-
-
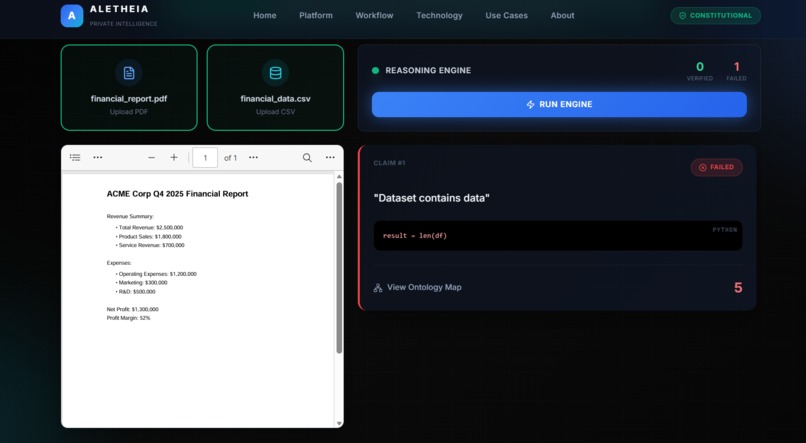
here the engine identify the mistake and highlights it in red colour
-
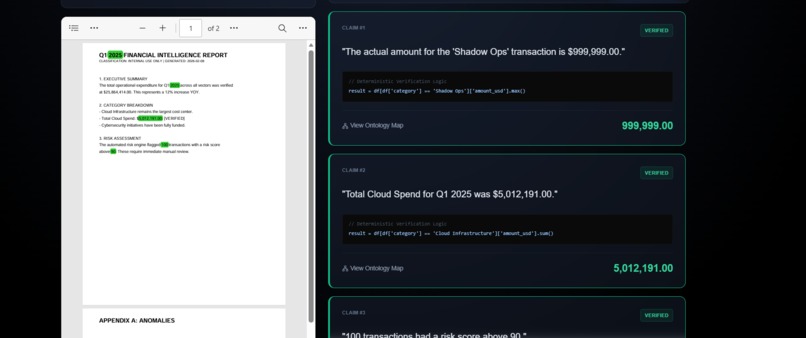
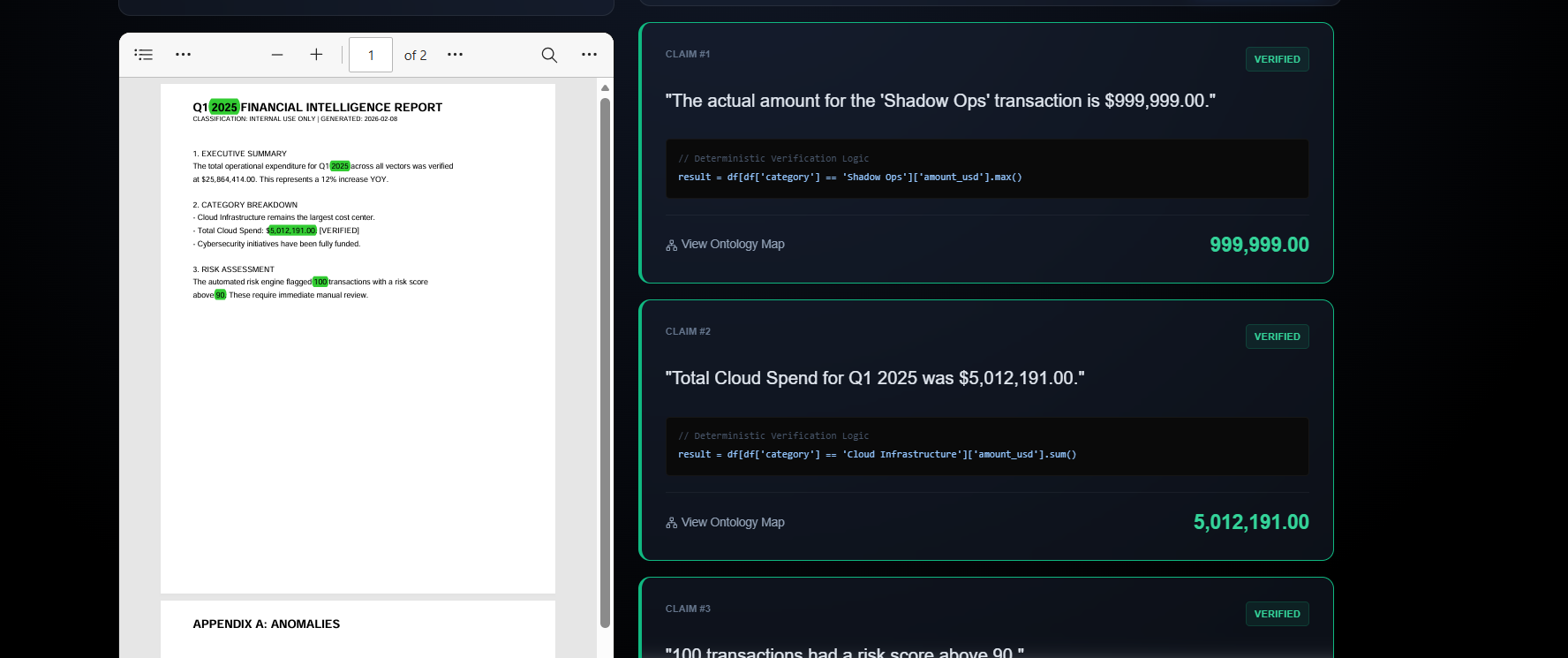
here the engine identify the matter is correct and highlights it in green colour
-
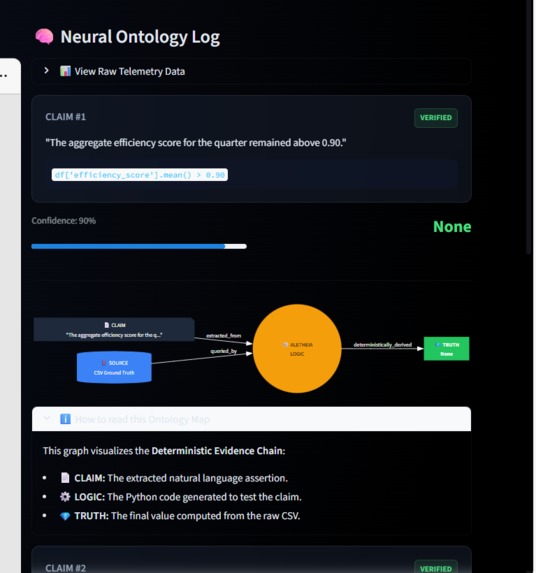
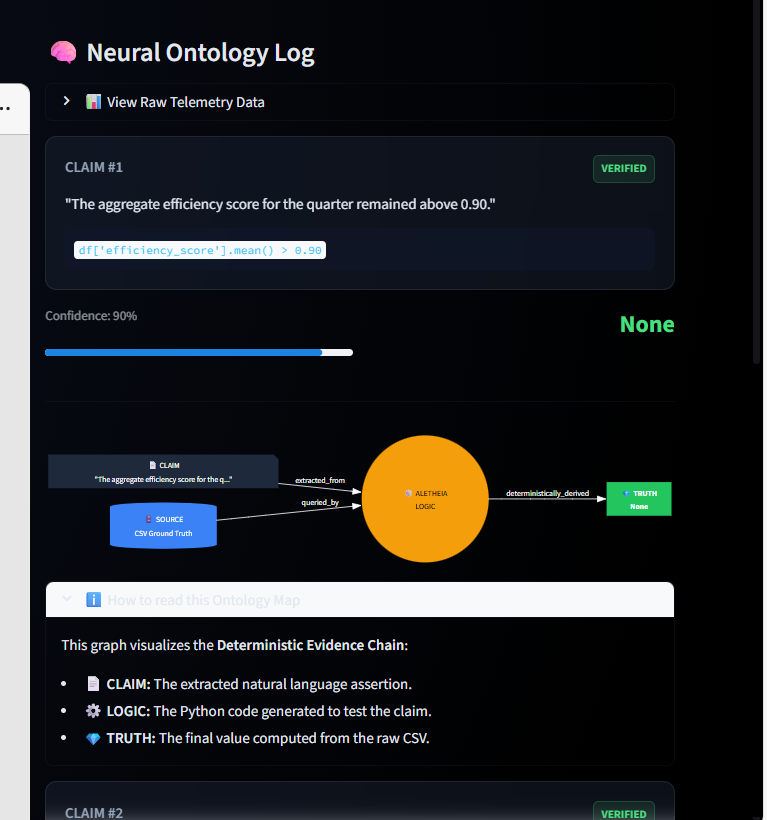
here it shows the logic and Ontology map
Inspiration
In high-stakes industries like Finance, Aerospace, and Healthcare, a "99% accurate" AI model isn't a success—it’s a liability. We are currently witnessing a "Trust Crisis" in Enterprise AI. Standard Large Language Models (LLMs) are probabilistic engines; they predict the next word, not the objective truth. When asked to audit a financial report, they often "hallucinate" numbers that look plausible but are factually wrong.
We were inspired by the concept of Neuro-Symbolic AI—bridging the semantic understanding of neural networks with the mathematical certainty of classical programming. We asked ourselves: What if we stopped asking the AI to calculate the answer, and instead asked it to write the code to find the answer?
Aletheia was born to solve the "Hallucination Gap." It moves us from "Chatting with Data" to "Auditing with Data," creating a digital paper trail that stands up to forensic scrutiny.
What it does
Aletheia is a Neuro-Symbolic Truth Engine that autonomously verifies unstructured claims against structured ground-truth data.
- 🛡️ Constitutional Safety Layer: Before any data touches the model, a pre-computation privacy layer scans for PII (Social Security Numbers, Credit Cards). Violations trigger a hard system block, ensuring compliance by design.
- 🧠 Deterministic Verification: Instead of guessing answers, Aletheia uses Google Gemini 2.5 Flash to generate Python code (Pandas/NumPy). This code is executed in a secure sandbox against the raw data to mathematically verify claims.
- 👁️ Visual Grounding: It doesn't just say "True" or "False." It highlights the evidence directly on the PDF—drawing Green boxes for verified facts and Red boxes for discrepancies.
- 🕸️ Ontology Maps: It generates real-time Knowledge Graphs (via Mermaid.js) that visualize the "Chain of Thought," tracing the lineage from Claim → Logic → Truth.
How we built it
We architected a pipeline that decouples Reasoning from Knowledge:
- The Brain (AI): We utilized Google Gemini 2.5 Flash via the
google-genaiSDK. Its massive context window allows us to ingest dense financial documents, and its superior code-generation capabilities are central to our logic engine. - The Eyes (Vision): We used PyMuPDF (Fitz) to perform fuzzy text searching within the PDF and render byte-level annotations (highlights) dynamically.
- The Hands (Execution): The backend is built on FastAPI (Python). It acts as a secure sandbox where the AI-generated code is executed against uploaded CSV datasets.
- The Face (UI): The frontend is a "Palantir-style" dashboard built with HTML5, Tailwind CSS, and Vanilla JS, using Mermaid.js for dynamic graph rendering.
Challenges we ran into
- The "Fuzzy Match" Problem: PDF text extraction is messy. Often, the AI would identify a claim, but our highlighter couldn't find the exact string in the PDF due to hidden newlines. We solved this by implementing a 3-Stage Fuzzy Search algorithm that breaks claims down into keywords and numerical values to locate them even in messy documents.
- Graph Rendering: Generating complex Mermaid.js diagrams inside hidden DOM elements caused the visualization engine to crash. We re-architected the frontend to handle asynchronous graph rendering only after the DOM was fully updated.
- Prompt Engineering: Early versions of the model tried to "guess" the answer in comments. We had to refine our system prompts to strictly enforce a "Code-Only" response format.
Accomplishments that we're proud of
- Zero Hallucinations: We successfully demonstrated that by forcing the model to use Python code, we eliminated numerical hallucinations. If the data isn't there, the code throws an error—it doesn't lie.
- The "Red Box" Moment: Seeing the system correctly identify a hidden financial discrepancy (a $9M vs $50k mismatch) and highlighting it in Red on the PDF was a massive validation of our forensic approach.
- Privacy First: Successfully implementing a privacy layer that blocks PII before API calls are made.
What we learned
- Logic > Knowledge: LLMs are far more powerful when used as "Reasoning Engines" (writing code) rather than "Knowledge Bases" (reciting facts).
- Trust requires Visuals: Telling a user "this is false" isn't enough. Showing them where in the document it is false (Visual Grounding) and how we know it's false (Ontology Map) is essential for enterprise adoption.
What's next for Aletheia
- Enterprise Connectors: Integrating direct SQL connections (Snowflake, Salesforce) so audits can run against live databases instead of uploaded CSVs.
- Human-in-the-Loop (HITL): Adding a code editor in the UI that allows human auditors to review and tweak the Python logic before it executes.
- Multi-Document Correlation: Scaling the engine to cross-reference a single claim against hundreds of disparate documents simultaneously.
Built With
- fastapi
- google-gemini
- javascript
- mermaid-js
- numpy
- pandas
- pymupdf
- python
- render
- tailwind-css
- vercel

Log in or sign up for Devpost to join the conversation.