-
-
data representations
Method
During the initial stages of our setup, we considered how to balance costs with model ability, which largely influenced our model selection. We prioritized models with strong conversational ability, as ultimately we wanted to create a chatbot. Additionally, we had to consider how to make use of data that was specific to Valorant—from a cost-efficiency perspective, RAG was a better choice as compared to fine-tuning. After experimenting with multiple foundational models, we ultimately decided on Anthropic’s Claude 3.0 Sonnet, which balanced strong conversational ability with efficient pricing.
The next big consideration was the dataset responsible for training our model. Valorant’s community-based platform, vlr.gg, which includes comprehensive statistics for every Valorant player and game, was our first choice for the dataset. The website contained insightful player-specific statistics that were aggregated over all their participating games. Given that Bedrock Knowledge Bases allowed native implementation of web crawlers to scrape player data, we assumed vlr.gg would be a viable and the only source of information for training our model. However, we soon ran into problems where we either were not able to appropriately configure the KB with the web crawler or we were easily crossing the agreed-upon rate limits for accessing vlr.gg.
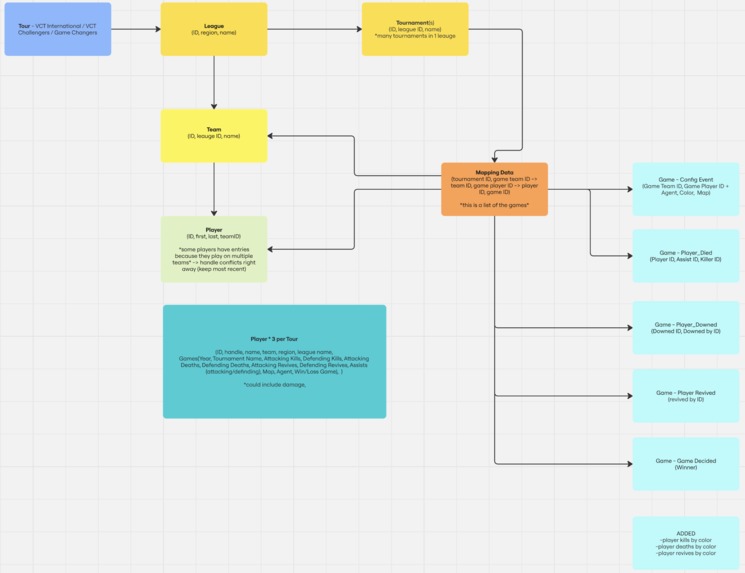
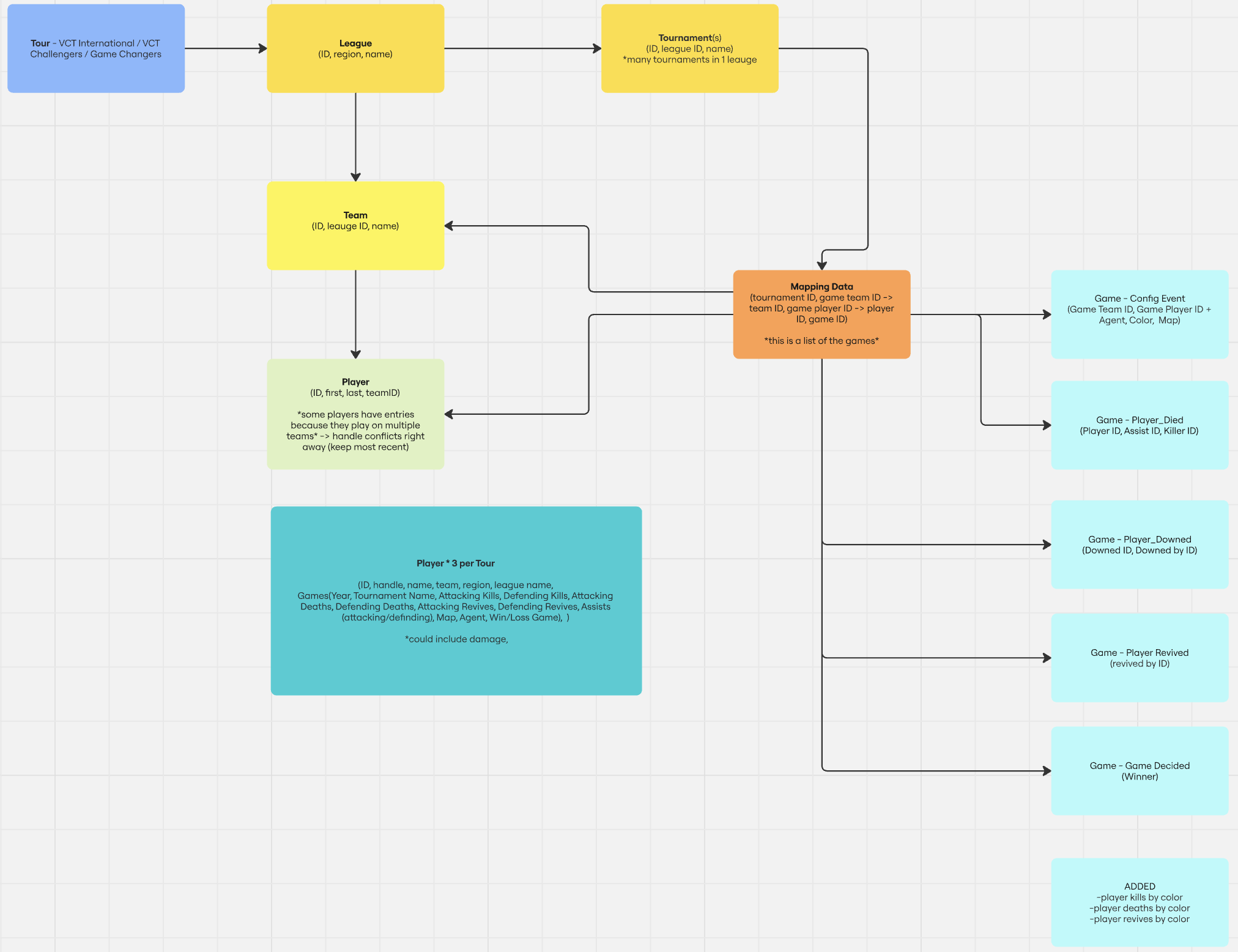
Soon, after taking inspiration from player metrics in vlr.gg, we turned our eyes toward the extensive game data files that were provided to us by the Riot Games team. This dataset essentially consisted of game log files and a variety of player, team, and league-specific metadata organized by their respective VCT tournaments and years. Given this vast data lake, translating all the data entities and their underlying relationships into a meaningful Miro board was a necessity. Clearly, parsing through all these data files would prove to be a programmatic and resource-intensive burden; however, it allowed us to build our very own player and agent-specific aggregations that accurately measured a player’s performance across all their games. While we used the player, team, and league metadata JSON files to gather human-friendly information about each of these entities, we used the game log files to calculate and finally aggregate a player’s performance off of metrics like kills, deaths, assists, combat score, etc.
After deconstructing the raw game data into a structured format, we created a Bedrock pipeline to feed the information to our Bedrock Agent via Bedrock’s native RAG capabilities. Unfortunately, the agent alone performed poorly at utilizing the information from the knowledge base to handle user queries. To mitigate this issue, we experimented with Agent Action Groups that involved creating Lambda functions to help the knowledge base traverse queries. Due to the unnecessary rise in complexity, we eventually decided on an alternative approach to employ a variety of prompting techniques including the following: chain of thought, multi-shot, XML tagging, pre-filling responses for output control, and chaining multiple prompts.
Throughout the project implementation, we remained mindful of the pricing considerations, ultimately influencing our choice of hosting the chat interface over AWS Amplify. In fact, due to our sensitivity to AWS pricing, we refrained from hosting/storing any of the raw game data (over 100 GB) in our S3 buckets. Instead, we ran our custom ETL transformations on the data in real time during transit. At all stages, we optimized our solutions by reducing extraneous data and only keeping the information we truly needed.
Challenges
We encountered several challenges including the sustainable maintenance of AWS expenditure, handling inconsistencies in Valorant game data files, accurately training our model, and finally optimizing it to reduce the response return times. As mentioned before, we handled our AWS expenditure by being mindful of our expenses and optimized the model for our use case by delving into several prompt engineering techniques.
Of the several challenges during the data wrangling phase, the key issues involved the player and game datasets. Essentially, the player's JSON file introduced multiple entries for the same player ID, making the unique player ID irrelevant. While these entries belonged to the same player, they represented different sets of information, as the player transitioned across different teams and periods of inactivity ranging from 2022 till 2024. Thus, it was essential for our model to be trained on the most recent information pertaining to each player so as to present a player’s latest metadata over the chat interface. Our implementation accounts for these multiple player entries while only keeping a player’s most recent data.
We noticed the second data wrangling challenge with a few game log files that did not adhere to the same event logging structure as the thousands of other game files. Our implementation disregards these erroneous game files, as player data from a couple of games should not significantly affect the player’s overall career statistics. Furthermore, we incorporated more robust error handling to deal with these inconsistencies.
Learning Outcomes
Throughout the hackathon, we learned a lot! With regards to LLMs, we deepened our understanding of how prompting and embedding techniques can change the outcome and accuracy of the model. We learned about how to handle data inconsistencies gracefully and strategies for representing large amounts of data effectively.
Topping all of this, we learned the most about AWS’s tools and services. In particular, after understanding Bedrock’s capabilities, we can leverage it as a solution for future GenAI endeavors. For example, one of our members has already pitched and gotten approval to incorporate this LLM marketplace for their research project.
What would we do if we didn’t have throttling issues?
As we continued experimentation with our trained model, we proactively tried to reduce the response time by employing either advanced prompting or chunking strategies. One such idea was a more efficient chunking strategy for our JSON data. Theoretically, chunking up our player JSON data into their own respective metadata and statistics file with corresponding file name markers/identifiers ought to improve the knowledge base indexing and ultimately the agent's querying capabilities. While we were able to chunk and store the players according to the above strategy, we did not have enough opportunity to test it owing to Bedrock's throttling exceptions.

Log in or sign up for Devpost to join the conversation.