-
-

The home screen, showing a users' documents
-
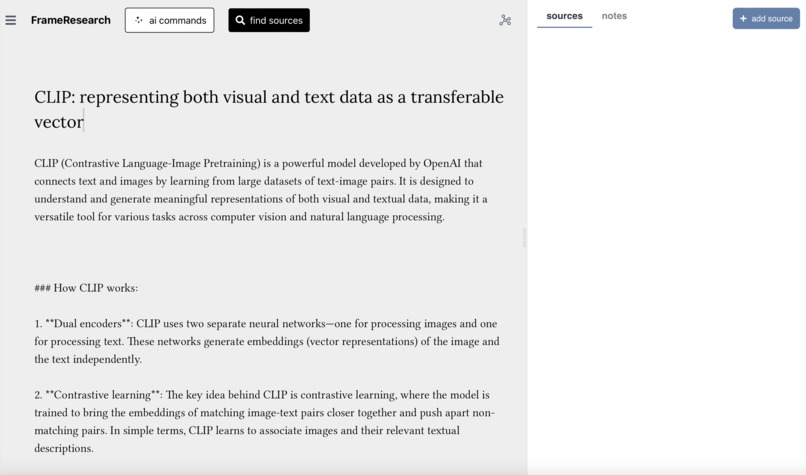
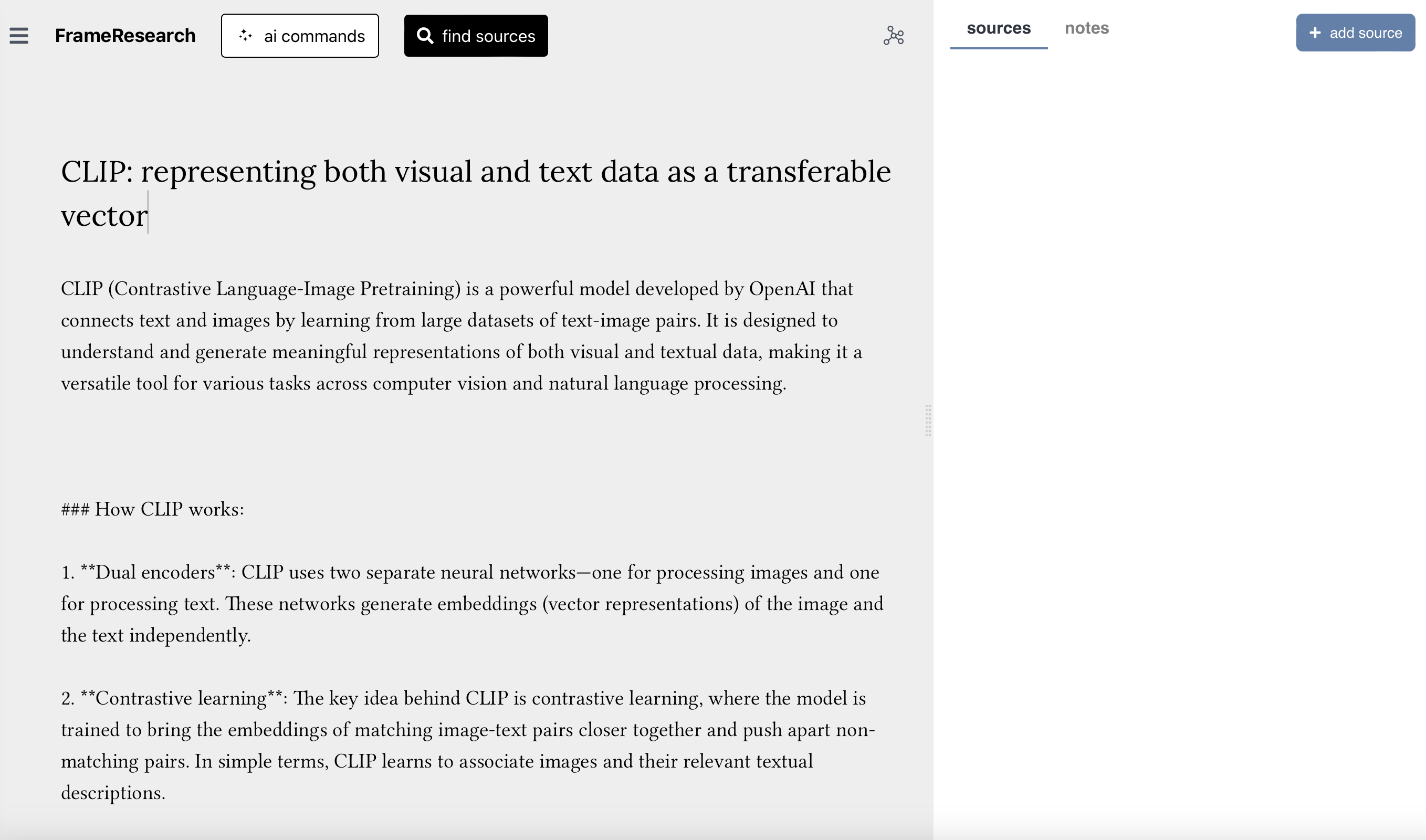
The editor window, with source management on the left
-
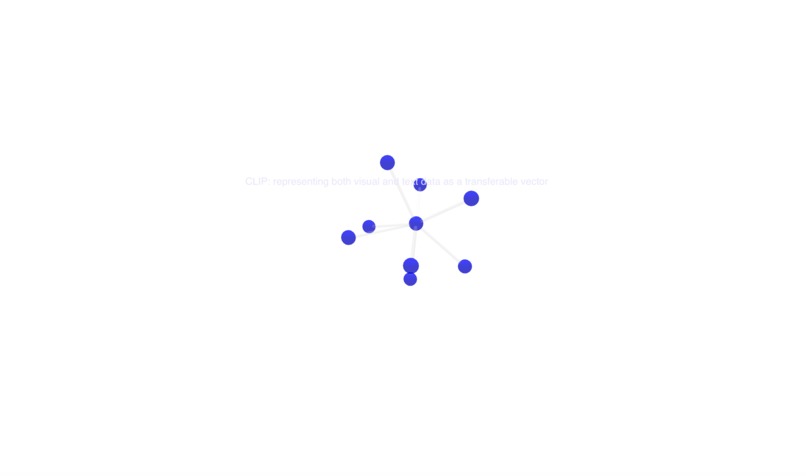
The document explorer tab, to explore what your peers are working on and how closely related their work is to yours
-
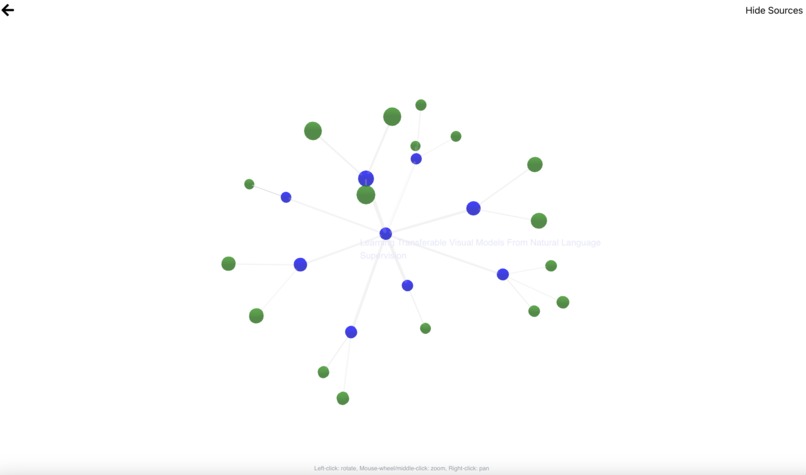
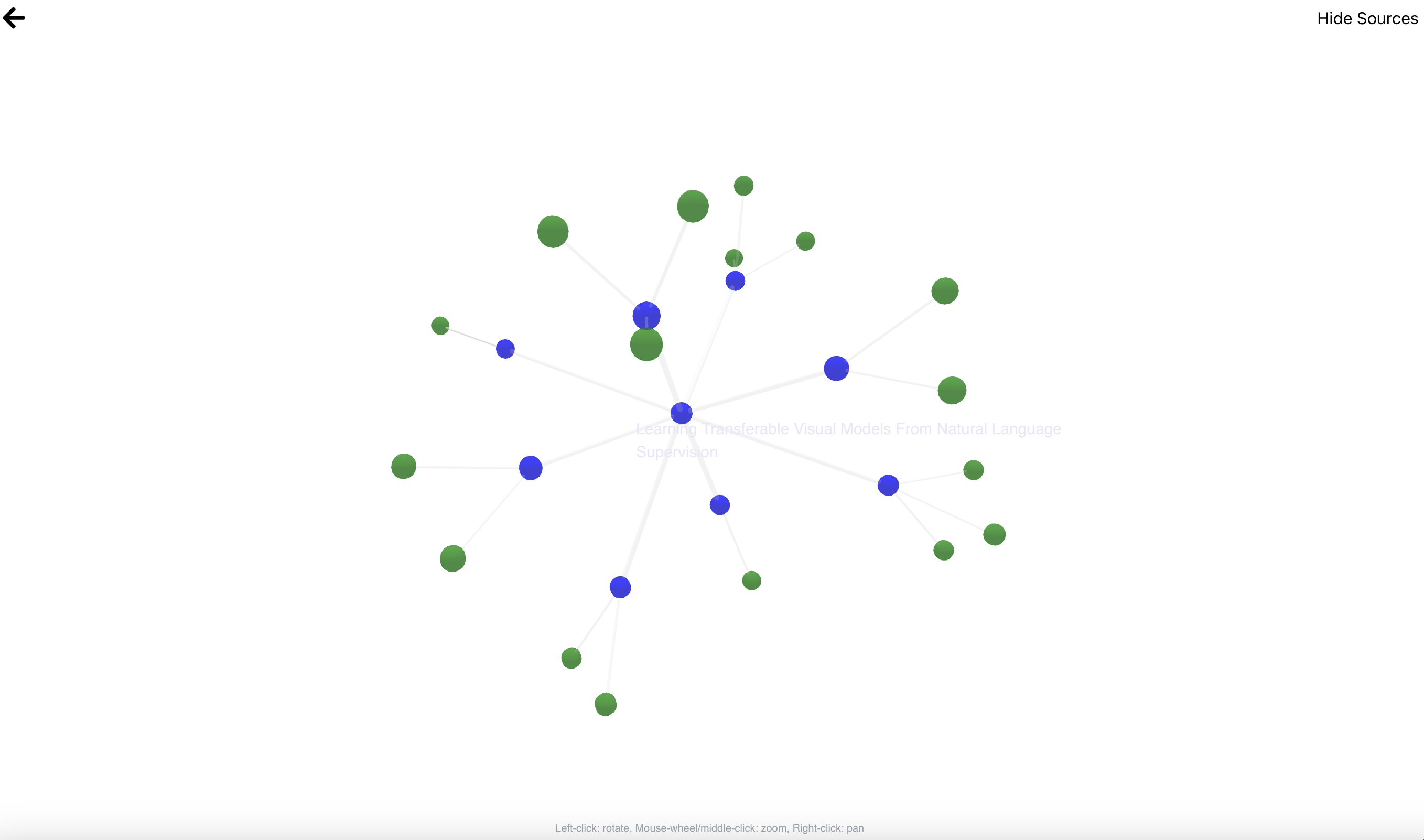
The document explorer tab with the sources shown (the green nodes)

Inspiration
I was working at a big tech company this past summer on a research-adjacent team, and the method of storing information was mainly through google docs-style documents, where links would just be passed around via slack. This made it hard to find out what other people were working on, and moreso how that could relate to what I was working on.
What it does
It computes similarity scores for your documents, and represents the documents you have, the documents your peers have, as well as all the sources used for each document as a weighted graph and allows you to find other people's work and research that's related to yours.
How we built it
Used Distilbert for generating embeddings, Singlestore db with vector store, python + JS backend, with React for the frontend work. All of it is hosted on digitalocean droplets.
Challenges we ran into
I ran into problems working with the text data from the JS editor and providing it to the bert-endpoint.
Accomplishments that we're proud of
I'm proud of the fact that it's a mostly working product, and that the similarity scoring actually works!
What we learned
Learned a lot about devops this time and about Singlestore's DB, I was fairly familiar with the other frameworks and technologies used.
What's next for Frame
I think it would be cool to keep building in more features, possibly ML-related.
Built With
- digitalocean
- python
- react
- singlestore



Log in or sign up for Devpost to join the conversation.