AI Jury - Your pitch just met its toughest crowd
Inspiration
I've organized hackathons. I've judged pitch competitions. And I've stood on stage with a deck in my hands.
Here's what I saw from each of those sides.
When you're an organizer - you know that by the finals you have 30, 40, sometimes 60 projects. And a panel of five exhausted people who physically cannot give each one the same depth of attention. By 2am the judges aren't analyzing anymore - they're surviving. Someone latches onto one bright slide. Someone votes on mood. Someone just wants to go home.
When you're a judge - you genuinely try to be objective. But you don't have time. You don't have a unified system. You have intuition, exhaustion, and fifteen minutes for a project a team spent three months building.
When you're a founder on stage - you feel it. You see one judge looking at their phone. Another asks a question that's clearly answered in the deck - they just didn't read it. And you'll never know why you didn't make it to the next round. Just "not this time."
This isn't malice. It's a systemic problem. People don't have the time, tools, or energy to evaluate consistently and fairly.
And I kept thinking about VC scouts drowning in hundreds of projects a month. Same story - just at industrial scale.
That's why we built AI Jury.
What it does
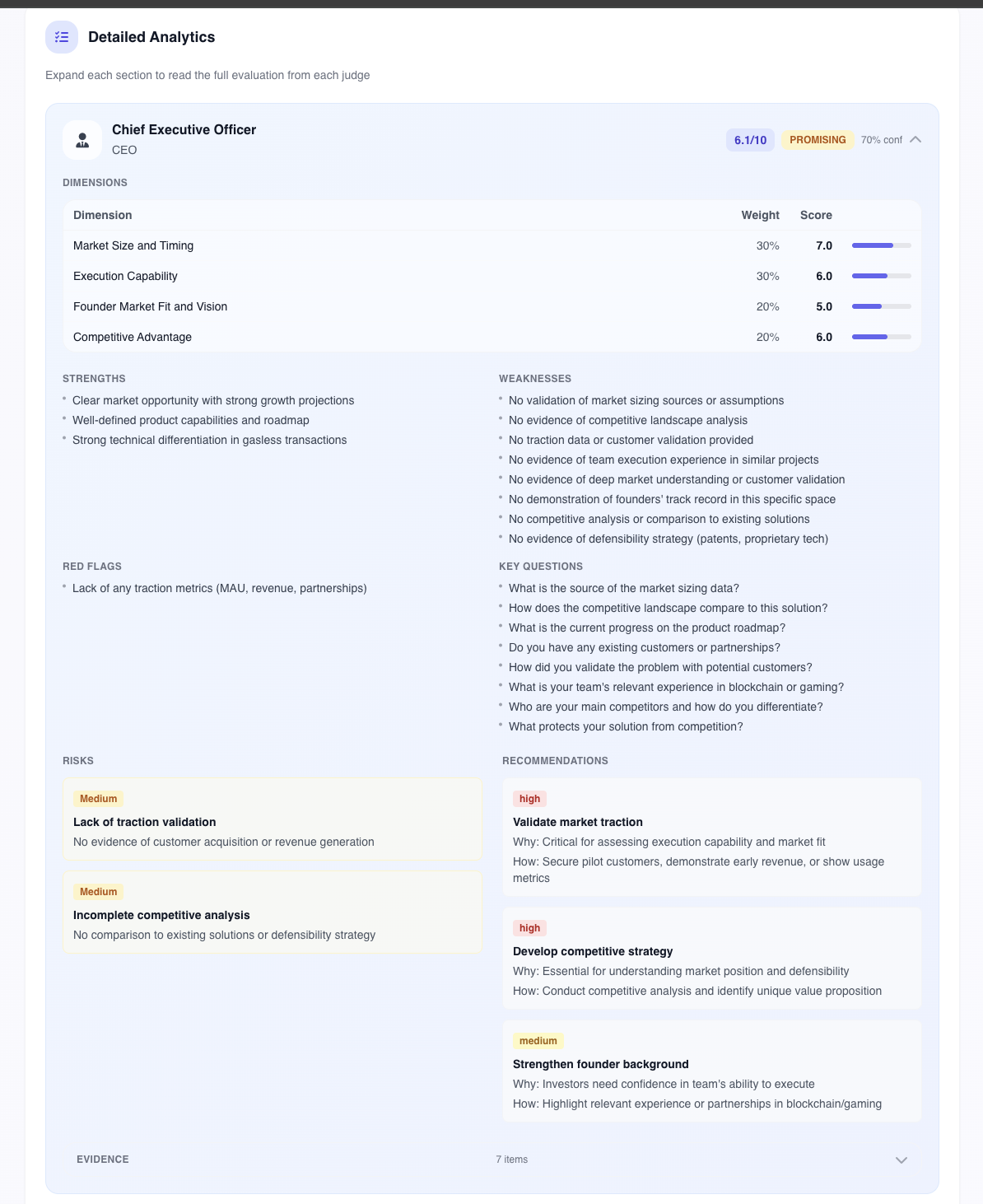
AI Jury is a multi-agent pitch evaluation system. You upload your deck or drop a link and a panel of 5+ virtual judges tears into it in under 2 minutes. Each judge has their own lens: one thinks like a VC, one like a product operator, one like a growth hacker. They work independently, then a Summarizer agent pulls everything together into one report.
Think Shark Tank - without the bad studio acoustics and with a guaranteed answer.
What you get back:
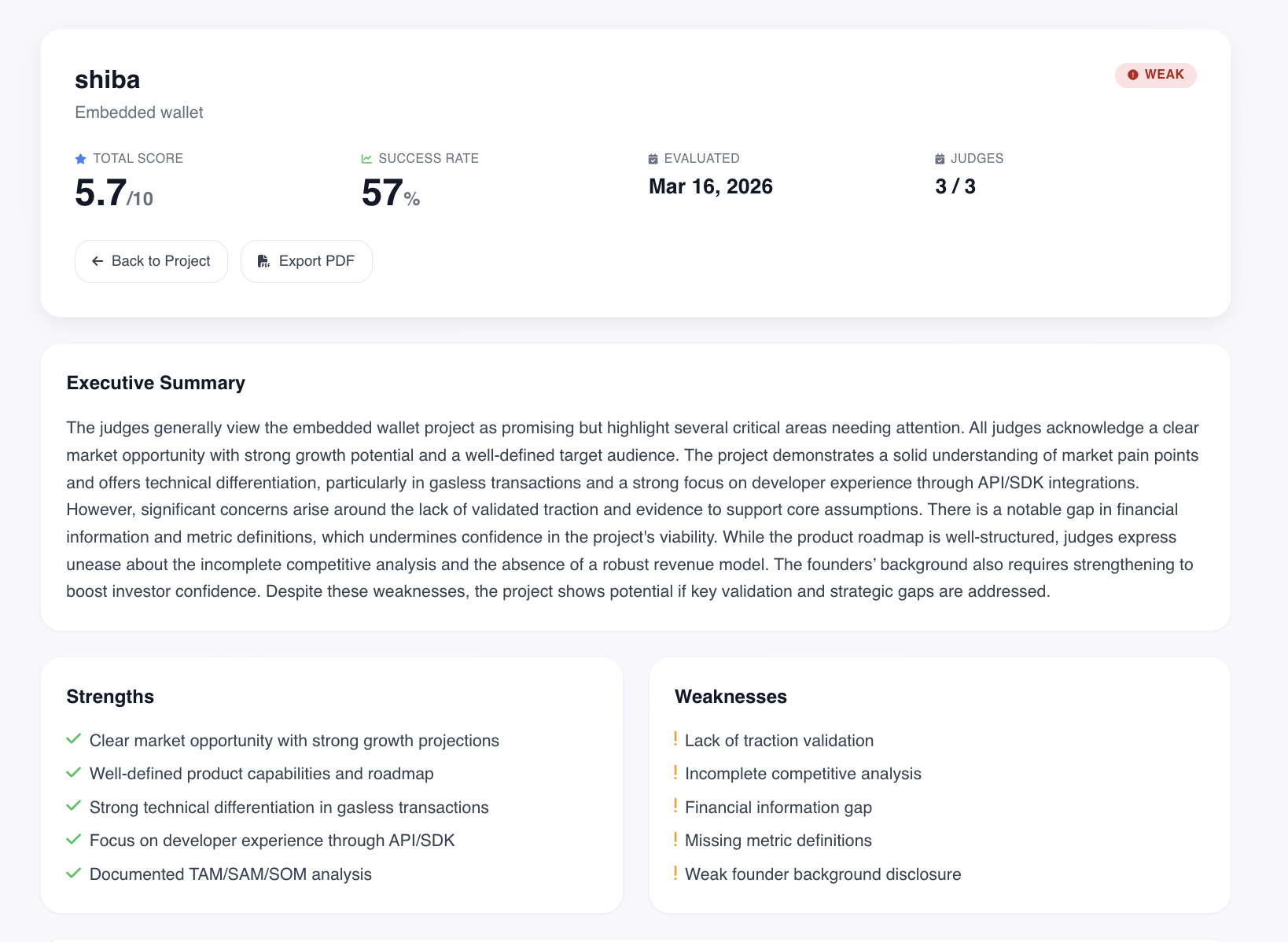
- Individual verdicts from each judge - score, strengths, weaknesses, recommendations
- Aggregate score - weighted across the full panel of 5+ judges
- Success probability - calculated from traction signals, market quality, team strength, and how much the judges actually agree with each other
- Disagreement map - where judges conflict and why. We don't hide this, we show it
- Concrete next steps - not "improve your deck", but exactly what and why
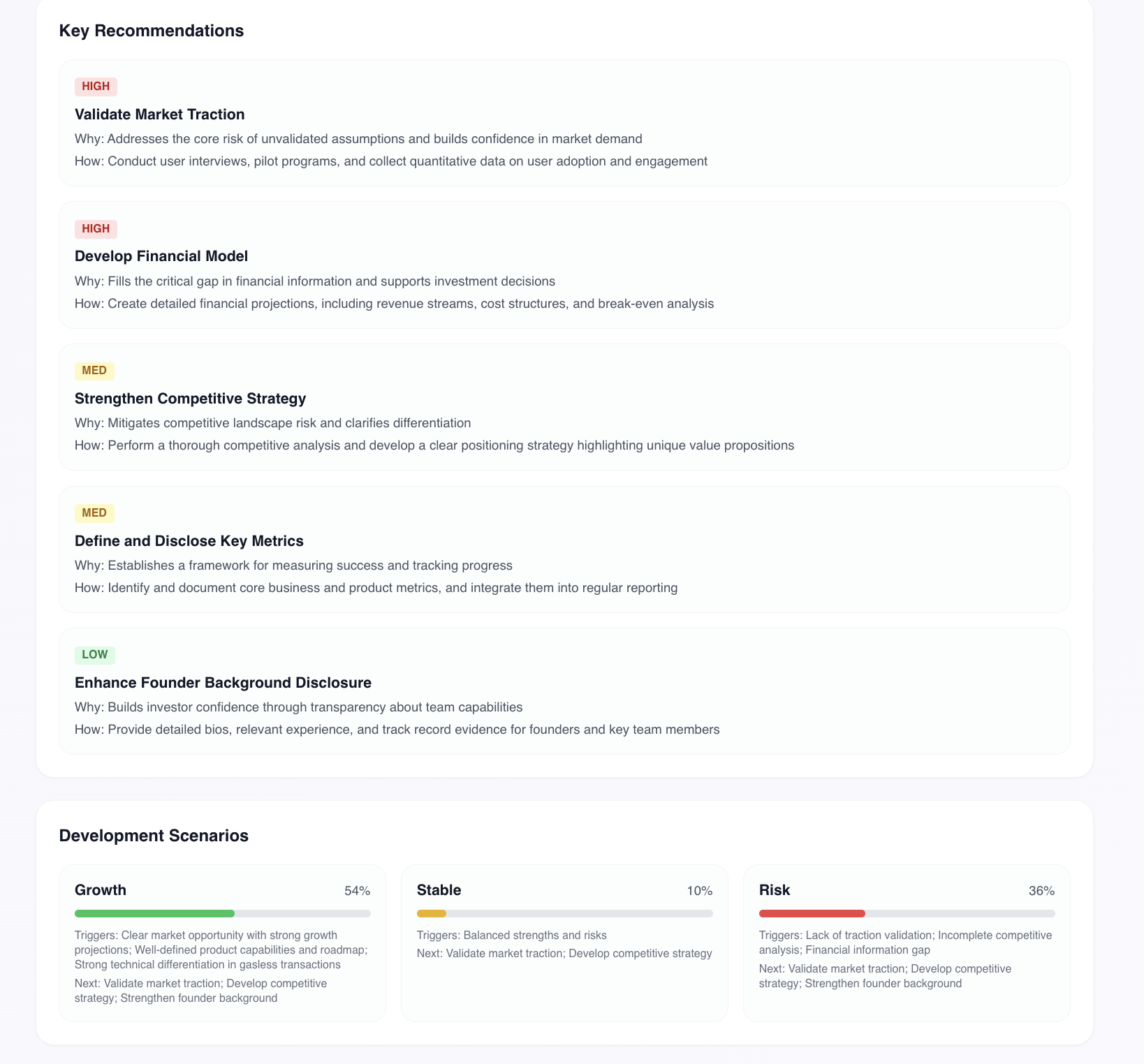
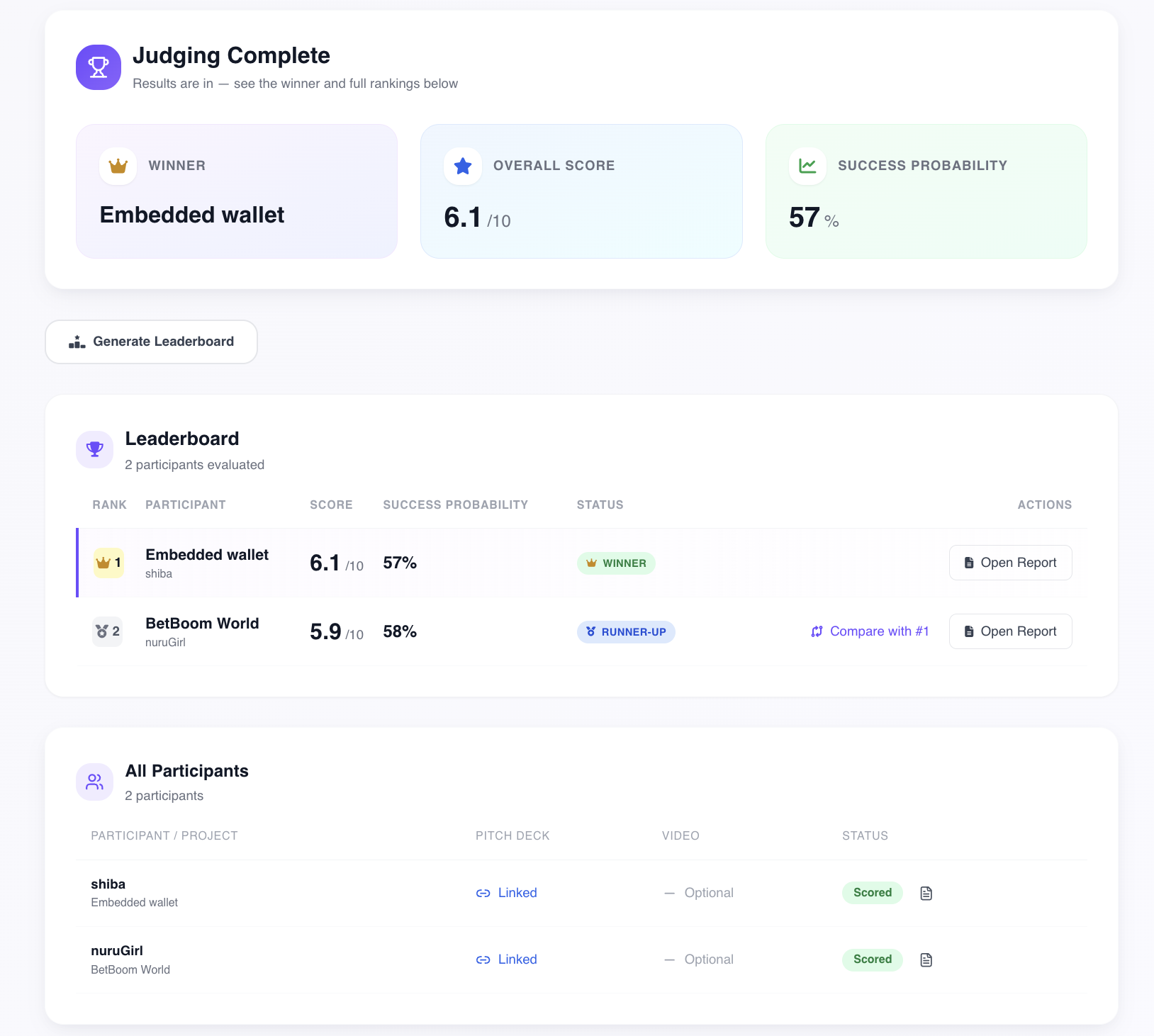
- Leaderboard - automatic ranking of all participants with final scores, per-criteria breakdown, and
WINNER / RUNNER-UP / TOP 3badges. Organizers see results instantly, no manual spreadsheet merging at 3am
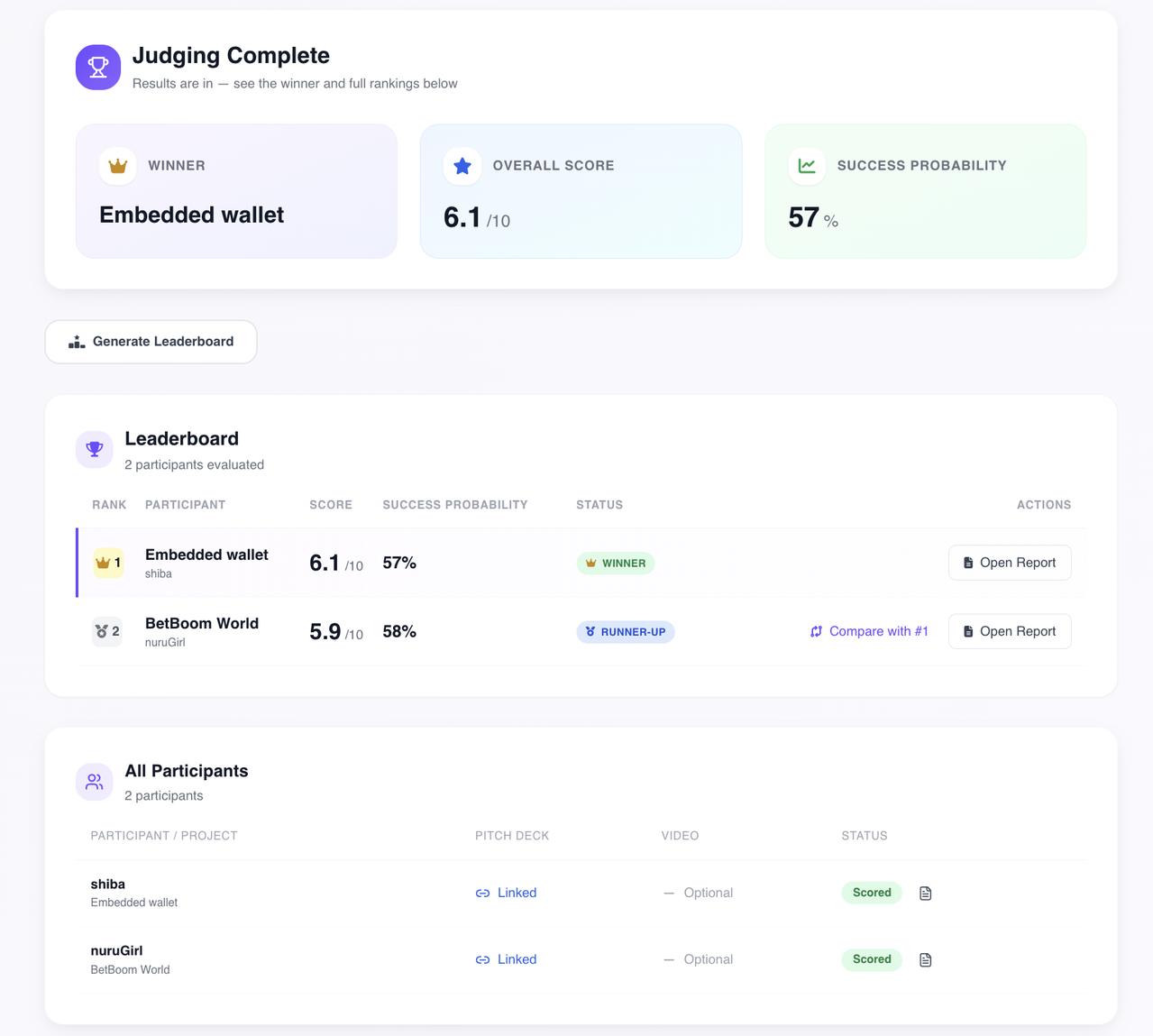 Project leaderboard — ranked participants with final scores, success rate and status badges
Project leaderboard — ranked participants with final scores, success rate and status badges
How we built it
Seven stages, clean and sequential - like a proper heist movie where everyone has a role and nobody goes off-script:
- Input Data - the system takes a single JSON from the database: project data, weighted criteria, judges with their prompts, participants with pitch links
- Decoder - normalizes and validates each participant's materials. Checks link availability, extracts text, sets
pitch_available: true/false. If there's no pitch the pipeline doesn't stop, it continues with what it has - Judge Orchestrator - runs all judges in parallel. Each judge works independently on their own
technical_prompt_mdwith three instruction layers: base, default, and advanced. Project criteria are intentionally not passed to judges - each one evaluates through their own lens - Summarizer Agent - aggregates all judge outputs per participant, eliminates duplicates, resolves conflicts, builds three development scenarios: Growth, Stable, Risk and calculates success probability
- Scoring Service - the only place where project criteria with weights are applied. Maps results onto
criteria[]with a weighted score formula and normalizes the final score per project scale - Leaderboard - ranks all participants, assigns status badges, builds per-criteria breakdown
- Comparison Agent - triggered only on user request. Compares two participants across criteria with delta scores and explains in three bullets why one beat the other
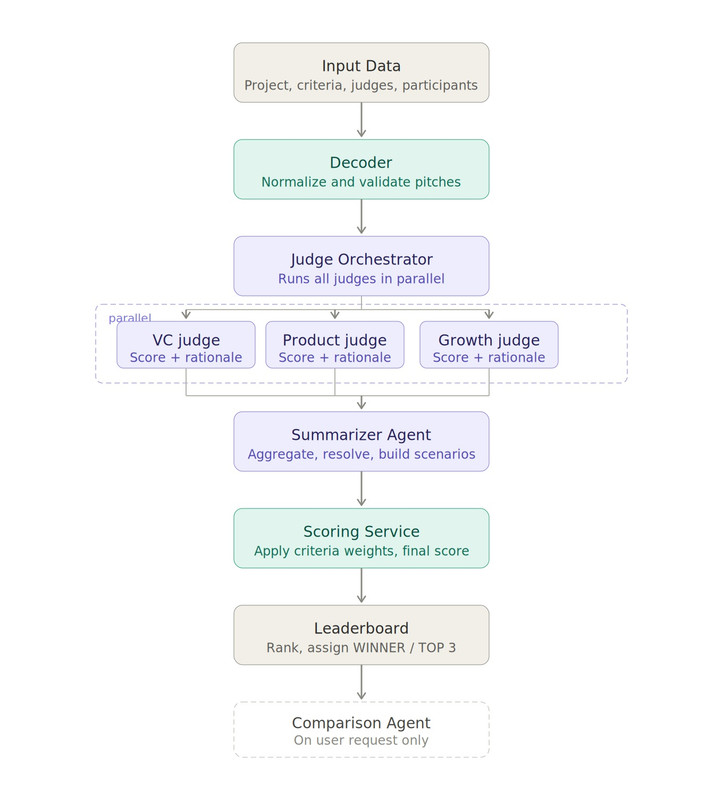 AI Jury evaluation pipeline — 7 stages from input to leaderboard
AI Jury evaluation pipeline — 7 stages from input to leaderboard
Why Amazon Nova 2 Lite
Our pipeline runs multiple agents in parallel — each processing a full pitch deck with complex structured prompts and returning strict JSON. That's not a job for just any model.
Here's why Nova 2 Lite was the right call:
- 1 million token context window — a full pitch deck, judge profile, scoring criteria and instructions fit in a single call with room to spare. No chunking, no summarization tricks, no context loss
- Built for agentic workflows — Nova 2 Lite is specifically designed for multi-step agent pipelines with reliable function calling and stable tool use. Exactly what an orchestrator running 5+ judges in parallel needs
- Consistent structured output — handles long, complex evaluation prompts and returns clean JSON every time. Our entire pipeline depends on this. One malformed response breaks the chain
- Extended thinking on demand — we can dial reasoning depth per agent: fast and cheap for extraction, deeper for summarization and scoring
- Industry-leading price performance — equal or better than GPT-4o Mini and Gemini Flash 2.5 on key benchmarks, at a fraction of the cost. Running 5+ judges per pitch at scale requires this
Challenges we ran into
The hardest thing for us was judge determinism - and that sounds simple right up until you actually face it.
Imagine: the same pitch, the same judge, the same prompt and a different score every time. Not slightly different. Noticeably different. We spent a long time fighting to make the system behave predictably: if you changed nothing in the pitch the score shouldn't change. If you changed something specific the score should move in exactly the direction you expect.
This sounds like a baseline requirement. In practice it's one of the hardest challenges in working with LLM agents. We went through temperature settings, rewrote prompt structures, introduced strict output contracts and validation at every layer - until we got behavior we could actually trust.
What we learned
Multi-agent systems are fun to design and humbling to build. The temptation is to give agents freedom - let them reason, explore, be creative. The discipline is making them structured without killing the quality of their thinking. Finding that balance is the real engineering work, and it's invisible in the final product - which means you did it right.
Also: AWS Bedrock is genuinely good at following complex structured prompts at scale. We threw some serious evaluation schemas at it and it returned clean JSON every time, fast enough to keep the entire pipeline under 2 minutes. That's not a given with LLMs and it mattered enormously here.
What's next
Product roadmap:
- [ ] Judge marketplace - VC, operator, technical, growth, domain-specific personas
- [ ] Custom judge builder for accelerators and funds with their own evaluation framework
- [ ] Re-evaluation flow: fix your deck, rerun through the same panel, see the delta
- [ ] Batch mode: compare multiple pitches side by side
- [ ] Full audit trail: versioned prompts, snapshots of every judge input and output
Next technology frontier: Live Pitch Decoder
Right now AI Jury evaluates what's written in the deck. But a pitch isn't just slides.
The next stage is a video decoder for live pitches. You walk out in front of an audience, pitch live, and AI Jury analyzes you in real time: pace of speech, delivery confidence, argument structure, responses under pressure. Not "what's written in the deck" but "how you're selling it."
This means a founder can come to demo day, pitch live and immediately get a breakdown not just of their idea but of their performance. Where they lost the room. Where they answered unconvincingly. What to fix before next time.
We call this IRL evaluation - and it transforms AI Jury from a preparation tool into a full coach for live pitch sessions.
Go-to-market:
Our first real distribution channel is the hackathon ecosystem. Yes, we see the beautiful irony of pitching this at a hackathon. Organizers receive hundreds of submissions and need consistent, scalable evaluation. AI Jury fits that workflow directly.
Second channel: VC scouts and early-stage analysts who review deal flow at volume. They get a tool that saves hours per week. We get first-hand feedback on what good evaluation actually means to people who do it professionally.
Both channels give us something money can't buy at this stage - real pitches, real feedback, real iteration.
Built with
| Layer | Technology |
|---|---|
| AI Engine | AWS Nova 2 Lite |
| Frontend | Next.js 14, React 18, TypeScript, Tailwind CSS |
| Backend | Next.js API Routes, Supabase (PostgreSQL, Auth, Storage) |
| Hosting | Vercel |
⚠️ Important Note
Since we haven't integrated a payment system yet, AI agents consume tokens to run evaluations.
If you'd like to test the project, please reach out directly and I'll make sure you get access:
- Telegram: @hellomrv
- LinkedIn: Yaroslav Volovoj
Happy to give you a live demo! 🚀
Built With
- amazon-nova-2-lite
- aws-bedrock
- next.js-14
- node.js
- react-18
- supabase
- tailwind-css
- typescript
- vercel






Log in or sign up for Devpost to join the conversation.