-
-
GAN
-

GAN1
-
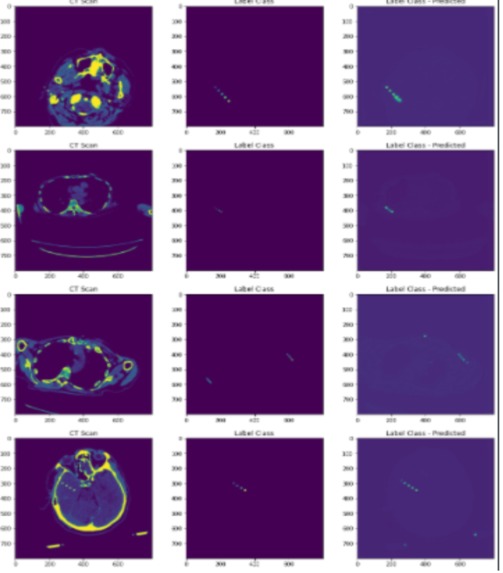
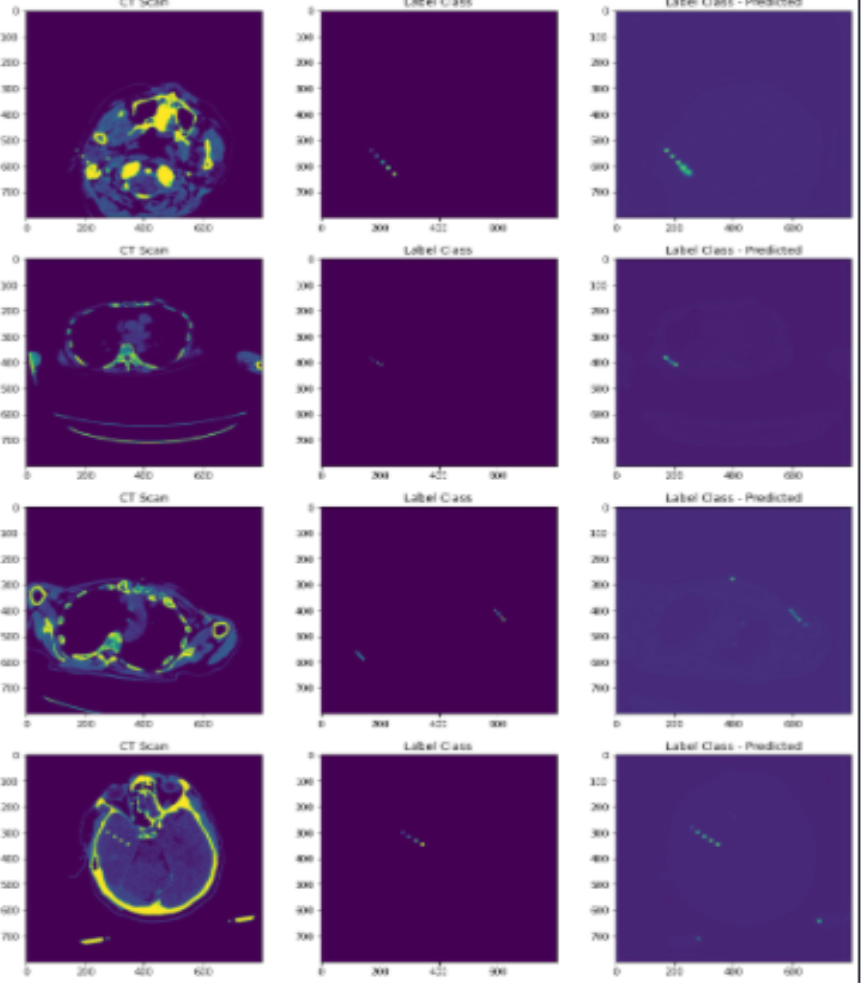
Sementation Results

Objective
We aim to detect the coordinates of seeds in the CT scan images for Alpha radiation treatment for solid tumors. We are also synthesizing the artificial CT scan images with or without seeds from the AlphaTau dataset.
Introduction
We have used the AlphaTau dataset, which is a synthetically made dataset of CT images. The accuracy of detecting coordinates of seeds must be very high. Else it can even cost a life. First, we segment the dataset using the UNet + ResNet 34 encoder, then extract the blob structure coordinates. We are also synthesizing the dataset using w-GAN, which significantly helps the medical sector as there is very little data available for usage. The dataset is huge, so we have sampled the data then made the predictions. It requires huge computation power.
Methods
We have changed the axis of our interest. Let’s say our image is of shape 1250*1250*41, i.e., 1250 images of 1250*41 dimensions. We have rotated the axis by 90 degrees. Then our new CT scan shape will be 41*1250*1250, i.e., 41 images of 1250*1250 dimensions.
- UNet based Architecture:
Encoder: Resnet 34 We used the UNet Based Segmentation model, a SOTA model in BioMedical Image segmentation. We used an augmented training set consisting of rotations, shifts, and flips of images. We used a combo loss of Dice Loss and Binary cross-entropy with Adam Optimizer, a popular optimizer in deep learning to help the model converge to the minima faster. We resized the images to a size of 800 and stacked the predictions to find the coordinates.
The coordinates were found by first finding blob contours in the predicted masks. Then we found the centers of the blobs to find the final seed locations.
- GANS:
We have used GANS for data augmentation. GANS are powerful models which can augment data effectively. As we have a limited number of CT scans, we can use GANS for data augmentation. We first converted the NumPy file format of images to png format for data. We also resized every image to (512, 512) and used flips and random zoom while converting. Then we have trained this data on DCGAN with wasserstein loss for around 1000 iterations. This loss function depends on a modification of the GAN scheme (called "Wasserstein GAN" or "WGAN") in which the discriminator does not actually classify instances. For each instance, it outputs a number. Discriminator training just tries to make the output bigger for real instances than for fake instances. The benefit of the DCGAN with WLoss is that the training process is more stable and less sensitive to model architecture and the choice of hyperparameter configurations. Perhaps most importantly, the loss of the discriminator appears to relate to the quality of images created by the generator.
Conclusion
We are able to build a prototype that can be used successfully for predicting seeds and generating data using GANS. and We can also upscale the quality of images generated can be increased if we have huge computation power, which we lacked.











Log in or sign up for Devpost to join the conversation.