-
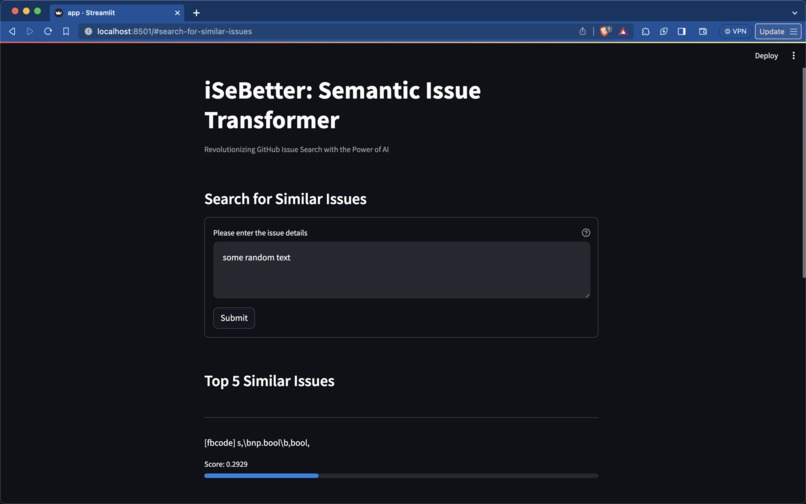
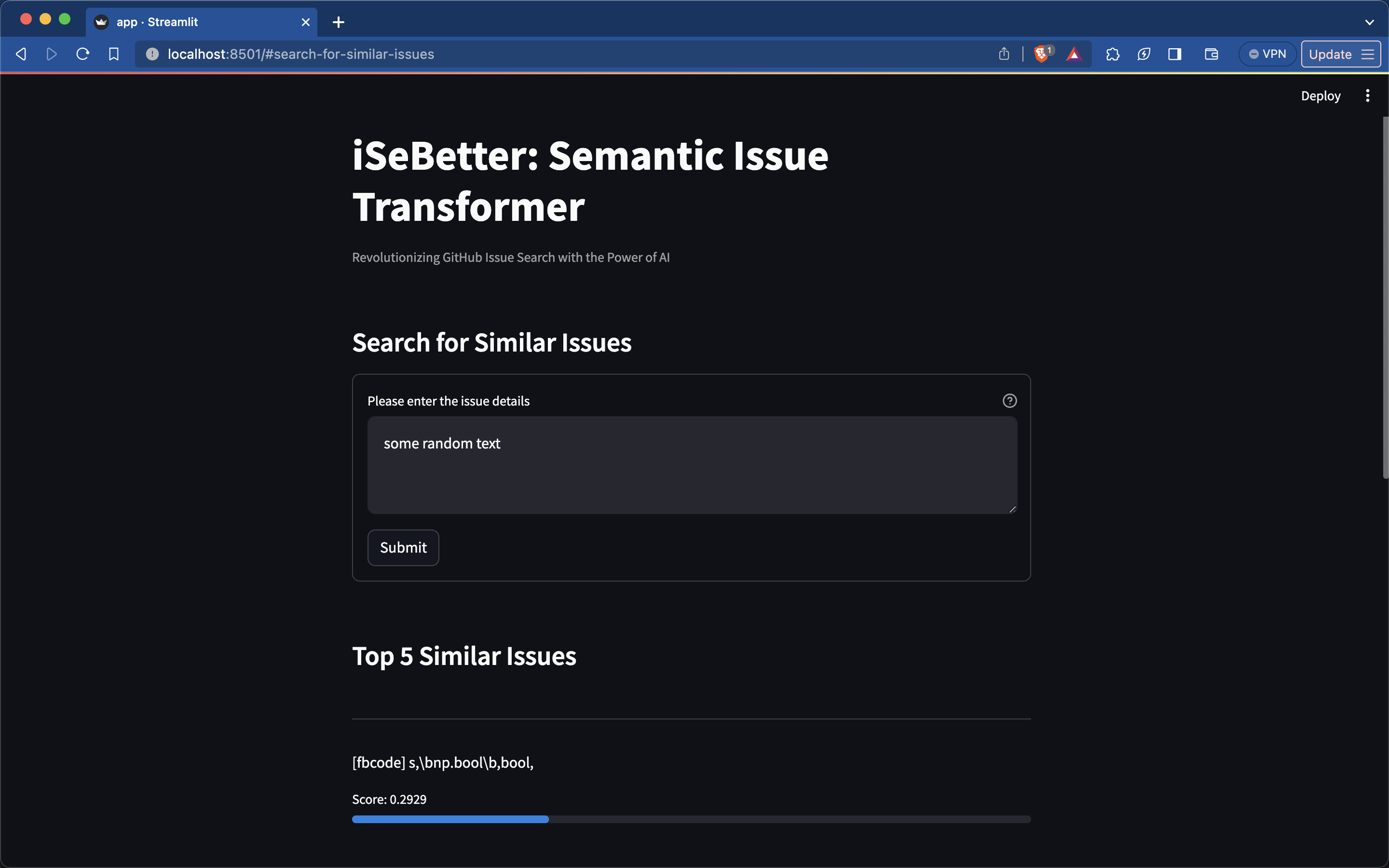
Sample UI
The Inspiration
GitHub issues can quickly accumulate, making it challenging to find similar or relevant problems. Developers often waste precious time sifting through issues that have already been resolved, leading to inefficiencies. Our hackathon project's aim is to effectively address these challenges by: Grouping Similar Issues: We make it easier for developers to collaborate and avoid redundant work. Reducing Duplicate Issues: This simplifies the task for maintainers, allowing them to consolidate efforts and address issues more effectively. Organizing and Prioritizing Issues: We help developers focus on the most critical tasks.
What We Learned
As we delved into this project, we acquired valuable insights and skills:
- Data collection and processing
- Different approaches to training the model
- Utilizing Hugging Face for model hosting
- Leveraging Streamlit for the user interface
- Understanding Transformers and their advantages
Building the Project
Data Collection and Preprocessing
Our journey began with the collection of a dataset of GitHub issues. We used the GitHub API to scrape issues from the PyTorch repository, which currently boasts more than 6,000 open issues. We gathered essential information, including issue titles, comments, and descriptions, and published the dataset on Hugging Face datasets.
Model Selection and Training
We opted for a pre-trained semantic search model, specifically the all-mpnet-base-v2 model with a sequence length of 512. We harnessed embeddings and k-nearest neighbors (KNN) to identify contextually similar issues.
Streamlit Integration
We developed a user-friendly Streamlit web application that empowers users to input a query issue. Our fine-tuned model then retrieves and displays the top-k similar issues, enhancing the user experience.
Deployment and Continuous Improvement
To ensure seamless deployment and continuous enhancement, we implemented GitHub webhooks. Any commit made to the repository triggers automated deployment to Hugging Face spaces, ensuring that the latest changes go live in production.
The Challenges
The development of iSeBetter presented its own unique set of challenges: The project encompassed numerous complex topics, which we had to quickly grasp. Dealing with the GitHub API's rate limiter posed a formidable challenge in gathering data. The field of AI is expansive and open-ended, making it difficult to identify the ideal model and fine-tune it to meet our requirements.
In summary, "iSeBetter: Semantic Github Issue Transformer" is the culmination of our efforts to enhance issue discovery and resolution on GitHub, with AI at its core. We hope this tool empowers developers and open-source contributors to work more efficiently and collaboratively within the community, making a substantial impact. We are excited to present our project to the judges and welcome their feedback.
Built With
- github
- huggingfaces
- natural-language-processing
- python
- pytorch
- streamlit
- transformers

Log in or sign up for Devpost to join the conversation.