-
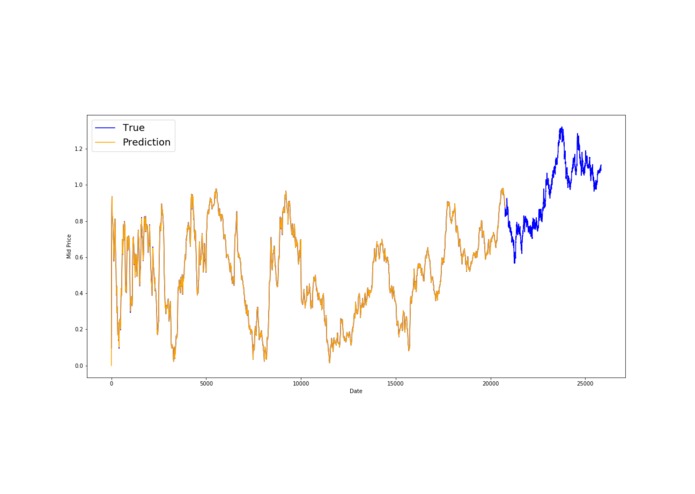
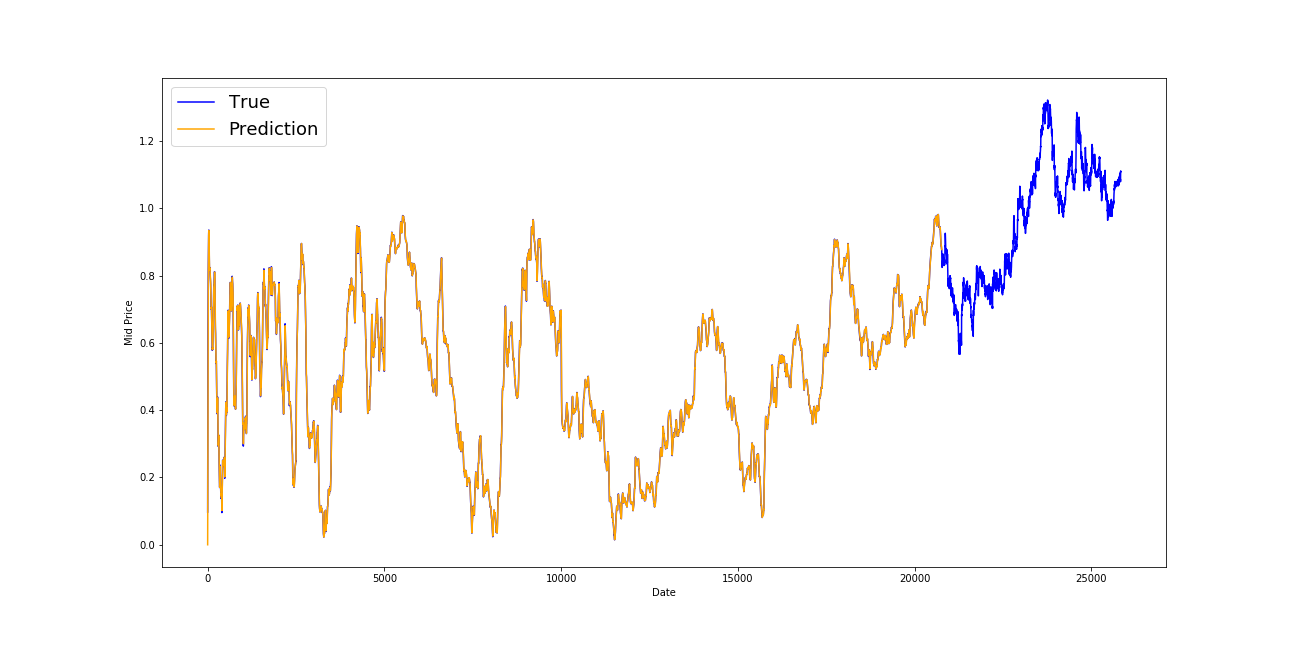
In-sample fit
Description of our strategy
We would like to model stock prices correctly, so as a stock buyer you can reasonably decide when to buy stocks and when to sell them to make a profit. This is where time series modelling comes in. We need good machine learning models that can look at the history of a sequence of data and correctly predict what the future elements of the sequence are going to be. However, we have to beware of many hurdles, such as underfitting, overfitting, stability and many more.
After pre-processing our financial dataset, we concluded it might be best to try a Long-Short Term Memory Neural Network, as we have to accurately predict hourly stock prices for the next seven months.
LSTM Model
LSTM Neural Networks, which stand for Long Short-Term Memory, are a particular type of recurrent neural networks that got lot of attention recently within the machine learning community. They are extremely powerful time-series models. They can predict an arbitrary number of steps into the future. In a simple way, LSTM networks have some internal contextual state cells that act as long-term or short-term memory cells.
The output of the LSTM network is modulated by the state of its cells. This is a very important property when we need the prediction of the neural network to depend on the historical context of inputs, rather than only on the very last input.
Additionally, they manage to keep contextual information of inputs by integrating a loop that allows information to flow from one step to the next. Predictions are always conditioned by the past experience of the network’s inputs. Remembering information for long periods of time is practically their default behaviour, not something they struggle to learn. And this is why it was really helpful in the case of the Kaggle project.
Here is a short description of the steps taken to achieve this goal:
Splitting Data into a Training set and a Test set Normalizing the Data One-Step Ahead Prediction via Averaging for intermediate evaluation. Exponential Moving Average for intermediate evaluation. However, we want to predict more steps into the future. To be exact, we need to predict 5064 timepoints.
Hence, the following steps were taken:
First, we implemented a data generator to train your model. Defining Hyperparameters Defining placeholders for training inputs and labels. Defining Parameters of the LSTM and Regression layer Calculating LSTM output and Feeding it to the regression layer to get final prediction Loss Calculation and Optimizer Prediction Related Calculations Finally, we run the LSTM using 30 epochs and determine the best epoch out based on the RMSE. NLP Strategy by Andrea de Marco
We are given 10 years’ worth of Reuters articles from 2007 to 2017. This amounts to approximately 2.5 million articles. In an ideal scenario, we must iterate through every single article, access the URL, generate a transcript of the actual article, preprocess the transcript, and run sentiment analysis and topic modelling in order to generate the relevance of the article to our problem and score to quantify how important the article could contribute to the inflation and deflation of the market.
Within a hackathon environment, implementation would have presented the team with several issues, including subpar performance and code efficiency, due to the rush of hacking. More importantly, accessing all those articles, preprocessing and generating a score would have taken a considerable amount of time and computational power. The code was compiled on a 1.4GHz i5 dual core MacBook Air, which is considerably old machine and hence efficiency had to be taken into consideration.
The Reuters data was stored in pickled data files containing a timestamp, title and URL for all the articles that were published per day. We choose 1546 days in total from 1 January 2014 to 31 December 2017, this is because the teams were given foreign exchange data of the mystery stock for that date range.
In order to save on memory and computational performance, the first step was to iterate through each title and put in place a filter that removes all the titles that are not relevant to the financial world. For this we used a csv file from the Loughran-McDonald Master Dictionary (https://sraf.nd.edu/textual-analysis/resources/ - identical to using pysentiment) to represent out financial dictionary. Additionally, we have also added our own custom list to this dictionary with adds important terms that were not included in the dictionary.
Furthermore, the titles went through two rounds of preprocessing where all the numbers and characters joined to these numbers were removed, all the punctuation was removed and letters were made lower case. This amounted to a corpus of titles of that was used to create a sentiment score. The next step was to generate a sentiment score that ranges from 1: positive to –1: negative based on the words included in the titles. To do this we used the package textblob. For each day, the mean from the score of each title was calculated.
Due to inefficient time, we opted to give a sentiment directly from the title. Ideally, after the titles were filtered, web scrapping could have been initialized which generates a transcript of the article. After preprocessing, the corpus would have given us a more reasonable sentiment score for each article which could then apply to our final score of each day. At this point, I should say that we were working under the assumption that a positive sentiment score would indicate stocks to rise whilst a negative sentiment score would indicated stocks to fall.
Instead, we decided to focus our efforts on generating a sentiment score based on the titles of the article per hour instead of per day. This required a bit of time to hack and iron out the bugs, but in the end we ended up with a csv file that has two columns, the timestamp per hour from January 1, 2014 and December 31, 2017; and the sentiment score from –1 to 1.
The csv file generated includes 13 days of sentiment score (there was an error on Day 14 due to Chinese letters) and took approximately 5 minutes. The whole 1546 days would have taken approximately 2 hours to compile and render the csv file.
Other ideas: Get an indication of the type of stock the mystery ticker, by looking at the prices given to us. This might be helpful in order to introduce an additional filter that analyses articles relevant to these types of stocks/tickers.
Challenges faced:
• Learning NLP as we go – this took a considerable amount of time but I felt as though this was a necessity to get a brief idea of what we were actually trying to do. • Minor bugs had to be fixed along the way, but I feel like this would be an issue for everyone. • Chinese titles – my guess would be to either remove characters not related to the English language (did not have time to work on this in the end)
Next Steps
The natural next step would be to combine the sentiment score from the NLP algorithm with the LSTM model in order to predict a more accurate forecast of the mystery ticker. However, our methods have not been able to improve our own imposed based model which is an adjusted forward carried last observation, giving us an RSE of 0.01855.
Built With
- jupyter-notebook
- python


Log in or sign up for Devpost to join the conversation.