-
-

ALIVE BANNER
-
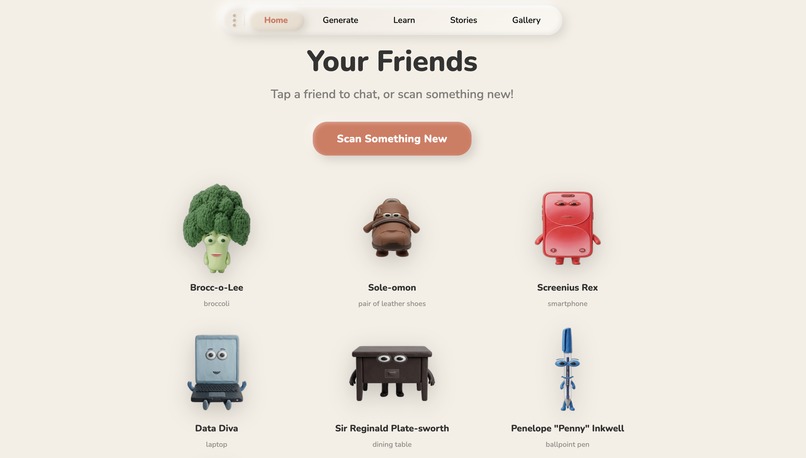
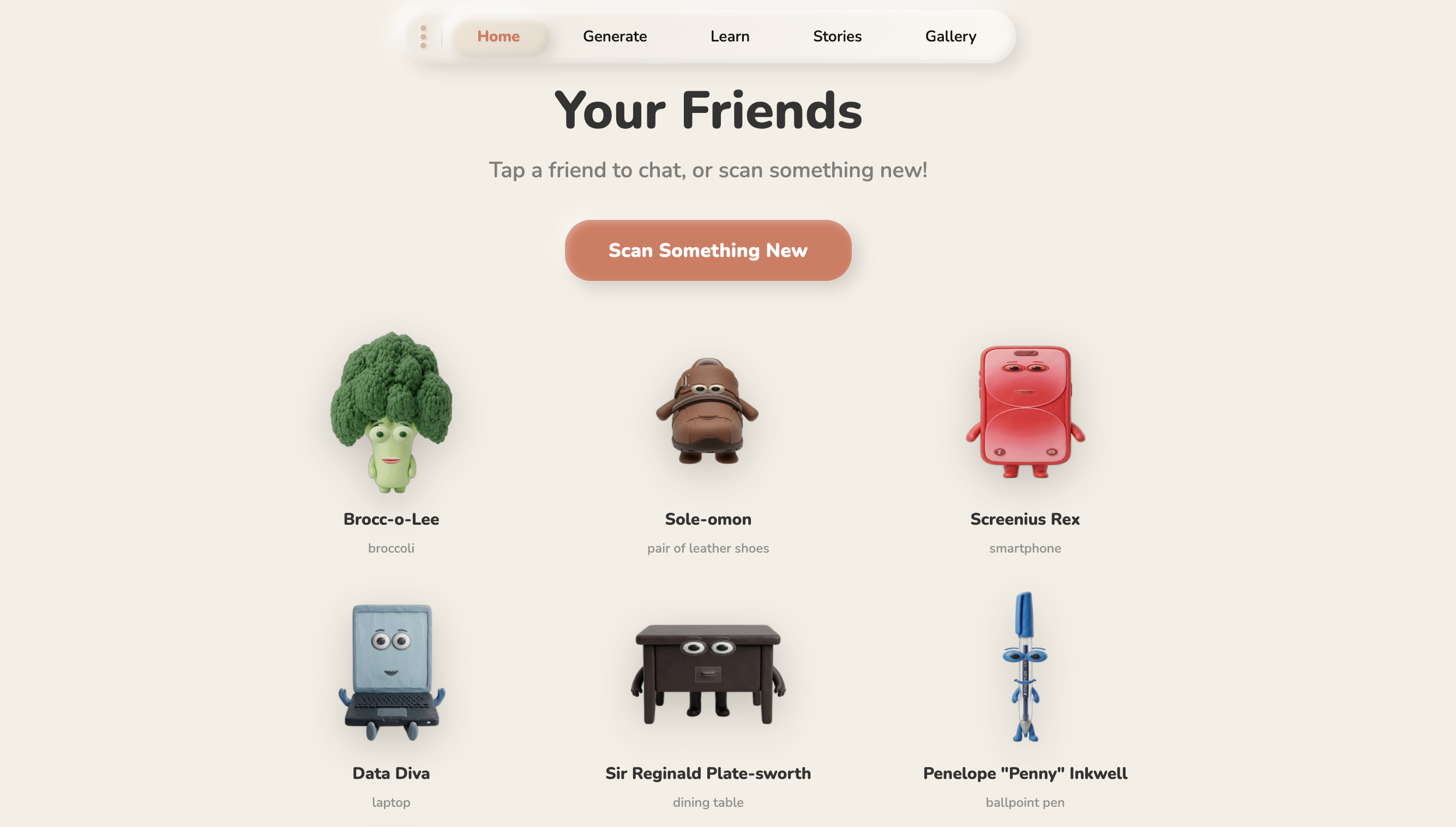
avatars page
-
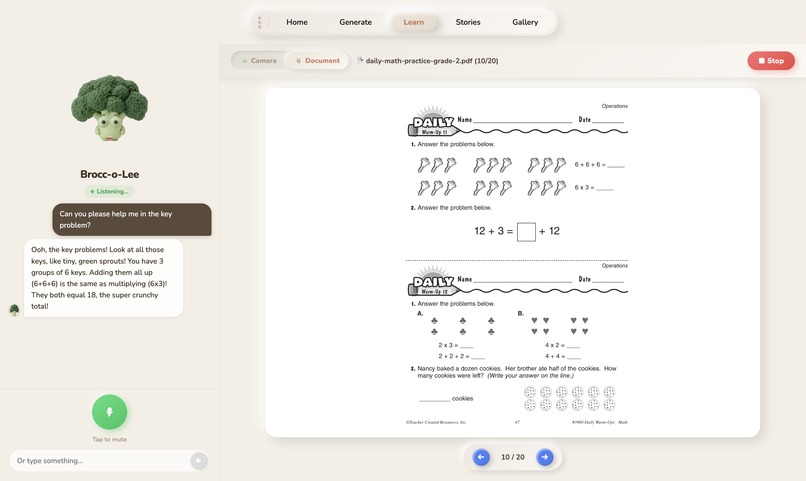
learn page
-
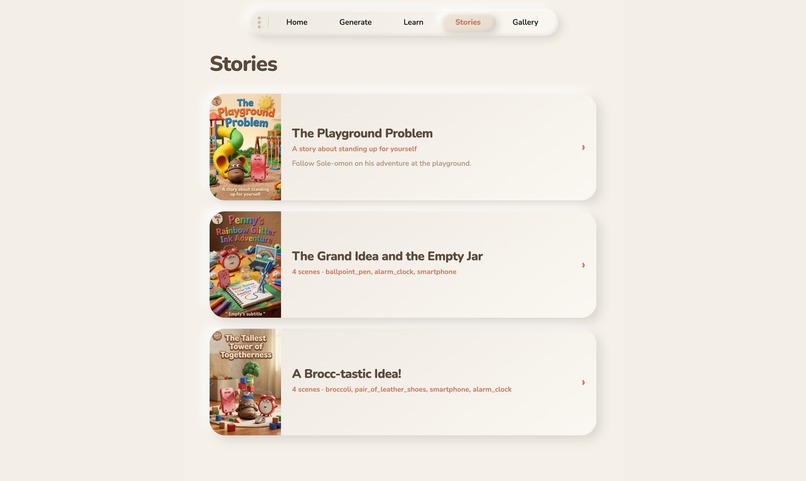
stories
-
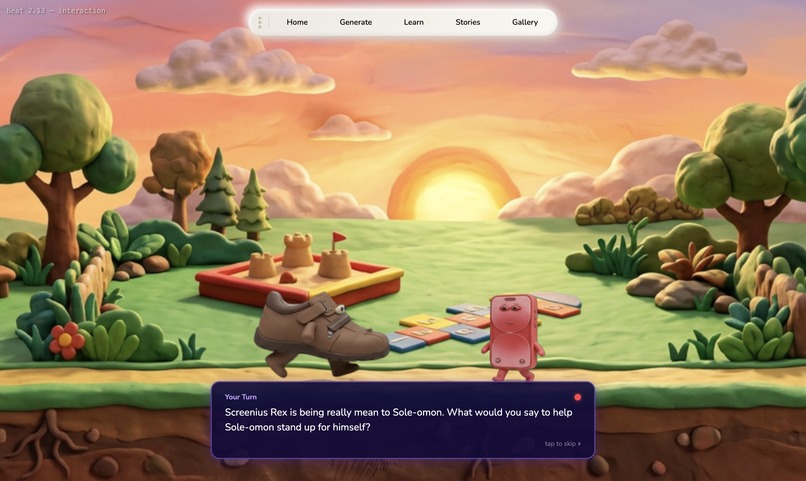
story scene
-
gallery
-
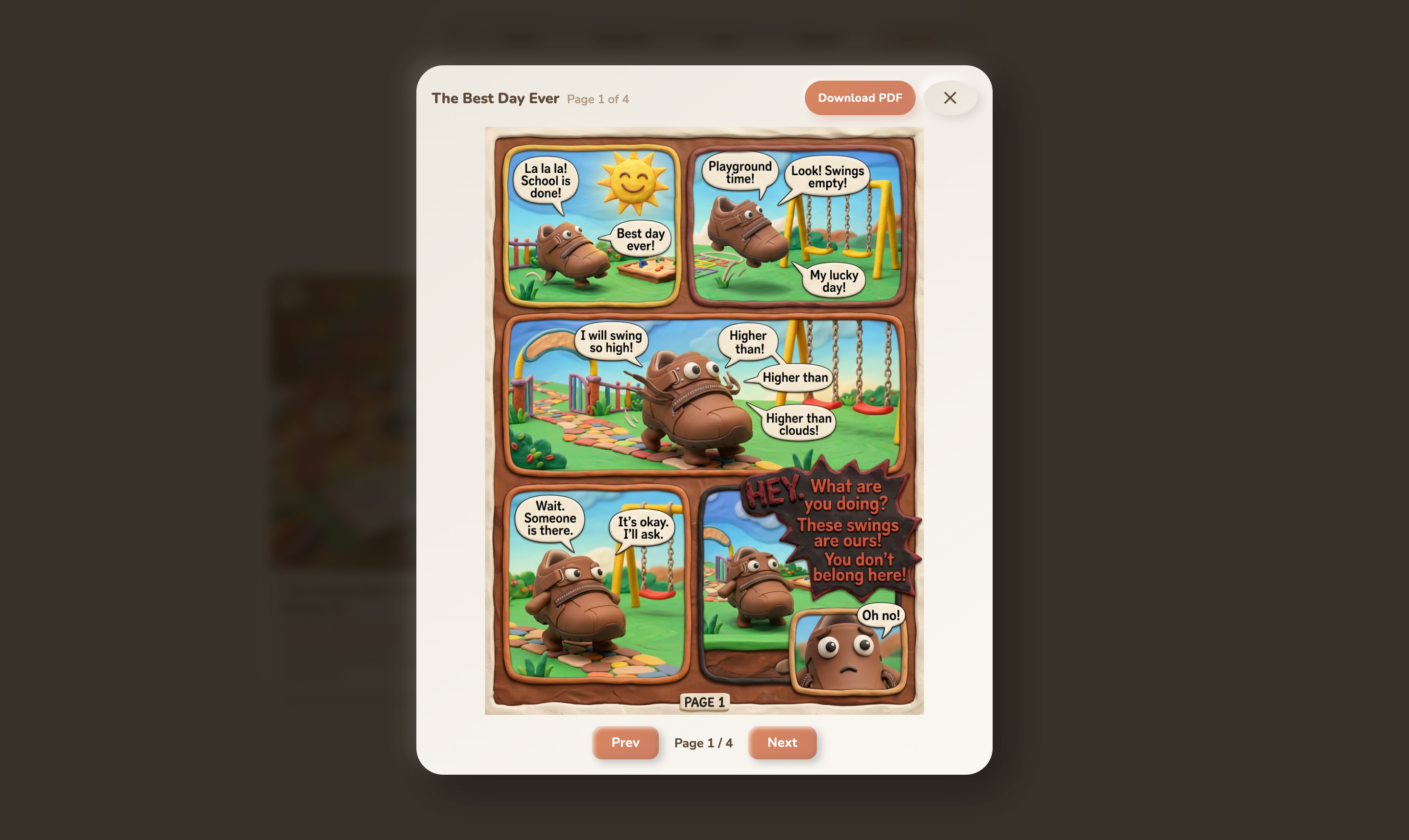
comicbook
-
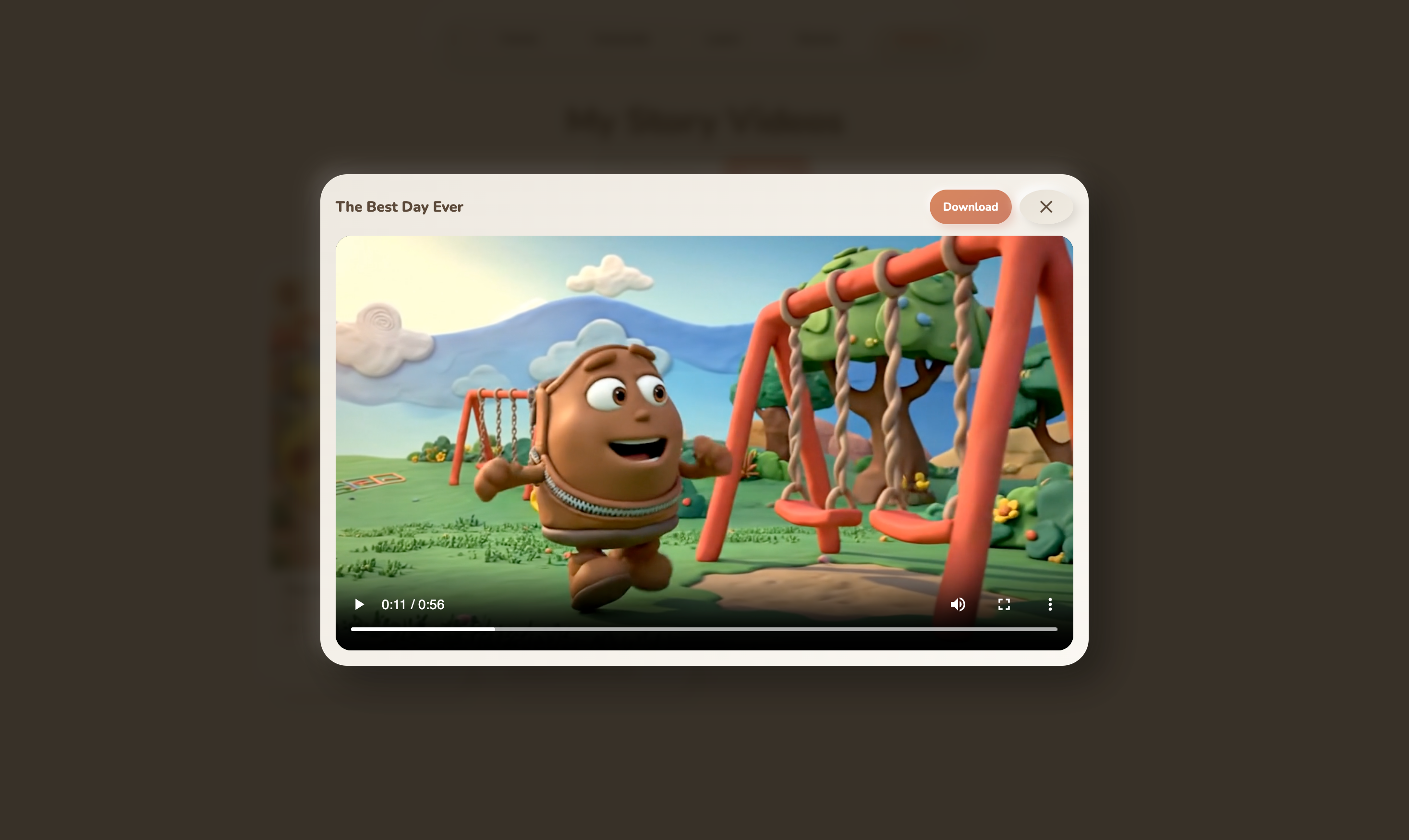
video
-
pin page
-
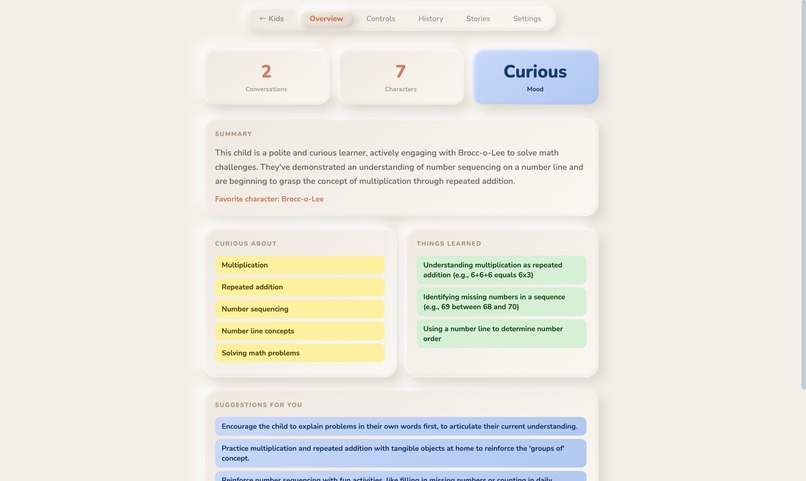
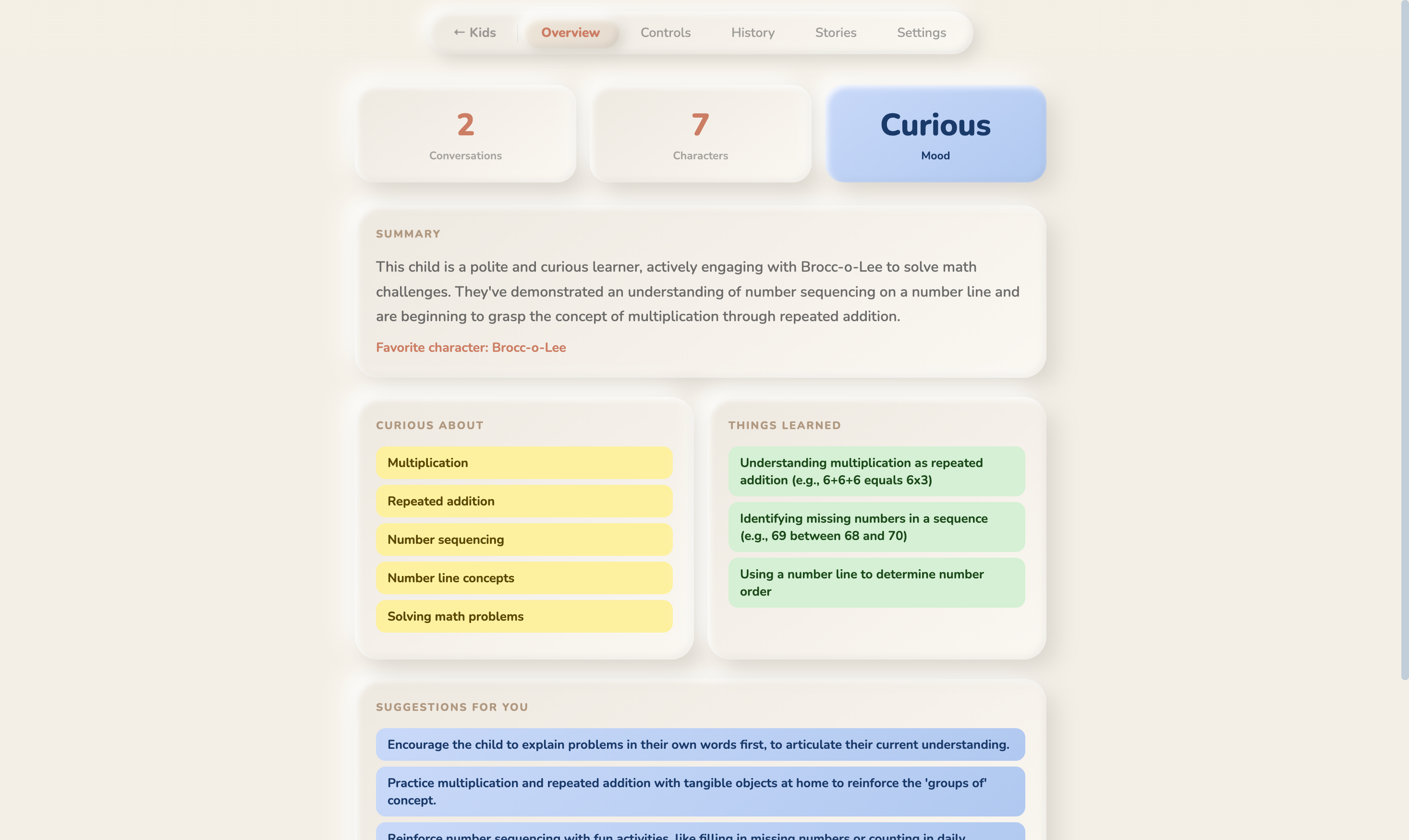
parent dashboard
-
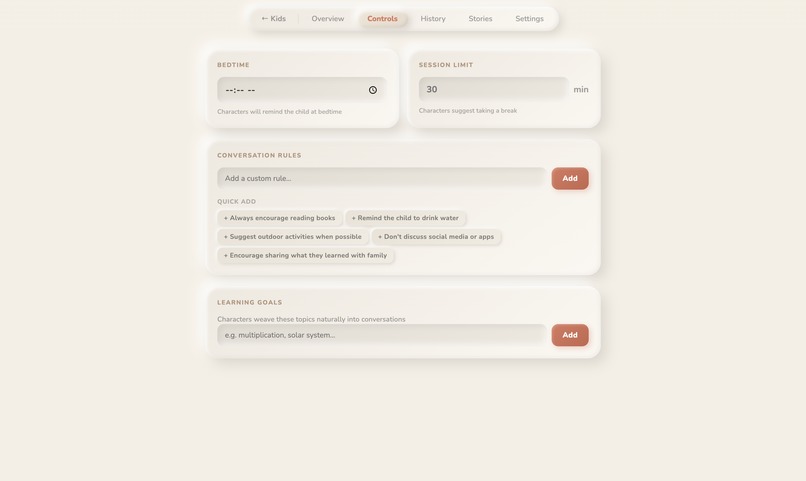
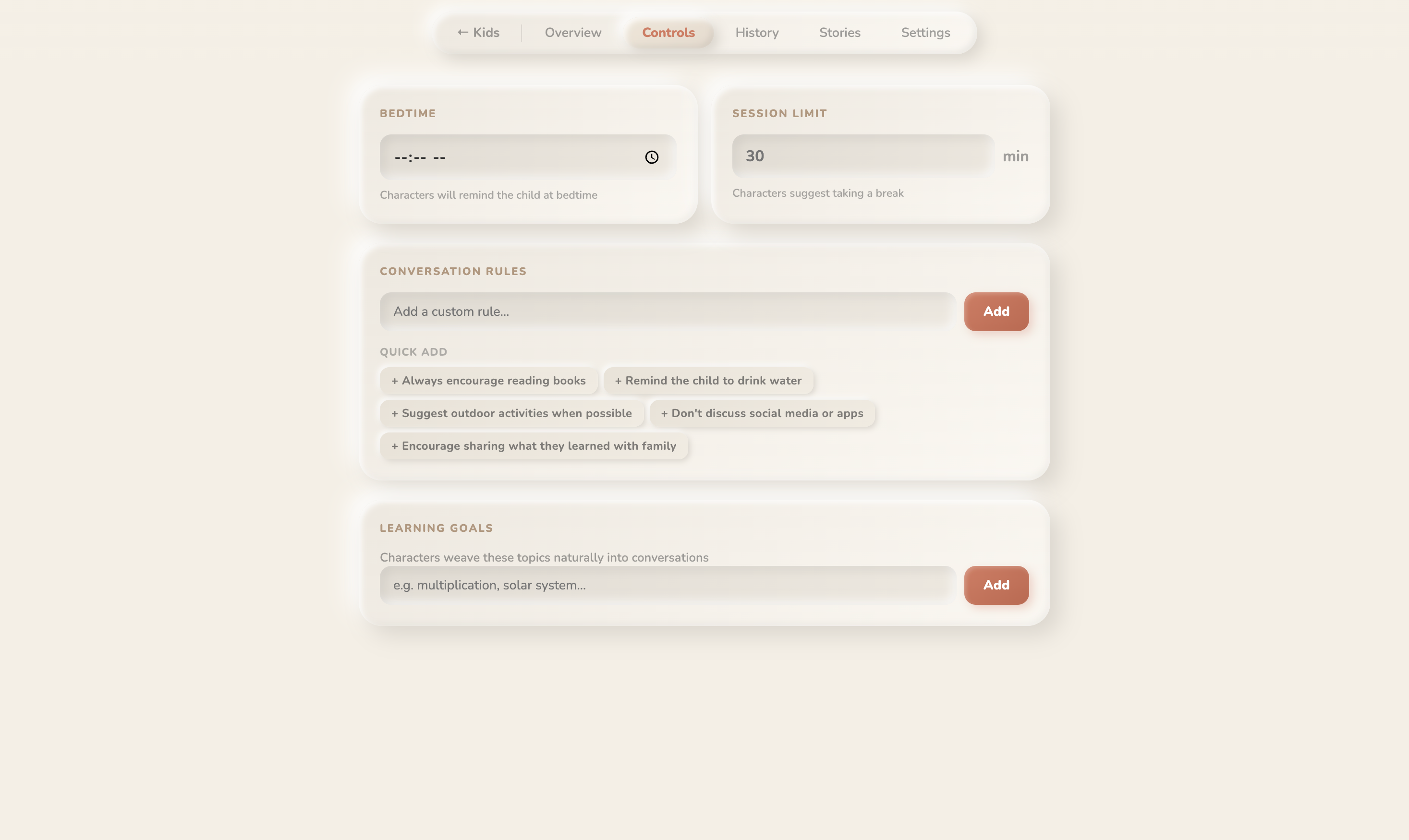
parent control
-
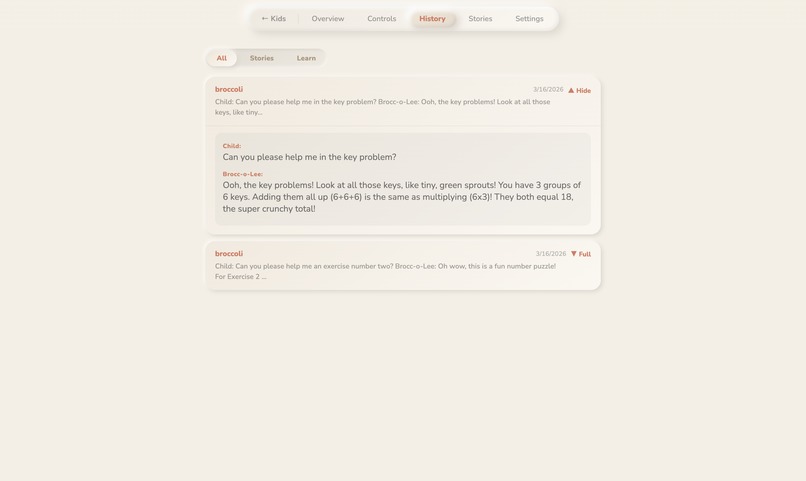
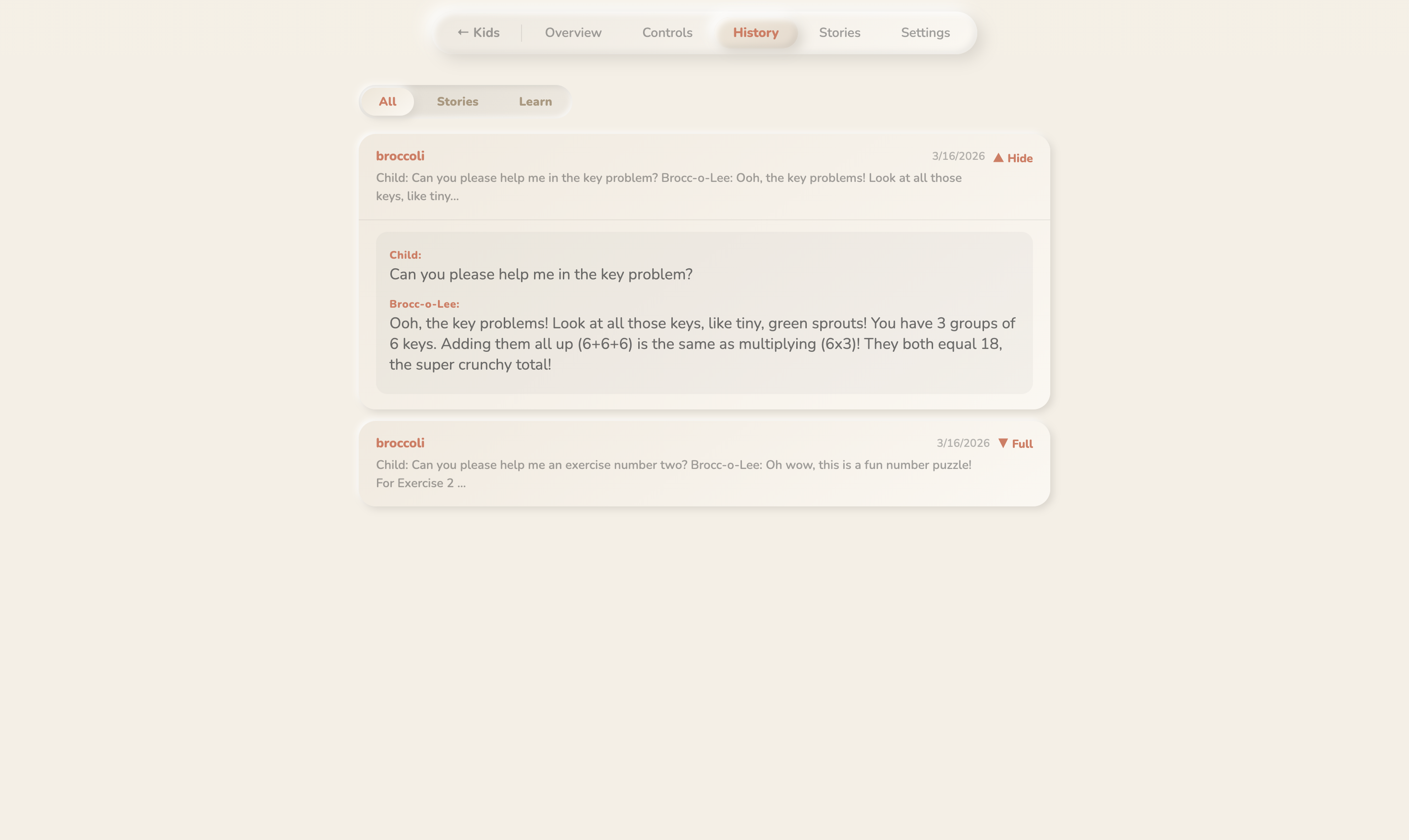
parent history

Inspiration
I've struggled with learning my entire life. Not because I wasn't curious , I was , but because the way things were taught never clicked. Textbooks felt lifeless. Lectures felt distant. I'd stare at objects around me and wish someone would just explain things the way I needed to hear them.
That never went away. And now, as someone who wants to have kids one day, I keep thinking: what if they go through the same thing? What if school doesn't work for them either?
So I built what I wished I had. Alive turns every object into a patient, funny, endlessly curious teacher. Point your phone at a shoe , it becomes Sole-omon, a wise-cracking leather shoe who knows everything about materials, friction, and why your feet smell. Point at a pen , meet Penny Inkwell, who'll teach your kid about ink chemistry while cracking puns.
No typing. No reading. Just pointing and talking.
What it does
A child points their camera at any object. Gemini Flash identifies it instantly, generates a unique personality (name, voice, catchphrase, mood), and Imagen 4.0 renders it as a 3D clay character.
From there, the child can learn in multiple ways:
- Go live , Open the camera and have a real-time voice conversation with the character via Gemini Live API. The character sees through the camera, so it can help with hands-on tasks , assembling a science project, identifying plants on a walk, or explaining how a machine works while looking at it.
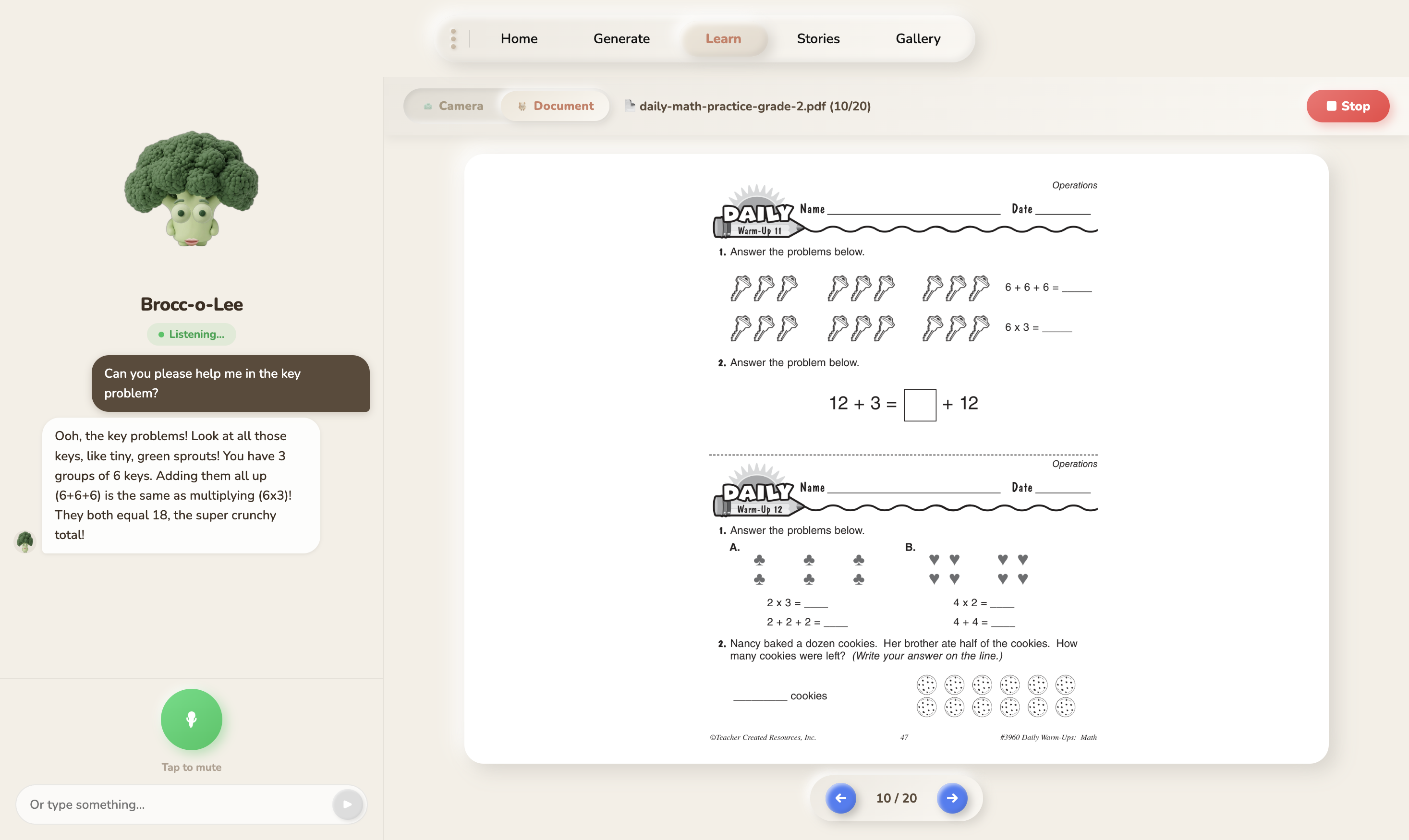
- Learn with a document , Drop in a PDF, a photo of homework, or a textbook page. The character reads it and walks the child through it, answering questions along the way.
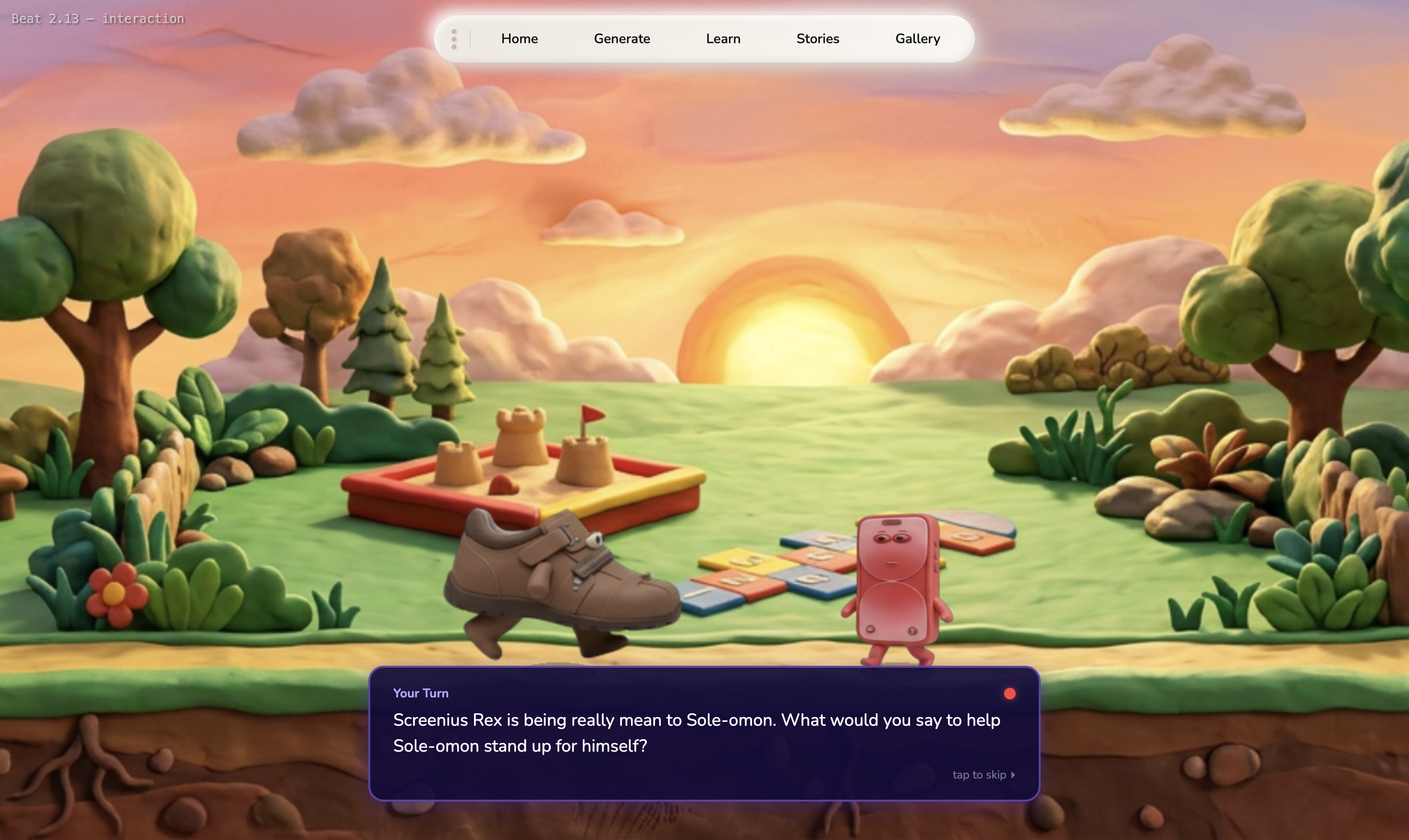
- Play a story , Parents set learning goals, and the system brainstorms interactive stories starring the child's own characters. A PixiJS scene engine plays them out with animations, dialogue, choice points, and TTS audio.
And it's not just school material. Characters teach values, help kids understand emotions, explain concepts like fairness or teamwork, or just have a silly conversation that builds confidence.
The characters remember past conversations using Gemini Embedding 2 Preview with ChromaDB vector memory, search the web when they don't know something, and never break character. Kids can interrupt, change topics, ask weird questions , the character handles it all fluidly.
Beyond conversations:
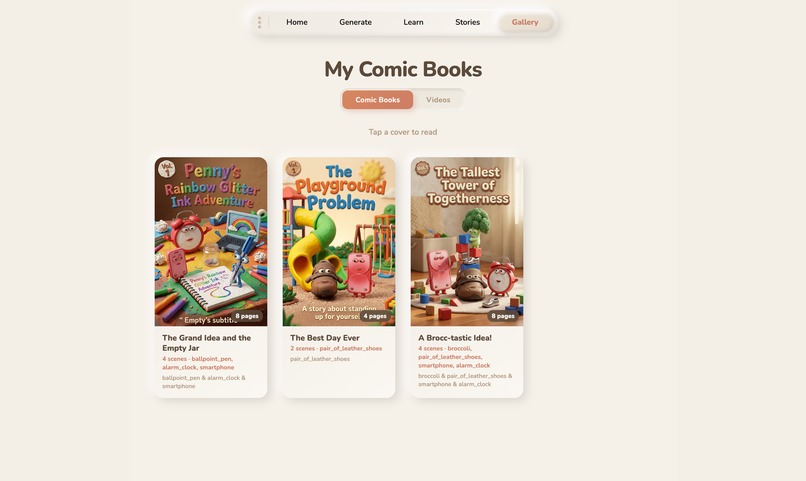
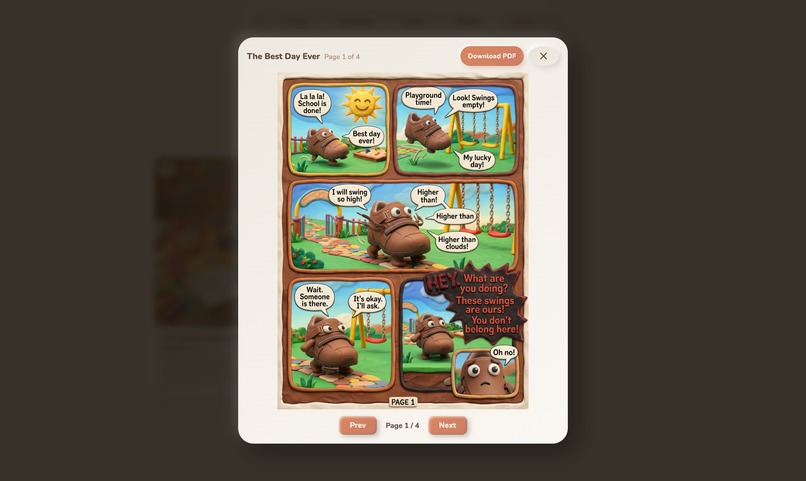
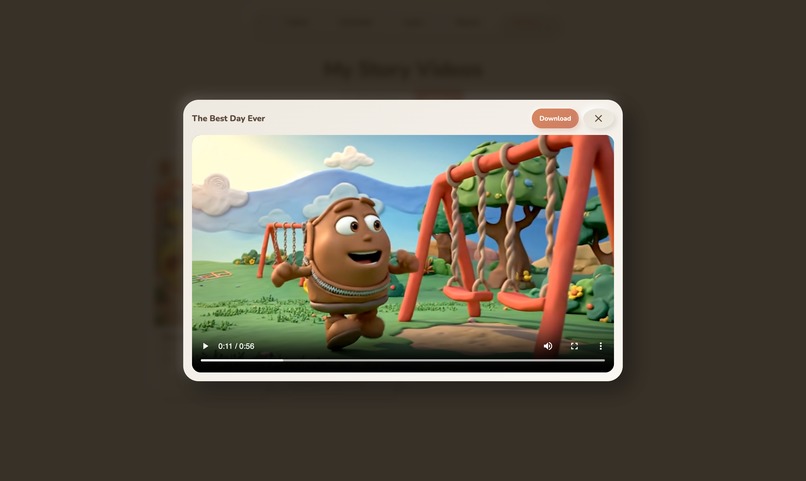
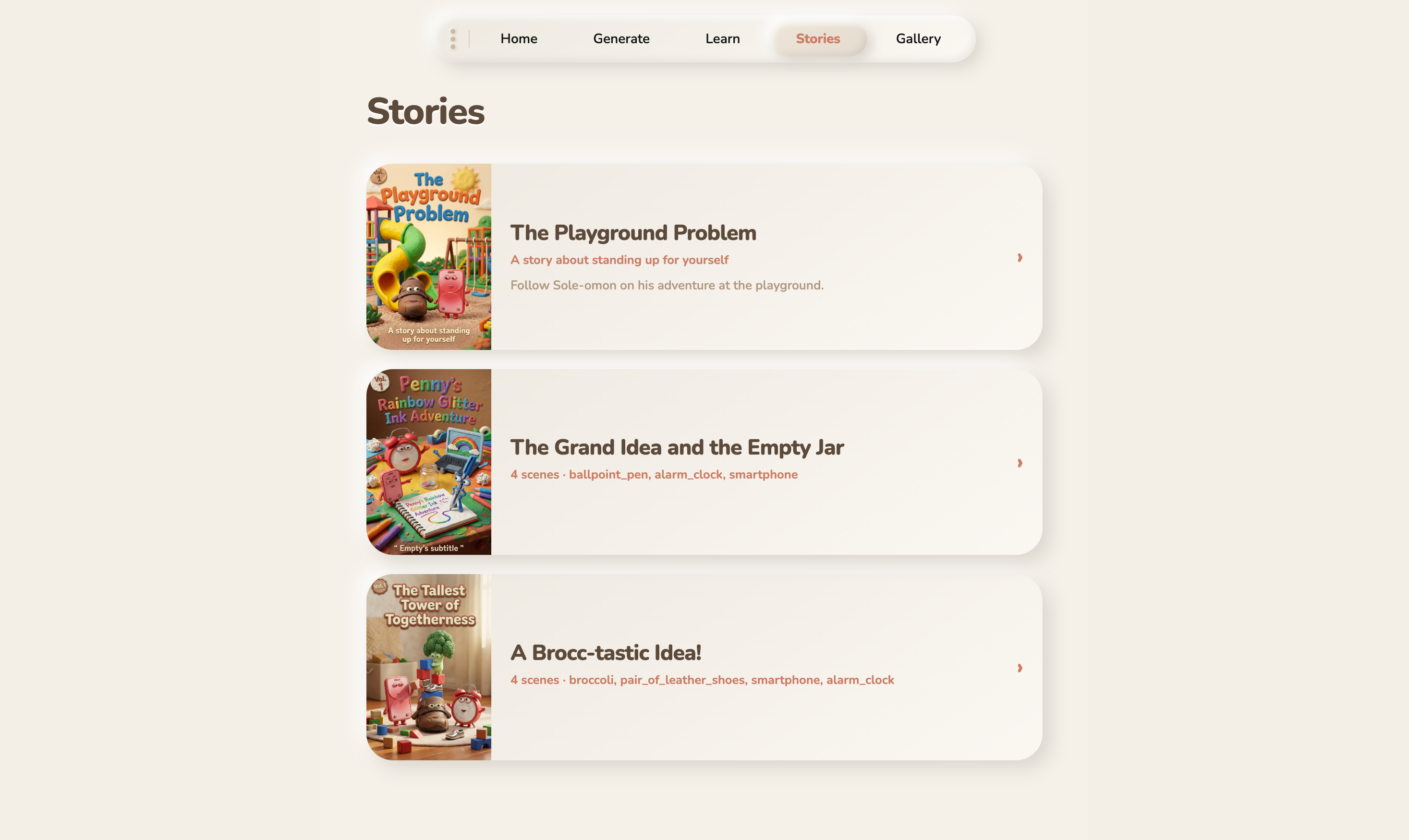
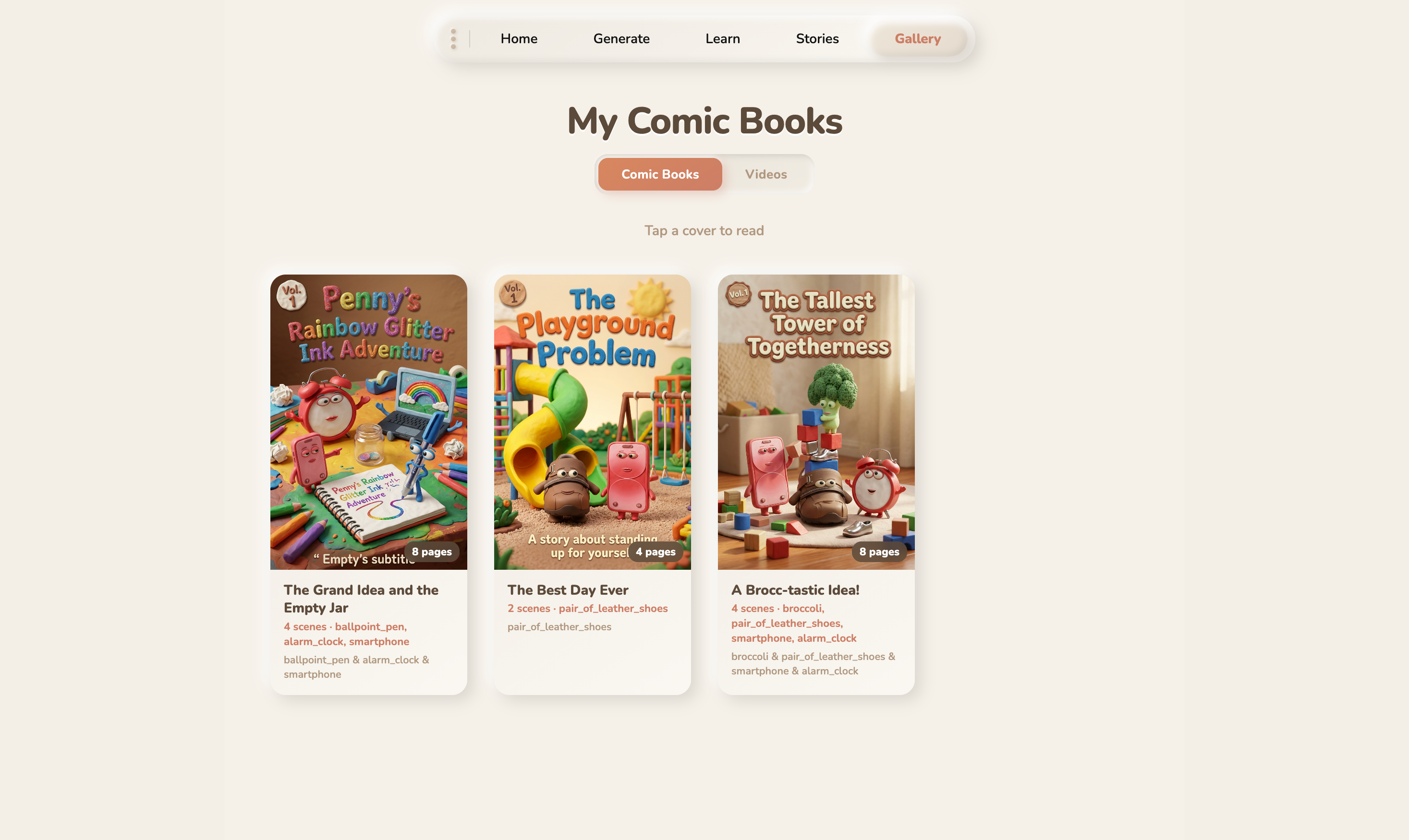
- Gallery , Every Story can become a comic book (via Gemini image models) or a claymation video (via Veo 3.1).
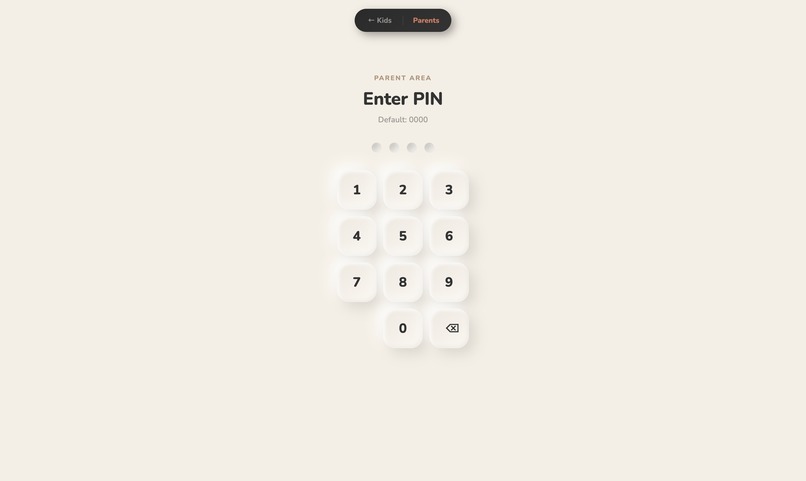
- Parent Dashboard , PIN-protected. AI-analyzed insights into what your child talked about, what they're curious about, what concerned them. Parents set what they want their children to learn , and what topics the AI should avoid. Learning goals, conversation rules, bedtime limits, session time caps.
How we built it
The backend is FastAPI with 7 WebSocket endpoints handling real-time audio streaming. The core is GeminiSession , a wrapper around Gemini Live API's native audio model that manages bidirectional audio, tool calling, vision frames, and transcription in a single connection.
The avatar pipeline was the most complex piece:
- Camera frame → Gemini Flash vision (identify object)
- Description → Imagen 4.0 (generate clay base character)
- rembg (remove background)
- Gemini Flash vision (detect face landmark positions)
- Gemini 3.1 Flash Image (generate eye variants + 4 mouth states)
- Pillow compositing (overlay eyes + mouth onto base at detected positions)
- Gemini 3.1 Flash Image (generate 7 animation spritesheets: walk, run, idle, jump, celebrate, scared, point)
- Gemini 2.5 Flash (validate spritesheet quality, retry if needed)
The frontend is React + TypeScript with Web Audio API for real-time lip-sync , FFT frequency analysis maps audio amplitude to mouth states (closed → slightly open → open → wide) at 60fps.
Stories are generated end-to-end: brainstorm outline → per-scene JSON with beats and interactions → panoramic backgrounds via image generation → pre-rendered TTS audio per dialogue beat → comic pages → video. All orchestrated through Celery + Redis for async processing.
Challenges we ran into
Spritesheet consistency was brutal. We went through 6 iterations trying to get AI-generated animation frames that didn't look like the character was melting between poses. V1 generated frames individually , wildly inconsistent sizes. V2 tried grid layouts , better but characters still "swam." V3-V5 experimented with biomechanical descriptions, leg crossover mechanics, different grid sizes. The breakthrough came in V6: generate a 16-frame 4×4 grid, split into individual frames, remove backgrounds, then apply uniform scaling using the largest bounding box across ALL frames. One scale factor for every frame. No more swimming. We then added AI-powered validation , Gemini 2.5 Flash analyzes the final spritesheet and flags bad frames, triggering automatic regeneration until quality hits 4/5.
Animating characters in stories. Getting clay characters to walk, run, jump, and celebrate across PixiJS scenes meant generating 7 different animation sets per character , each as a 16-frame spritesheet , and then orchestrating their movement, positioning, and timing across panoramic backgrounds with camera tracking. Characters needed to spawn, move to positions, play animations, and speak with lip-sync, all driven by a beat system that sequences dialogue, animation, and interactive choice points.
Video generation with character consistency. Generating claymation videos via Veo 3.1 that actually matched our characters required passing three reference images , the character's composite neutral pose, a scene context shot, and the story background , so the model could maintain visual consistency. Without all three references, the generated video would drift into generic clay figures that looked nothing like the characters kids had created.
Lip-sync timing. Getting mouth animations to feel natural required buffered audio scheduling through Web Audio API plus a hold-frame system that prevents the mouth from flickering between states too rapidly.
Multi-model orchestration. A single avatar generation touches Imagen 4.0, Gemini 3.1 Flash Image, Gemini 2.5 Flash (vision + text), and rembg , each with different rate limits, failure modes, and output formats. We built graceful degradation at every step so a conversation can still start even if mouth generation fails.
Gemini Live API + tool calling. The native audio model doesn't support Google Search in its tool config (returns a 1011 error), so we built a workaround: the agent's google_search tool routes through a separate Gemini Flash call with search grounding enabled, then feeds results back into the Live session.
Guardrails for a children's app. Every system prompt enforces age-appropriate behavior , characters must never generate scary content, redirect inappropriate questions gracefully, avoid violence or adult themes, and stay in character at all times. Parent-set rules are injected directly into the system prompt so the AI respects boundaries like "don't discuss [topic]" or "focus on [learning goal]." The parent dashboard gives full visibility into every conversation, so nothing happens in a black box.
Accomplishments that we're proud of
AI that validates AI. Our spritesheet pipeline uses Gemini 2.5 Flash as a quality gate on Gemini 3.1 Flash Image outputs. Generate → validate → retry. This pattern made the whole system reliable enough to run unsupervised, and it's the reason every character has 7 consistent animation sets.
A real conversation, not a chatbot. Gemini Live API enables genuine back-and-forth , kids interrupt, the character notices things through the camera, remembers what you talked about last time, and searches the web when it doesn't know something. It feels like talking to a character, not a computer.
Full content pipeline. A single conversation can become an interactive story with PixiJS animations, a comic book with AI-generated panels, or a claymation video via Veo 3.1 , all from the same transcript.
Parent-child loop. Parents set what their children should learn and what topics to avoid. The AI weaves learning goals into conversations and stories naturally, respects boundaries, and the dashboard shows what the child actually engaged with , mood, interests, concerns, favorite characters. The system doesn't just entertain , it reports back, and it listens to what parents need.
What we learned
Gemini Live API is genuinely different. It's not a chat endpoint with audio bolted on. The interruption handling, the ability to send camera frames mid-conversation, the natural turn-taking , it enables experiences that weren't possible before.
Kids don't need simple , they need patient. The system prompt engineering for child-appropriate conversation was surprisingly nuanced. Characters need to explain complex topics simply, redirect inappropriate questions gracefully, weave in parent-set learning goals naturally, and never talk down. Getting that right mattered more than any technical feature.
Multi-model orchestration is an art. Coordinating Gemini Live API, Gemini Flash, Gemini 3.1 Flash Image, Imagen 4.0, Veo 3.1, Gemini Embedding, and Gemini TTS , each with different rate limits, failure modes, and quirks , taught us that graceful degradation isn't optional. Every step needs a fallback.
What's next for ALIVE
Alive started as a hackathon project, but it's the tool I actually want to exist. Real-time object-based learning, personalized to each child, with parents in the loop. The foundation is here , the next steps are mobile-native deployment, multi-language support, and long-term learning progression tracking across sessions.
Every object has a story. Now they can tell it themselves.
Built With
- celery
- chromadb
- fastapi
- gemini-2.5-flash
- gemini-2.5-flash-image
- gemini-2.5-flash-native-audio-preview
- gemini-2.5-flash-preview-tts
- gemini-3.1-flash-image-preview
- gemini-embedding-2-preview
- gemini-live-api
- google-cloud
- google-cloud-firestore
- google-cloud-run
- google-genai-sdk
- google-search-grounding
- imagen-4.0
- jspdf
- katex
- node.js
- pillow
- pixijs
- pwa
- pymupdf
- python
- react
- react-markdown
- redis
- rembg
- typescript
- veo-3.1
- vertex-ai
- vite
- web-audio-api
- websockets
Log in or sign up for Devpost to join the conversation.