Introduction
In order to reach the U.S. national on-time high school graduation rate by 2020, government may need to implement some new methods. In this challenge, I analyzed high school graduation rate under education agency(district) level and tried to find insights that are actionable. When dealing with observational study, it is almost impossible to draw causal relation. It is not reasonable to simply plot one chosen variable against Whole state graduation rate and claim the pattern we see is the true relation. Like the idea from multiple linear regression, we have to adjust the effects of other variables and then check the relation between one variable against graduation rate. Under certain criteria, the situation of graduation rate can be totally different for each cluster and therefore we have to implement different methods for different clusters. The challenge part is to find these criteria. I used GUIDE( a multi-purpose machine learning algorithm for constructing classification and regression trees) to build models, find the most discriminated variable and do analysis under the criteria given by the most discriminated variable. Comprehensive report that describe the whole processes I did and results I have is here: ( Please click it and see) Comprehensive report
Below is a glance of the report.
Summary of data cleaning
Merged three datasets together. They are:
1.merged(Required dataset)
2.Education Finance data( elsec12t)
3.Local Education Agency Universe Survey Data( common core of data).
Found the maximum overlap of school agencies of these three datasets
Removed redundant variables ( EX: MOE, marginal of error from Required dataset)
Converted variables into consistent type
Applied feature engineering
Final dataset has school agency = 9866 and variable = 352
Model building
One thing I need to point out before building the model is, if we are predicting ALL_RATE( total student graduation rate), we should not put other graduation rate such as MAM_RATE ( Native American graduation rate), MAS_RATE (Asian/Pacific Islander graduation rate) and other relative graduation rates inside the model. Because we do not know the relative graduation rate, just like we do not know ALL_RATE when we are trying to predict it. Adding relative graduation rates into the model will make the model become useless. ( And the real R^2 should be much lower than R^2 from this wrong model)
I used R to do data cleaning, feature engineering, and basic analysis.
I used GUIDE( Run in terminal) to build machine learning model and inputted into R. ( Sorry I said it wrong in the video)
I use tree based Machine learning algorithm from GUIDE, build different models for:
Total graduation rate against selected features from Merged dataset, Education Financial dataset and NCES data.
There are two purposes for the models I built:
1.For finding insight.
2.For achieving higher prediction accuracy and R square.
I first built models using data without geographical variables( State, City, County, Tract), because I want to find pattern based on school agency level. Then I add the geographical variables to build model that can lead to a higher prediction accuracy. The reason I don’t simple use a multiple linear regression to predict graduation rate is because there are too much noisy and factors inside whole data. We can not simply expect that some selected features from linear model can accurately explain the variability of whole state. Instead, I used decision tree, which will find different clusters by making split based on different features that can give lowest prediction error. Decision tree can find those most discriminant features and it is good enough for me to have the information to start with.
There are different parameters I can set for a specific single tree, some options are:
Which method to use at each node:
1.Best simple linear regression
2.Stepwise linear regression
Pruning standard error
Maximum depth of the tree
Minimum sample size at each node
I can also build model based on ensemble trees
1.Random Forest
2.Bagging
Different parameters will give me different tree. Generally what kind of tree model to use is based on required purpose. When building model based on machine learning algorithm, model can easily become a blackbox when I choose complex parameters.( uninterpretable, but achieve much higher prediction accuracy). If I want the tree to be as much interpretable as it can, I will use a simple tree. ex: Use best simple linear at each node for a single tree. If I want to achieve the best prediction I can, I will use ensemble tree. ex: Use random forest, average prediction results from many trees, with each tree randomly choose some features to consider for split.
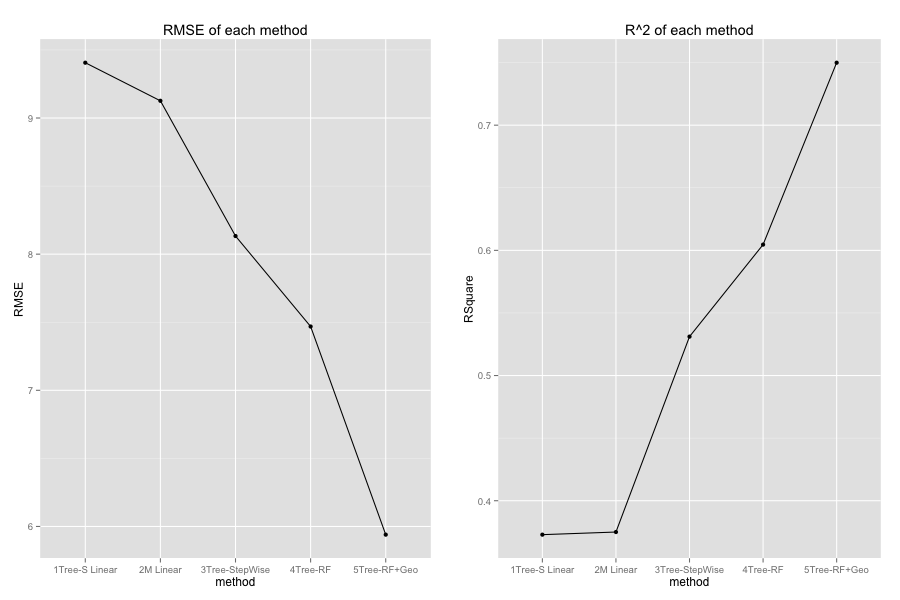
One thing we need to be aware of is that we should avoid overfitting, which means you can get a relative low prediction error and relative high R^2 from the data you used to fit( In this case, data before 2015), but when you make prediction for a completely new dataset ( For example, new graduation rate of 2016), you prediction error will be larger than before and R^2 will also decrease. One way to avoid it is to use cross validation when you train your model. The methods I finally choose and the results I provide are all calculated after using cross validation. Therefore, even though the R^2 is not the highest I can achieve, the results are more accurate and stable.
For finding insight, I used the model Tree-StepWise (fit stepwise multiple linear regression at each node for a single tree), which is not that simple as multiple linear regression or Best simple linear at each node for a single tree, and not that complicated or uninterpretable as Random forest.
For achieving best prediction accuracy, I used Random Forest.
Conclusion
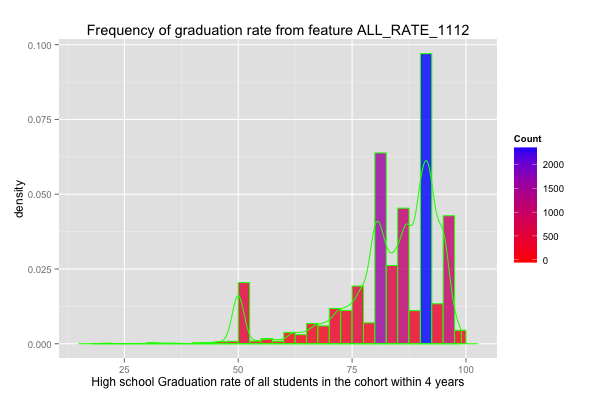
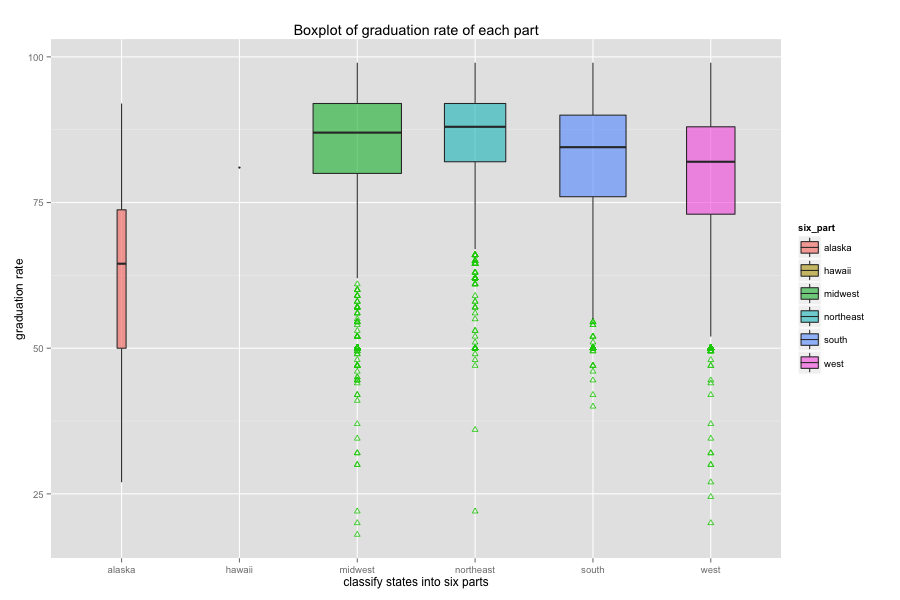
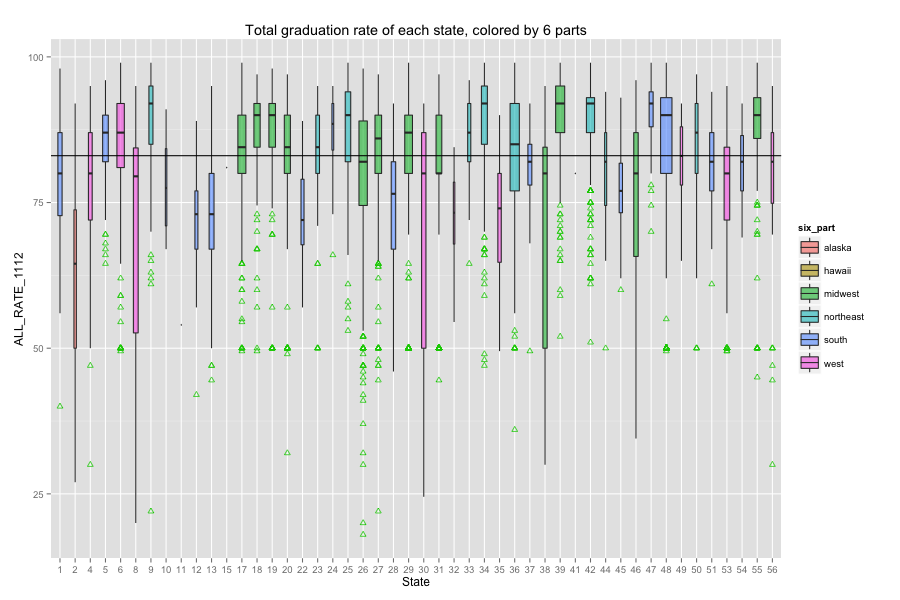
My best model captured 75% variability of graduation rate, with adjusted R-square 0.75. Root mean square error is around 6%.
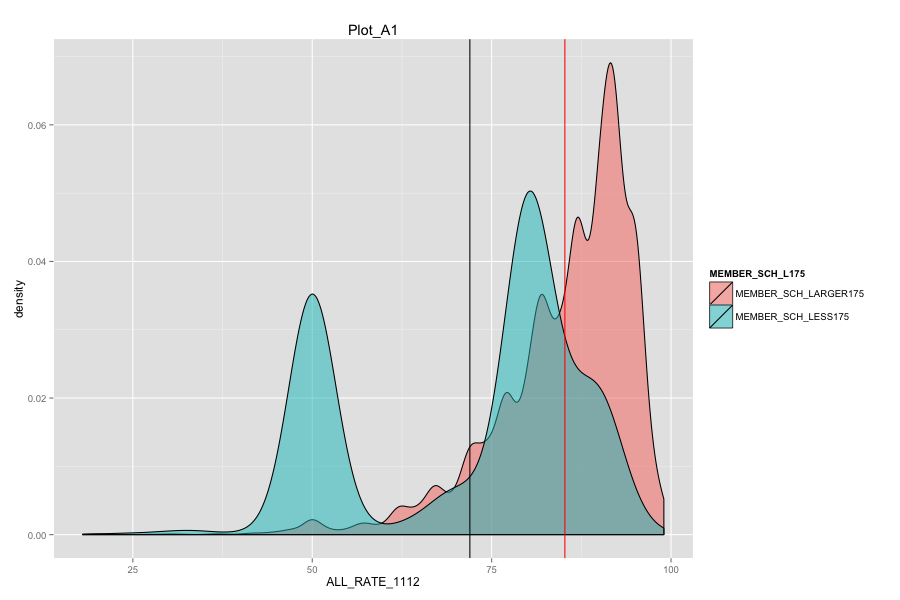
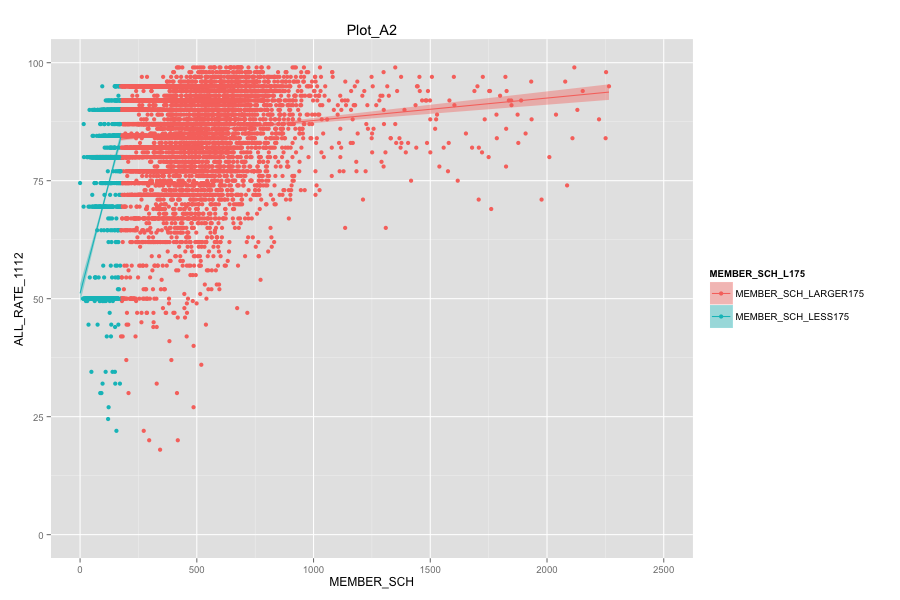
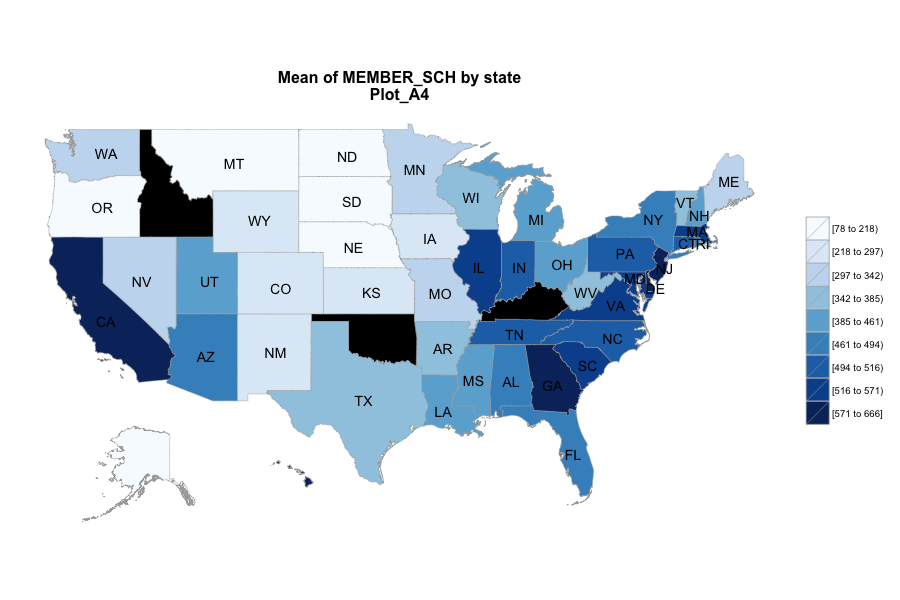
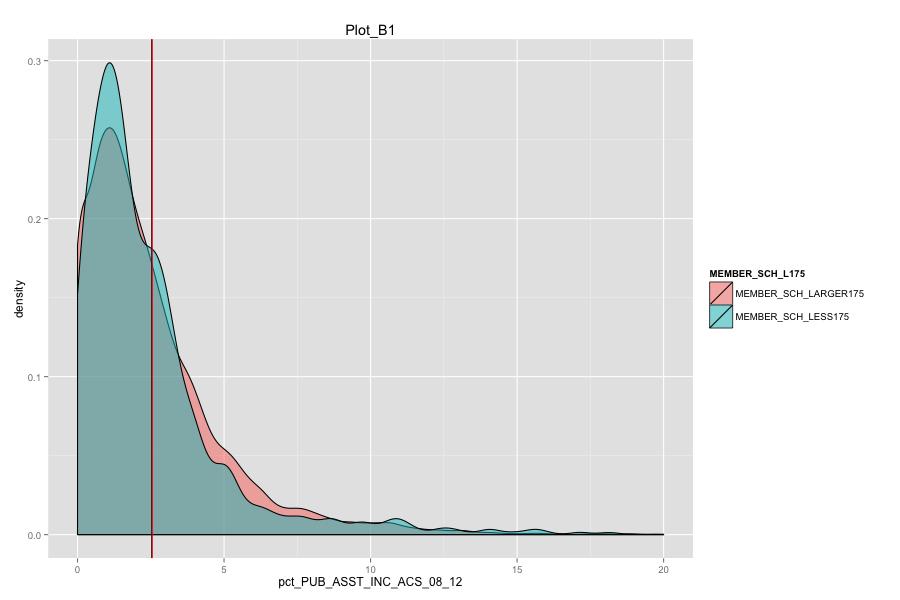
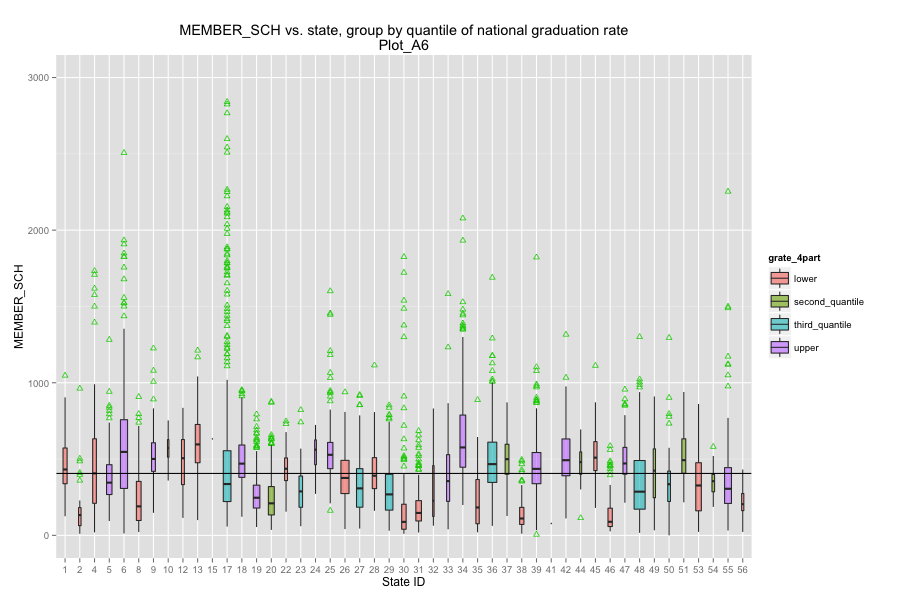
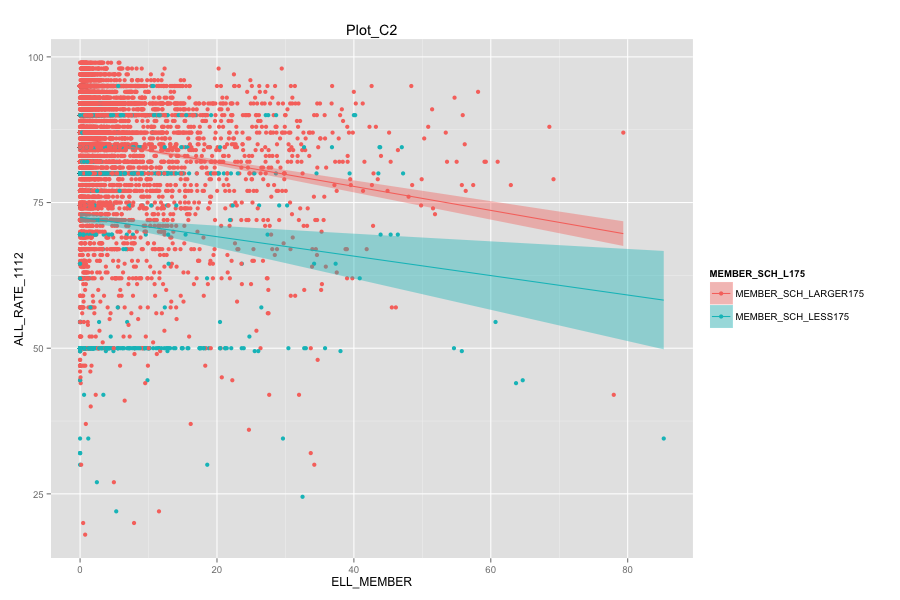
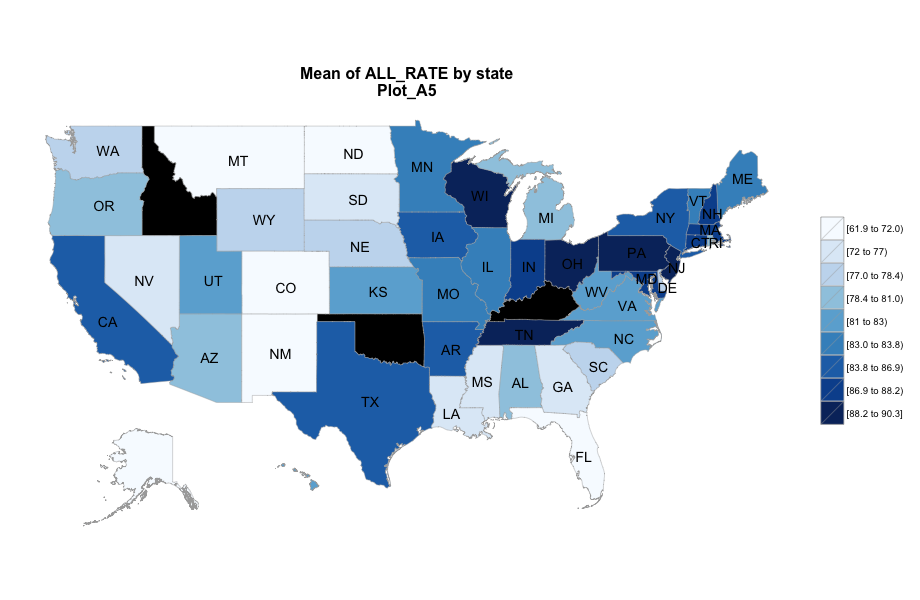
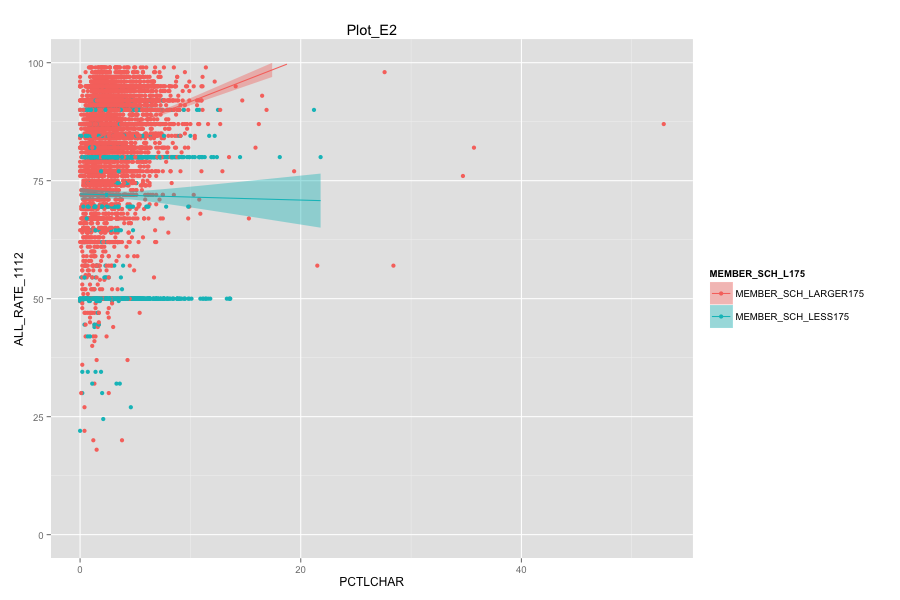
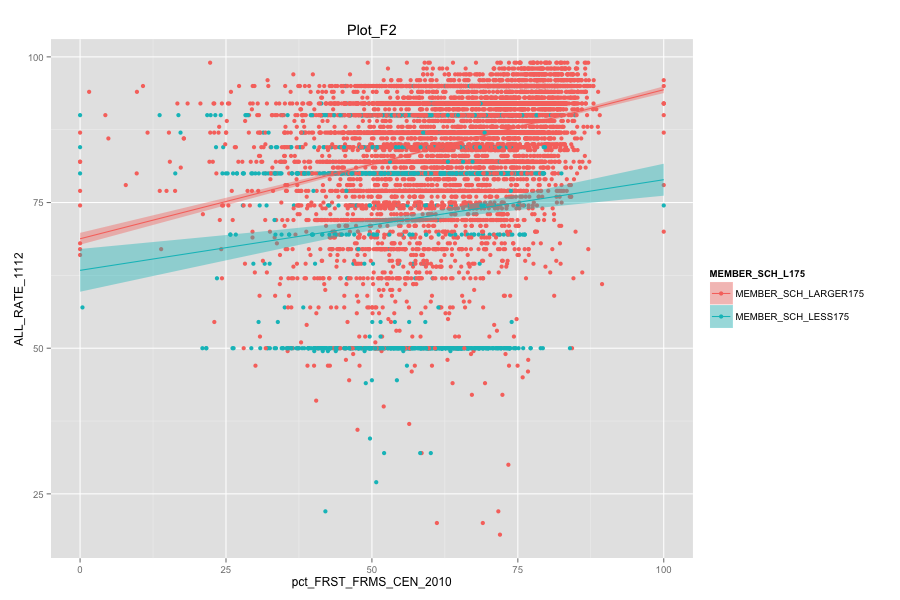
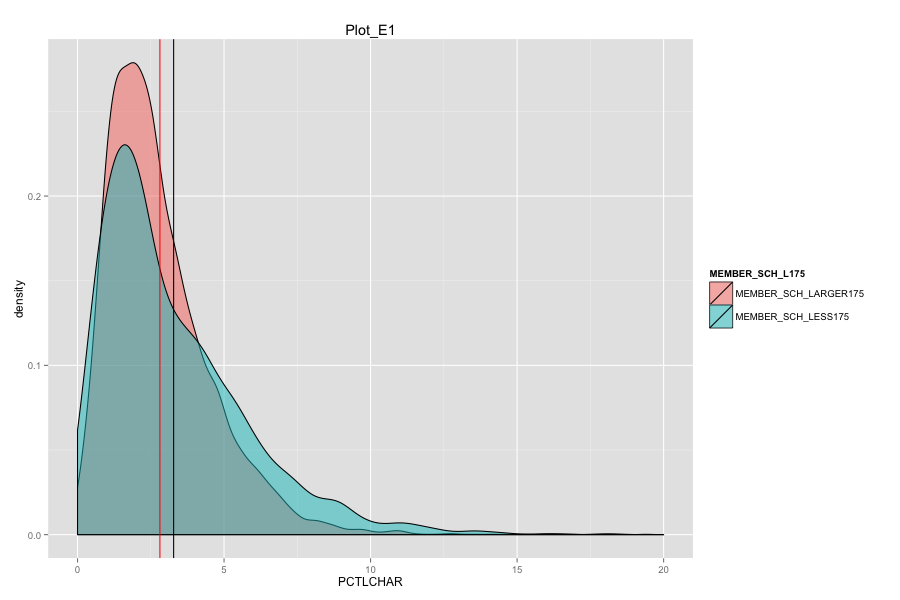
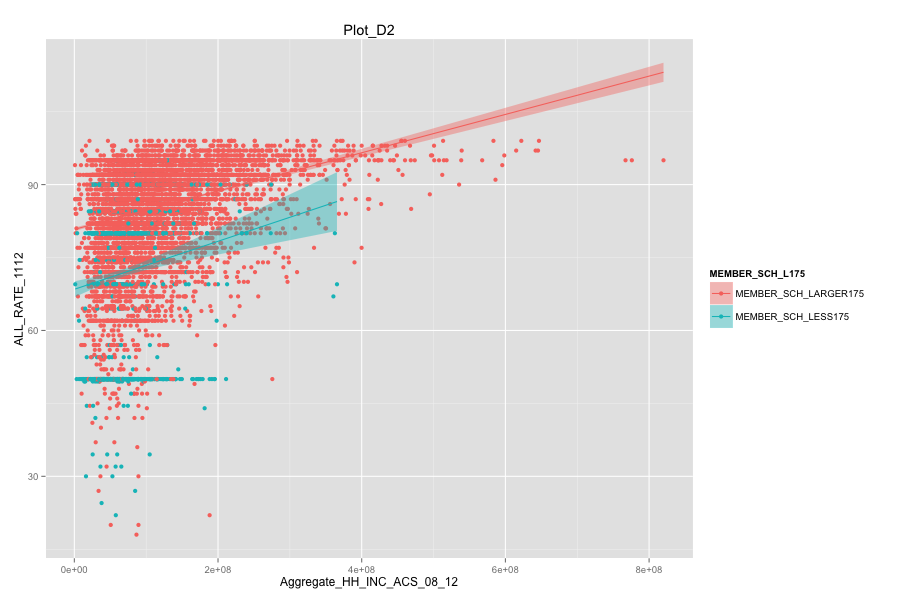
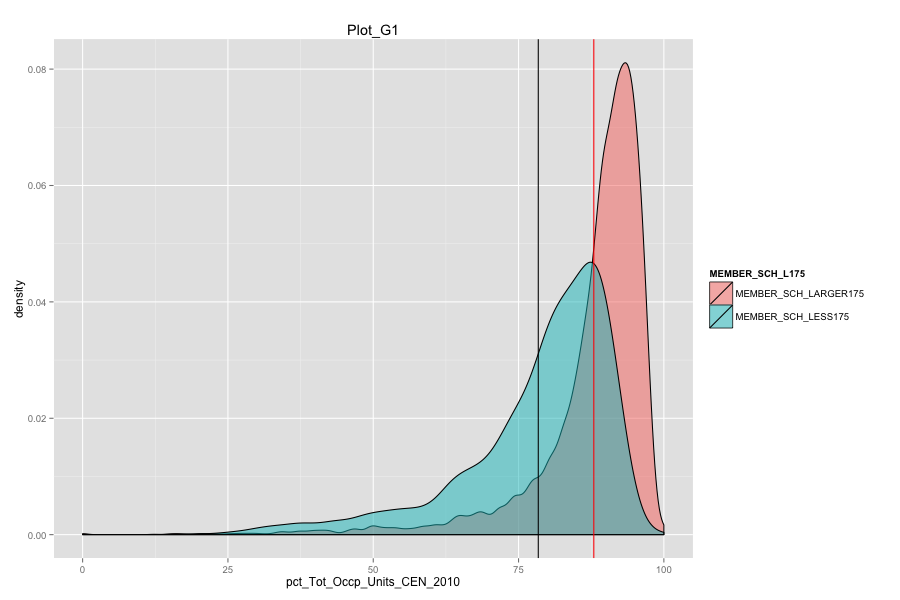
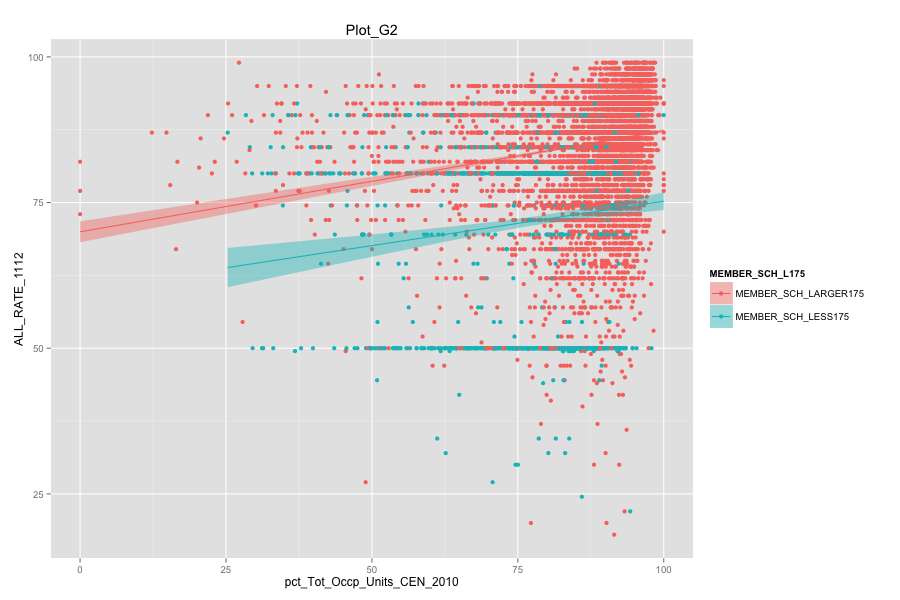
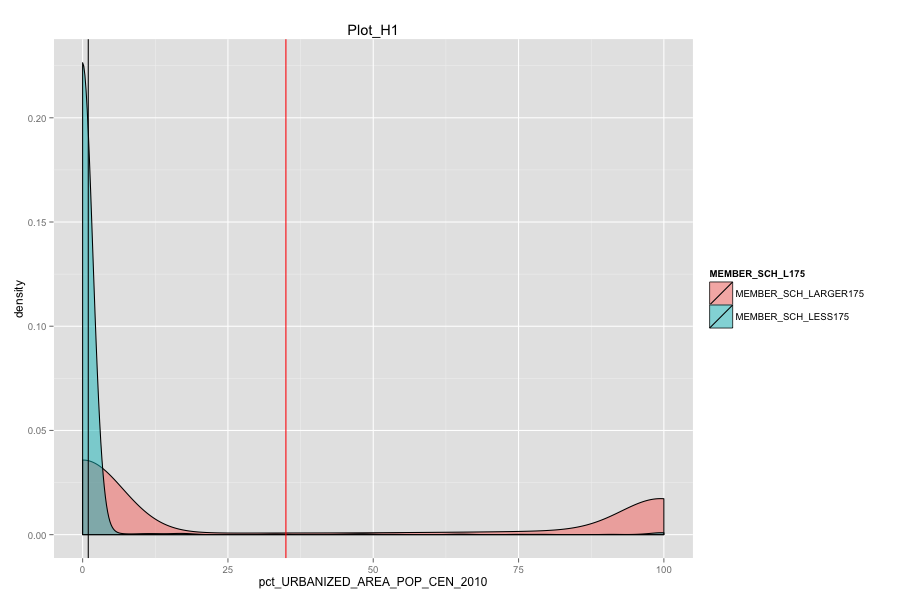
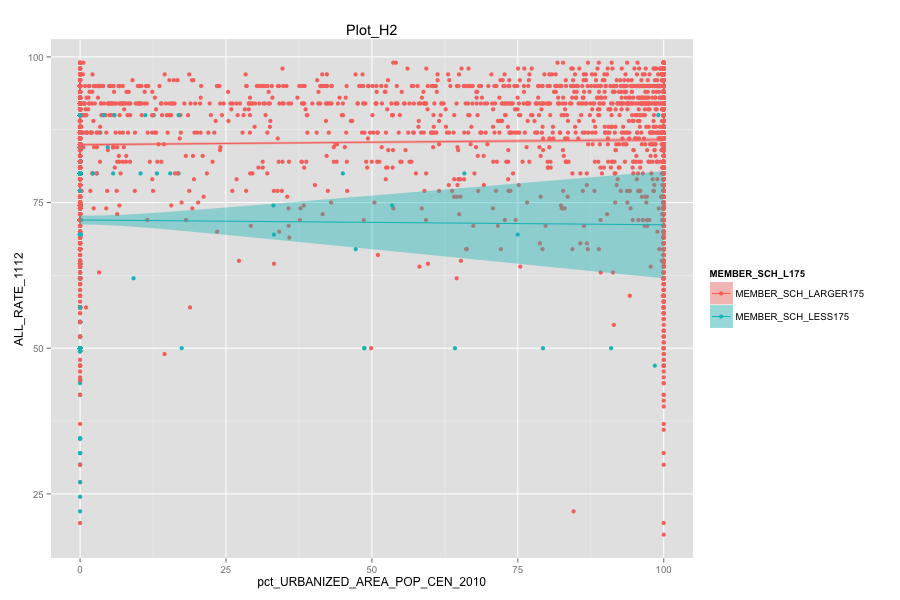
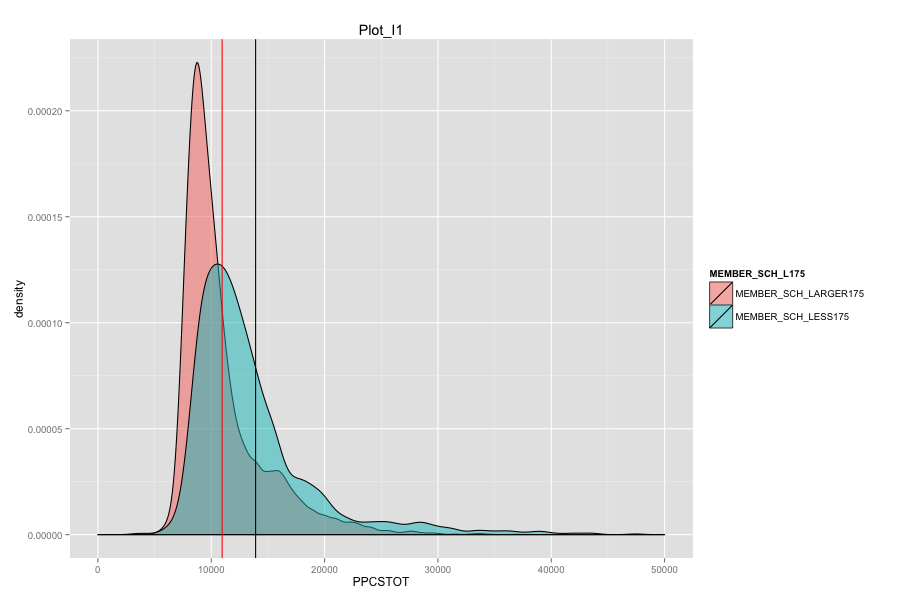
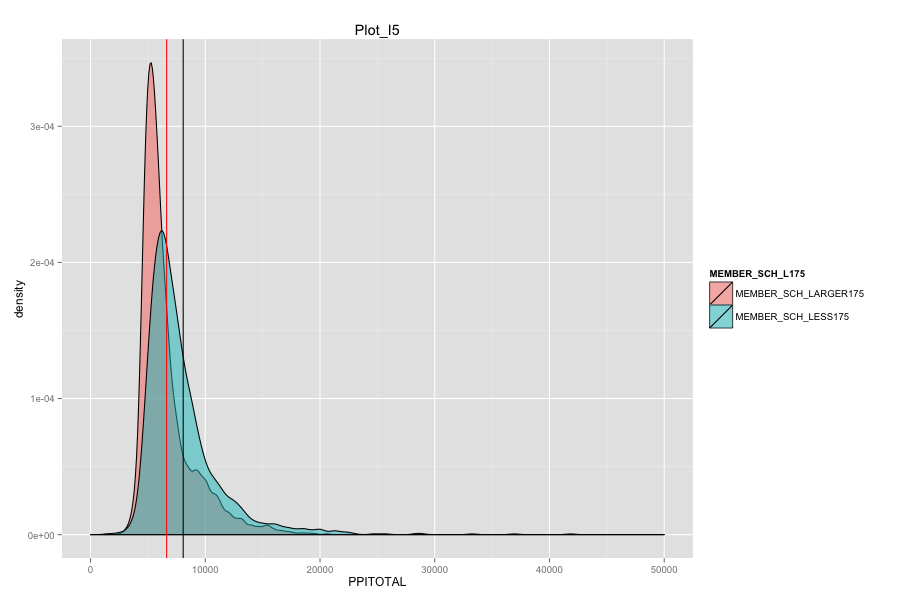
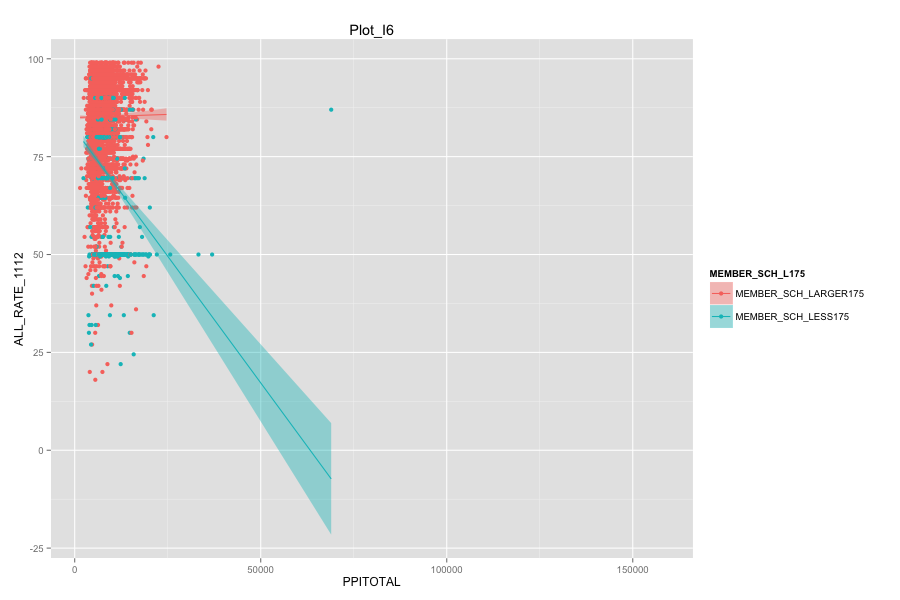
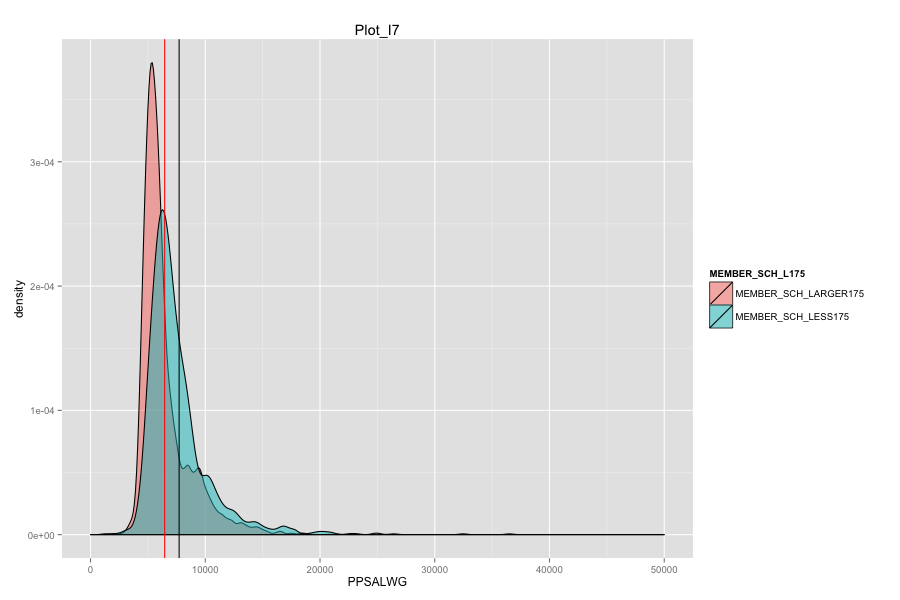
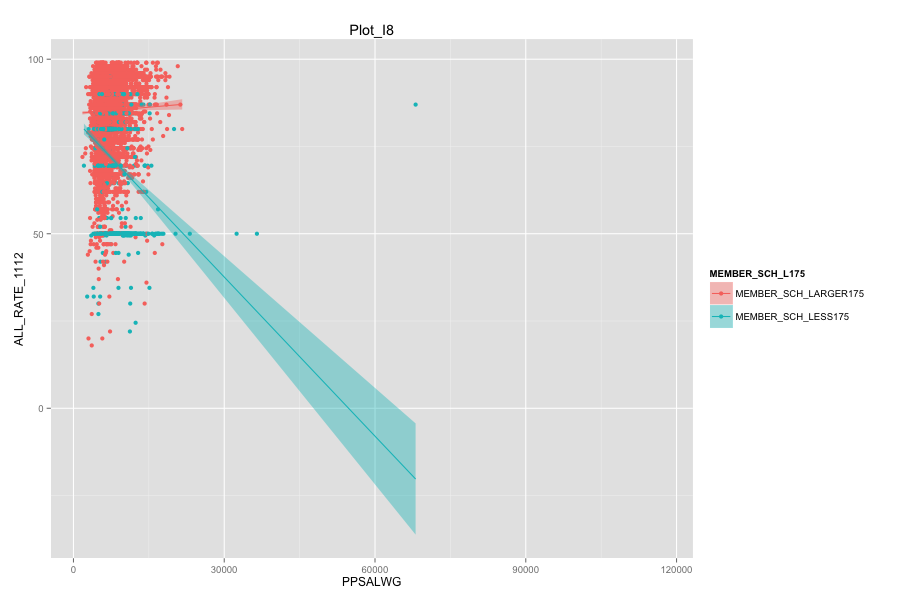
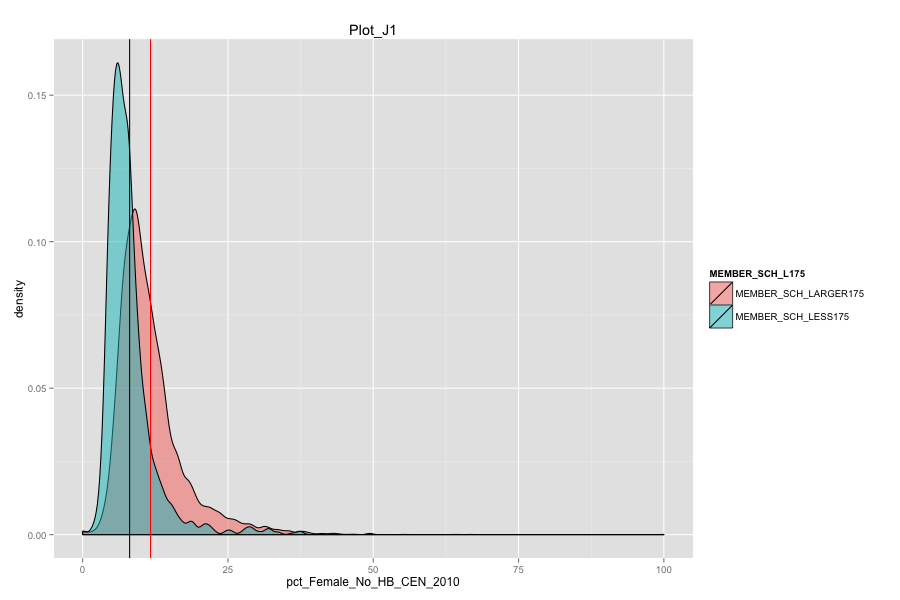
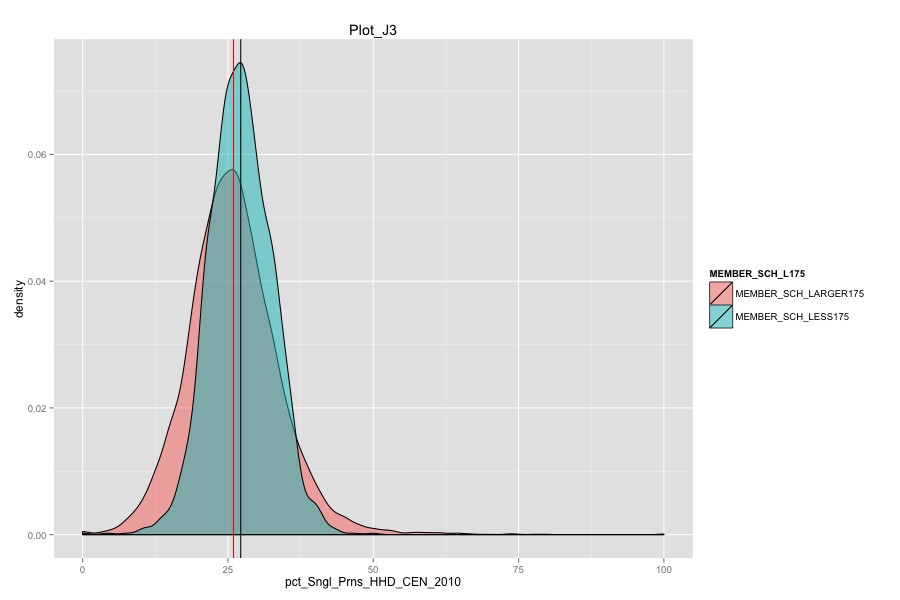
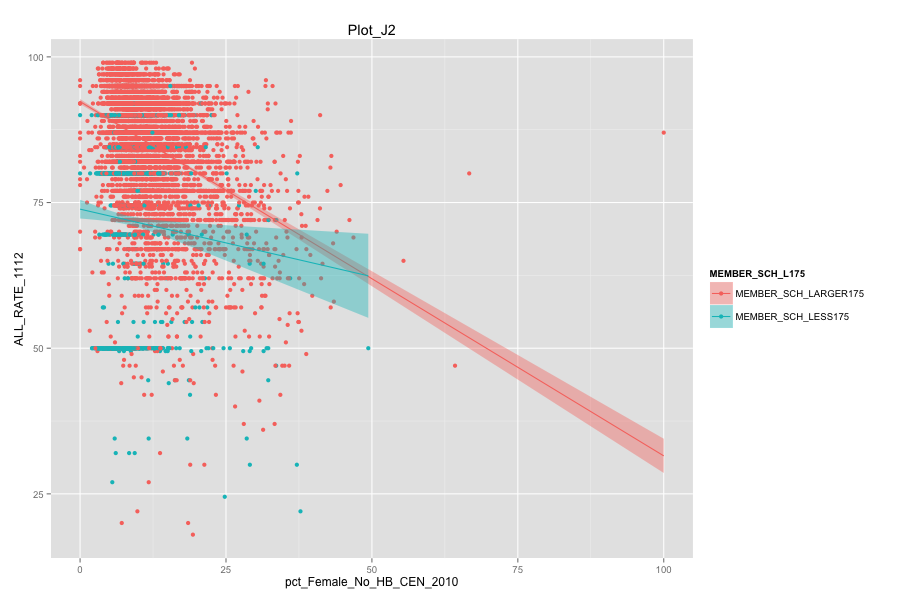
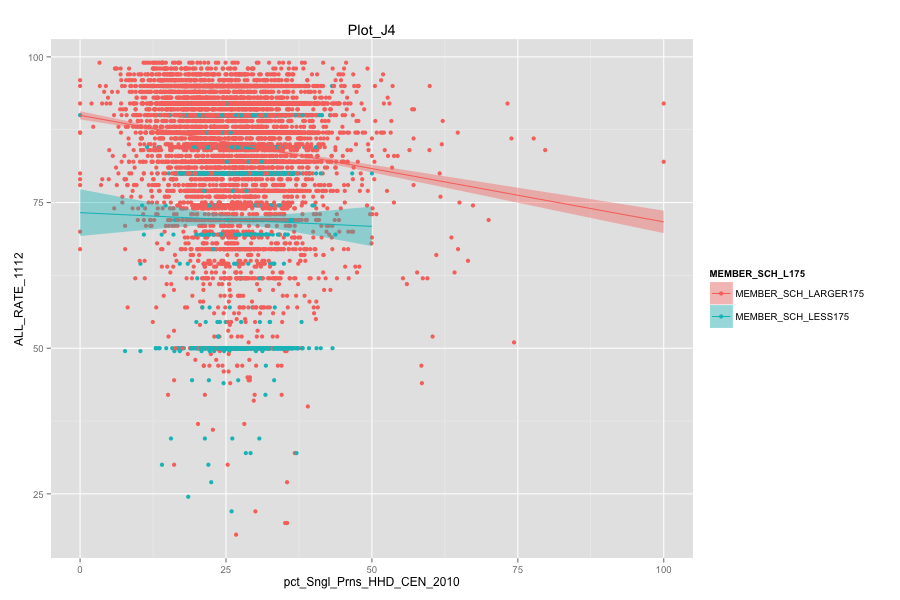
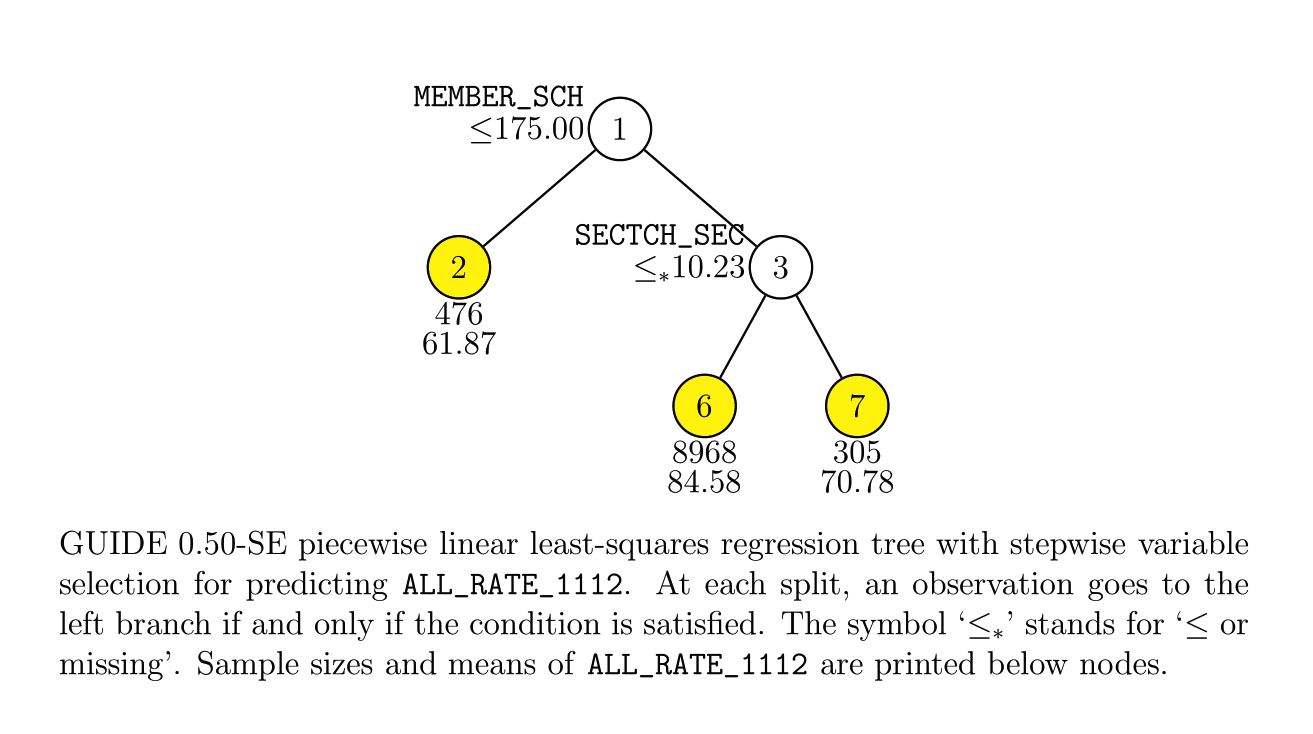
Average number of student per school is the most important, discriminated and actionable variable. When the number of Average number of student per school went up, graduation rate went up. States, which contain more than 30% education agencies whose average number of student per school less than 175 are:
Hawaii, Oregon, Alaska, North Dakota, Montana, Colorado, and South Dakota.
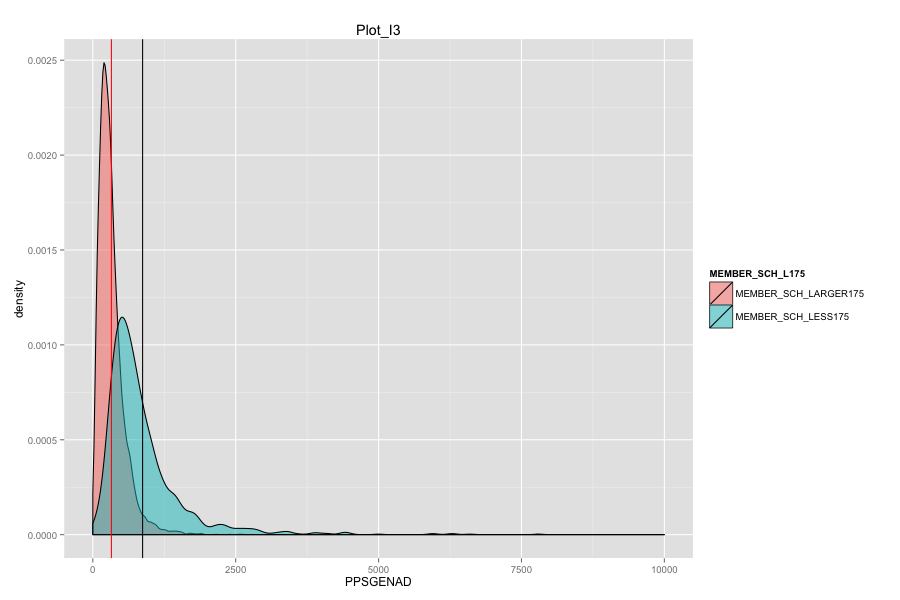
Characteristics of school agencies that have average number of student per school less than 175.
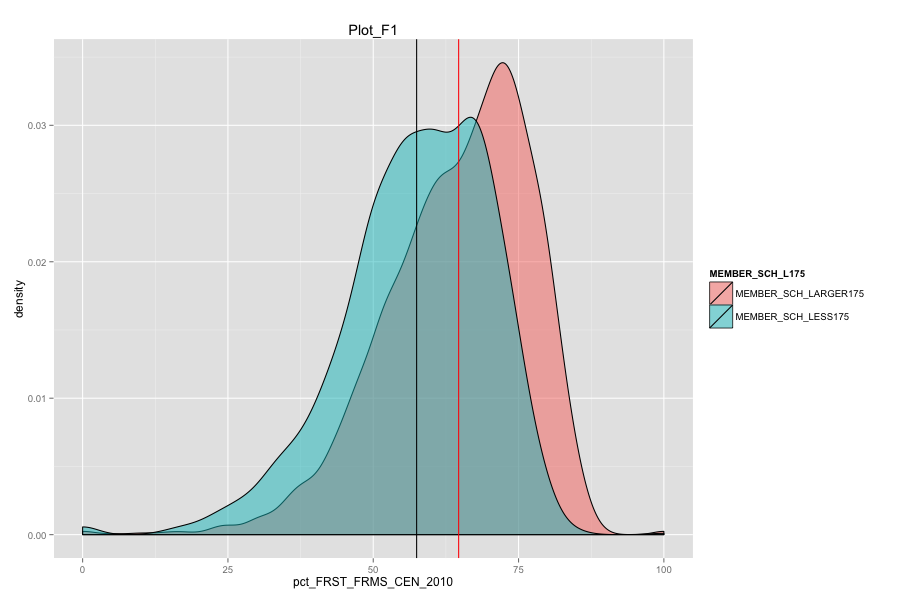
- They have relatively low percentage of "first mail was completed and returned".
- They have relatively low percentage of "housing unit that are classified as the usual place of residence of the individual or group living in it".
- Their percentage of total population that lives in a densely settled area containing 50,000 or more people are very low and is around 2%.
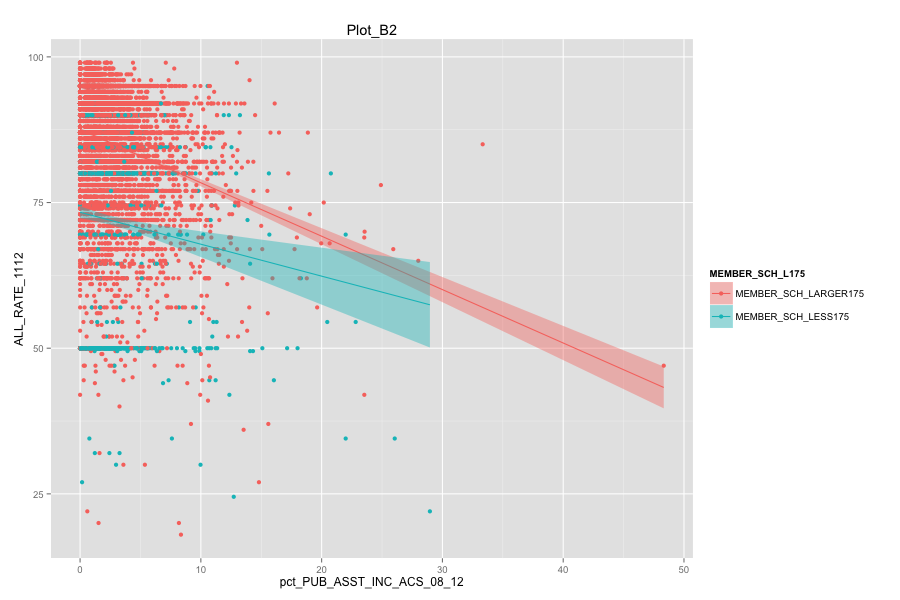
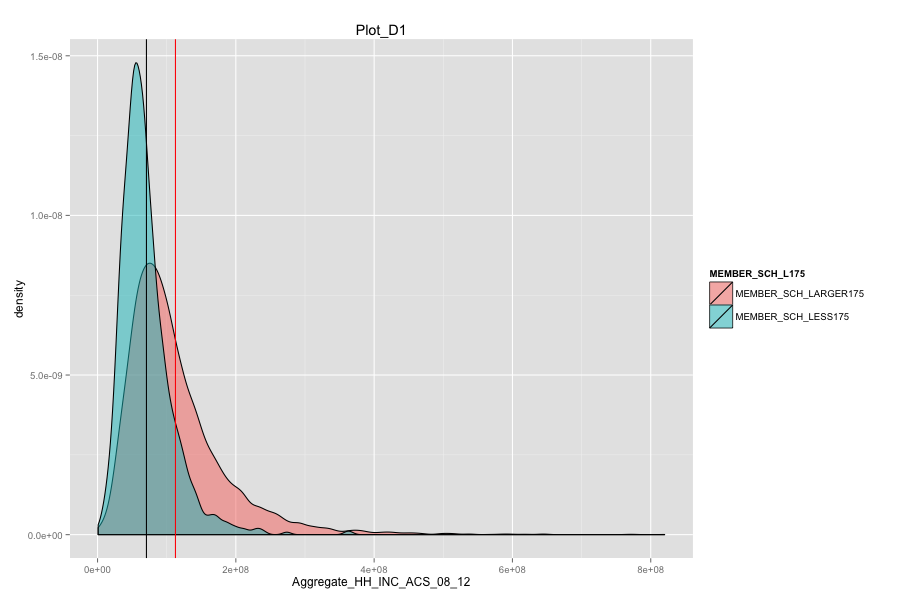
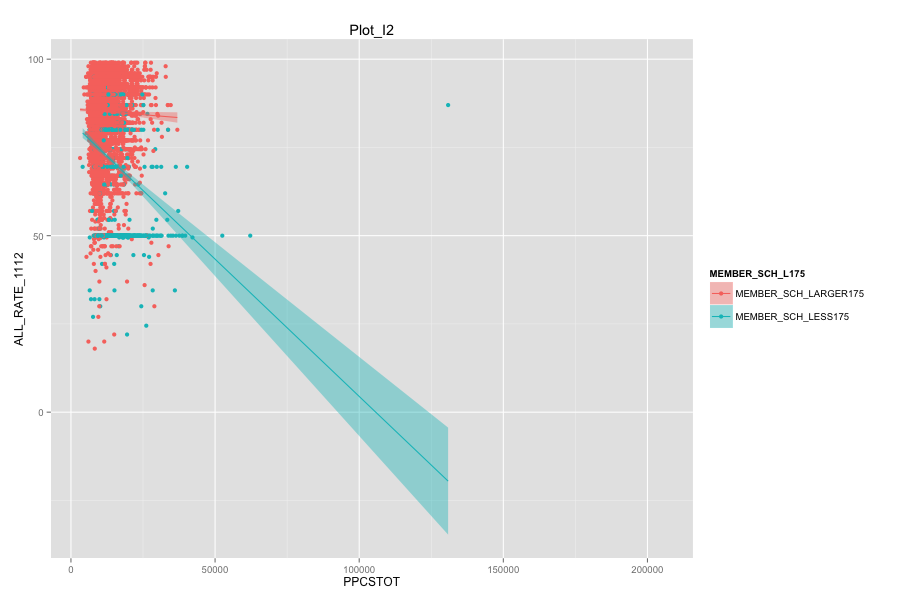
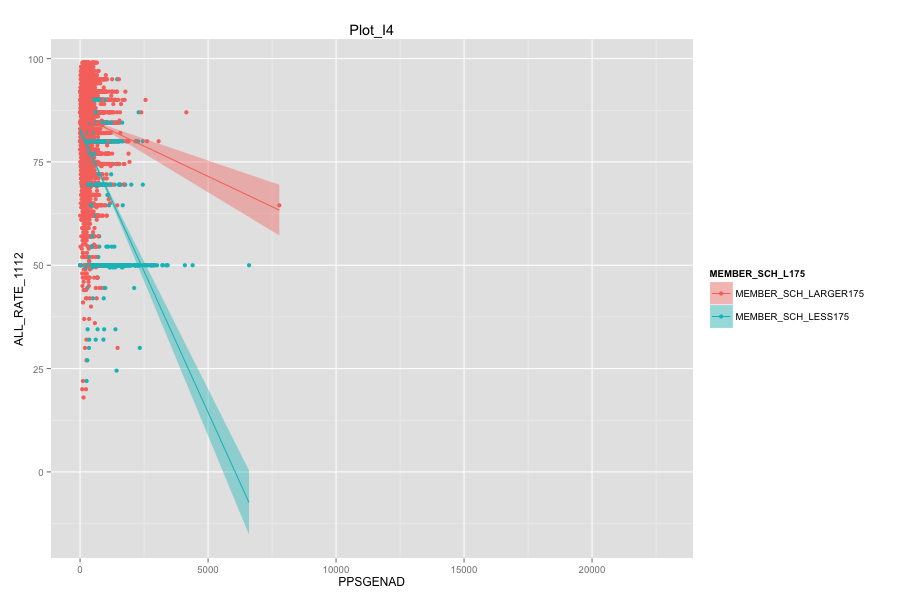
- As Total current spending per pupil increase, the graduation rate of these school agencies do not increase. Instead, graduation rate even decreased a lot. Spending more money on General administration, Instruction, Total salaries and wages are not the suitable solutions for these school agencies. And it can also mean that in order for government to achieve same education quality, government needs to spend more on these school agencies and the result-graduation rate still did not become better.
Actionable suggestions:
For whole school agencies:
Government should pay more attention to children involved in a housing unit that receive public assistant.
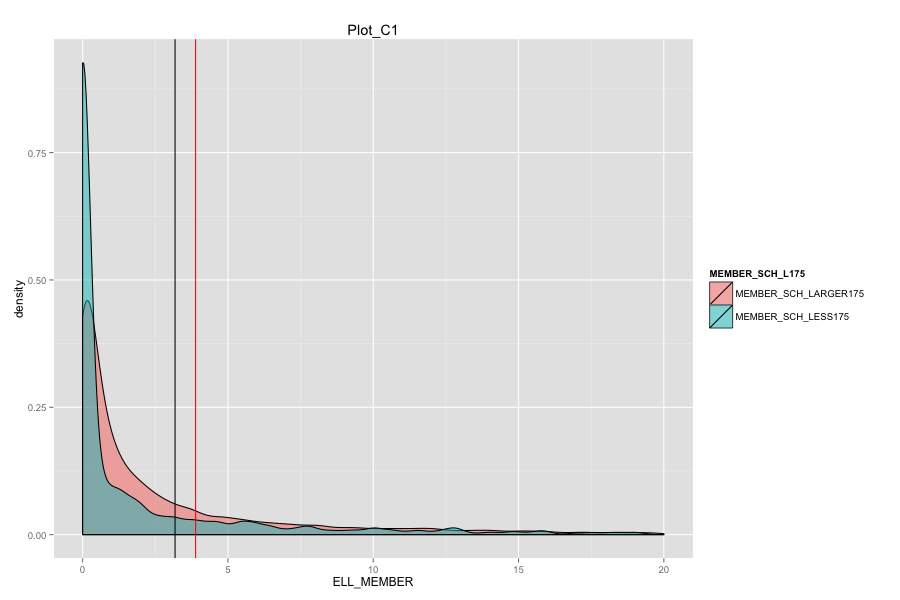
Government should pay more attention to children who are learning English.
Government should pay more attention to female living in a housing unit without husband. Figure out some methods to decrease divorce rate.
Government should pay more attention to occupied housing units where a householder lives alone.
For school agencies with average number of students per school less than 175:
Instead of using traditional educational method, government need to implement new education method specifically aim at these school agencies.
For example, can we try to replace part of the in-class education by online teaching? Since most of the housing unit of school agencies that have average number of students per school less than 175 live in rural area and are classified as unusual place of residence, children of these hosing units might cost more to go to school. Even when they arrive school, the average number of student in school is around 100,which means the number of students per grade is around 10. They do not have many opportunities to make new friends and the studying atmosphere is not good. It is not worthy to spend more effort in order to go to school.
Instead, if government can implement online education, children can have more opportunities to meet new friends online and government can connect the students from several schools in this area together so that
there is more students studying at the same time on line. Government just need to figure out a way to make this online teaching as real as possible. And besides study, school agency can arrange some weekly sports activities that request more children to join together in person.
The mean of graduation rate of school agencies with average number of students per school less than 175 is around 70%, if government can aim at these agencies and improve their graduation rate into national average graduation rate 81.4%, we have more chance to reach the 90% graduation goal by 2020.
Again, please click the link to view the comprehensive report with plots inside. Comprehensive report
References
Built With
- guide
- machine-learning
- r

Log in or sign up for Devpost to join the conversation.