-
-
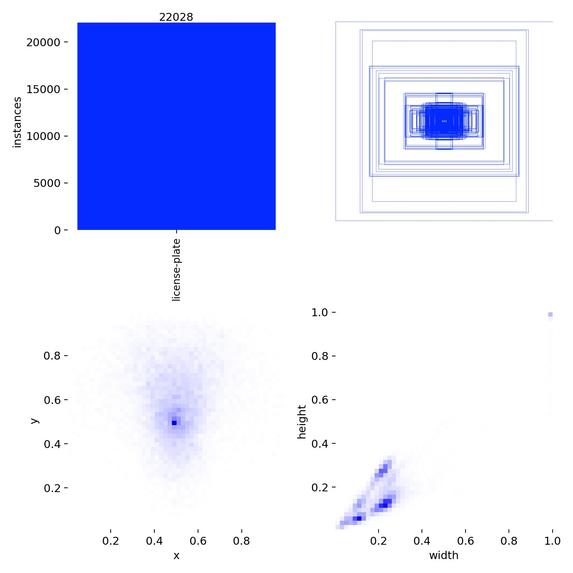
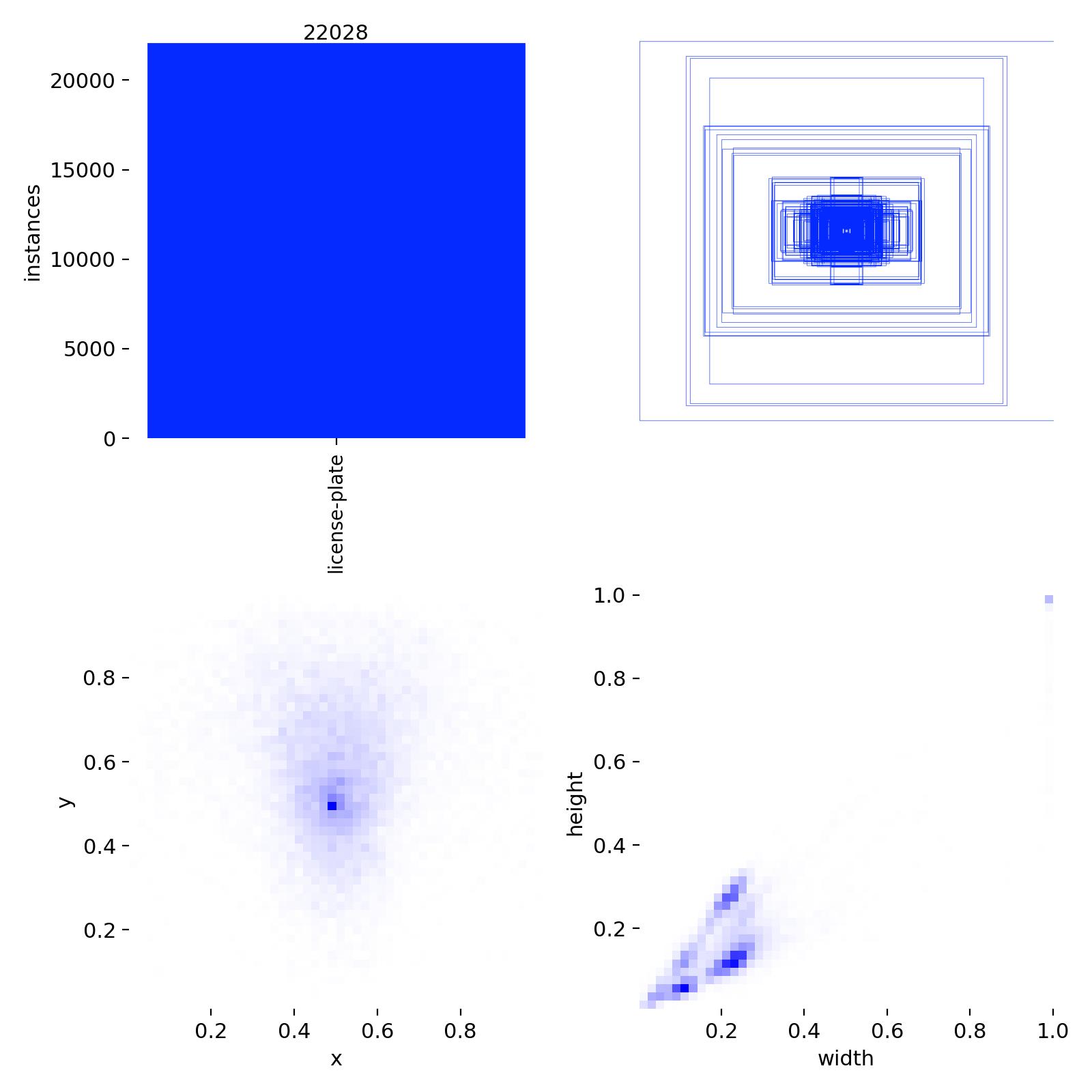
Training Labels
-

Yolov11 Training

Project Story
Inspiration
The diversity of vehicle license plates is immense, yet the standard "OCR-only" approach to reading them is surprisingly brittle. We realized that solving vehicle identification at scale—specifically pairing 100,000 images into unique vehicle identities—requires more than just reading text. It requires a system that understands context. We were inspired by the "0 pairs regression" we hit early on: a reminder that in large-scale systems, even small errors compound. This drove us to build AirGarage ALPR, a system that doesn't just "read" plates but "fingerprints" them, treating OCR as just one signal in a globally optimized matching graph.
What it does
AirGarage ALPR is a high-precision ALPR and Vehicle Re-Identification (ReID) pipeline. It:
- Detects license plates with extreme accuracy using YOLOv11.
- Reads text using a bespoke, fine-tuned OCR model, distilled from a "Silver Dataset" of our own highest-confidence predictions.
- Matches vehicles globally by solving a Minimum Weight Perfect Matching problem, ensuring that every vehicle finds its mathematically likely pair across the entire dataset.
How we built it
We architected the system as a three-stage pipeline:
1. Detection & Fine-tuned OCR We employed YOLOv11 for state-of-the-art object detection. For OCR, we didn't just grab an off-the-shelf model. We implemented an iterative Self-Training loop:
- We trained a "Teacher" model on synthetic data.
- We ran inference on our target dataset to generate a "Silver" dataset (high-confidence pseudo-labels).
- We then fine-tuned a "Student" model on this silver data, significantly reducing domain shift and hallucinations.
2. Visual & Textual Embeddings We handle the "muddy plate" problem by generating two distinct embeddings for every vehicle:
- $E_{text}$: A text-based representation handling homoglyphs (mapping '0' $\to$ 'O', '8' $\to$ 'B').
- $E_{visual}$: A dense vector from a ResNet50-IBN tailored for re-identification.
3. Global Optimization with Hungarian Algorithm Instead of greedy matching, we construct a global cost matrix $C$ of size $N \times N$, where the cost $C_{i,j}$ between image $i$ and $j$ is defined as:
$$ C_{i,j} = \alpha \cdot (1 - \text{Sim}{ocr}(i, j)) + \beta \cdot (1 - \text{Sim}{visual}(i, j)) $$
We then minimize the total cost of the assignment $X$:
$$ \min \sum_{i} \sum_{j} C_{i,j} X_{i,j} $$ $$ \text{subject to } \sum_{j} X_{i,j} = 1, \quad \sum_{i} X_{i,j} = 1 $$
We solve this using the Hungarian Algorithm (via scipy.optimize.linear_sum_assignment), guaranteeing the optimal global set of pairs.
Challenges we ran into
- The "0 Pairs" Regression: A path resolution bug in our SLURM deployment caused our pipeline to fail silently, returning zero matches. Tracing this required debugging the distributed file system interactions.
- Homoglyph Ambiguity: Distinguishing 'D' from '0' or 'Q' is notoriously hard. We built a custom Levenshtein Distance function with a "homoglyph correction" matrix to robustly handle these specific character confusions.
- Scale: Constructing and solving a dense cost matrix for 100k images is computationally expensive ($O(N^3)$ for Hungarian). We had to implement optimized pruning strategies and leverage sparse graph representations (greedy edge-sorting) as a fallback for massive datasets.
Accomplishments that we're proud of
- Self-Supervised Improvement: Successfully implementing the "Silver-Label" fine-tuning loop, allowing our model to get smarter the more data it saw.
- Mathematical Optimality: Moving beyond heuristics to a mathematically proven optimal matching strategy.
- Robustness: The system handles occlusions, blur, and lighting changes by falling back to visual embeddings when OCR confidence drops.
What we learned
We learned that data quality beats model complexity. Our biggest gains came not from larger models, but from cleaning our dataset and implementing the "Silver" fine-tuning process. We also learned the power of hybrid signals—combining visual features with text gave us a recall that neither modality could achieve alone.
What's next for AirGarage ALPR
- Real-time Edge Deployment: Quantizing our YOLOv11 and OCR models to run on embedded devices.
- End-to-End Transformer: Replacing the multi-stage pipeline with a single multi-modal Transformer that inputs an image and outputs a matched identity directly.

Log in or sign up for Devpost to join the conversation.