-
-
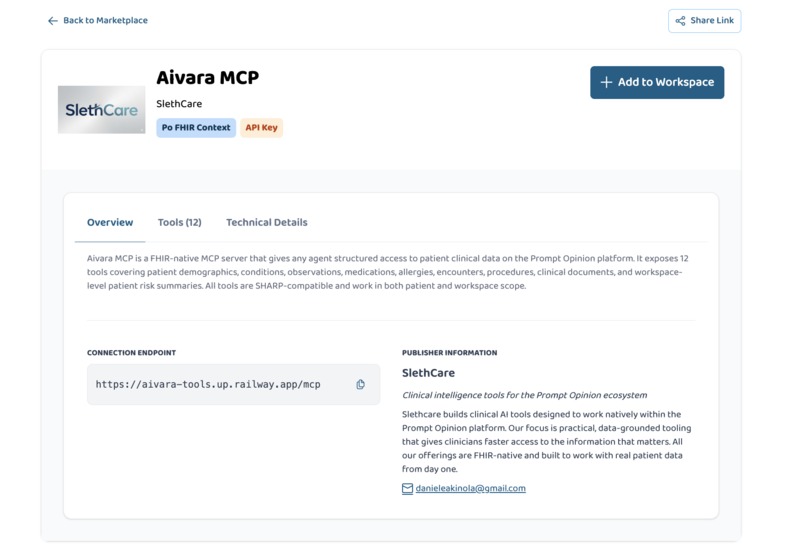
Marketplace listing
-
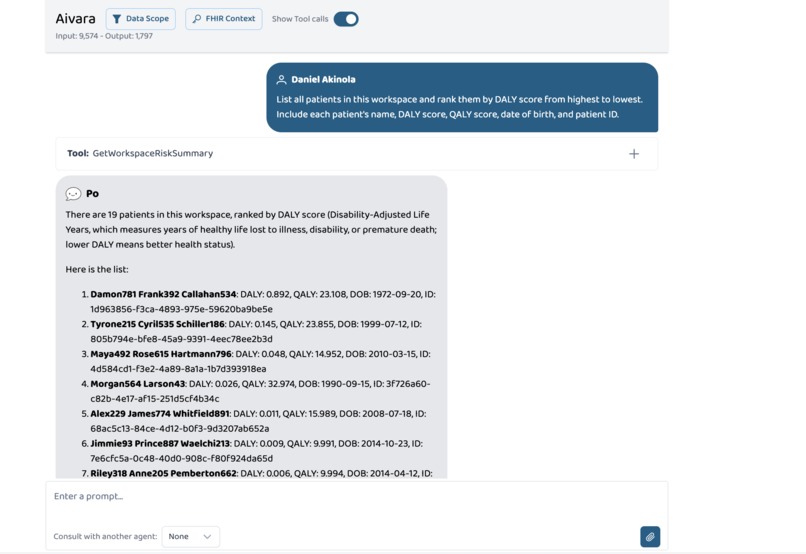
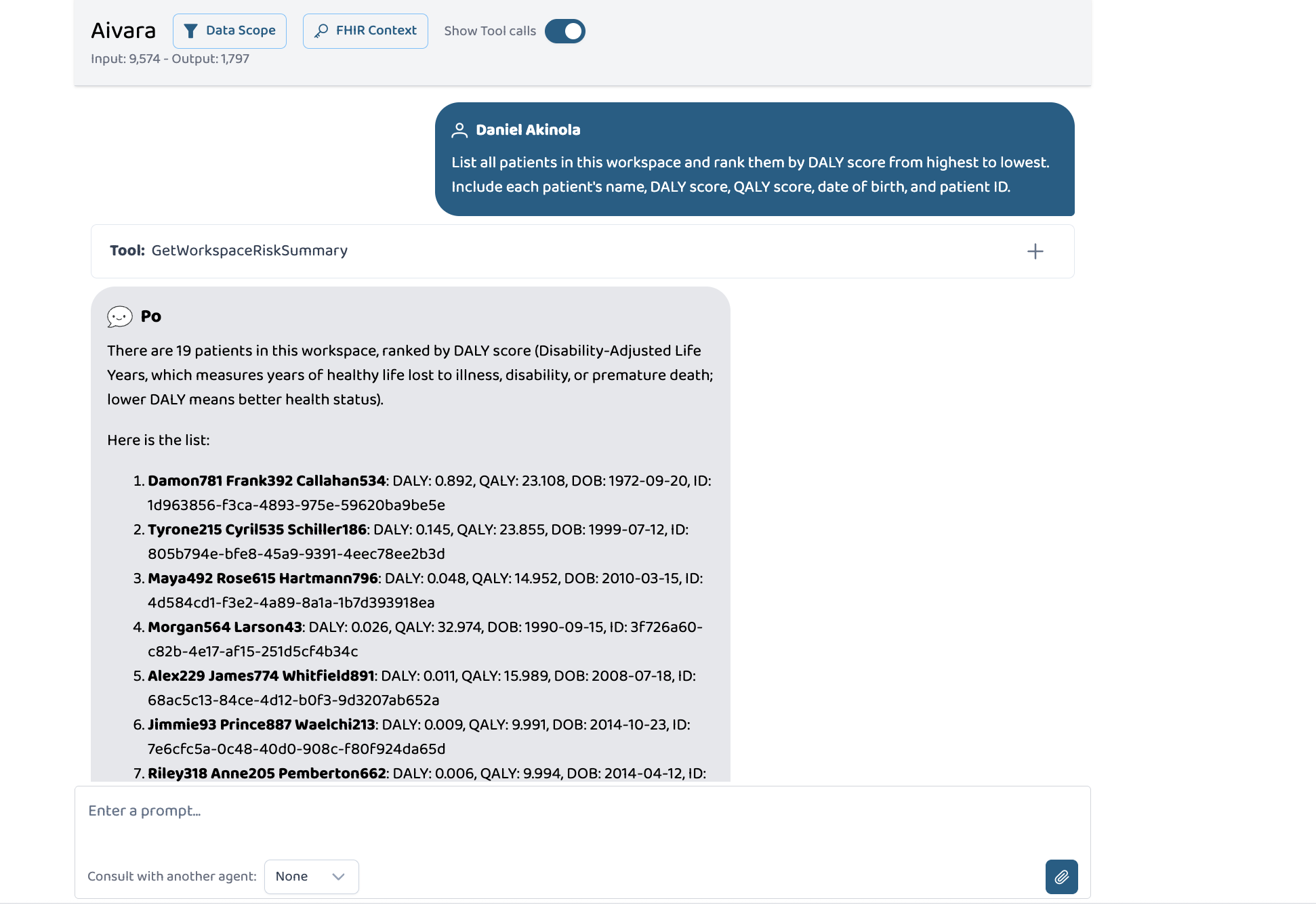
GetWorkspaceRiskSummary tool call in the chat
Inspiration
Every clinical agent needs data before it can reason. But getting that data from a FHIR server correctly and safely is plumbing work that nobody wants to do twice. I built Aivara MCP to be that layer once, and make it available to any agent on the platform.
What it does
Aivara MCP gives any agent on Prompt Opinion structured access to patient clinical data through 12 composable tools. It covers demographics, conditions, observations, medications, encounters, procedures, clinical notes, and workspace-level patient risk summaries. One connection, everything you need.
How we built it
Built with FastMCP in Python and deployed to a web server. Each tool is a thin FHIR query that returns clean structured data. Patient credentials come from the SHARP context at runtime, so the server stays stateless and safe across any patient or workspace.
Challenges we ran into
Working with FHIR data required a lot of attention to detail. Observation values come in different shapes depending on the type, blood pressure returns as components, document content is base64 encoded inline, and DALY scores live inside extension arrays rather than top-level fields. Every tool had to handle these variations correctly or the agent would receive bad data and reason from it.
Accomplishments that we're proud of
One tool call ranks every patient in the workspace by disease burden in under 15 seconds. The same 12 tools that surface a routine chronic disease review for one patient surface compound safeguarding risk and a three-year care gap for another, with no configuration changes.
What we learned
I learned early on not to put reasoning inside the tools. Every time a tool did more than just fetch and return data, it created problems the agent could not see or correct. Keeping tools focused on retrieval and leaving all interpretation to the agent made the whole system more reliable and much easier to debug.
What's next for Aivara MCP: FHIR Clinical Data Tools for Healthcare Agents
More testing against real patient workspaces outside of Prompt Opinion to make the tools more reliable across different data shapes. Better error handling so tools fail clearly rather than silently. And potentially more tools as the complexity of real patient data reveals gaps in what the current 12 cover.
Built With
- fastmcp
- python
- streamablehttp

Log in or sign up for Devpost to join the conversation.