-
-
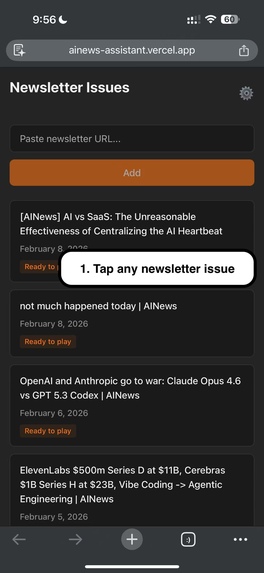
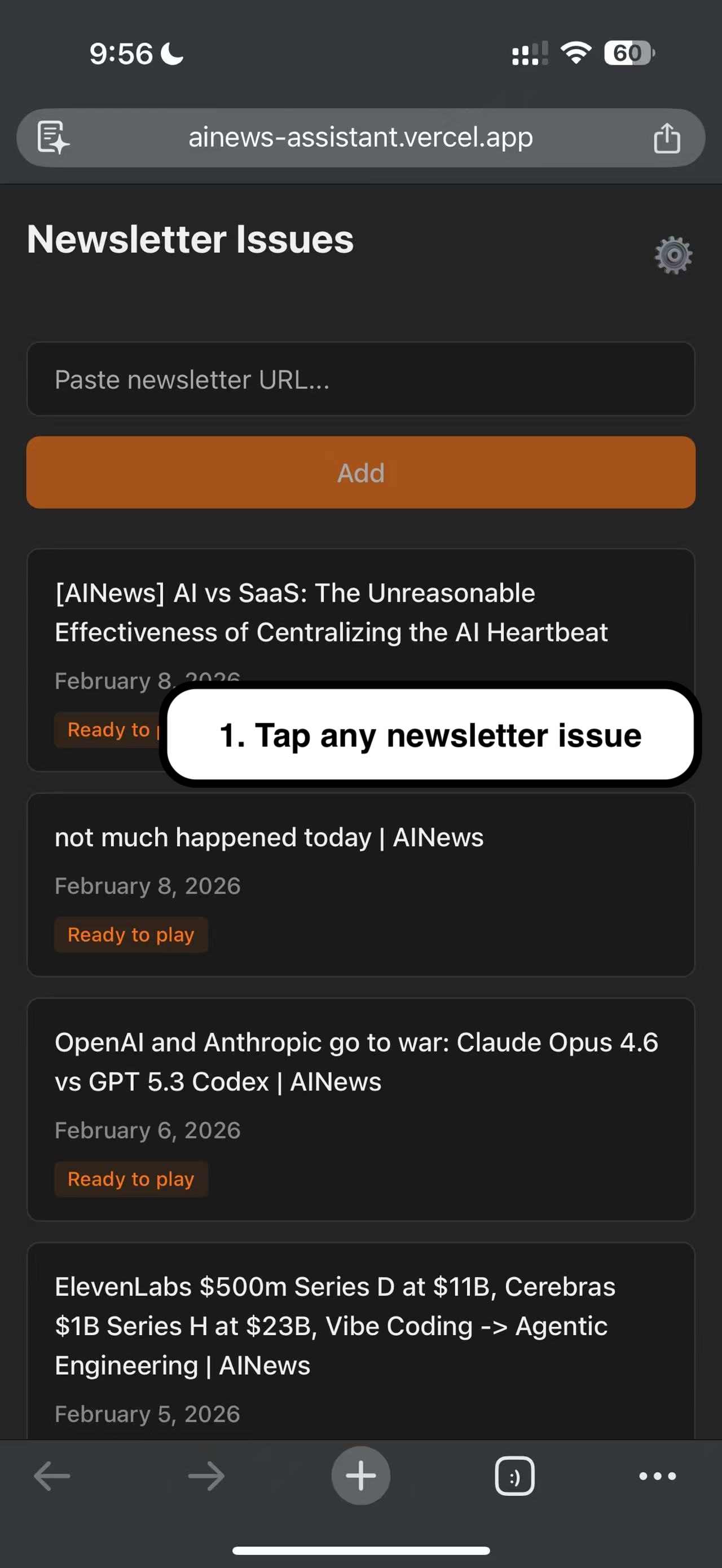
1. Tap any newsletter issue.
-
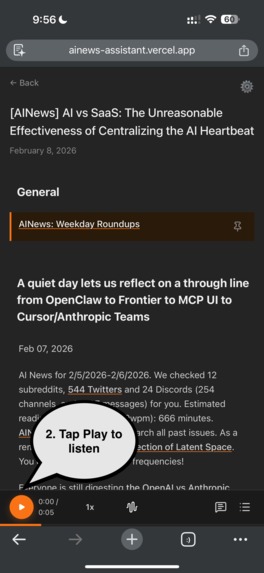
2. Tap Play to listen.
-
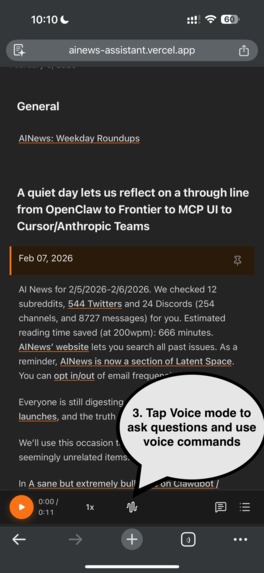
3. Tap Voice mode to ask questions and use voice commands.
Inspiration
I listen to a lot of newsletters while commuting and working out. Most newsletters don't have audio, so I use the browser's read-aloud feature. But the playback control is clunky and I have to switch to a separate app/LLM when I have questions. I always wanted a "news assistant" that reads to me with high-quality voices but also lets me interrupt to ask questions, skip boring parts, and re-listen to segments I missed. All hands-free.
What it does
Aina (AI News Assistant) is a Progressive Web App (PWA) that converts newsletter RSS feed into an intelligent audio session. It leverages the latest Gemini 3 models to create a "Wow" hands-free experience:
Smart Cleaning & Translation with Gemini 3 Flash: We use the new Gemini 3 Flash model to process chaotic HTML from newsletters. Its advanced reasoning capability distinguishes between content, headers, and ads with high precision, and it provides nuanced English-to-Chinese translations that capture the original "newsletter tone", all at lightning speed.
Real-Time Voice Control with Gemini Live: Users can control playback ("pause", "rewind", "bookmark this") purely by voice. We use Gemini Live's function calling in a real-time WebSocket session to detect commands without a rigid "wake word."
Conversational Q&A: If you seek clarification (e.g., "What did that last segment say about the model release competition?"), Gemini Live answers instantly with audio, maintaining context of the entire newsletter.
Premium Audio: The app generates per-segment audio using Google Cloud's Chirp 3 HD Aoede voices for a lifelike listening experience.
Bilingual Mode: Seamlessly toggle between English and Chinese audio tracks, perfect for language learners or bilingual users.
How we built it
I'm a data scientist, not an app developer. So I agentic-engineered the entire project in Antigravity, with Gemini CLI, Claude Code, and Codex. I brainstormed the initial MVP (newsletter processing + read-aloud) with all coding agents, verifying tech stack choices. Then I iteratively added voice commands and live Q&A, using agents to review each other's plans and code. The multi-agent workflow, with Antigravity handling peer review via terminal log access, was key to catching cross-cutting bugs (e.g., iOS WebSocket issues, audio race conditions).
Tech stack: React 19 + TypeScript PWA on Vercel, FastAPI backend on Cloud Run, Supabase (Postgres), Google Cloud Storage for audio, Vertex AI for Gemini models.
Challenges we ran into
iOS Safari WebSocket limitations: Connecting directly to Gemini Live from the browser hit WebSocket upgrade bugs in Safari. We solved this by building a FastAPI WebSocket proxy that bridges the browser and Gemini Live bidirectionally, handling both binary audio and JSON control messages.
Sub-second voice interruption: Gemini Live's
speech_startedevent doesn't exist — you only get transcription after silence. We solved this with a dual-layer approach: client-side VAD (Silero model via ONNX Runtime) detects speech onset and pauses the newsletter instantly, while Gemini's function calling handles command recognition in parallel. Result: the newsletter pauses the moment you speak, not seconds later.Per-segment processing trade-offs: We iterated between processing segments individually vs. by topic group. Individual processing gives fine-grained playback control but risks API rate limits. Topic-group processing reduces API calls but loses per-segment features. We settled on per-segment with parallel batching (5 concurrent) and error tolerance (continues if some segments fail).
Accomplishments that we're proud of
True hands-free operation: From "Play the newsletter" to "Bookmark this" to "What's the latest on the model release competition?" You never have to touch the screen.
Sub-second voice response: Client-side VAD + Gemini Live function calling delivers <1 second command latency, all in a phone browser without a native app.
Gemini Live as a voice UI layer: Using function calling to map natural speech to app commands (7 tools). No intent classification pipeline, no training data, just tool definitions.
Production-quality PWA: Offline caching, auto-resume playback position, install-to-homescreen, bilingual support
What we learned
- Gemini Live API's function calling is a game-changer for voice-controlled UIs — it replaces an entire intent-classification pipeline with simple tool definitions
- Client-side VAD is essential for responsive voice interfaces; server-side detection adds too much latency
- WebSocket proxying is necessary for broad browser compatibility with streaming APIs (especially iOS Safari)
- Multi-agent development works: different models and/or different harnesses catch different bugs. Antigravity excels at peer review since it has access to terminal logs
What's next for Aina
- Expand beyond AINews to support any newsletter RSS feed
- Improve voice command reliability in noisy environments (e.g., running outdoors)
- Explore video content Q&A with Gemini's multimodal capabilities
- Upgrade to Gemini 3 Live API when available for even better real-time voice interaction
Built With
- fastapi
- gemini-3-flash-preview
- gemini-3-pro-preview
- gemini-live-2.5-flash-native-audio
- google-cloud
- google-cloud-run
- google-cloud-tts
- google-cloud-vertex-ai
- python
- react
- ricky0123/vad-web
- supabase
- typescript


Log in or sign up for Devpost to join the conversation.