-
-

Header
-
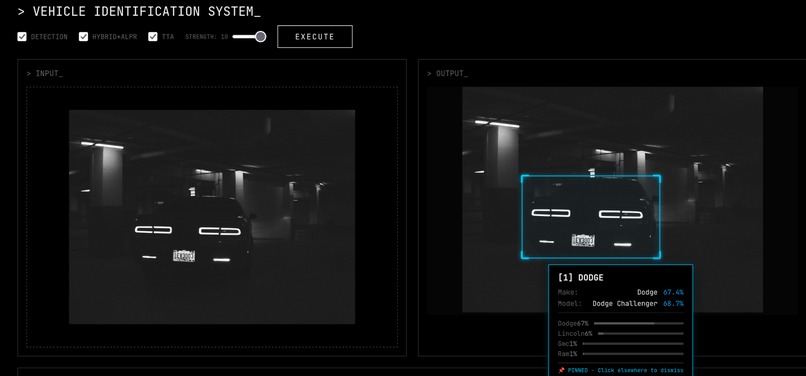
Dark Lighting
-
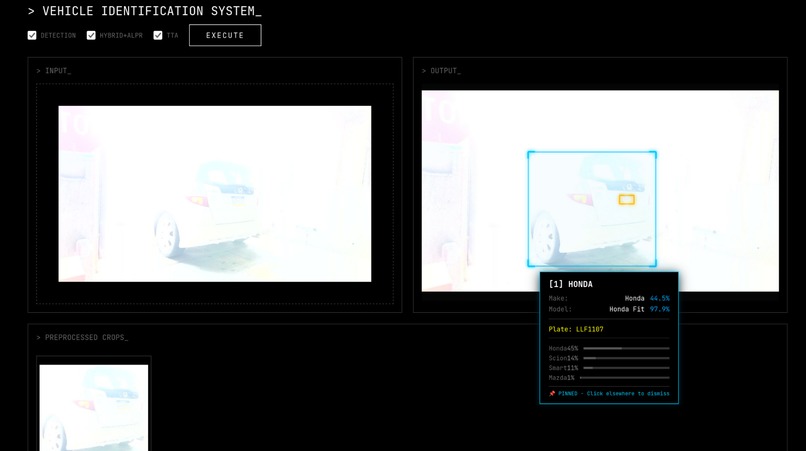
Bright Lighting
-
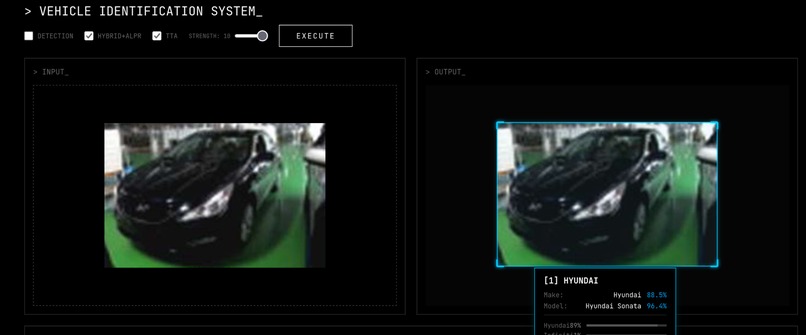
Blur
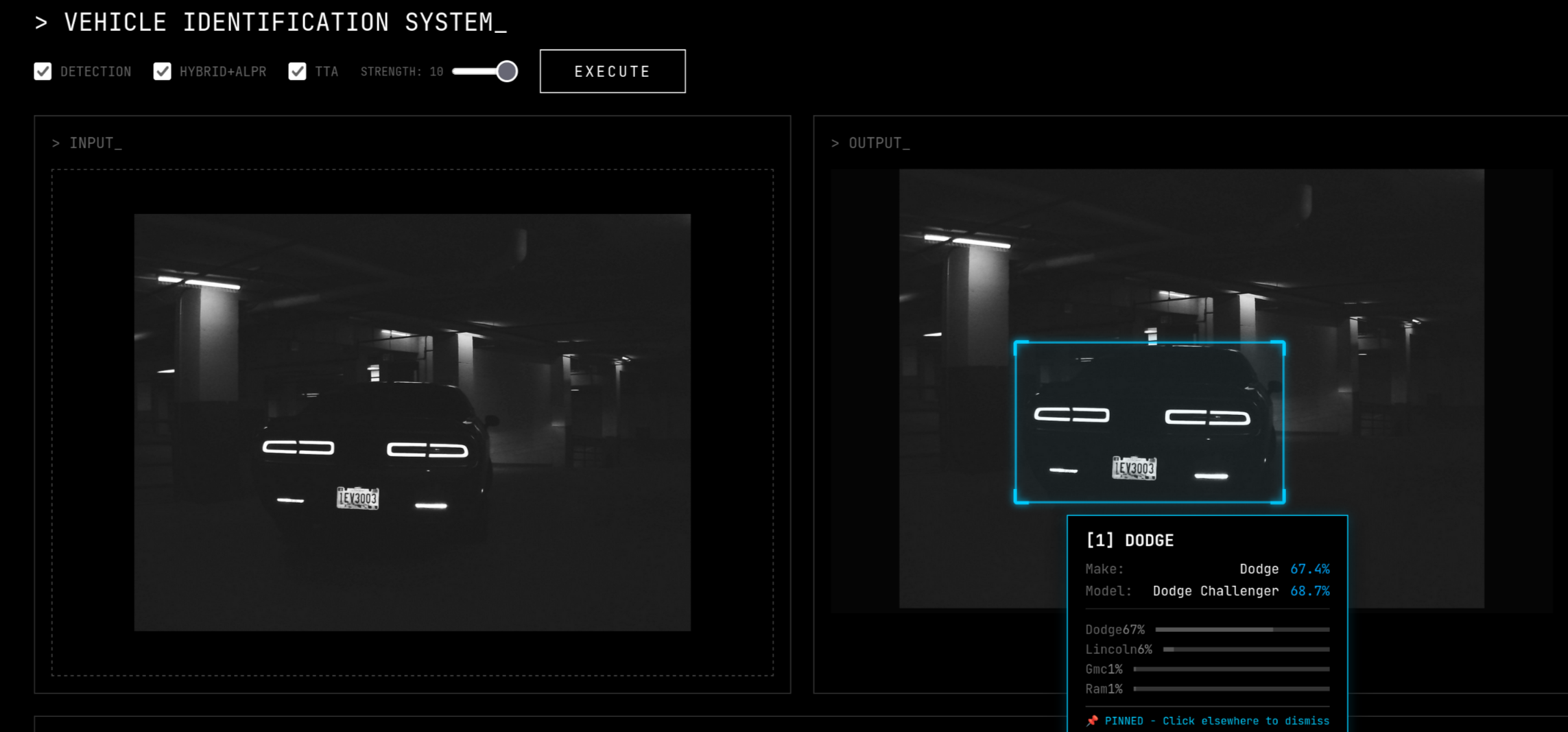
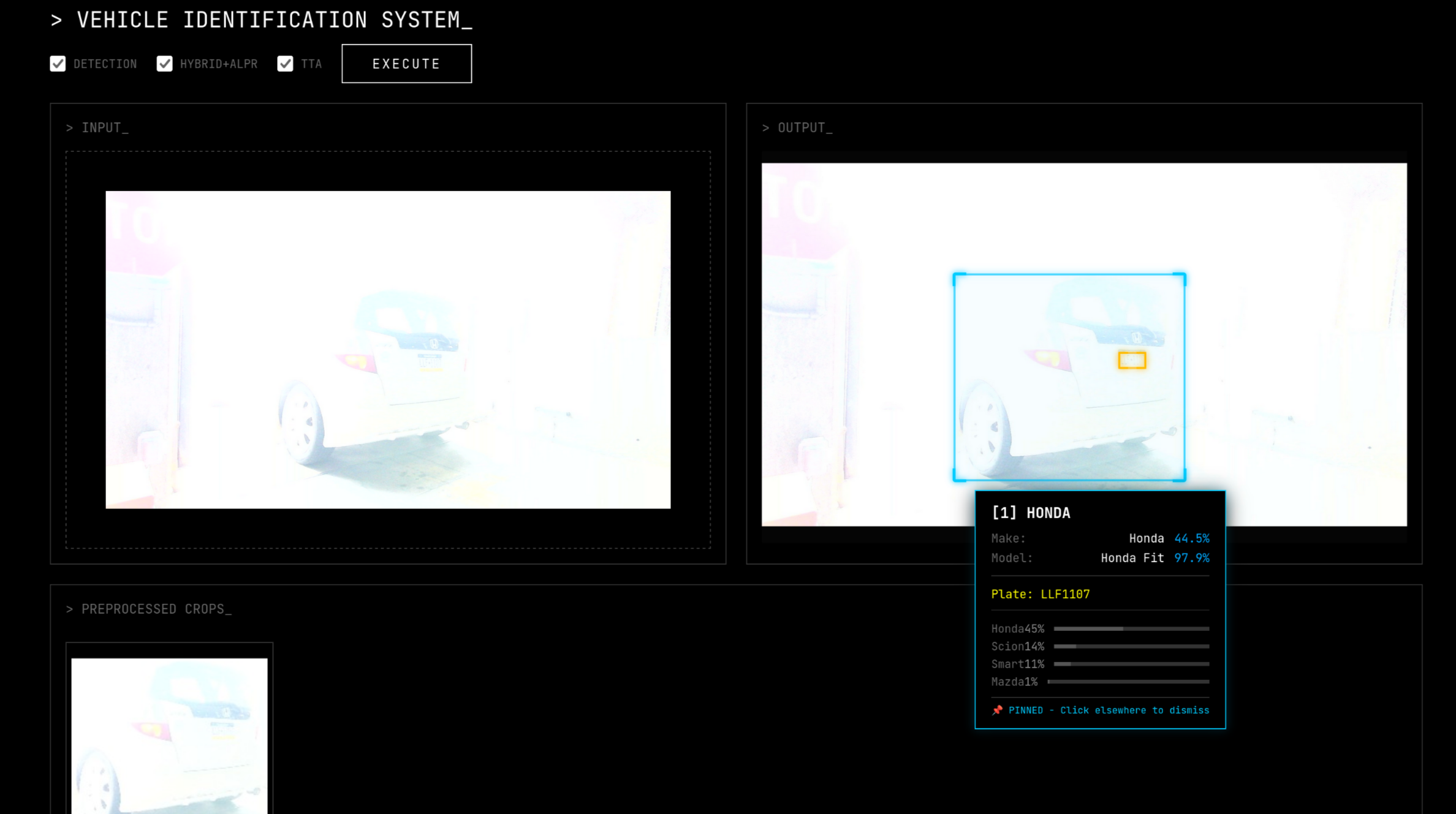
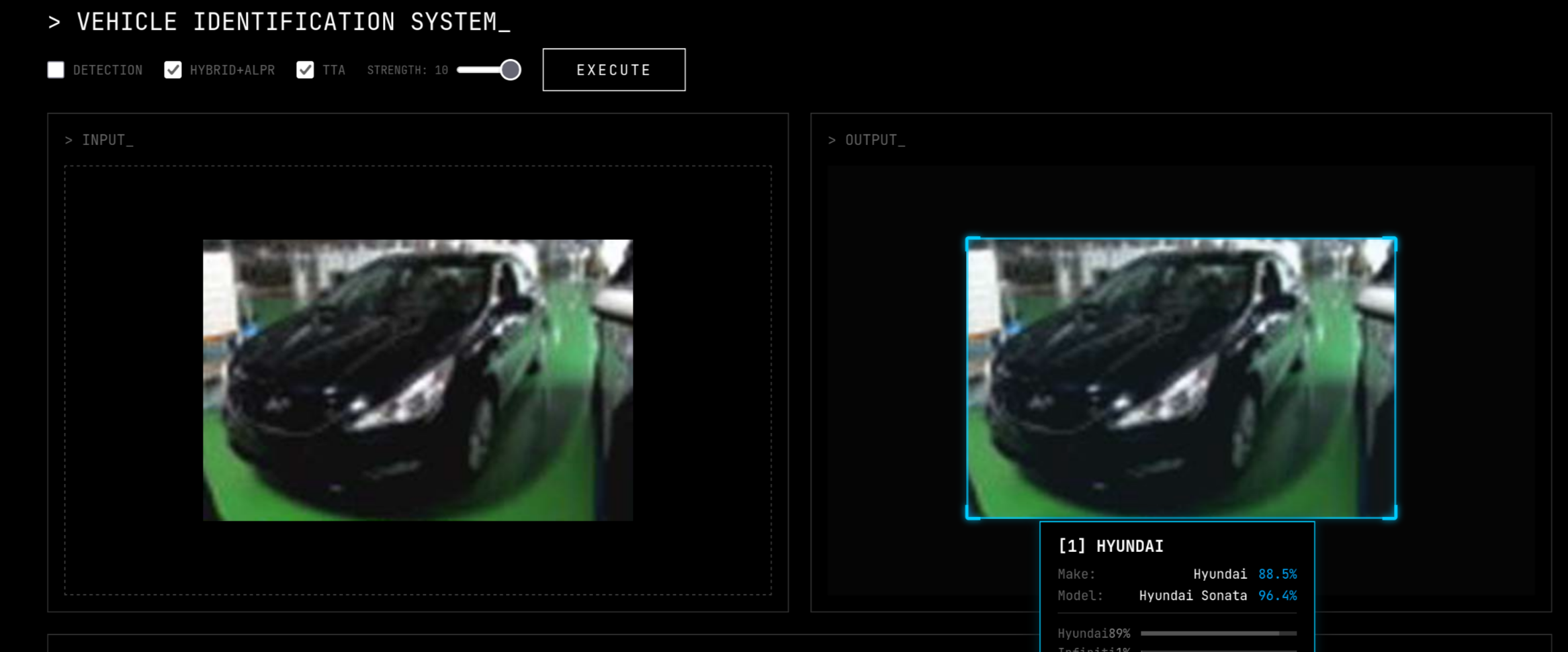
Vehicle Make Model Recognition
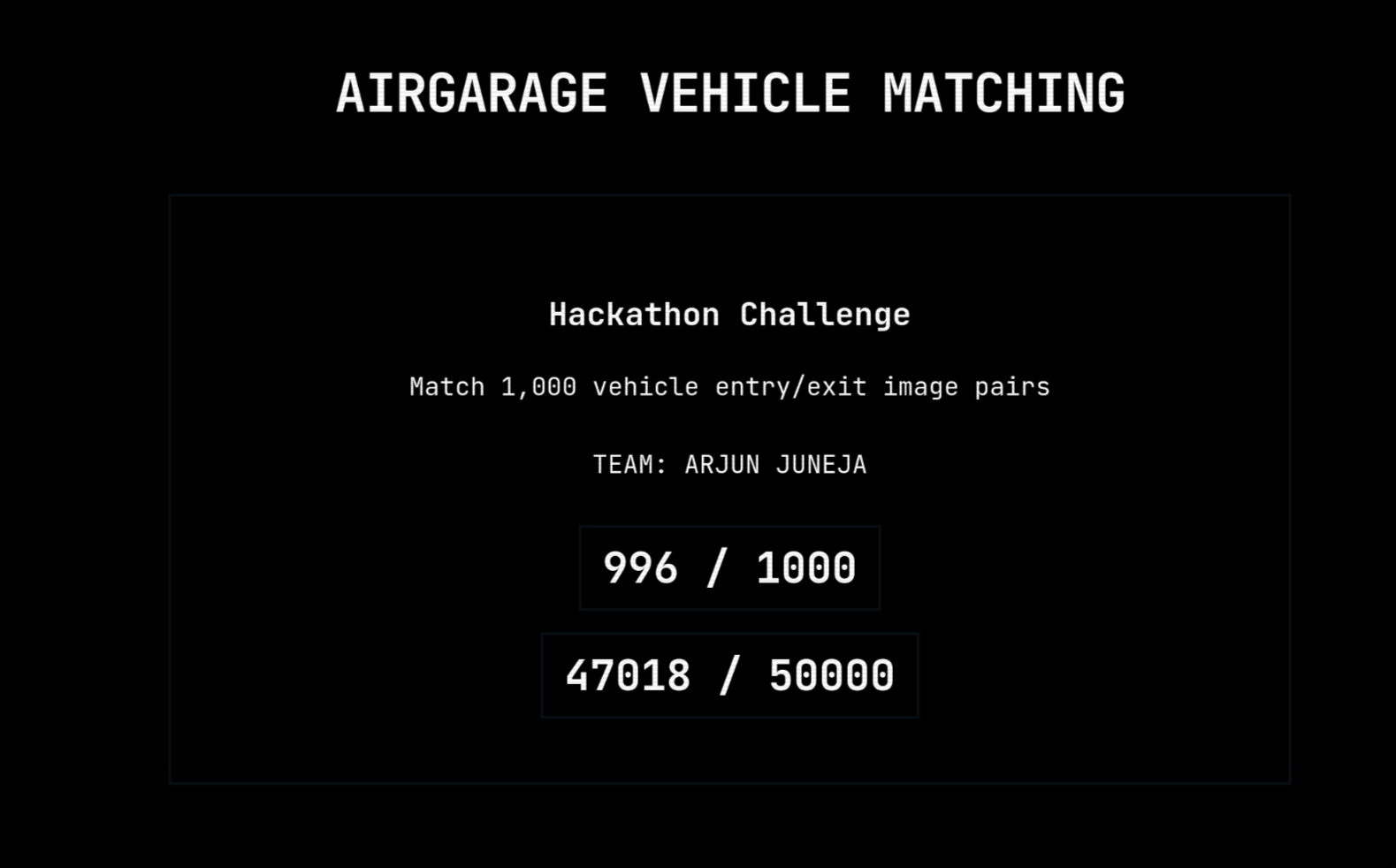
Inspiration
The idea naturally came from the AirGarage challenge. I achieved a 996 and 47018 score using this project, alongside OCR, and various other techniques, but the largest and most impactful deliverable outside of the challenge scope would be the SOTA model I have trained for Vehicle Make Model identification. This model uses quite new techniques based on a vision transformer model, was based on many newer research papers about vision models.
All using just a standard camera and modern deep learning techniques. The final model can be run on my local laptop which only has an RTX 4060 Laptop GPU, hence isnt too resource intensive for inference purposes.
What I Learned
Fine-Grained Visual Classification is Hard
The mathematical formulation for hierarchical classification:
$$P(\text{model} | \text{image}) = P(\text{model} | \text{make}, \text{image}) \cdot P(\text{make} | \text{image})$$
By first predicting the make with high confidence, we can constrain the model predictions to only those belonging to that make, dramatically reducing the search space from 912 models to ~15-30 models per make.
Data Quality Is Insanely Important
Interestingly, fine-tuning on DVM after training on my initial dataset led to catastrophic forgetting: the model's performance degraded because DVM's label distribution was different, and its variety of makes and models, hence confused my existing working model.
Vision Transformers Excel at Fine-Grained Recognition
Compared to CNNs, Vision Transformers (ViT) showed superior performance on this task. The self-attention mechanism allows the model to focus on discriminative regions (grilles, emblems, headlights) regardless of their position in the image:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
The global receptive field from the first layer means ViT can correlate features across the entire image which is obviously essential in cases where a badge in one corner helps identify the vehicle.
Test-Time Augmentation (TTA)
To improve robustness, I implemented 5-transform TTA:
transforms = [
original,
horizontal_flip,
slight_rotation(±5°),
brightness_adjustment(±10%),
slight_scale(0.9-1.1)
]
Final predictions are the weighted average of all transform outputs, improving accuracy by ~10-20% on difficult cases.
Results
| Metric | Value |
|---|---|
| Make Accuracy | 98.0% |
| Model Accuracy | 92.3% |
| Make Top-5 Accuracy | 99.6% |
| Inference Time | ~150ms (GPU) |
Future Work
- Add a head to predict vehicle year
- Body Type Classification: Sedan, SUV, truck, etc.
- Real-time processing with tracking
- Optimize for Jetson/mobile devices
- More makes/models, especially non-US vehicles

Log in or sign up for Devpost to join the conversation.