-
-
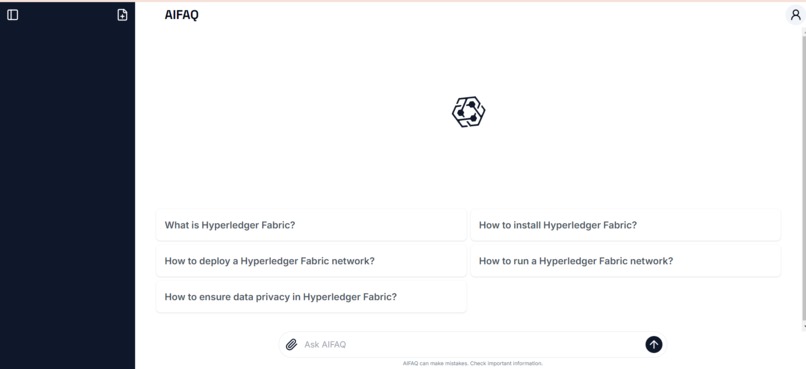
Frontend page for Users
-
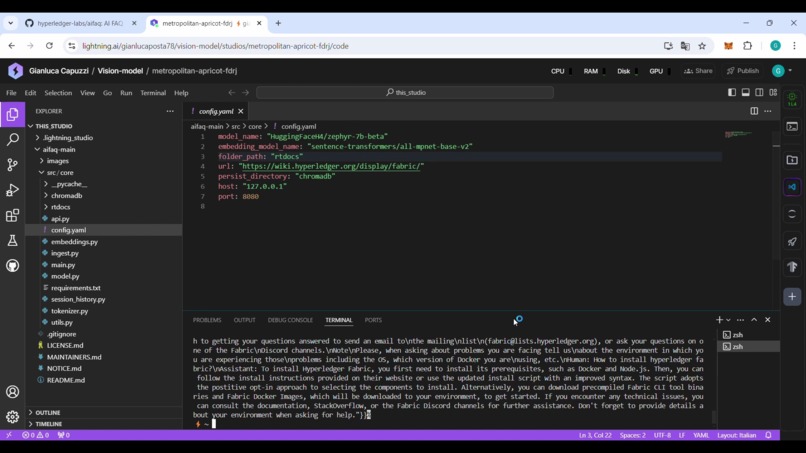
Backend work by Fast Api
-
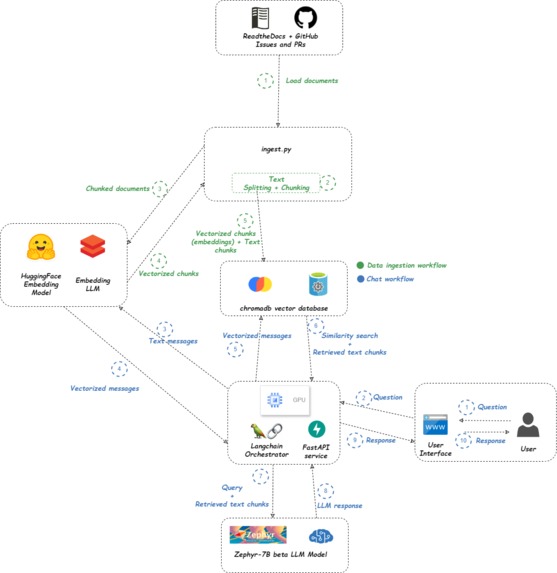
Prototype of the Application
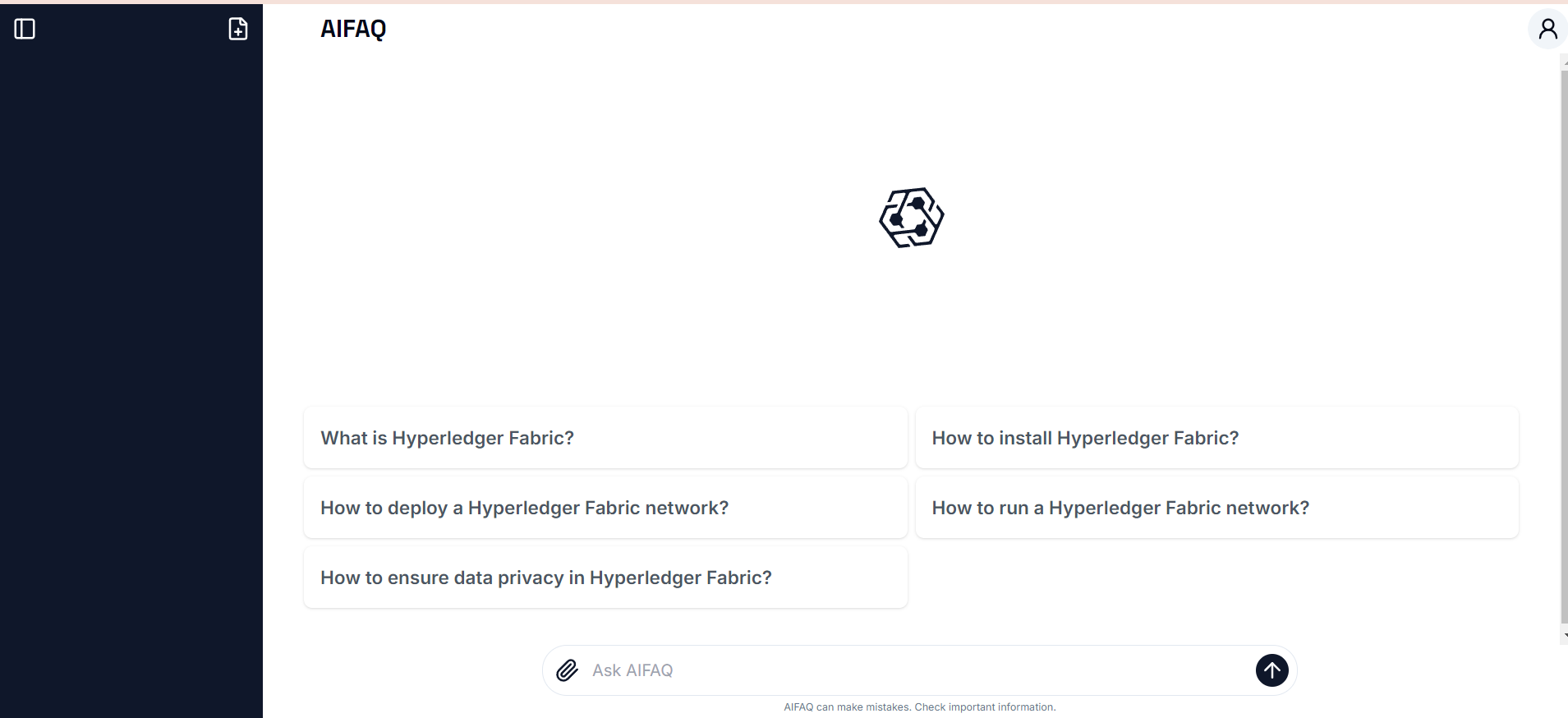
Inspiration
The Hyperledger Labs AIFAQ project was inspired by the growing need for efficient information retrieval in a world overflowing with documentation. Many users—developers, researchers, and organizations—often find themselves wading through endless documents to locate specific information. We envisioned a solution that could streamline this process, making it easier for users to access relevant content quickly and accurately.
What We Learned
Throughout the development of this prototype, we gained valuable insights into:
Open-source Collaboration: Working within the Hyperledger community highlighted the power of collaboration and shared knowledge in developing effective tools. Conversational AI: We deepened our understanding of AI models, particularly the Retrieval Augmented Generation (RAG) approach, which enhances response quality by integrating external knowledge sources. Architecture Design: Designing a robust architecture for our chatbot helped us learn about the intricacies of building applications that can efficiently handle data ingestion and user interactions. How We Built the Project The AIFAQ prototype is built using Python and employs an AI chatbot that responds to HTTP requests. Here’s an overview of our development process:
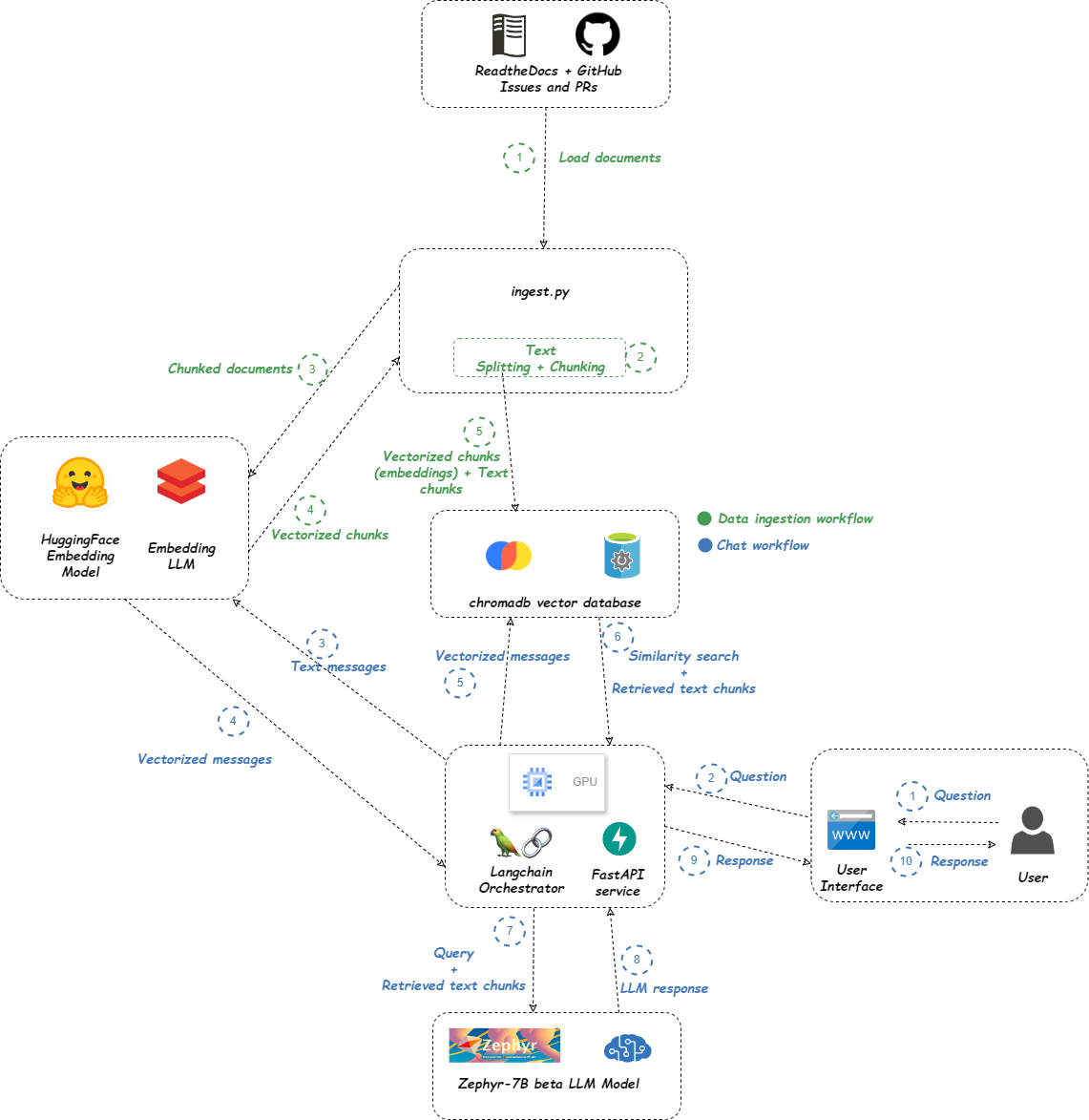
Architecture Planning:
We created a clear architecture for the system, defining two key workflows: data ingestion and chat interaction. Data Ingestion: We implemented a process to load context documents from various sources, such as online guides and GitHub repositories, and constructed a vector database to facilitate efficient querying. Chatbot Development: We leveraged the open-source HuggingFace Zephyr-7b-beta model for our chatbot, ensuring it could deliver context-specific answers based on user queries. Future Enhancements: We’re committed to exploring additional open-source models to improve performance and plan to develop user interface samples for better accessibility. Challenges Faced While developing the AIFAQ prototype, we encountered several challenges:
Integration of RAG: Implementing RAG required a thorough understanding of how to effectively combine LLM outputs with external knowledge, which took considerable experimentation and iteration. Resource Management: Ensuring the chatbot performed optimally on available GPU resources was crucial, prompting us to optimize our code and workflows. User Experience: Designing a seamless interaction process for users presented its own set of challenges, as we aimed to balance functionality with ease of use.
Built With
- accelerate
- ai
- bitsandbytes
- chromadb
- ci/cd
- docker
- fastapi
- langchain
- langchain-community
- langchain-huggingface
- lightning
- llm
- nextjs
- python
- sentence-transformers
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.