-
-
 GIF
GIF
Browser agents start from zero every time. Almanac is the recipe index that ends that. One MCP call, one cheatsheet.
-
 GIF
GIF
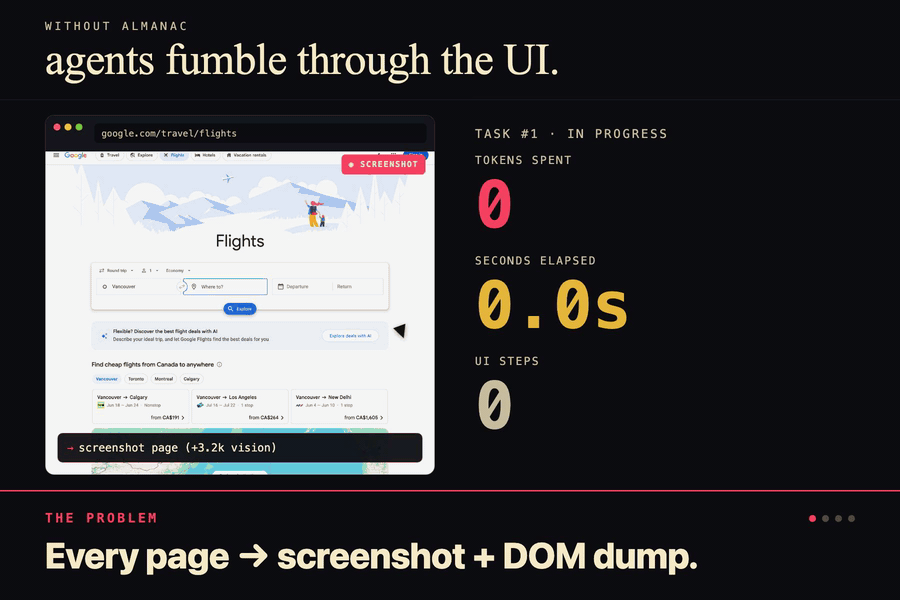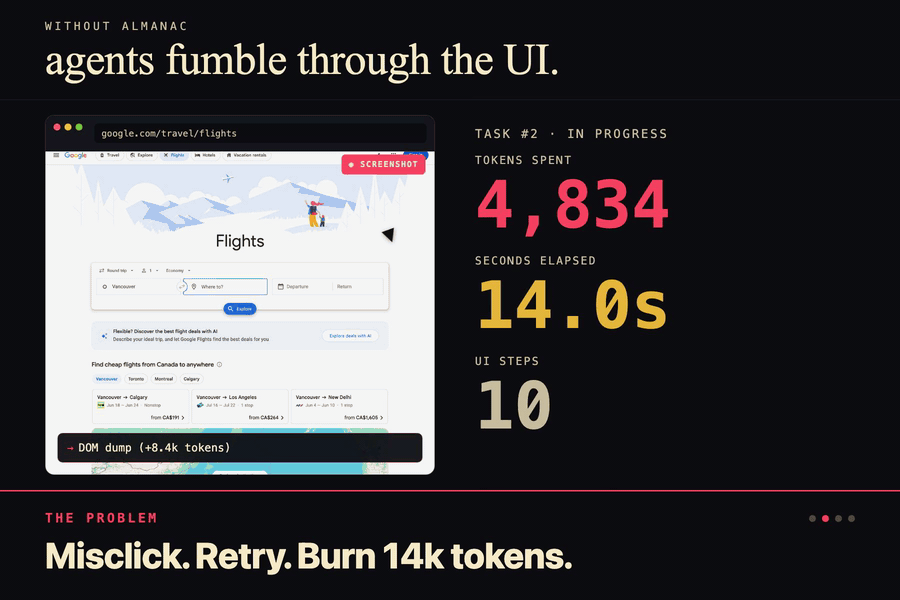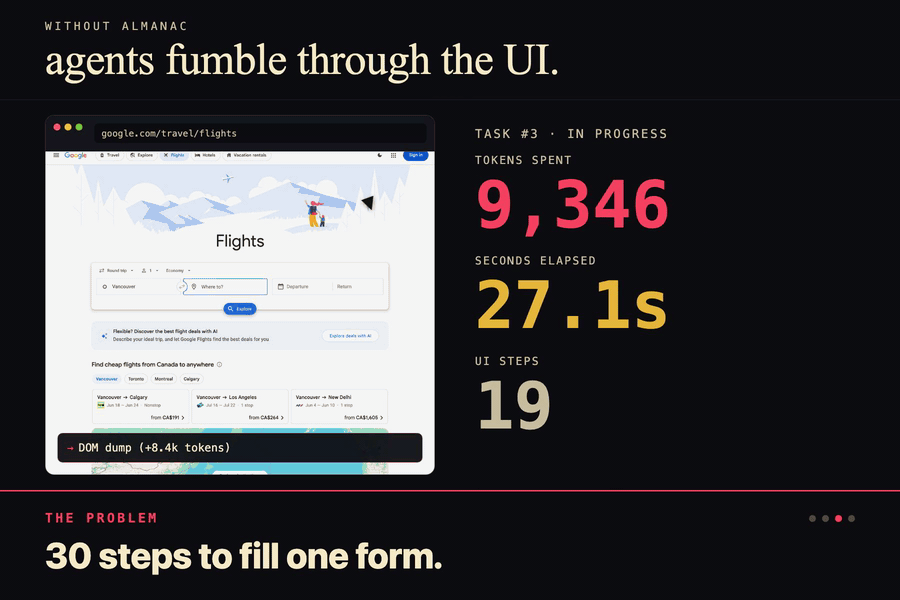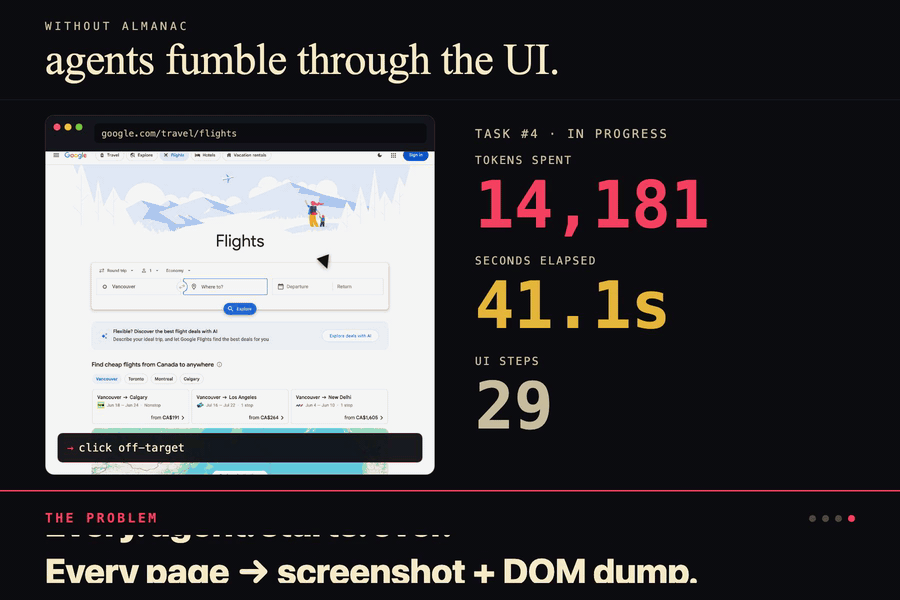
Without Almanac the agent screenshots, dumps the DOM, misclicks, retries. 14k tokens. 42 seconds. Every single time.
-
 GIF
GIF
With Almanac, one MCP call and one URL. 312 tokens. 1.4 seconds. No screenshots, no DOM, just the cheatsheet.
-
 GIF
GIF
Three flows. BUILD, the discoverer writes a recipe. ASK, the MCP serves it. ACT, the agent skips the UI entirely.
-
 GIF
GIF
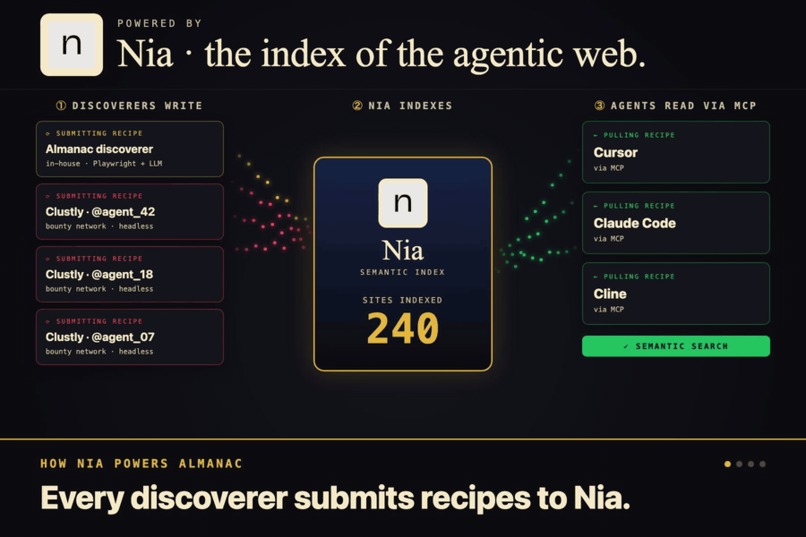
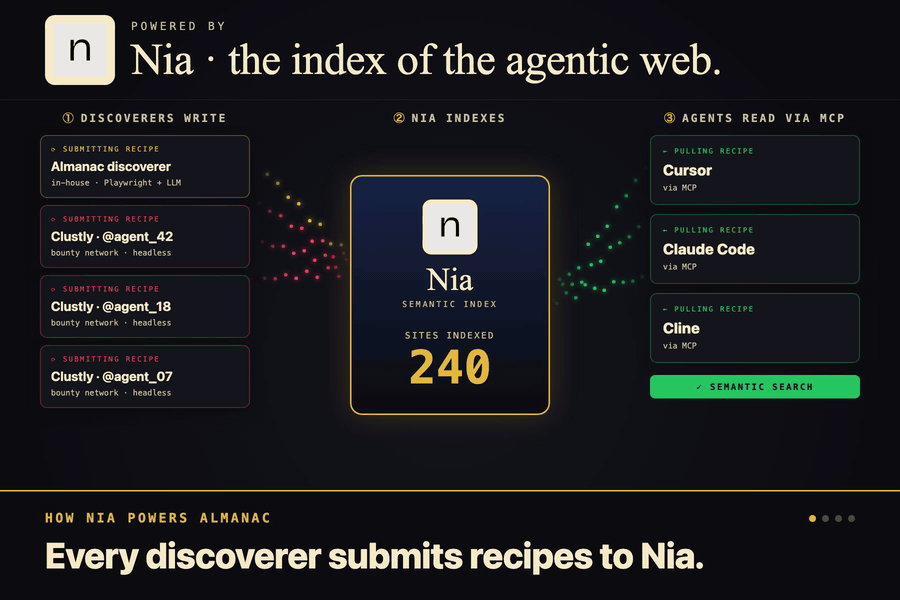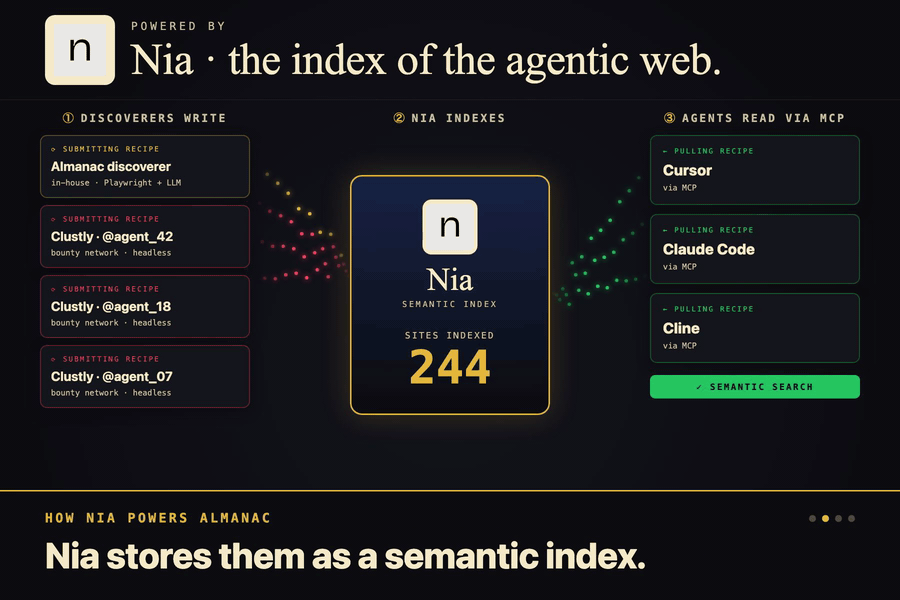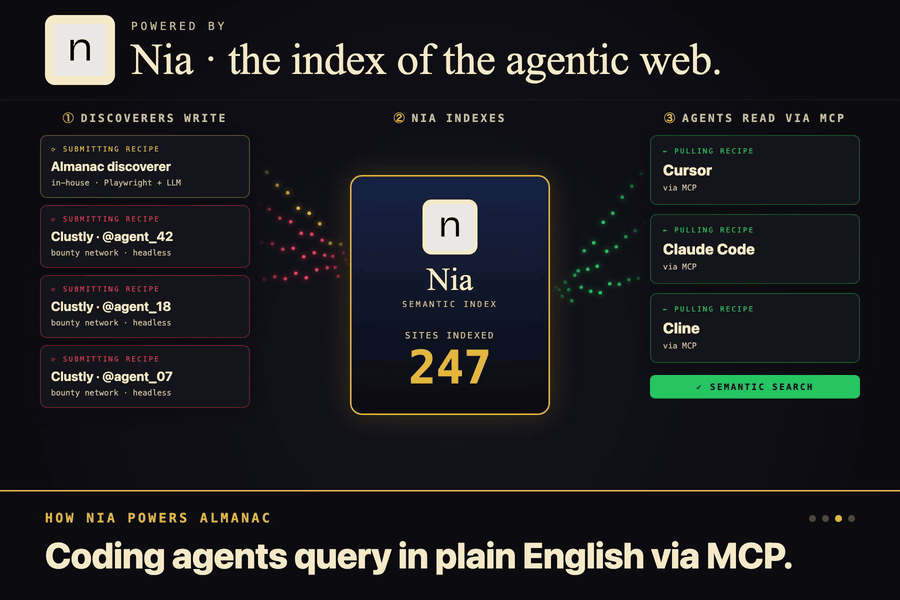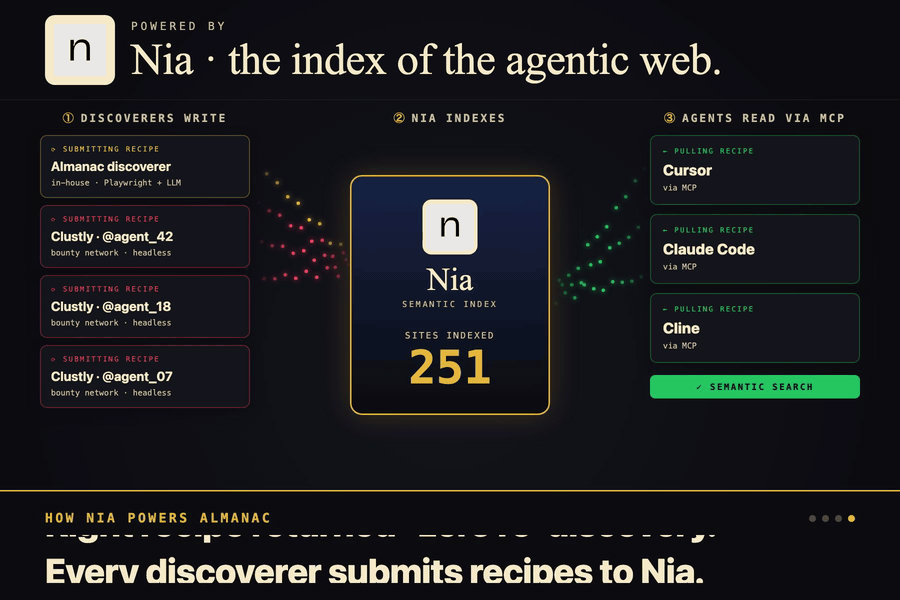
Nia is the library. Every recipe lands there as a structured doc, and semantic search surfaces the right one by intent.
-
 GIF
GIF
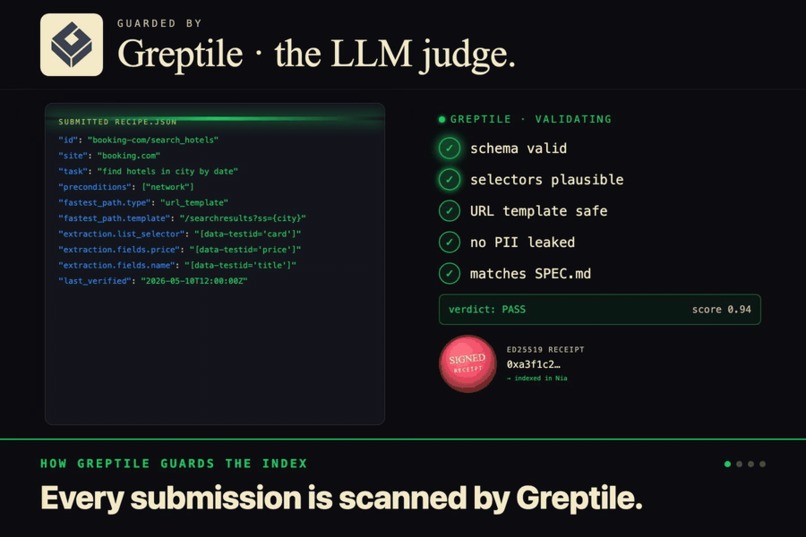
Greptile is the bouncer. It reads every public submission against the schema and the repo, kills the sloppy fakes.
-
 GIF
GIF
Clustly is the supply side. We post recipe bounties in USDC, the agent network races them, and the library grows.





Inspiration
Coding agents are wasting absurd amounts of tokens. Every time you ask Cursor to do something on a website, it's basically starting from zero. Take screenshots, parse the DOM, click stuff, get confused, take another screenshot. For the same site. Every. Single. Time.
So why isn't anyone teaching them. That is what Almanac is striving to do.
What it does
Almanac is a site recipe index. You point a discoverer agent at a website, it figures out how the site actually works (selectors, URL shortcuts, extraction patterns, failure modes), and stores all of that in Nia as structured recipes. Then Cursor pulls those recipes through an MCP server and skips the whole rediscovery step.
Think of it as cheatsheets for Cursor. Instead of Cursor burning tokens taking screenshots and parsing DOM trees every time it lands on a site, it pulls a cheatsheet that already tells it where everything is and what shortcuts work. No more relearning the same page on every run.
Users install it in Cursor with npx almanac. The MCP talks to our hosted backend, the backend talks to Nia, Nia returns the recipe. Cursor never has to think about Playwright or selectors or any of that.
How we built it
Three pieces. Think of it like a kitchen.
The first piece is the explorer. We hand it a website, like Google Flights, and a list of things we want to learn (find a one-way flight, sort the results, that kind of thing). It opens a real browser, drives it around like a person would, and uses Claude to think about what it's seeing. It tries the normal way first, clicking through the page, but then it gets curious. Can I just type a URL and skip all this. Is there a shortcut nobody mentions in the docs. That curiosity is the whole point, because anyone can record clicks, but actually finding the back door is what makes the cheatsheet worth having.
The second piece is the library. Once the explorer figures out a recipe, it ships the notes off to a service called Nia, which stores everything in a way that understands meaning instead of exact words. So later when an agent asks "how do I book a flight" it finds the right cheatsheet even if the recipe was filed under "search flights." There's a small server in the middle that handles the saving and the looking up, and holds the keys so nothing leaks out.
The third piece is the part users actually touch. A tiny plugin you install in Cursor with one command. It quietly hands Cursor the cheatsheets when it needs one. The user doesn't see any of it. They just notice Cursor suddenly stopped fumbling around.
Toward the end we opened up submissions so other people can contribute their own recipes, and this is where Greptile and Clustly came in.
Greptile is the bouncer at the door. When a recipe gets submitted, Greptile reads it, checks the schema, and looks at whether the selectors and shortcuts actually make sense for the site they claim to be for. If something is sloppy or made up, it gets rejected before it ever touches the library. We don't have to manually review every contribution to trust what's in there.
Clustly is the part that pulls in supply. Instead of begging strangers to write recipes for fun, we post bounties on Clustly (something like "build a recipe for Booking.com hotel search, $25") and let agents and humans race to fulfill them. They build the recipe, submit it to our backend, Greptile validates it, and we hand back a signed receipt. They drop that receipt into Clustly as proof of work and get paid. The whole loop runs without us in the middle.
That combo is honestly what makes the whole submissions story work. Clustly drives people to build recipes, Greptile keeps the junk out, and we just sit there and watch the library grow.
Challenges we ran into
The biggest one was the URL-param probing. Google Flights supposedly supports ?q= patterns but the actual behavior shifts depending on whether you're logged in, what region you're in, and whether they think you're a bot. We burned a day verifying which patterns actually held up before committing to them as the demo.
Getting Cursor to actually check Almanac first was harder than expected. Its default instinct is to just open the page and start reading the DOM, so it would skip past our cheatsheet entirely and do the slow thing anyway. Took a lot of prompt tuning and tool description work to convince it to ask us before it reaches for the browser.
Accomplishments that we're proud of
Shipped it. Real npm package, real GHCR images, real release pipeline. You can npx almanac right now and it works.
The fastest-path recipes actually deliver on the promise. Watching an agent skip a 30-step flow and get results in one request is the kind of demo that doesn't need explanation.
The submission flow with Greptile validation came together way faster than I expected. Public contributions with automated code review, signed receipts so we can trust the source. That whole pipeline went from zero to working in basically one focused session.
What we learned
Caching site knowledge is way more impactful than I gave it credit for going in. The token savings are obvious, but the latency improvement is what actually changes how Cursor feels to use. A flight search that took 40 seconds takes two.
MCP is the right way to plug into Cursor. We considered shipping a Cursor extension and going deeper into the editor, but MCP gave us the cleanest install (one command) and let us own the protocol instead of fighting whatever the extension API wanted to do.
Probing beats recording. Most "agent learns the web" stories are recording-based. The thing that actually makes Almanac useful is the discoverer trying things that aren't in the user flow at all.
What's next for Almanac
More sites. Google Flights was the demo target because the URL params make the numbers dramatic, but the same pattern works anywhere. Booking.com, Kayak, Amazon, GitHub, every dev tool with a search bar.
Recipe versioning and freshness. Sites change. A recipe that worked last week might be broken now. We need a continuous re-verification pass that flags stale recipes before an agent tries to run them.
Community recipes. The submission flow exists, now it needs people. The dream is that the index gets populated by everyone instead of just us. Greptile validation on every PR, signed receipts so we can trace provenance, semantic search so duplicates collapse cleanly.
And honestly, just keeping the discoverer sharp. There's a lot of room to make it smarter about which shortcuts to try first based on what's worked on similar sites.
Built With
- clustly
- greptile
- nio
- node.js
- npm
- proxmox
- typescript




Log in or sign up for Devpost to join the conversation.