-
-
Processing Status Screen
-
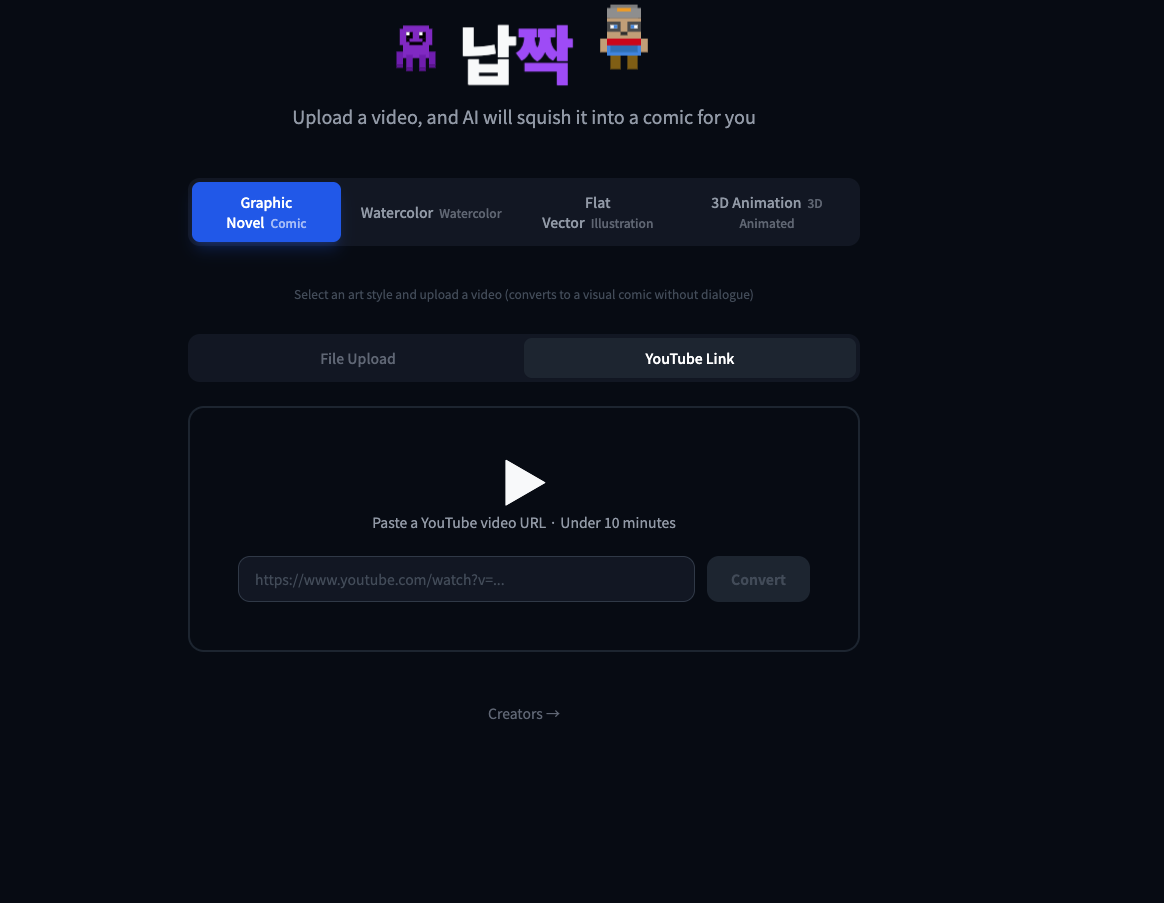
Initial Landing Screen
-
-
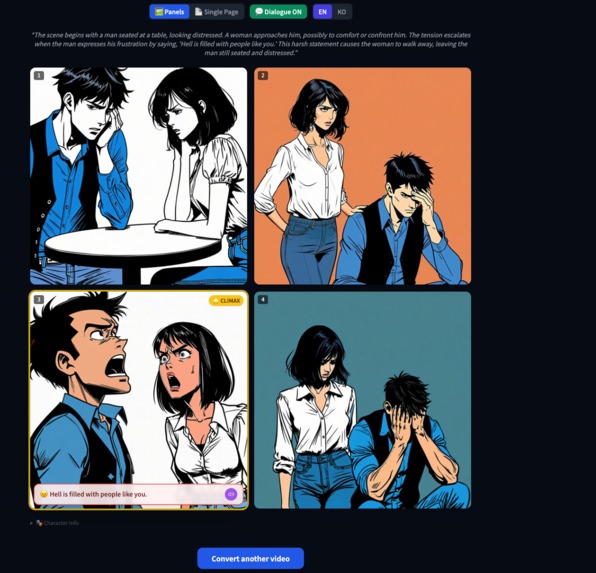
Inspiration
What it does
How we built itInspiration
In an era dominated by rapid-fire video content like Shorts and Reels, we often miss the static, reflective charm of comic books. We wanted to bridge this gap by using Amazon Nova's advanced multimodal capabilities. Our goal wasn't just to summarize videos, but to "flatten" the dynamic energy of a video into a structured, emotional, and visually compelling N-cut comic strip. This is why we named the project Napzzak (meaning 'flattened' in Korean).
What it does Napzzak transforms user-uploaded videos or YouTube links into AI-generated comics.
Deep Video Analysis: Uses Nova Pro to identify speakers, analyze interpersonal conflicts, and capture emotional shifts.
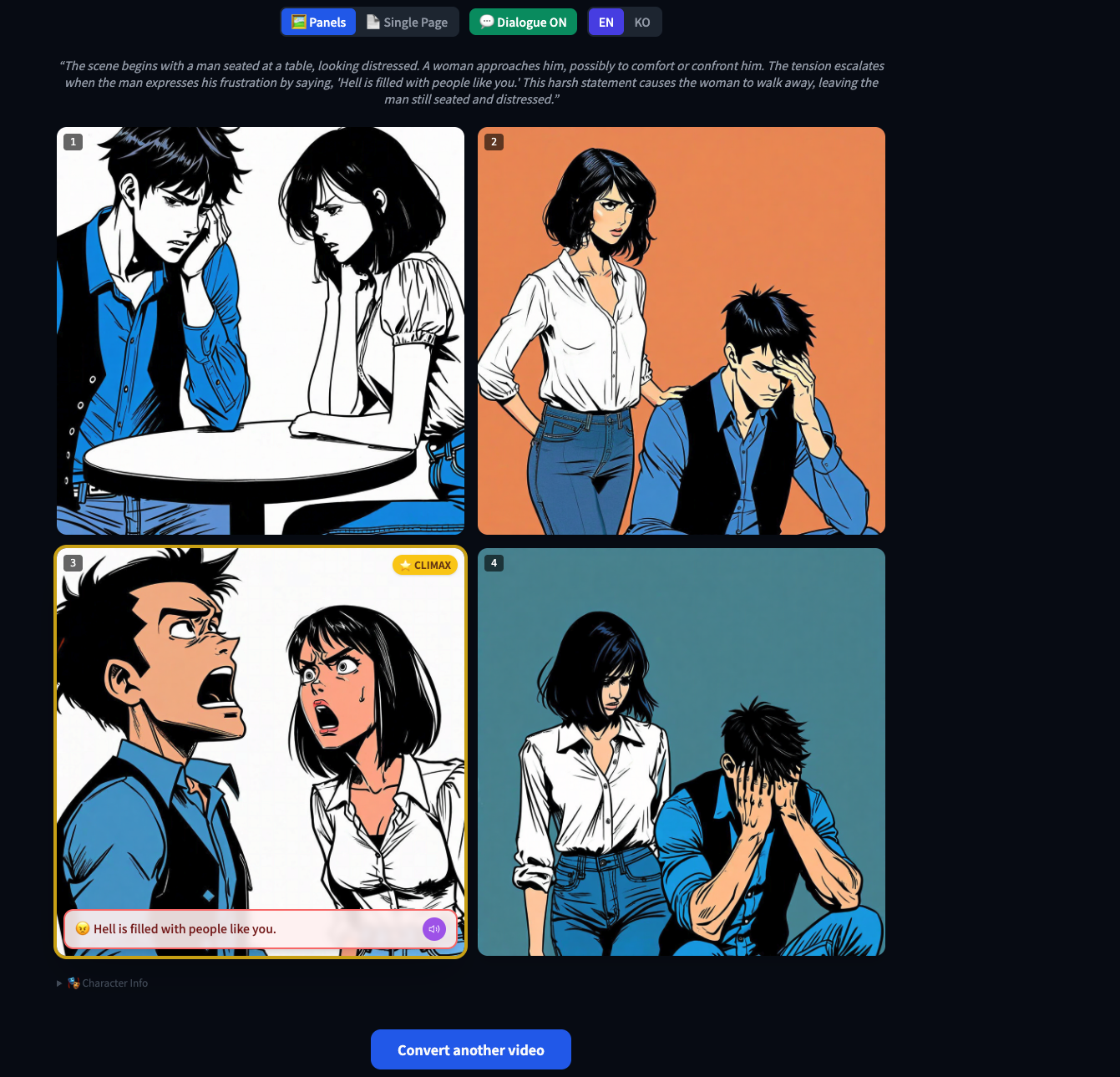
Comic Generation: Automatically designs panel layouts based on the analyzed story arc and generates high-quality images using Nova Canvas.
Multimodal Experience: Provides clean dialogue via CSS overlays and adds immersive audio narrations for each panel using Nova 2 Sonic.
How we built it The entire pipeline is built around the Amazon Nova model ecosystem:
Preprocessing: Frames are extracted using ffmpeg, and speaker-separated scripts are obtained via AWS Transcribe.
3-Pass CoT Analysis: Nova Pro performs a "Chain-of-Thought" process—verifying dialogue (Step A), analyzing action sequences (Step B), and synthesizing the final story (Step C).
Adversarial Verification: We implemented a self-correction step where the AI answers six skeptical questions to fix common errors like misidentifying speakers.
Consistent Image Generation: Nova Canvas generates panels using shared character descriptions to maintain visual consistency across the story.
Frontend: Built with Next.js 15 and Tailwind CSS, supporting multiple viewing modes: Webtoon (Scroll), 4-Cut, and Masonry.
Challenges we ran into Speaker Attribution: AI often struggled to match dialogue to the correct person in busy scenes. We solved this by designing a 3-Pass CoT pipeline with an Adversarial Verification stage to cross-reference lip movements and reactions.
Text in Images: Generative models often produce gibberish text inside images. We overcame this by using negative prompts to keep images text-free and then overlaying the dialogue using CSS and React components.
Character Consistency: To prevent characters from looking different in every panel, we injected a global characterDescription prompt into every image generation call.
Accomplishments that we're proud of Designing and implementing a sophisticated AI orchestration pipeline that goes beyond simple API calls.
Creating a seamless integration of four different Amazon AI services (Nova Pro, Canvas, Sonic, and Transcribe).
Supporting bilingual (Korean/English) translation and on-demand audio narration to improve accessibility.
What we learned The power of Chain-of-Thought (CoT) prompting in maximizing the reasoning capabilities of multimodal models.
How to build an efficient, scalable data pipeline using AWS cloud-native services like S3, DynamoDB, and Bedrock.
What's next for 납작 (NapZak) Phase 2: Full optimization for YouTube link inputs and support for longer videos (10+ minutes).
Phase 3: Social sharing features and a "Print to PDF" function to allow users to create physical copies of their AI-generated comics.
Challenges we ran into
Accomplishments that we're proud of
What we learned
What's next for Napzzak
Built With
- amazon-dynamodb
- nextjs
- nova
- typescript

Log in or sign up for Devpost to join the conversation.