-
-
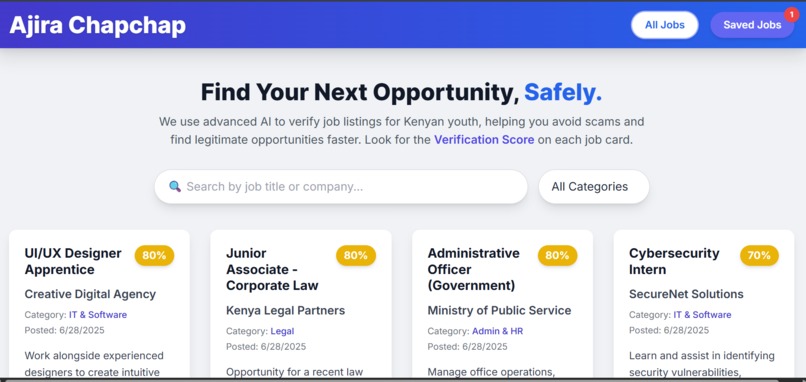
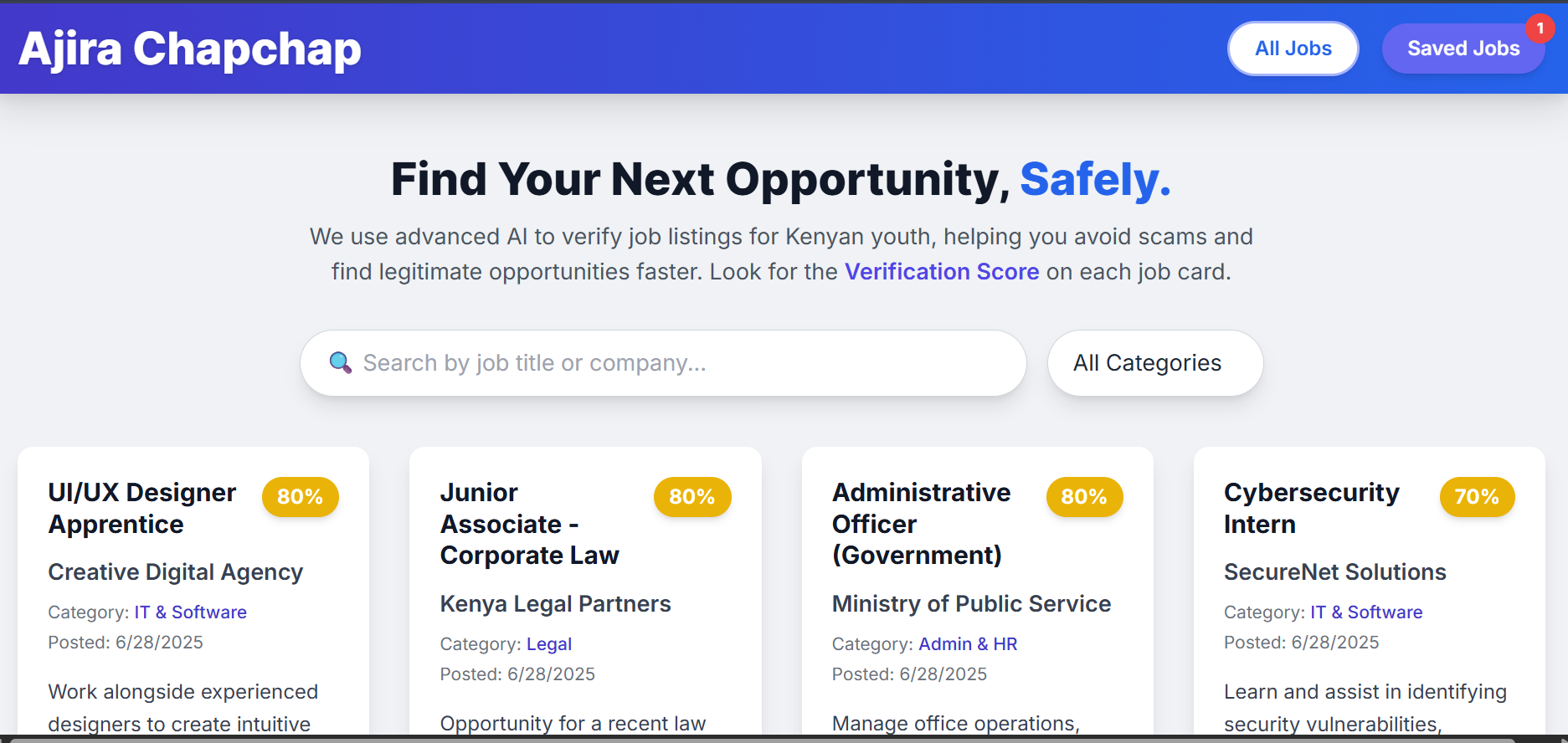
Landing Page
Inspiration
The inspiration for Ajira Chapchap stemmed from a critical observation of the job market for young people in Kenya. While there's a significant demand for entry-level talent, the online landscape is unfortunately riddled with fraudulent job postings and scams. These scams not only waste job seekers' time and resources but can also lead to financial exploitation. I envisioned a platform that could cut through the noise, providing a trusted and efficient way for Kenyan youth to find legitimate opportunities, empowering them to build their careers safely.
How We Built It
I adopted a serverless-first approach on AWS to ensure scalability, cost-efficiency, and minimal operational overhead. The core of our solution revolves around three interconnected AWS Lambda functions, orchestrating the entire job verification pipeline:
- Data Acquisition: I initially explored web scraping live job boards using Python's
requestsandBeautifulSoup. While challenging due to anti-bot measures, this phase taught us the intricacies of HTML parsing and polite scraping practices. For a robust demonstration, I pivoted to using a rich, pre-curated sample dataset within ourscrapeJobsFunction. - AI-Powered Analysis: This is where the magic happens. I integrated Amazon Bedrock and its Titan Text Express Foundation Model. By crafting precise prompts, we trained the model to perform complex tasks: summarizing job descriptions, assessing legitimacy (assigning a
verificationScoreandflags), and categorizing jobs into relevant industry sectors. This AI layer is crucial for transforming raw, unstructured data into valuable, actionable insights. - Data Persistence & Delivery: Processed job data is stored in Amazon DynamoDB, a high-performance NoSQL database. This data is then exposed via Amazon API Gateway, which triggers another Lambda function to serve the jobs to our frontend.
- User Interface: The frontend is a responsive Single-Page Application built with HTML, Tailwind CSS, and JavaScript, hosted on Amazon S3. It provides a clean interface for users to browse, search, filter, and save jobs.
What I Learned
Building Ajira Chapchap was an invaluable learning experience:
- Serverless Architecture: Deepened our understanding of AWS Lambda, S3, DynamoDB, API Gateway, and EventBridge, and how they seamlessly integrate to form a powerful, event-driven system.
- Prompt Engineering: Gained hands-on experience in crafting effective prompts for Large Language Models (LLMs) on Amazon Bedrock to achieve specific, structured outputs (JSON formatting, categorization, sentiment analysis).
- Web Scraping Challenges: Understood the complexities and ethical considerations of web scraping, including handling anti-bot measures and adapting to dynamic website structures.
- Data Pipeline Design: Learned to design a robust data pipeline that handles data ingestion, processing, storage, and delivery in an automated and scalable manner.
- UI/UX for Data: Focused on presenting complex AI-generated data (like verification scores and flags) in an easily digestible and trustworthy manner on the frontend.
Challenges Faced
Our journey wasn't without its hurdles:
- Web Scraping Robustness: Reliably scraping dynamic job boards proved challenging due to frequent HTML changes and aggressive anti-bot mechanisms (e.g.,
403 Forbiddenerrors from Indeed.com). This led us to implement a robust fallback to sample data for consistent demonstration. - LLM Consistency: Ensuring the Amazon Titan Text Express model consistently returned perfectly formatted JSON and adhered strictly to the predefined category list required iterative prompt refinement. Sometimes, the model would omit keys or provide slightly off-list categories, necessitating careful parsing and default handling.
- Lambda Timeouts: Initial Bedrock API calls within Lambda functions sometimes exceeded default timeouts, requiring us to carefully monitor logs and adjust Lambda configurations.
- Frontend-Backend Integration: Ensuring seamless data flow from DynamoDB through API Gateway to the frontend, including client-side filtering and state management, required meticulous debugging and testing.
Despite these challenges, overcoming them provided immense satisfaction and solidified our understanding of building intelligent, scalable cloud applications.
Built With
- amazon-api-gateway
- amazon-bedrock
- amazon-cloudfront-cdn
- amazon-cloudwatch
- amazon-dynamodb
- amazon-eventbridge
- amazon-lambda
- amazon-web-services
- aws-iam
- beautiful-soup
- boto3
- chart.js
- git
- github
- html5
- javascript
- python
- requests
- rest-api
- tailwind-css

Log in or sign up for Devpost to join the conversation.