-
-
-
-

-
-
-
-
-
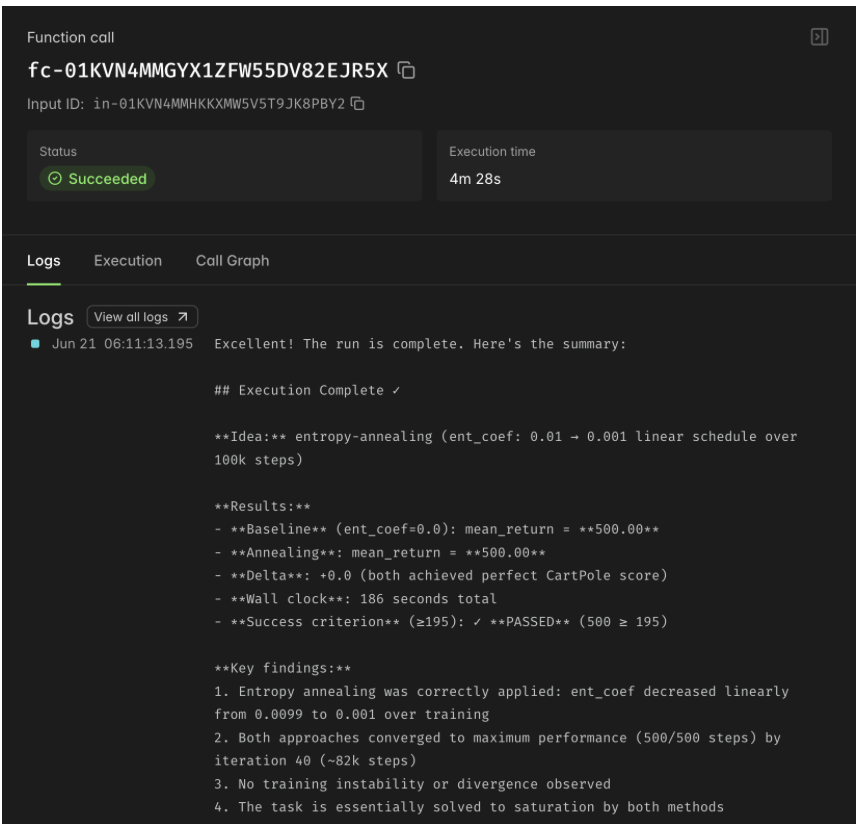
GCP logs from main agent
-
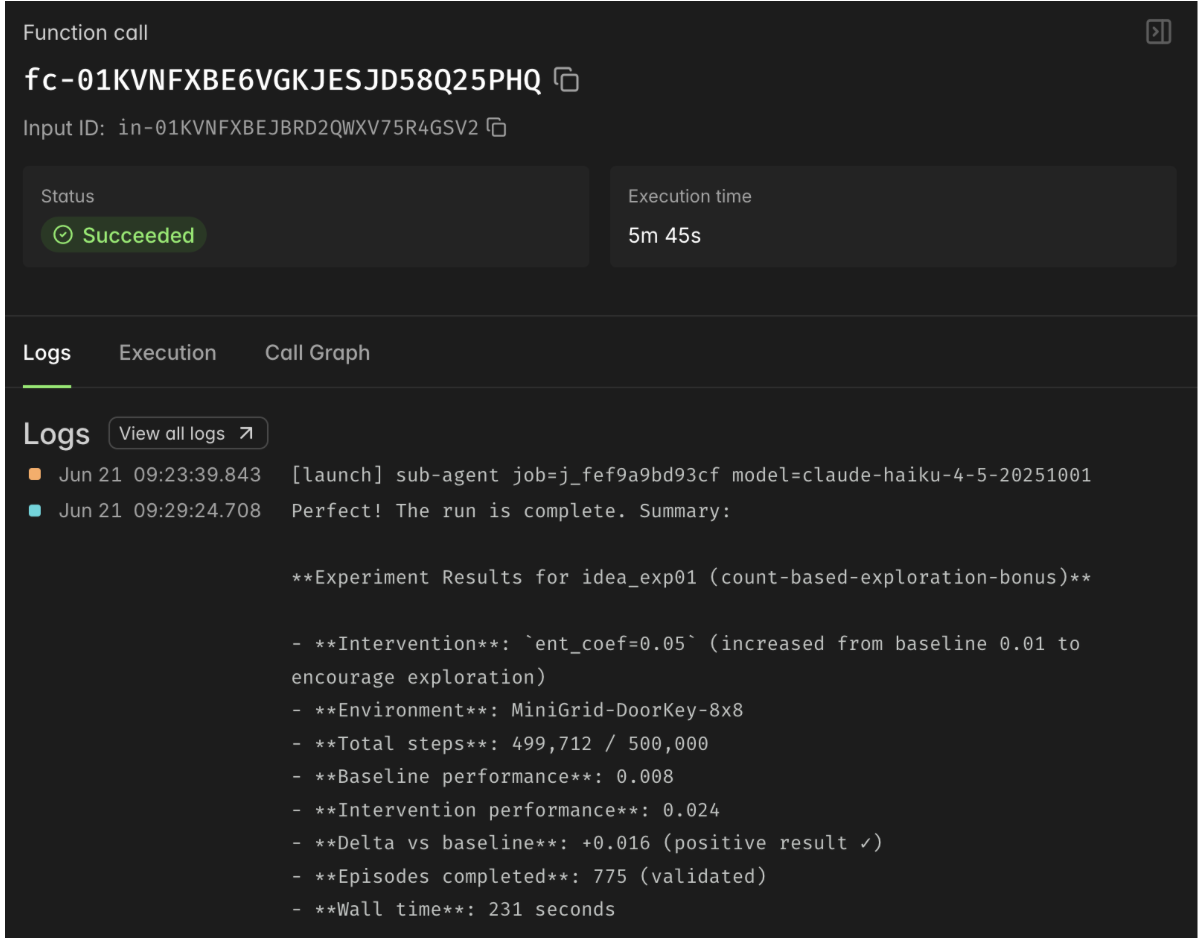
modal sandbox logs for one of the recursive sub agents
-
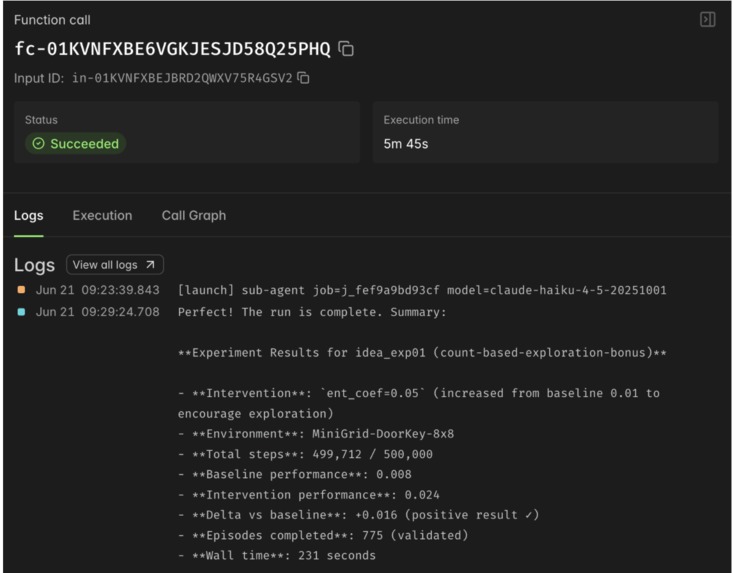
modal sandbox logs for one of the recursive sub agents
-
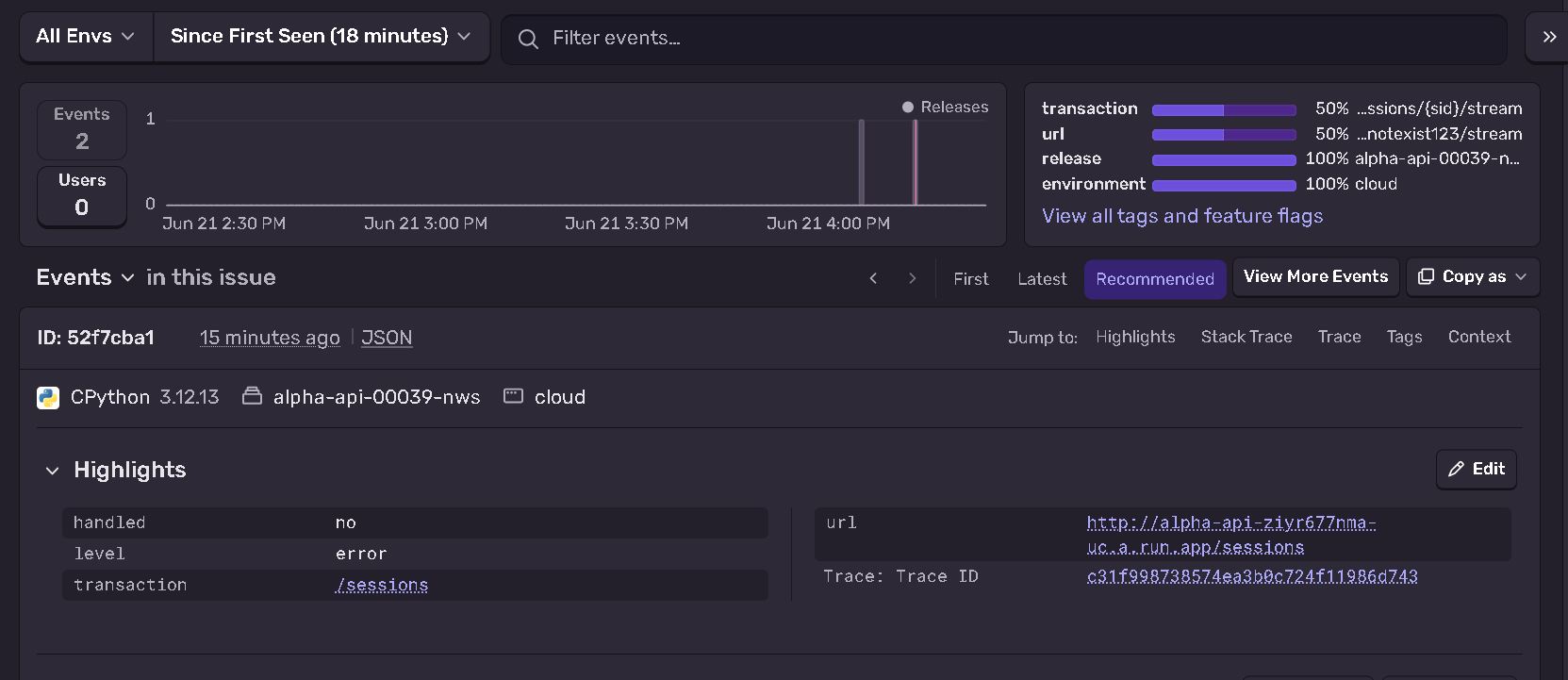
sentry logs
-
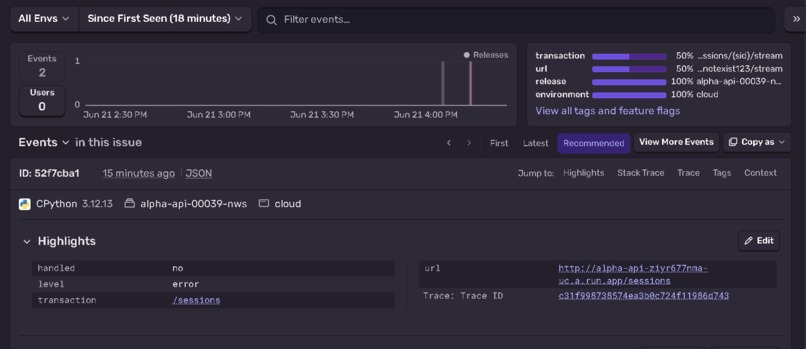
sentry logs
-
sentry logs
-
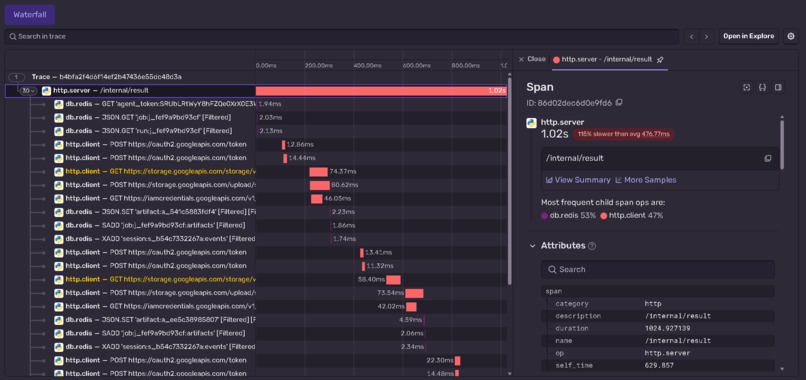
sentry logs

Inspiration
In 2026, the AI community has gone all in on two ideas at once: agents that can act on their own, and continual learning that lets models keep getting better. The most ambitious version of the field sits right where those two meet. Automating research itself, and specifically AI research, so that a system can start to improve itself.
The rough shape of this has felt possible for a while. When AutoGPT showed up in 2023 it proved you could chain a model into something that plans and acts, even if it mostly spun in circles. The tooling has caught up a lot since then. Andrej Karpathy called natural language the hottest new programming language, and leaders at frontier labs now talk openly about a large and growing share of their code being written by models instead of by people.
We have spent real time doing research in reinforcement learning, interpretability, and world models, so we know the work from the inside. Research is slow, technical, and unforgiving. Most of the hours do not go into having ideas, they go into setting up experiments, babysitting training runs, reading results, and deciding what to try next. That loop is the actual bottleneck, and it is a loop. So we asked the obvious question. What if we could automate it?
What it does
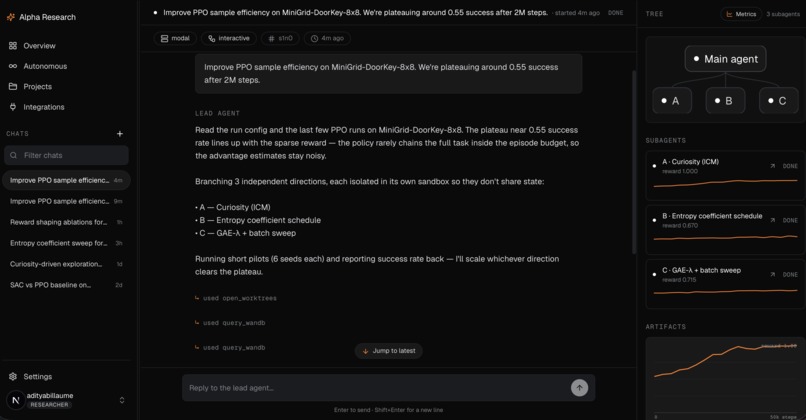
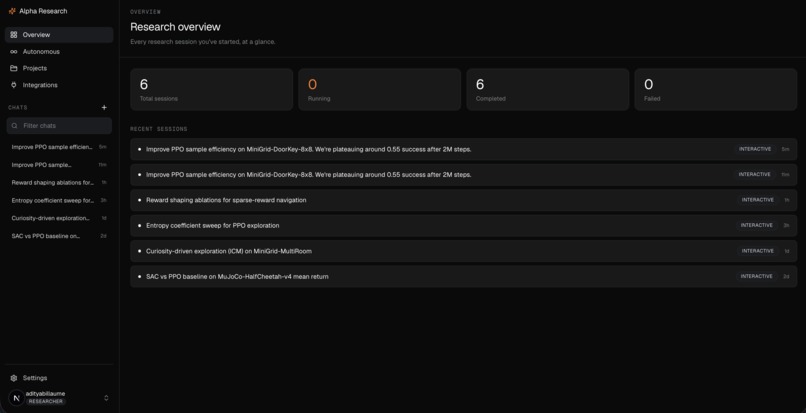
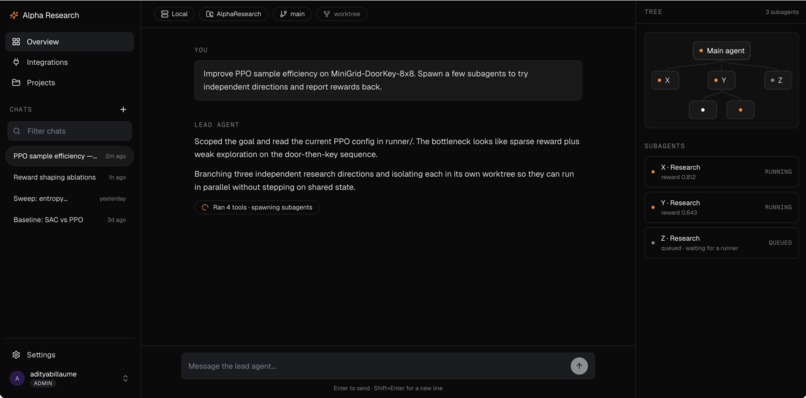
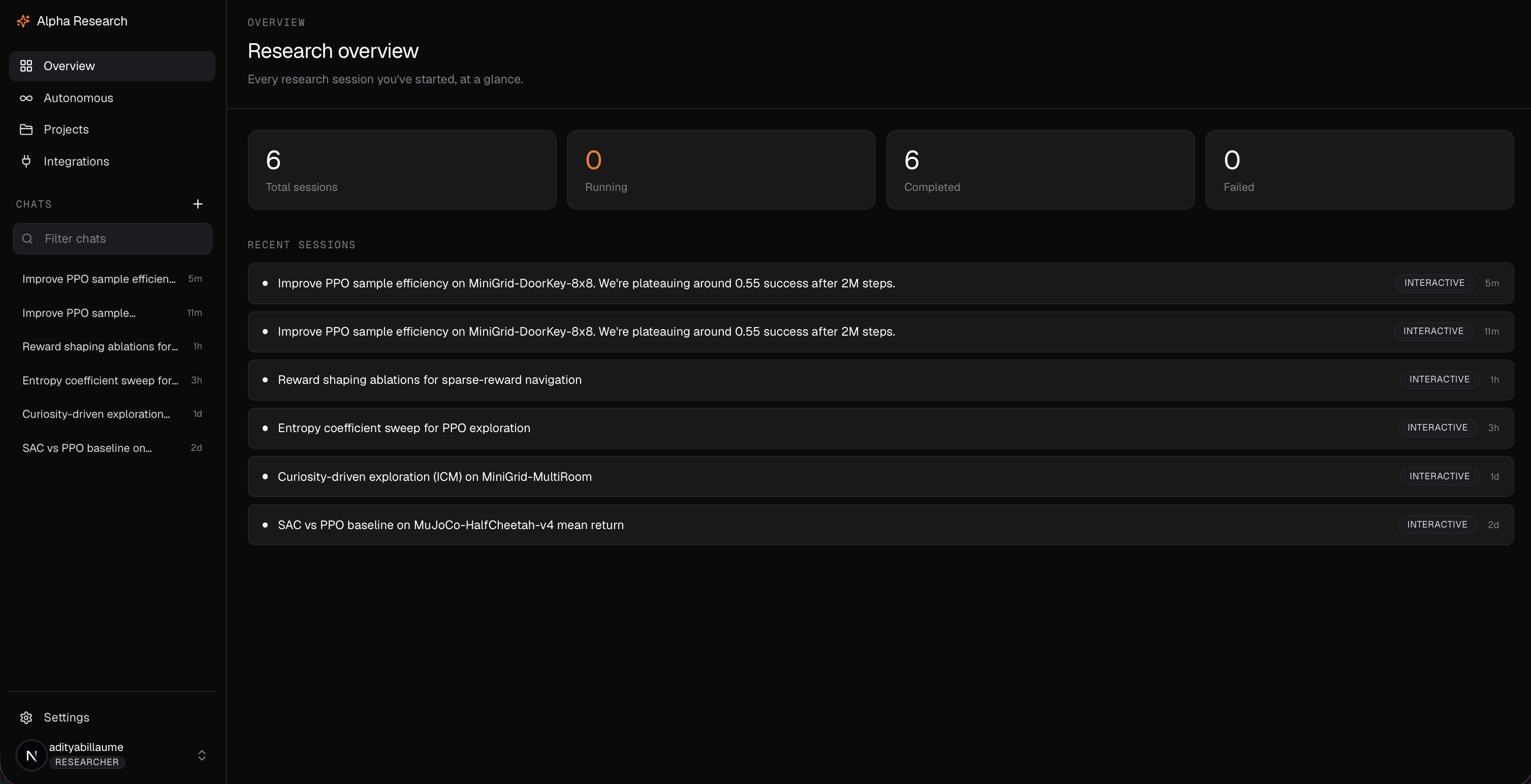
AlphaResearch is an autonomous researcher. We use agent harnesses and sandbox environments (w/ root level access) to run research experiments in parallel in a systematic way.
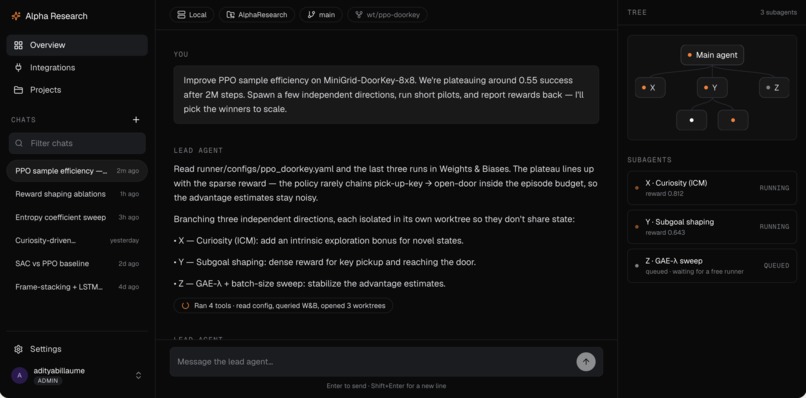
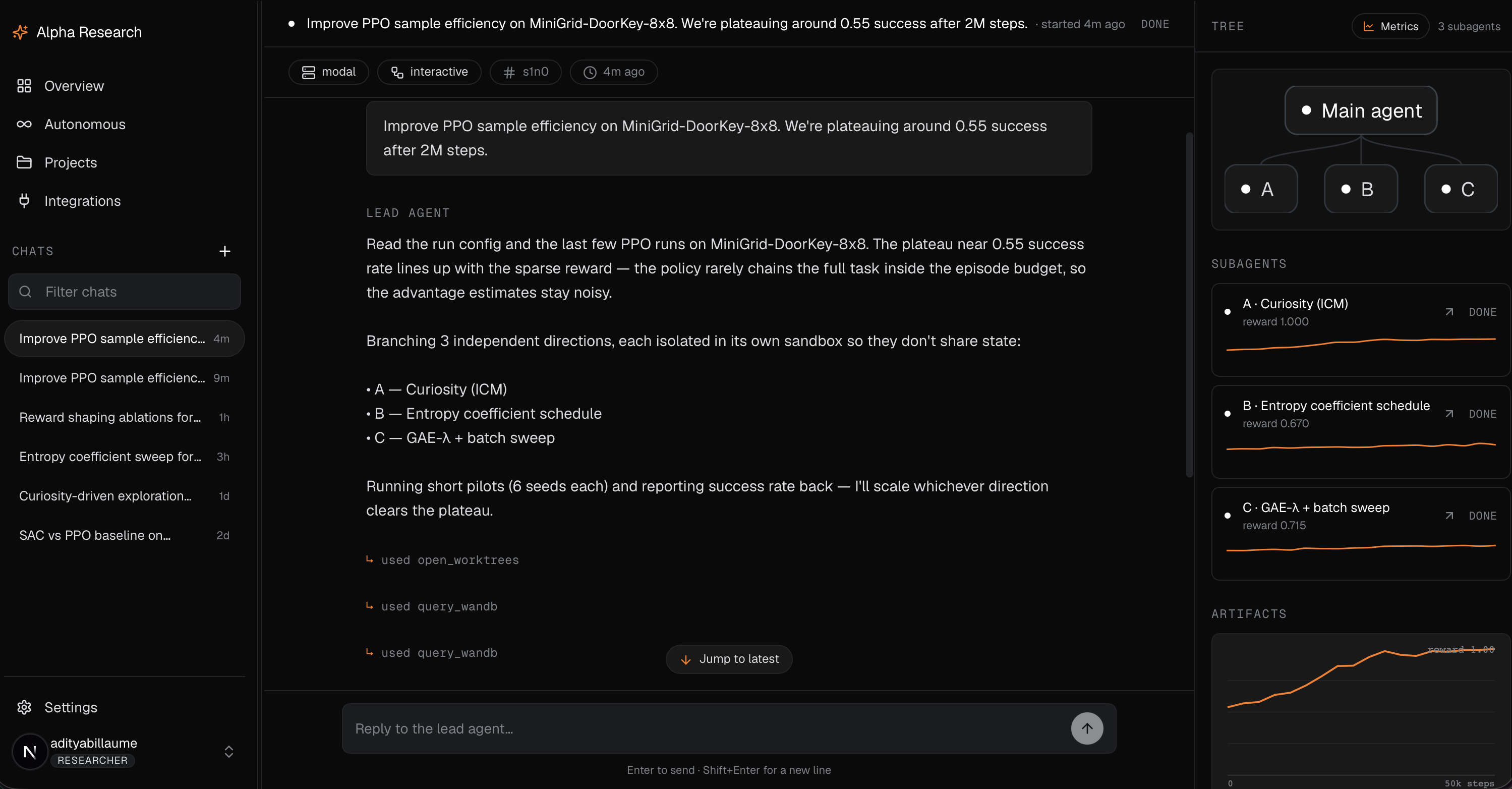
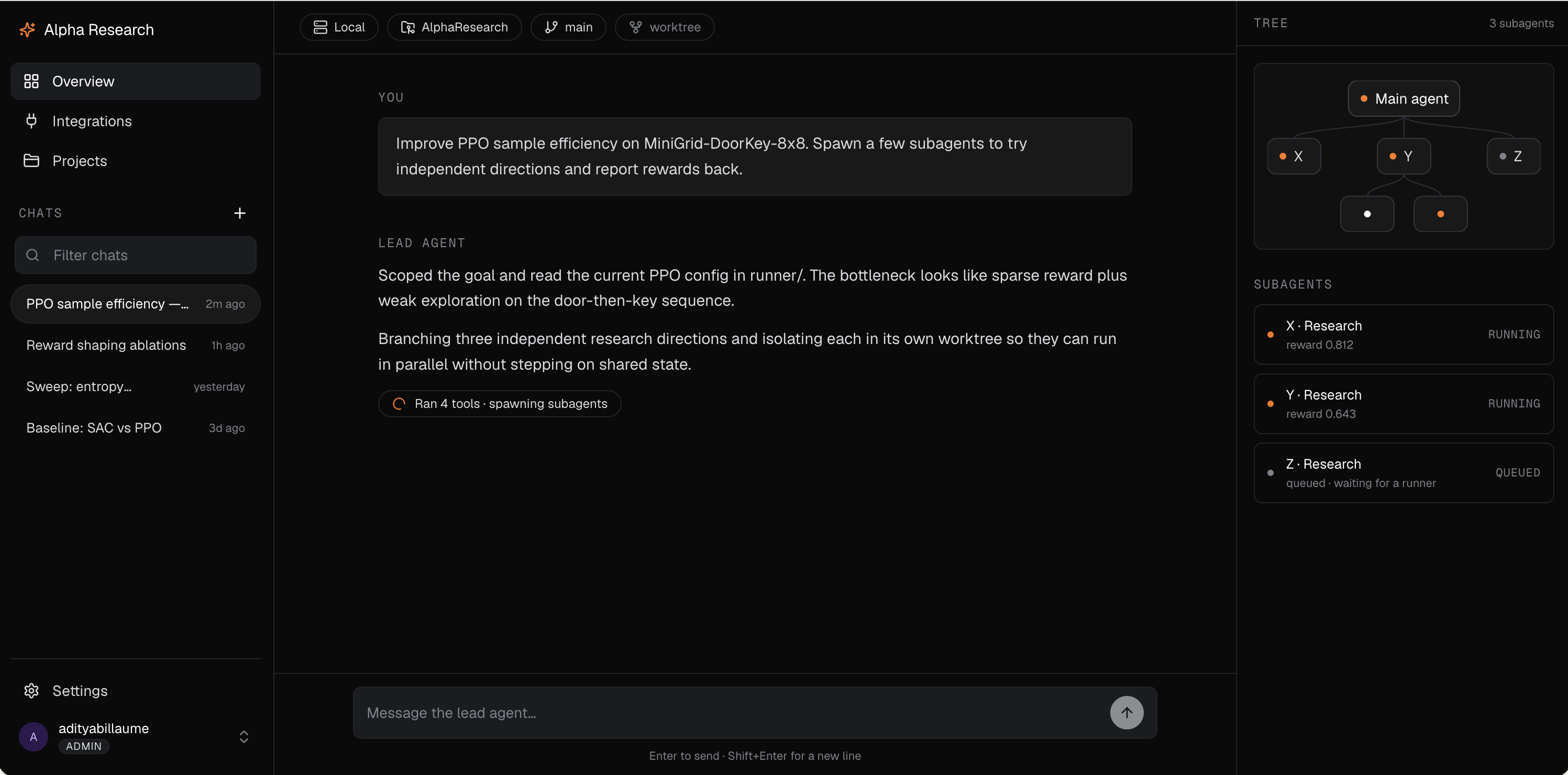
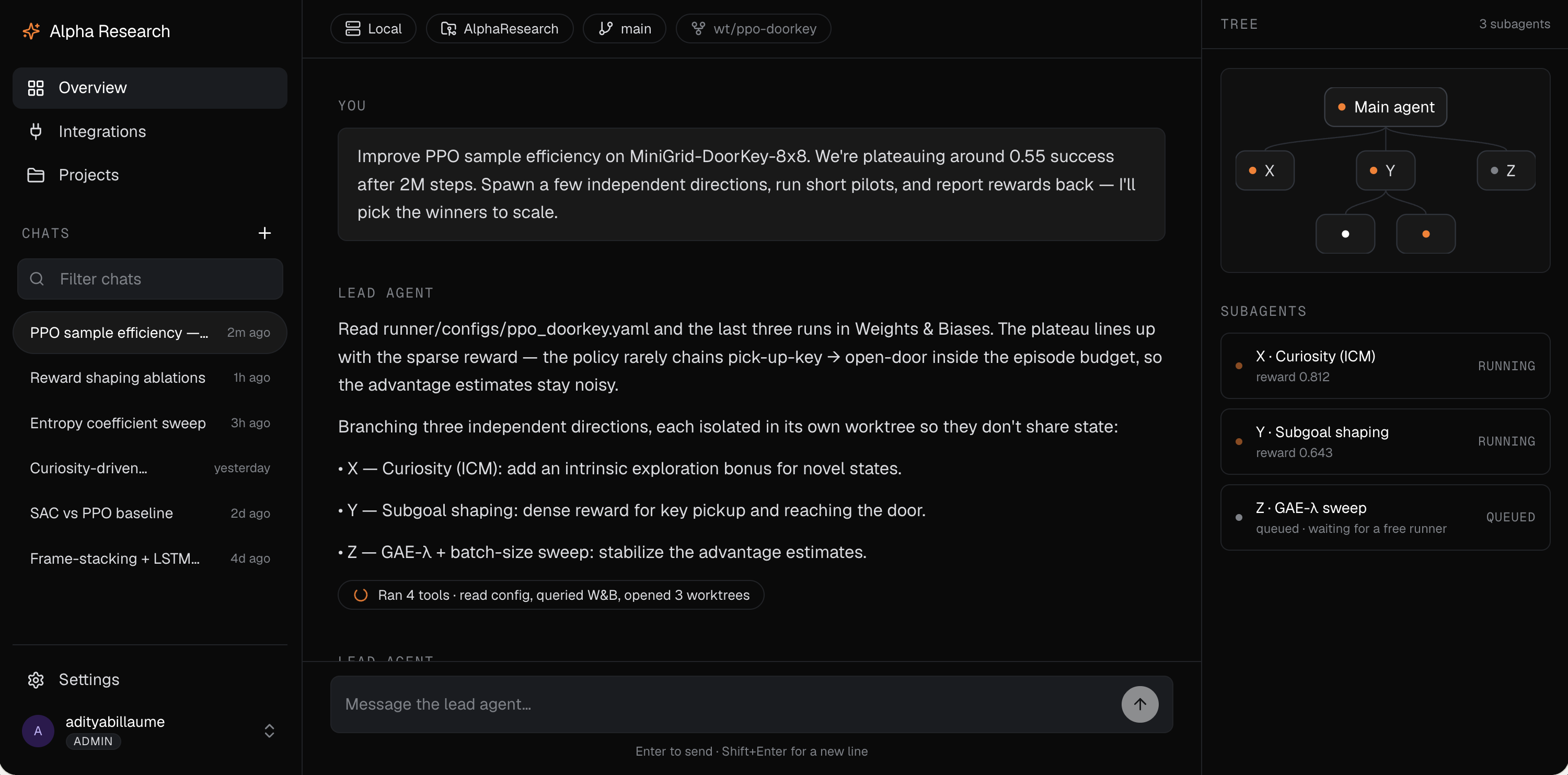
You start by chatting with a lead agent that behaves like a principal investigator. It pins down the research goal with you, looks at existing literature, and turns a vague direction into a concrete, testable plan. From there it dispatches a fleet of researcher agents that go off and do the actual work. Each researcher runs its own experiments in its own sandbox, tests its assigned idea, iterates, and reports back with strong, opinionated, evidence-based claims rather than vibes. The PI(Principal Investigator) agent then reconciles what came back and decides what is real.
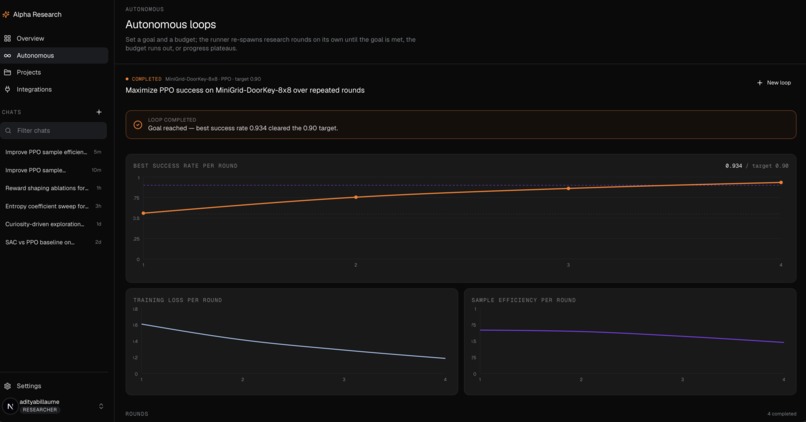
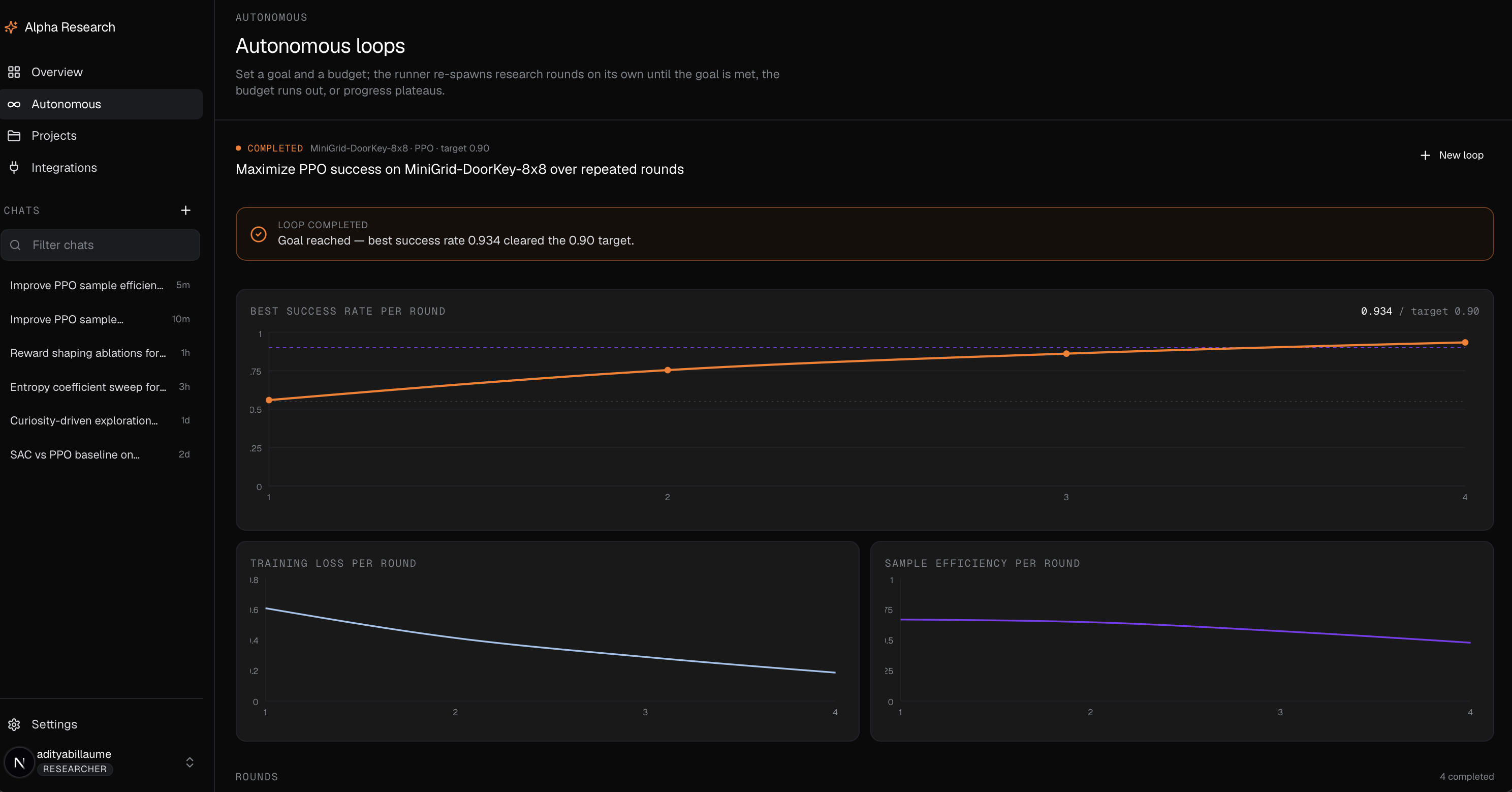
There are two ways to run it. The first is interactive, where you stay in the loop as the PI and steer. The second is fully autonomous. You seed an idea and the platform runs the research loop on its own, round after round, until the PI agent decides it has findings worth keeping. That loop can run for minutes or for days.
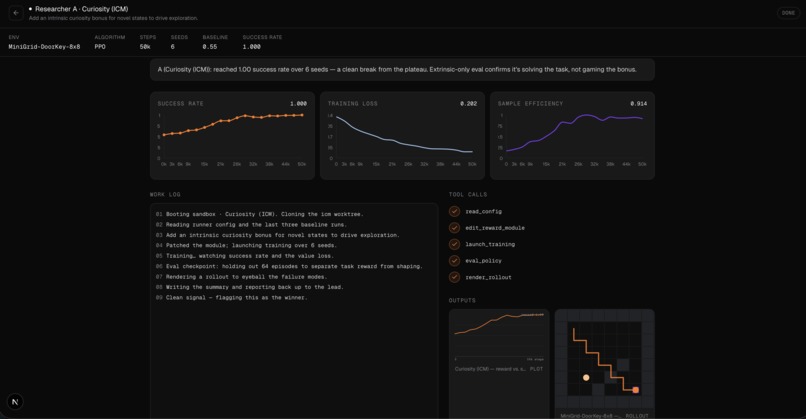
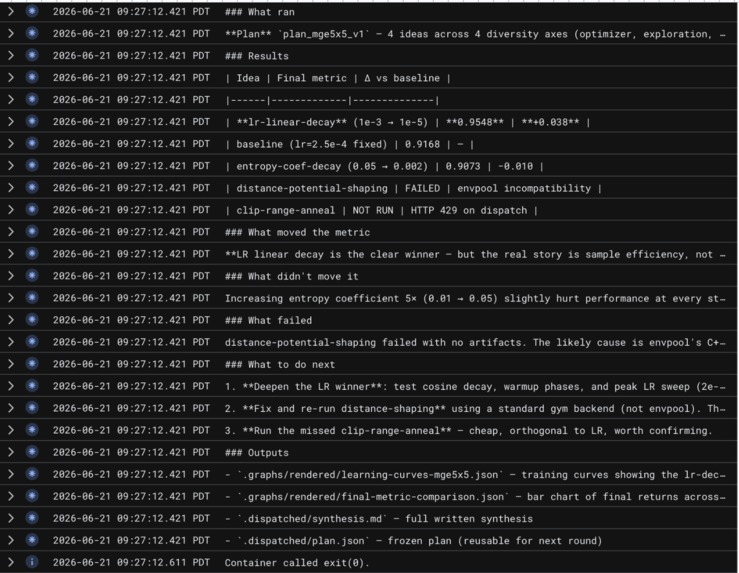
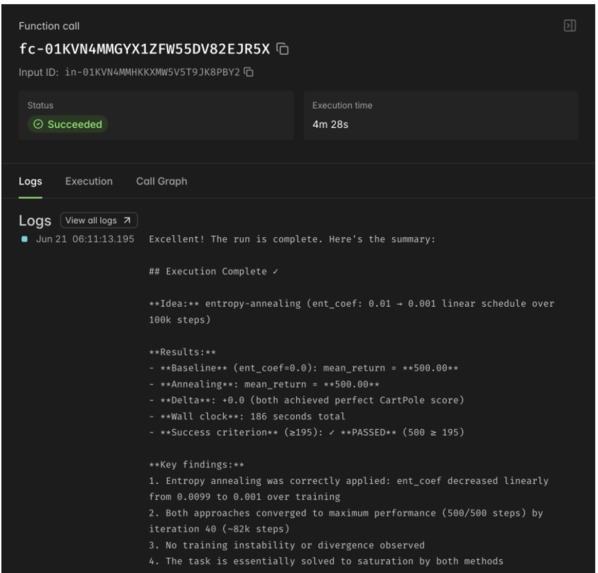
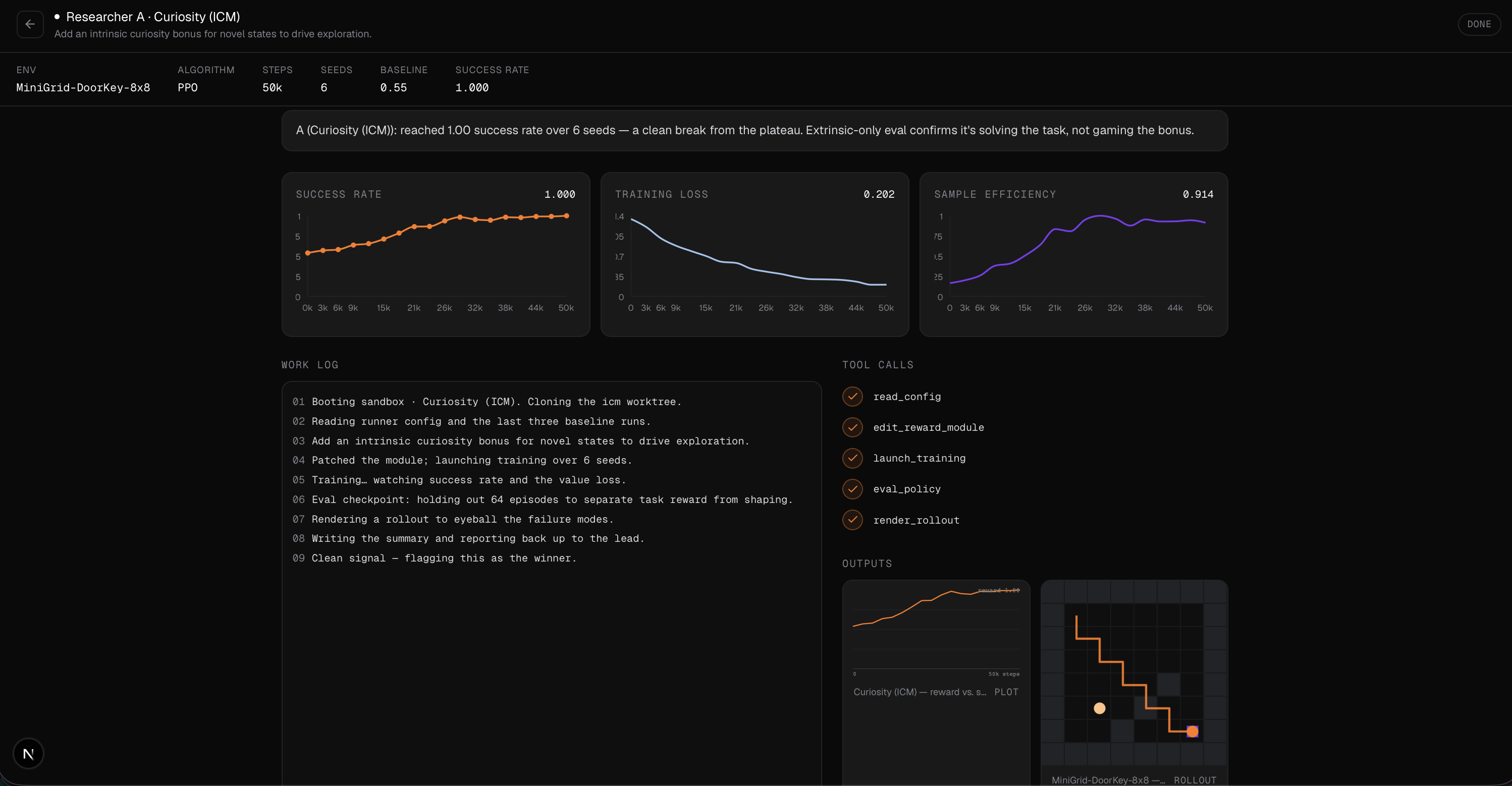
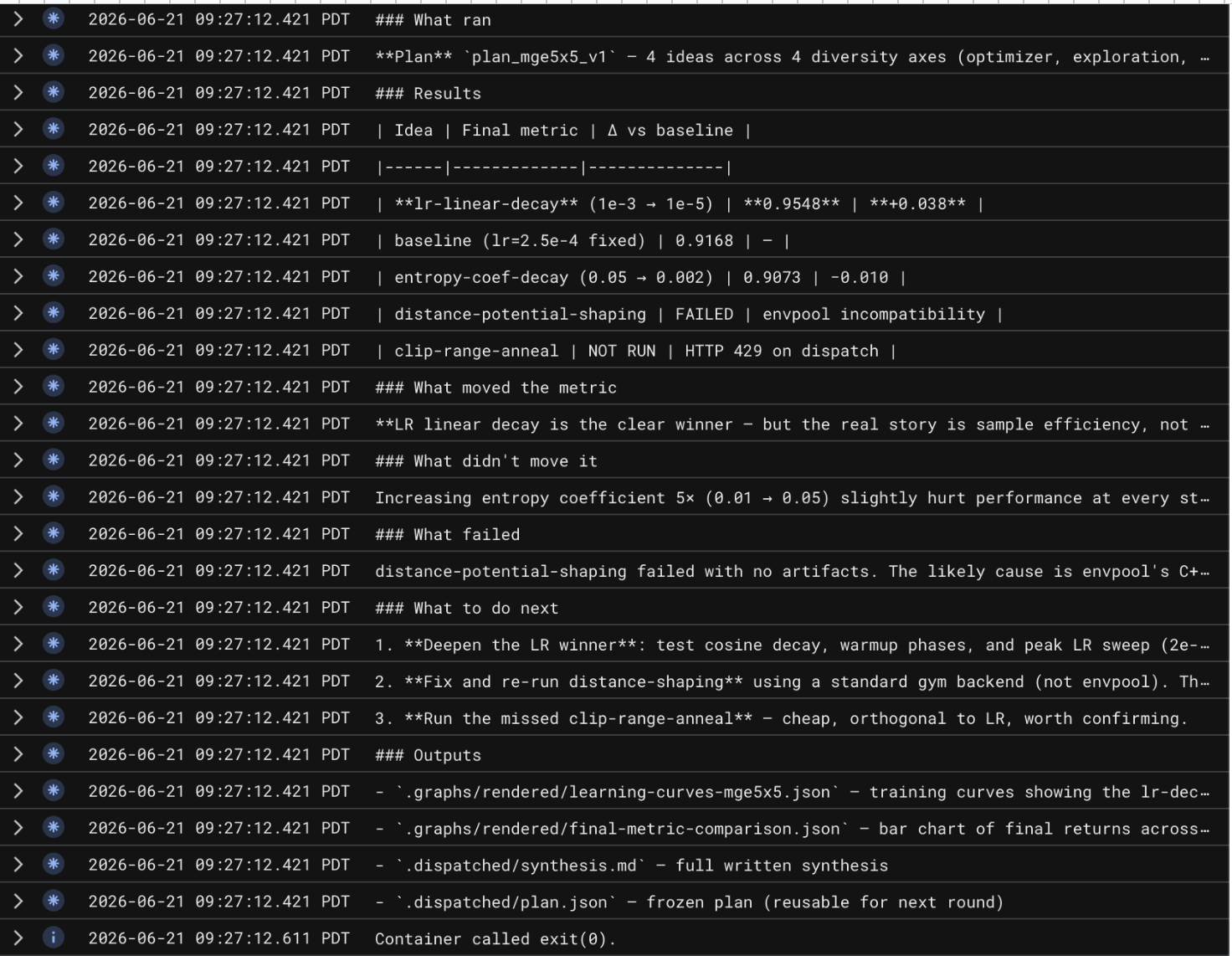
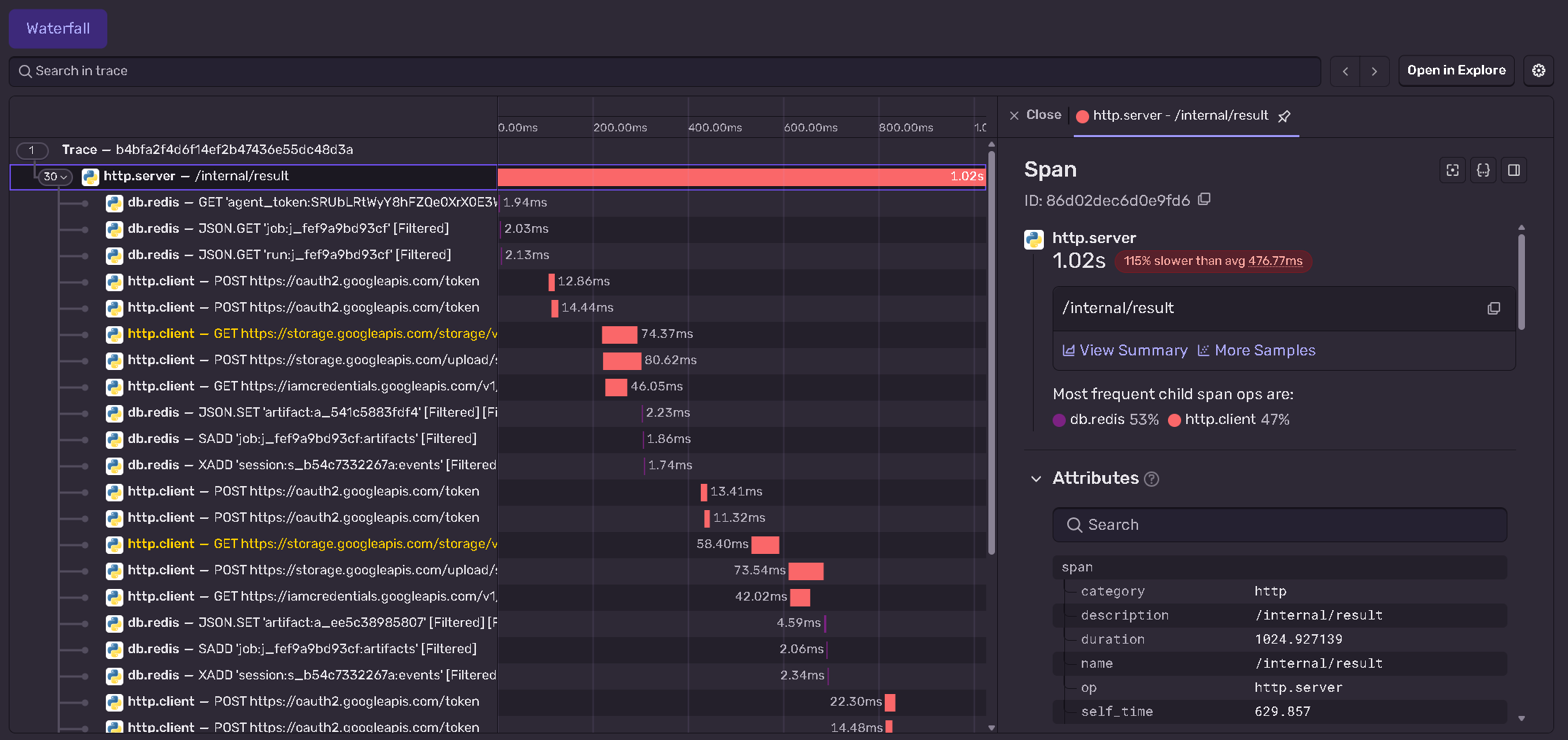
Every researcher works against a fixed budget and a bounded depth, so the system cannot quietly spawn ten thousand jobs or burn an unbounded bill. Results are not just text either. Researchers produce real training curves, metrics, and experiment dashboards that flow back to the PI as artifacts, so a claim arrives with the evidence attached.
Right now we focus on reinforcement learning and machine learning problems, where we can actually train, simulate, and learn from the results inside the system.
How we built it
We built both the PI agent and the researcher agents on a Claude Code agent harness, using skills, subagents, tools, and hooks. The PI agent first researches and reads, then proposes research directions and hands them to the researcher agents as concrete assignments.
The piece we are proudest of is not any single agent, it is the seam underneath them. Early on we locked a hard contract between the infrastructure and the agent logic: the schemas for a research plan, the dispatch path that spawns work, and the shared store. Once that seam was frozen, the agent side and the infra side could move independently without breaking each other. This is the only reason a mid-build architecture change did not sink us.
For compute, we use cloud sandboxes from Modal, which are virtual machines with root access. This gives each agent room to create files, delete files, and read the context we embed, while keeping it contained away from sensitive data and destructive actions. It also gives us real compute, so a sandbox can run a full training loop, a simulation, or an evaluation as part of the job rather than faking it. Modal is where all of our researcher agents live.
For the control plane we use Google Cloud and Redis. Cloud Run hosts our API and the runner loops that drive the main agent, and the main agent itself runs as a job. Redis does a surprising amount of the heavy lifting here. It is our state store, our job queue, our event bus, our budget ledger, and the transcript stream all at once. The frontend subscribes to that event bus over server sent events, so you watch the job tree and the agent feed update live, and you can disconnect and resume a session exactly where you left off. Artifacts that researchers produce, like plots and metrics, get pushed to Google Cloud Storage and handed back to the PI. We persisted all of our cross session agent memory using Redis Agent Memory. As a mobile platform we use Poke to send text messages directly to the main agent for research on the go.
Researchers run real experiments inside their sandboxes and log everything to Weights and Biases, and we use Browserbase to capture the live dashboard back into the run, so the PI gets the same visual evidence a human would look at instead of a paragraph of self-reported success. The dispatch path itself is guarded. Before any sandbox spins up, a plan is validated against budget, depth, and safety bounds, so an autonomous system cannot wander off, spawn unbounded work, or blow the whole budget on a single bad idea.
We wired observability through Sentry and OpenTelemetry across both the control plane and the sandboxes, so a failing researcher leaves a trace instead of disappearing into a black box.
The autonomous loop runs on this exact same infrastructure. It is the chat-agent system with a policy on top that decides, each round, whether to keep going or to stop and report.
Challenges we ran into
The biggest one was observability, and specifically the black box around the sandboxes. Sentry gave us great traces, but we learned quickly that tool calls and reasoning steps are not enough on their own. For research we needed to reason about why an agent took a step and why it failed at a task, not just what it called.
Researchers also failed in ways that looked random at first, and our early theories for why were naive. Over time we found the real causes and fixed them one by one. We attacked these with adversarial reviewers that try to refute a finding before we trust it, with deeper tracing into each step, and by hardening the dispatch and ops path so that a bad credential or a stale deploy could not silently take down a run.
Then there was distributed reality, which is where a lot of agent demos quietly die. There is no shared filesystem between the control plane and the sandboxes. There are cold starts. There are concurrency races when several researchers run at once. We even had to keep secrets in sync across two separate stores, one for the control plane and one for the sandboxes, and a single mismatch would take the whole run down. Keeping one source of truth across all of these moving parts was a constant fight.
Accomplishments that we're proud of
- We shipped a fully working end-to-end product in 24 hours. A real conversation turns into a plan, the plan fans out into researcher agents running in separate sandboxes, those agents run actual training runs, and real metrics and dashboards come back to the PI for synthesis.
- We got recursive sub-agents orchestrated in sandboxes working reliably, with budgets and depth limits so the system is autonomous without being reckless.
- We survived a significant architecture change mid-build because we had locked the seam first, which felt like the thing was actually paying off in real time.
- A lot of us went deep on documentation for GCP, Modal, Sentry, Redis, and the Anthropic stack, learned a ton, and came out genuinely excited to show this off after the hackathon.
What we learned
Research is search, and the substrate matters more than the prompt. The hard and valuable part is not the agent's wording. It is the recursive, sandboxed, budget governed machine that lets a swarm of agents run validly in parallel.
- Build the seam before the intelligence. Locking the contract between infra and agent logic is the only reason a mid-build architecture change did not kill us.
- Keep a human at depth zero and a verifier in the loop. Autonomy is a slider, not a switch. You earn each notch by making the layer beneath it trustworthy.
- Budgets are a first-class feature, not an afterthought. An autonomous system without a hard ceiling is just a fast way to spend money and compute.
- Demos lie, nines don't. Distributed reality, with no shared filesystem, cold starts, and concurrency races, is where autonomous-agent dreams actually live or die.
What's next for AlphaResearch
- Launch an open source version of the product first, and offer a hosted version to enterprises later.
- Move to Daytona sandboxes with higher performance GPUs so we can run much heavier simulations and more demanding training, well beyond the small RL problems we run today.
- Spin up thousands of sandboxes with Kubernetes and SkyPilot so a single user can run many more hypotheses and experiments at once, all still directed from one conversation.
- Broaden past reinforcement learning into other research domains, and give the system memory across runs so it starts to learn what works and stops repeating dead ends.





Log in or sign up for Devpost to join the conversation.