-
-
Poster
Title
AlphaChef - Build a transformer-based model to generate recipes from food videos.
Who
ChenHao Lu (clu63)
Nan Chen (nchen40)
PingYao Shen (pshen6)
Ziao Zhang (ziao306)
Introduction
With the unprecedented disaster, COVID-19, more families prefer to choose eat-at-home. And the trend of eat-at-home boosted by the COVID-19 crisis won’t recede anytime soon post-pandemic. According to the research from CPG sales and marketing firm Acosta, it states that eating at home became the norm during COVID-19. The result shows that 31% of families have eaten dinner at home every day since COVID, compared to only 18% pre-pandemic. Moreover, Acosta’s research reveals that 92% of families plan to continue eating together at home at least as often as they do now, if not more often, after the pandemic ends [1]. Our team realized the importance of learning to cook during the pandemic and post-pandemic period because of the significant increase of eat-at-home . We sincerely hope that our project can provide more convenience to all the households in learning to cook.
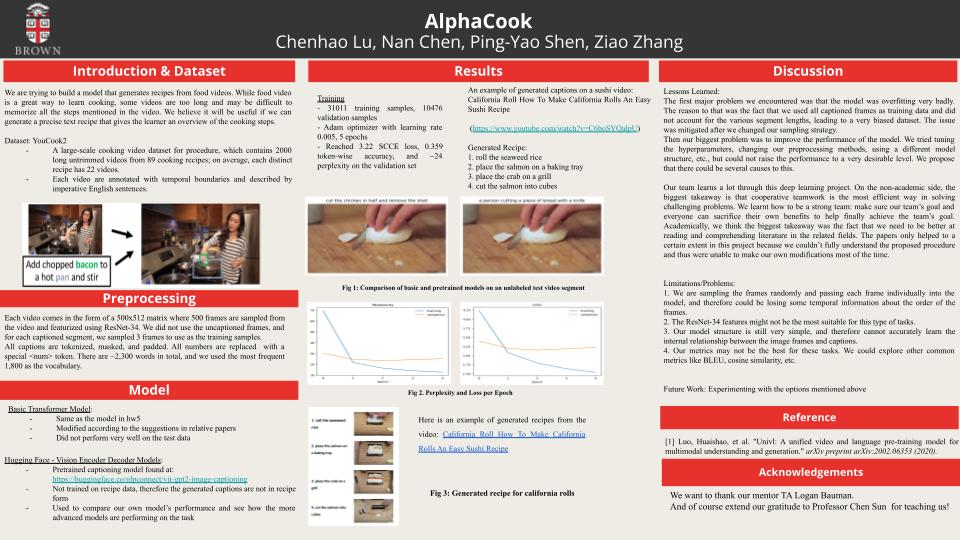
Here is our project: we are trying to build a model that generates text recipes from food videos. While food videos are a great way to learn cooking, some videos are too long and may be difficult to memorize all the steps mentioned in the video. Therefore, we believe it will be useful if we can generate a precise text recipe that gives the learner an overview of the cooking steps.
At the beginning, we took inspiration from Luo et. al.’s (2020) paper UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation [2]. Combining lectures in transformers and attention from the Deep Learning course, we used our own implementation of the preprocessing function and the model, and looked for suggestions from the paper when we needed to improve the performance.
Related Work
We found an existing paper that are related to our goal: UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
The paper will only be our reference and starting point.
Data
We used the YouCook2 dataset from the University of Michigan. It is one of the largest task-oriented, instructional video dataset in the vision community, and contains 2000 long untrimmed videos from 89 cooking recipes; on average, each distinct recipe has 22 videos. The procedure steps for each video are annotated with temporal boundaries and described by imperative English sentences. The videos come either in raw form, or in the form of feature matrices where the frames are already sampled and featurized using ResNet. Sampling is applied 10 times on each video with different timestamps for augmentation purposes, but we did not include the augmented data in our training set.
Methodology
We will be using the already preprocessed video data from the YC2 dataset, and build our own preprocessing method for the text data. They will then be encoded separately with two encoders. These encodings will go through a transformer to generate the output text descriptions.
Preprocessing
Each video comes in the form of a 500x512 matrix where 500 frames are sampled from the video and featurized using ResNet-34. By using the annotation file, we filtered out all the uncaptioned frames as they are not part of any recipes. For the captioned segments, we sampled 3 frames from each segment to minimize the potential bias and imbalance caused by the various lengths of the segments. All captions are tokenized, masked, and padded. We used a window size of 20 to make all captions the same length. All numbers are replaced with a special token. There are approximately 2,300 words in total, and we used the most frequent 1,800 words to build the vocabulary.
The final dimensions of the train and validation captions are (31011, 21) and (10476, 21) respectively.
Metrics
We will use common NLP metrics like perplexity, BLEU, etc., to evaluate the performance of our model.
Ethics
- We decide to use Youcook2 as our dataset. We notice that most of the videos are about western dishes. Given that all the videos and recipes in our dataset are in English, this uneven distribution is understandable. Nevertheless, this might affect the model’s performance when we try to generate recipes for certain types of dishes.
- The stakeholders of this project might be those who are trying to learn to cook a new recipe. Unclear instructions in our generated text recipe may lead to waste of food ingredients, or more severely, kitchen accidents.
Division of labor
- ChenHao Lu: encoder and decoder.
- Nan Chen: preprocess text and video data.
- PingYao Shen: preprocess text and video data.
- Ziao Zhang: encoder and decoder
Check In #1
Check In #2
Final Reflection
Poster
References
- [1] Russell Redman, “Study: Most U.S. consumers stick with eating at home post-pandemic.”https://www.supermarketnews.com/consumer-trends/study-most-us-consumers-stick-eating-home-post-pandemic
- [2] Luo, Huaishao, et al. "Univl: A unified video and language pre-training model for multimodal understanding and generation." arXiv preprint arXiv:2002.06353 (2020).



Log in or sign up for Devpost to join the conversation.