-
-
agent detail
-
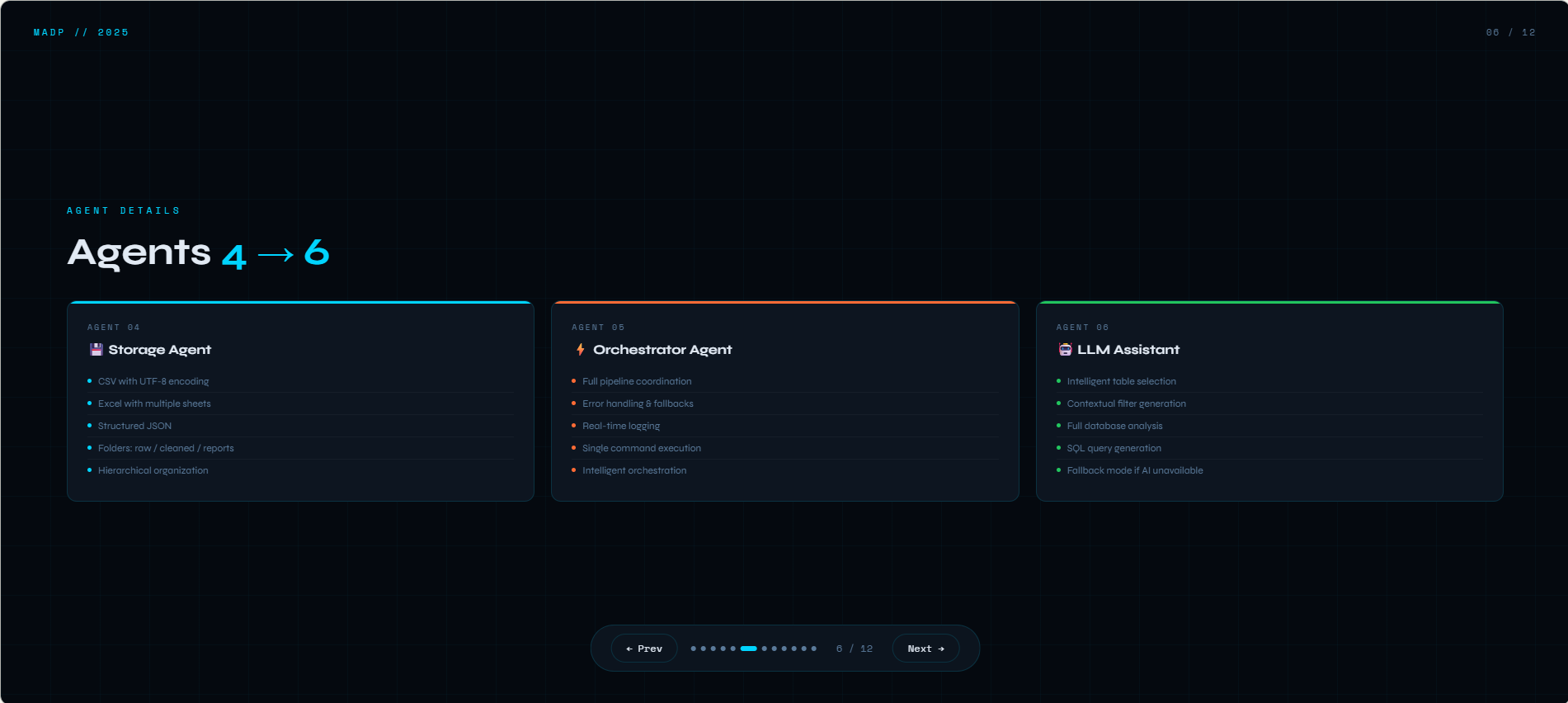
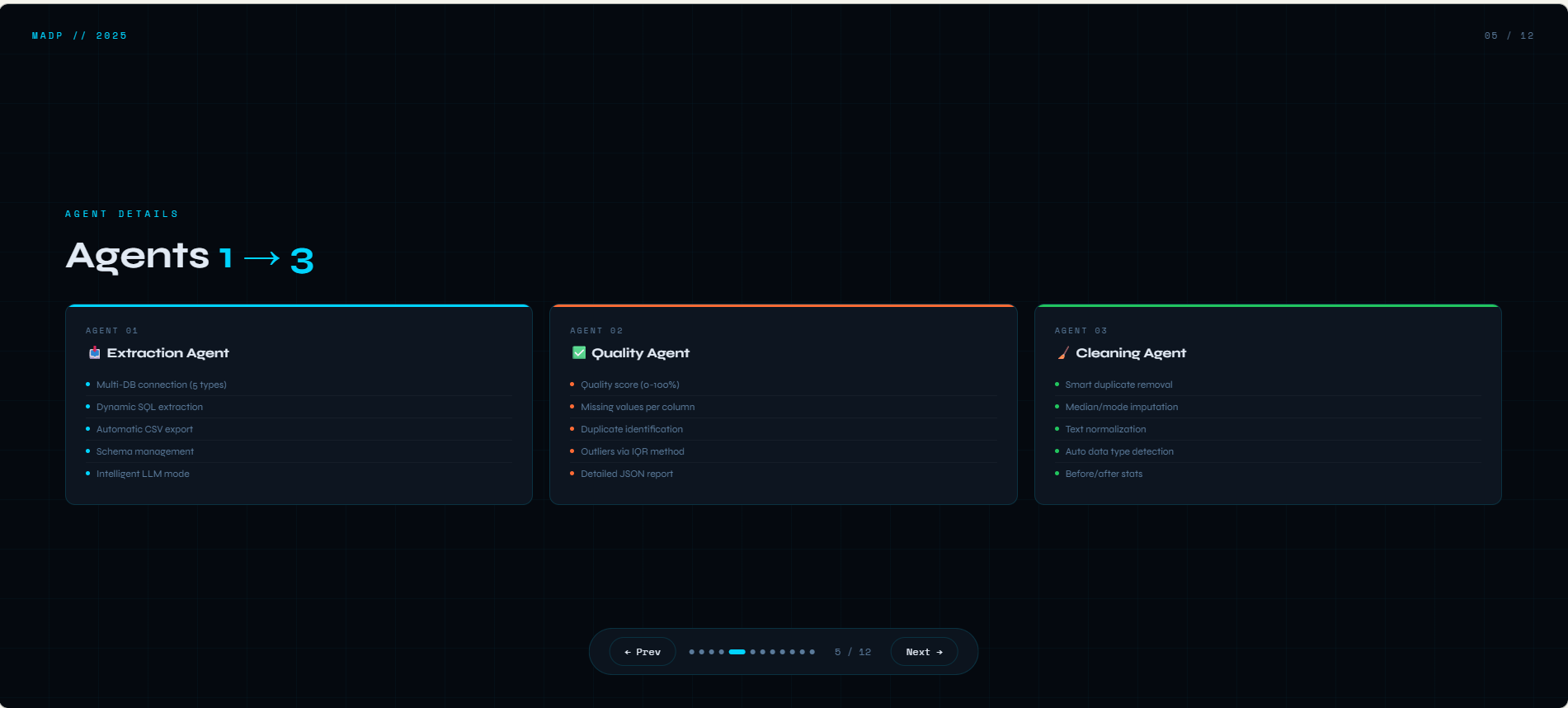
agents detail
-
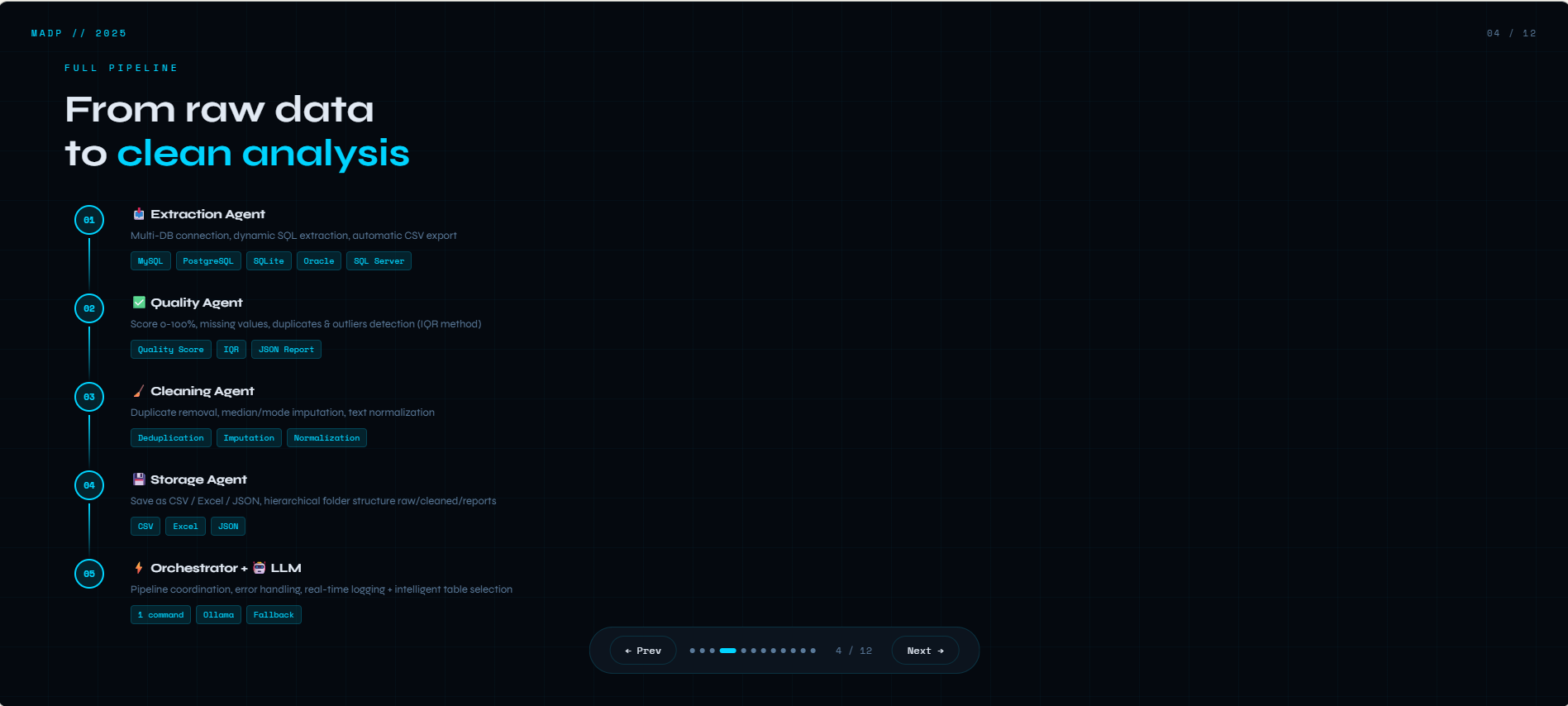
pipeline processus
-
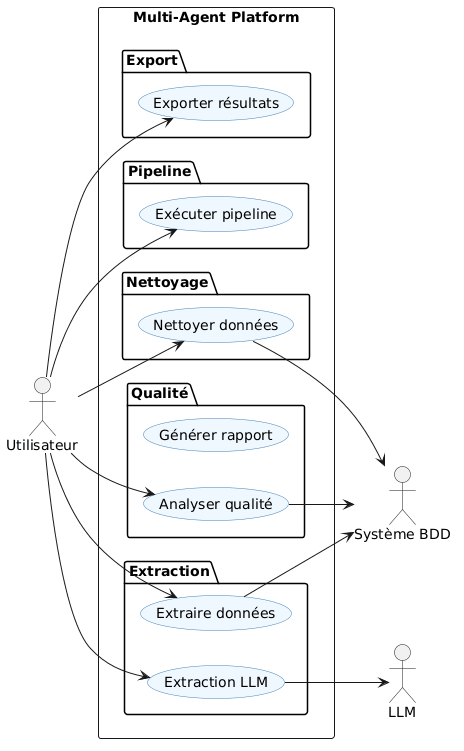
usecase
Une plateforme intelligente de traitement de données par agents spécialisés
Inspiration Tout a commencé par une statistique qui nous a profondément marqués : "Les data scientists passent 80% de leur temps à préparer les données et seulement 20% à les analyser" (Forbes). En discutant avec des analystes data dans diverses entreprises, nous avons constaté un pattern récurrent : des données sales, dupliquées, avec des valeurs manquantes, provenant de sources multiples et hétérogènes. Les processus manuels de nettoyage prenaient des jours entiers, introduisant des erreurs humaines qui faussaient les analyses et impactaient les décisions business. Nous nous sommes alors posé une question simple mais ambitieuse : "Et si on créait une équipe d'agents intelligents qui travaillent ensemble 24/7 pour automatiser tout ce processus ?" L'inspiration est venue des systèmes multi-agents en IA distribuée, où plutôt qu'un monolithe, une équipe d'agents spécialisés collabore pour former un pipeline intelligent et automatisé.
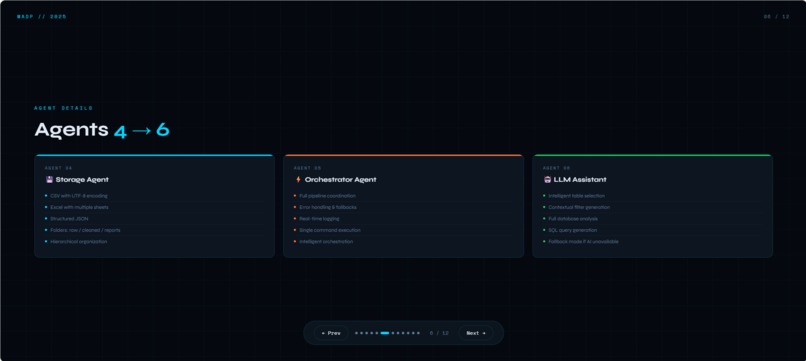
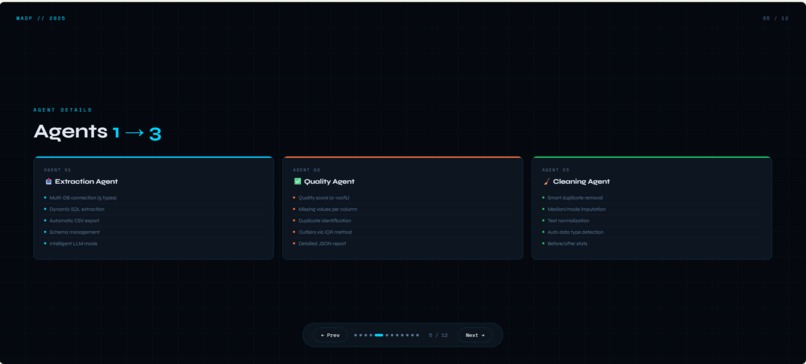
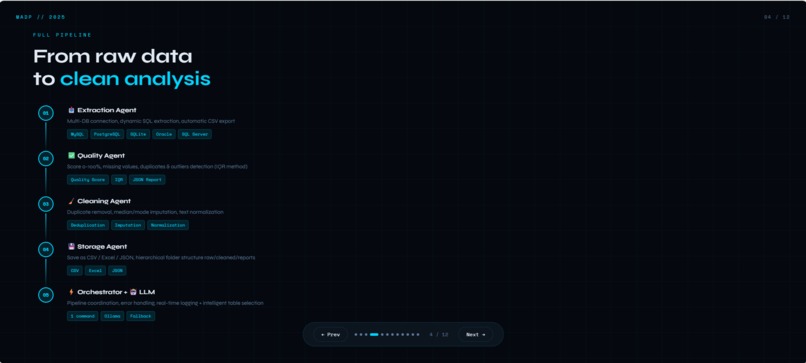
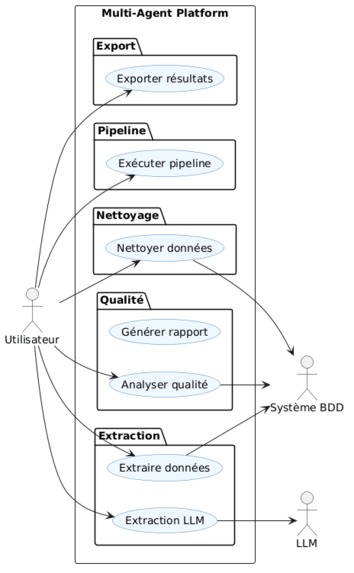
What it does? Multi-Agent Data Platform est une solution complète qui automatise le traitement des données grâce à 6 agents spécialisés travaillant en synergie. L'ExtractionAgent se connecte à multiples bases de données (MySQL, PostgreSQL, SQLite, Oracle, SQL Server) pour récupérer les données brutes. Le QualityAgent analyse ensuite la qualité en calculant un score de 0 à 100%, en détectant les doublons, les valeurs manquantes et les outliers via la méthode IQR. Le CleaningAgent prend le relais pour supprimer les doublons, imputer les valeurs manquantes de manière intelligente (médiane pour les numériques, mode pour le texte) et normaliser les données textuelles. Le StorageAgent sauvegarde les résultats aux formats CSV, Excel et JSON, en organisant proprement les dossiers raw, cleaned et reports. L'OrchestratorAgent coordonne l'ensemble du pipeline, gère les erreurs et assure une traçabilité complète via des logs détaillés. Enfin, le LLMAssistant (basé sur Ollama) apporte une couche d'intelligence en sélectionnant automatiquement les tables pertinentes, en générant des filtres contextuels et en analysant la base de données selon les besoins de l'utilisateur. Le tout est accessible via une interface web intuitive développée avec Django, offrant un dashboard en temps réel, des pages dédiées pour chaque agent, et un pipeline exécutable en un seul clic.
How we built it? La plateforme a été construite avec une architecture modulaire et extensible. Le backend est développé en Python avec Django 4.2, offrant à la fois l'API REST et le rendu des templates. Pour la manipulation des données, nous utilisons Pandas et NumPy, tandis que SQLAlchemy assure les connexions uniformisées aux 5 types de bases de données supportées. L'intelligence artificielle est intégrée via LangChain pour l'orchestration des prompts et Ollama comme serveur LLM local exécutant LLaMA2, garantissant que toutes les données restent privées et jamais envoyées sur Internet. Le frontend utilise HTML5, CSS3 et JavaScript vanilla pour une interface responsive et des interactions dynamiques sans dépendances lourdes. La structure du projet suit une organisation claire : un dossier agents/ contenant chaque agent spécialisé, un dossier web/ pour l'application Django avec ses templates, un dossier data/ pour le stockage hiérarchisé des fichiers, et un système de logging complet dans logs/. Chaque agent a été développé de manière indépendante avec des interfaces bien définies, permettant une intégration facile et des tests unitaires ciblés. L'orchestrateur coordonne le flux en appelant séquentiellement les agents tout en gérant les erreurs et en assurant des fallbacks élégants quand une étape échoue.
Challenges we ran into? Le premier défi majeur a été la gestion des types de données hétérogènes. Nous avons rencontré de nombreuses erreurs comme Cannot perform reduction 'median' with string dtype lorsque l'agent de nettoyage tentait d'appliquer des opérations numériques à des colonnes textuelles. La solution a été d'implémenter une détection intelligente des types avec pd.api.types.is_numeric_dtype() et de traiter chaque colonne selon sa nature : médiane pour les numériques, mode pour le texte, valeurs par défaut pour les autres cas.
Le deuxième défi, et non des moindres, a été la sérialisation JSON. Nous étions constamment confrontés à l'erreur Unexpected token 'N' in JSON à cause des valeurs NaN présentes dans les DataFrames. Nous avons dû développer une fonction récursive clean_for_json() qui convertit récursivement tous les types numpy et pandas en types Python natifs, remplaçant les NaN par None (qui devient null en JSON), et gérant les cas particuliers comme les infinities et les dates.
L'intégration du LLM avec Ollama a également présenté des défis, notamment la gestion des cas où Ollama n'est pas installé ou ne répond pas. Nous avons implémenté un système de fallback intelligent qui, en cas d'échec du LLM, sélectionne automatiquement les 3 premières tables ou utilise des filtres par défaut, garantissant que la plateforme reste fonctionnelle même sans IA.
Enfin, les performances avec de grands volumes de données nous ont obligés à optimiser le code. Nous avons implémenté la lecture par chunks pour les fichiers CSV dépassant le million de lignes, et optimisé les opérations Pandas pour minimiser l'utilisation mémoire tout en maintenant des temps de réponse acceptables.
Accomplishments that we're proud of Nous sommes particulièrement fiers d'avoir réussi à créer un pipeline complet exécutable en un seul clic, réduisant de 80% le temps de traitement des données. Là où un analyste passait des heures à nettoyer manuellement un fichier de 100 000 lignes, notre plateforme accomplit la même tâche en moins de 3 secondes. L'intégration réussie d'un LLM local avec fallback intelligent est une autre source de fierté, permettant à la plateforme de prendre des décisions contextuelles tout en restant fonctionnelle même hors ligne. La qualité du code et de l'architecture, avec des agents modulaires et testables, nous permet d'envisager sereinement les évolutions futures. L'interface utilisateur intuitive, développée sans frameworks JavaScript lourds, démontre qu'on peut créer une expérience utilisateur riche avec des technologies simples. Enfin, la couverture de 5 types de bases de données et 3 formats d'export fait de notre solution un outil véritablement polyvalent, adaptable à la plupart des environnements professionnels.
What we learned Ce projet nous a appris l'importance cruciale de la gestion des cas particuliers en traitement de données. Chaque type de donnée, chaque format, chaque source apporte son lot d'exceptions qu'il faut anticiper et traiter gracieusement. Nous avons approfondi notre compréhension des subtilités de Pandas et des conversions de types, découvrant des fonctions comme pd.api.types.is_numeric_dtype() qui sont devenues essentielles. L'intégration d'un LLM nous a enseigné la valeur des fallbacks : l'IA est puissante mais doit toujours avoir un plan B. Nous avons également renforcé nos compétences en architecture logicielle, en concevant des agents avec des responsabilités claires et des interfaces bien définies. La gestion des erreurs et le logging se sont révélés cruciaux pour le debugging et la maintenance. Enfin, nous avons compris que l'expérience utilisateur est aussi importante que la puissance technique : une interface intuitive transforme un outil complexe en solution accessible.
What's next for Multi-Agent Data Quality L'avenir de la plateforme est riche en perspectives. À court terme, nous prévoyons d'ajouter le support de MongoDB pour couvrir les bases NoSQL, d'intégrer des modèles LLM supplémentaires comme GPT4All, et d'enrichir les visualisations avec Chart.js pour des graphiques plus parlants. Nous travaillons également sur l'export PDF des rapports qualité pour faciliter leur partage. À moyen terme, nous voulons exposer une API REST complète pour permettre l'intégration avec d'autres outils, ajouter un système d'authentification avec rôles utilisateurs, et implémenter la planification automatique des pipelines via cron. Enfin, à long terme, nous envisageons un déploiement cloud (AWS/Azure/GCP) pour passer à l'échelle, l'ajout de versioning des données avec DVC, un dashboard temps réel utilisant WebSockets, et pourquoi pas de l'autoML pour recommander automatiquement les stratégies de nettoyage les plus adaptées à chaque jeu de données.
Built With
- css
- django
- html5
- javascript
- json
- langchain-ollama
- numpy
- pandas
- python
- sqlalchemy

Log in or sign up for Devpost to join the conversation.