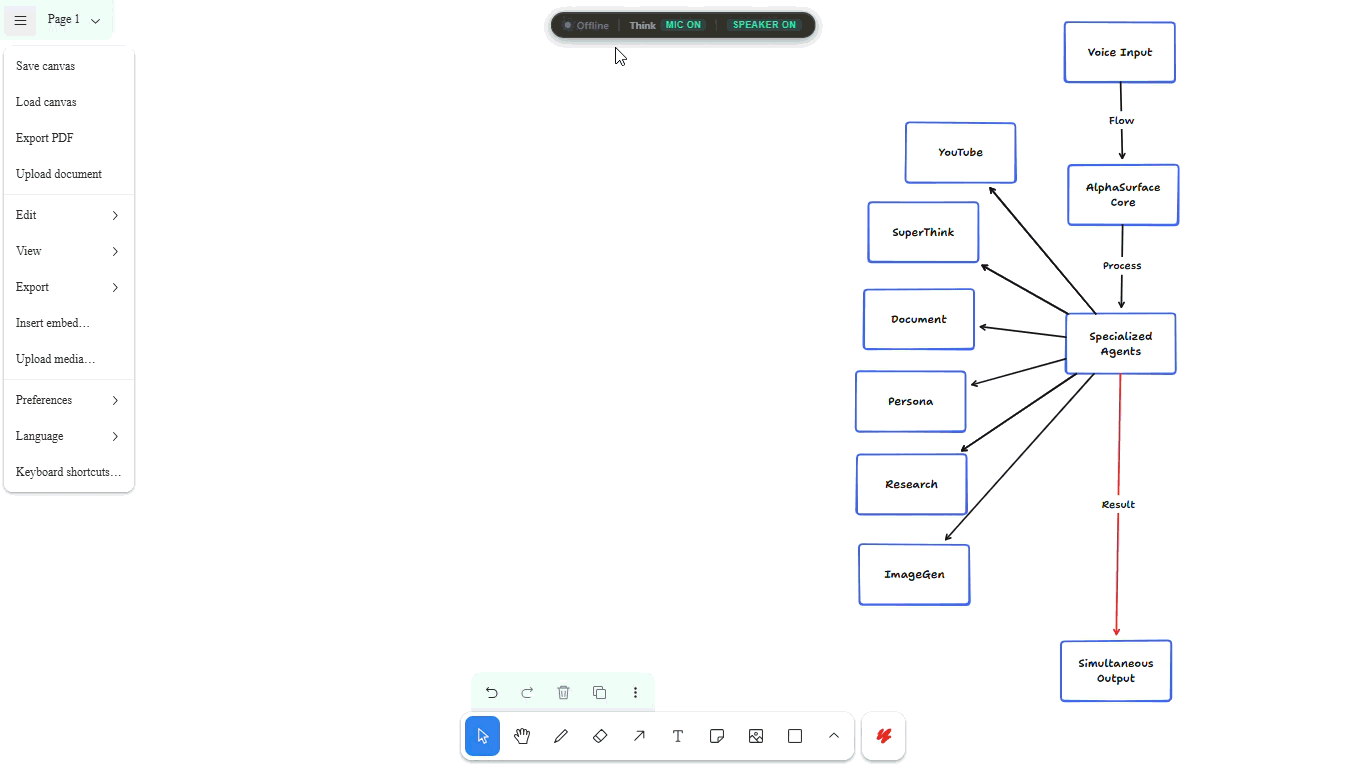
The Story of AlphaSurface
Inspiration
I spent four days straight arguing with Gemini about my hackathon idea. By the end, the chat thread was a chaotic, unreadable mess. It had lost the plot entirely—agreeing with things I had contradicted three prompts ago and burying my original premise under walls of generic text.
To fix this, I started opening parallel tabs. I used one tab strictly to test architectures and throw bad ideas at the wall. I used another purely to explain the refined, surviving ideas so the AI could spot patterns without getting confused by the scratchpad noise.
That's when I realized the problem with how we currently use large language models. I didn't want an AI that just gives me answers or acts like a yes-man. I wanted pushback. I wanted an interrogator.
Around that time, I watched Advait Sarkar’s video on AI and critical thinking. He asked a question that stuck with me: do we want tools that think for us, or tools that make us think? That single concept became the foundation of AlphaSurface. I also realized I needed a better way to explain my chaotic mental scratchpad to my friends. I imagined a canvas that could visually map out my thoughts in real-time as I spoke, acting as a visual co-pilot.
What it does
AlphaSurface is a spatial, real-time co-thinking canvas. It completely abandons the traditional text-box interface.
It has two main environments. "Think Mode" is a provocation engine. Instead of generating a finished product for you to blindly copy-paste, the canvas actively challenges your assumptions. If I drop a sloppy architecture plan on the board, it shouldn't just write the code for it. It should ask me where the bottlenecks are and force me to look deeper into my own logic.
"Explain Mode" is the translation layer. When I'm trying to explain a complex idea to someone else, the canvas stays one step behind me, turning my speech into connected visual nodes and reference cards so the person I'm talking to can actually follow my train of thought.
I run six different agents on this board to make it work:
- SuperThink runs in the background. It maps out multi-step logic visually so you can actually see its reasoning traces.
- Persona watches how you use the board and adapts on its own. You don't have to tweak system prompts or write a manual of rules; it just learns your workflow.
- Document handles PDF chunking so you can drag files onto the board and talk to them.
- Research runs live web searches and drops them as interactive cards right where you're working.
- YouTube hunts down relevant videos and embeds them on the board for playback.
- ImageGen turns natural language into visual anchors.
My mental model for the whole project boils down to this:
$$\lim_{\text{Friction} \to 0} \left( \frac{\text{Human Imagination} \times \text{Provocative AI}}{\text{Traditional Chatbot}} \right) = \text{AlphaSurface}$$
How I built it
I built the visual interface on top of the tldraw SDK. If you've ever tried building an infinite, panning whiteboard from scratch, you know it's a nightmare of state management and canvas rendering. tldraw gave me all the spatial primitives out of the box—zooming, drawing, and shape management—so I could actually focus on making the AI interact with those shapes instead of reinventing the wheel. I orchestrated the agent logic using the Google Agent Development Kit (ADK). The backend relies on FastAPI and WebSockets.
This specific architecture is what lets the AI speak to me out loud, draw a flowchart node on the screen, and run a web search all at the exact same time. The ADK was actually great for this. It handled a lot of the heavy lifting for agent routing and saved me from having to write mountains of boilerplate code from scratch.
Challenges I ran into
The debugging process was brutal. I completely botched my Google Cloud billing on day one. I thought linking my card was enough to unlock the hackathon free credits, but I missed the identity verification step until it was too late. I blew through my free tier limits immediately. Getting locked out by quotas when you just want to test a single prompt behavior is agonizing. At one point, I had to hot-swap to Pollinations AI just to keep testing my image generation nodes while my Gemini limits slowly reset.
The backend code fought me just as hard. I drowned in 1008 WebSocket errors and 429 rate limit warnings. The connection would inevitably drop right when a brilliant thought was forming. I had to gut and rewrite live_session.py to handle audio streaming and canvas snapshots simultaneously without crashing the whole application.
The ADK versioning was a massive headache too—pulling a model from v1alpha kept silently defaulting to v1beta, which broke features I was relying on. Then there was the audio barge-in issue. If the AI is rambling and I interrupt, the front-end audio buffer needs to clear instantly. Otherwise, the AI keeps talking over me for three seconds while the backlog plays out. Building the logic to flush that buffer the exact second I started speaking took ridiculous precision.
Accomplishments that I'm proud of
I'm genuinely proud of getting six different agents to fire off parallel actions on a shared canvas without stepping on each other's toes. Watching the AI speak, pull a YouTube video, and draw a logic node simultaneously—and actually having all of it match the context of my live audio—was a huge win.
I'm also really happy with how the Persona agent turned out. Usually, personalization in AI means forcing the user to fill out a giant settings form. Having an agent that just quietly picks up on your habits and adapts its output naturally feels like a massive step forward in UX.
What I learned
Seeing this actually work changed how I view large language models. They don't have to be passive chat interfaces waiting for you to type a prompt. You can build an environment that acts as an active, spatial collaborator. AlphaSurface proved to me that I can build tools that amplify human imagination instead of just automating it away. The tech is there; I just have to stop putting it in standard chat windows.
What's next for AlphaSurface
The immediate next step is proper multiplayer collaboration. Right now, I can explain my ideas visually to an observer, but I want multiple users inside the canvas at the exact same time, interacting with the agents collaboratively.
The Persona agent also needs real long-term memory. If I map out an architecture on a Tuesday, I shouldn't have to re-explain those constraints when I start a new session three weeks later. It should just know. Finally, I'm planning to tighten up the Document agent with proper chunking and throw in autocomplete so the whole board feels faster.
Built With
- asyncio
- fastapi
- gemini-2.5-flash
- gemini-2.5-pro
- gemini-api
- google-agent-development-kit-(adk)
- javascript
- pollinations-ai
- python
- react
- tldraw-sdk
- uv
- vite
- websockets
- youtube-data-api-v3



Log in or sign up for Devpost to join the conversation.