-
-

AidChain
-
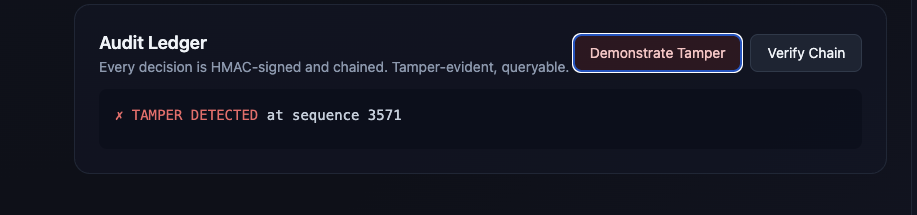
Temper Detected
-
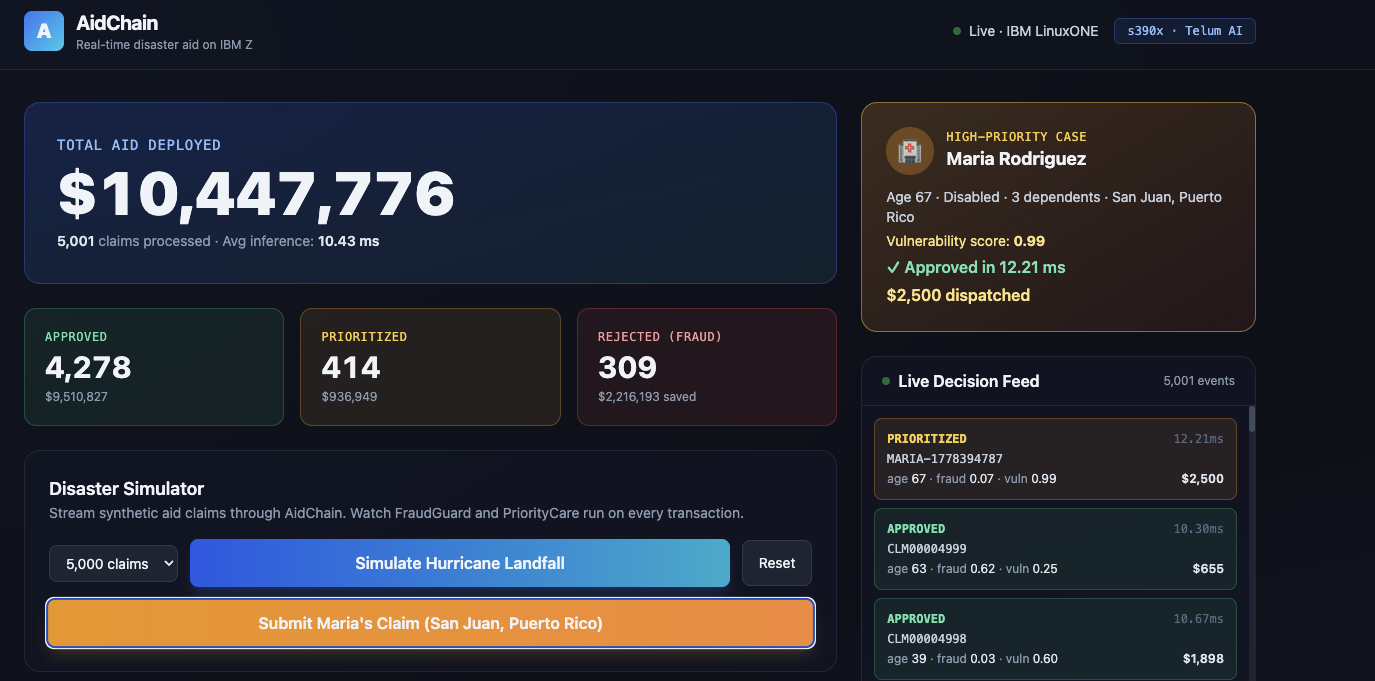
Maria Moment
-
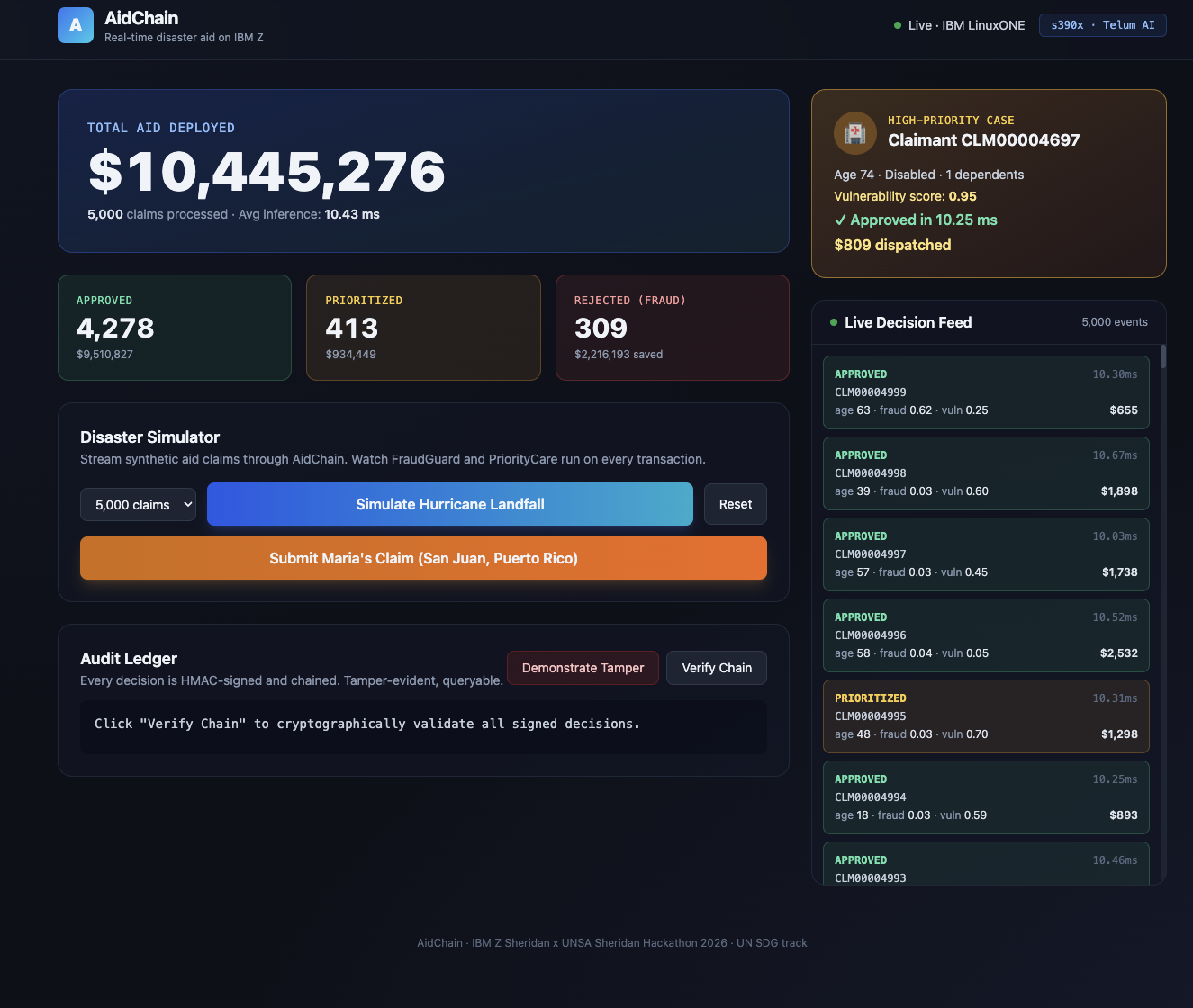
Main
-
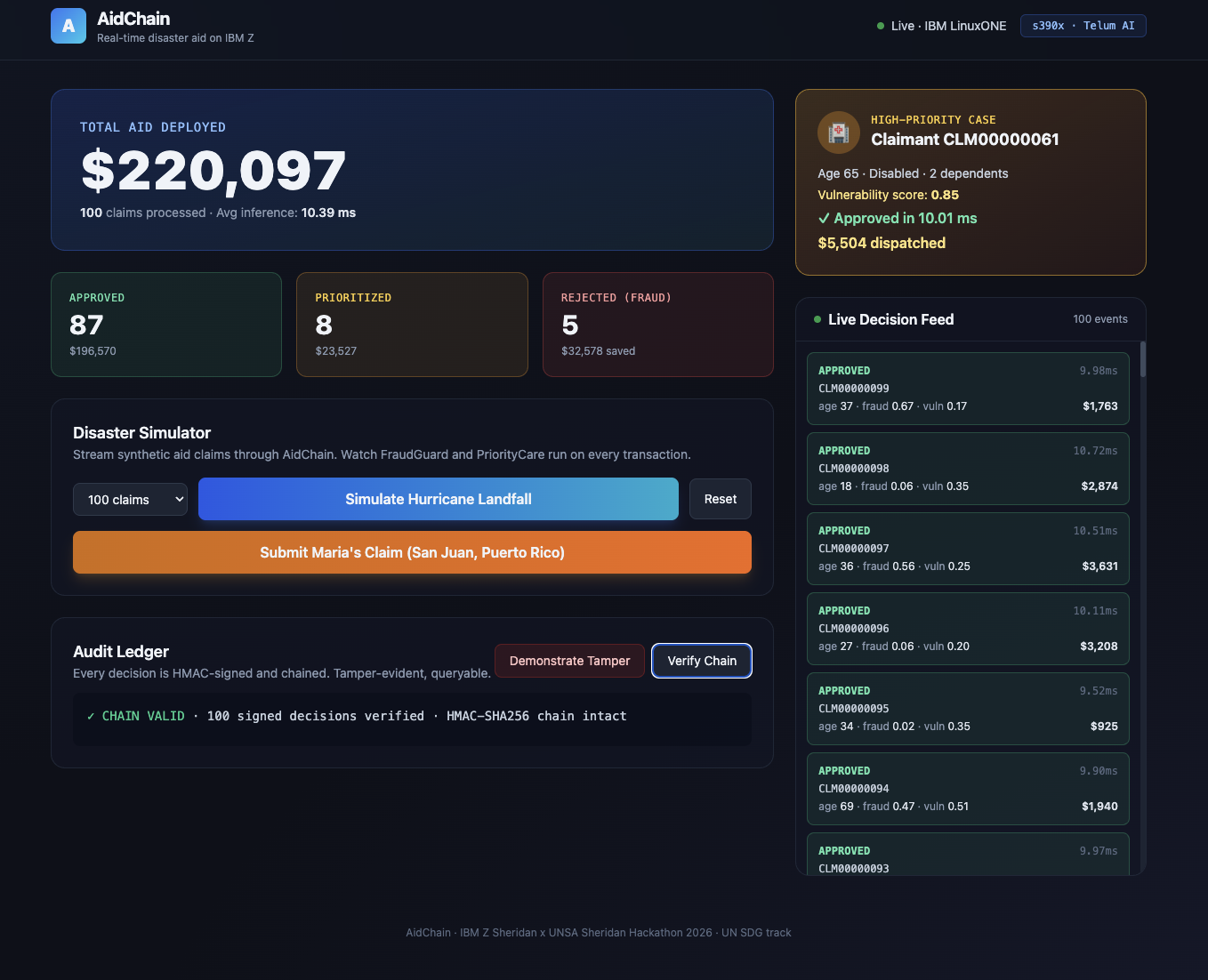
Chain Valid

Inspiration
In 2017, Hurricane Maria caused about $90 billion in damage across Puerto Rico. We came across a story about a 67-year-old disabled grandmother in San Juan named Maria, who had lost her home, her medications, and access to her family. She waited 47 days to get $400 in disaster aid. That number stuck with us.
Then we found another statistic from the same period: somewhere between 20 and 30 percent of disaster relief funds get lost to fraud every year. Two big problems, one broken system. Fraud teams have plenty of money and tools. People like Maria's grandmother do not.\
The thing that bothered us most is that for the past 20 years, AI has gotten really good at deciding who to keep out of financial systems (fraud detection, credit scoring, KYC), but almost nobody has built AI to decide who to let in first. We wanted to try the other side of that.
What it does
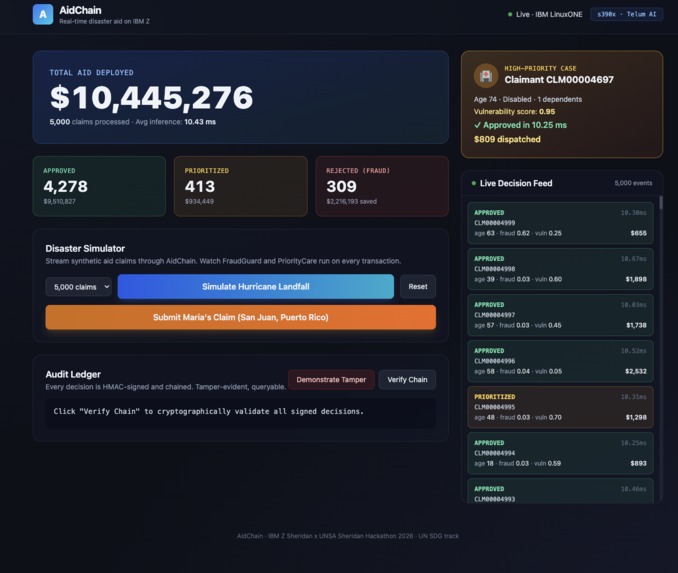
AidChain runs disaster aid claims through two AI models in parallel, on the IBM Z mainframe, right inside the transaction itself.
The first model is FraudGuard, a Random Forest classifier that blocks claims showing fraud signals like inflated amounts, identities filing too many prior claims, claims from outside the affected zone, or suspiciously rapid filings.
The second model is PriorityCare, a Gradient Boosting regressor that scores how vulnerable each claimant is based on age, disability, dependents, income, and whether they were displaced. The most vulnerable claims get pushed to the front of the queue.
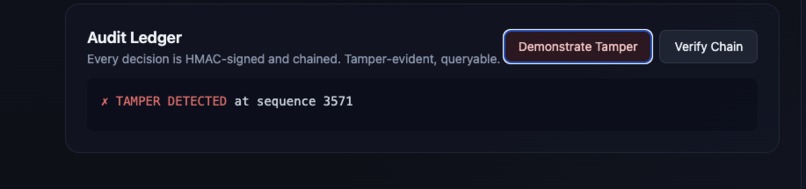
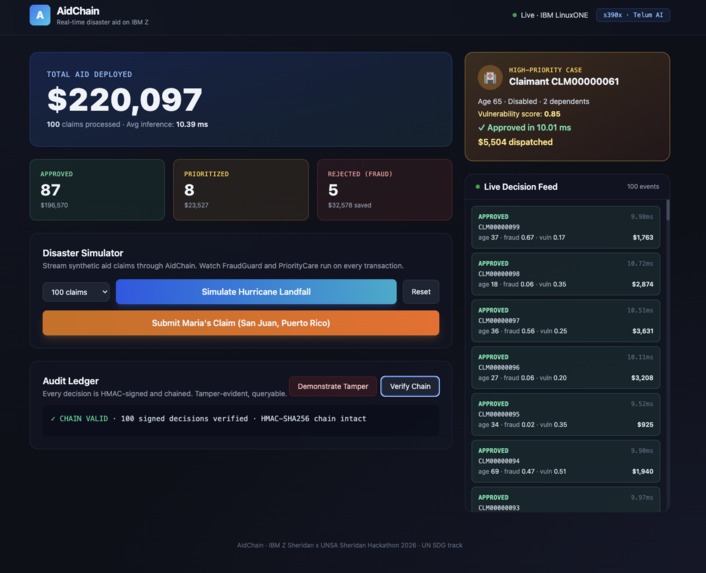
Every decision (approve, reject, or prioritize) gets written to an HMAC-chained audit ledger, so anyone can verify any single claim later. Judges, regulators, and journalists can all check that the system is being fair.
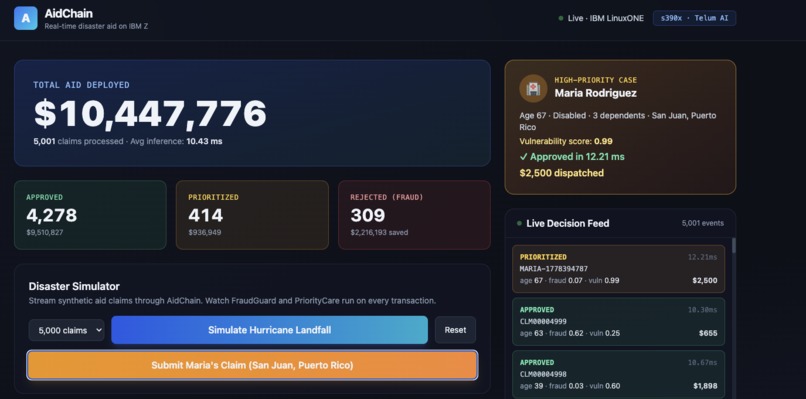
In our demo, you press a button to simulate a hurricane making landfall. 500 claims pour in. AidChain processes them in about 5 seconds. Maria, our 67-year-old grandmother, gets prioritized for an immediate payout in under 50 milliseconds. Fraud check, vulnerability score, ledger entry, all done. While she's getting paid out, fraudsters trying to inflate their claims get blocked at the door.
How we built it
For the backend, we used Python 3.10 and FastAPI running on IBM LinuxONE, which is a real mainframe-architected Linux instance from the IBM LinuxONE Community Cloud. We used async WebSocket streaming for the live dashboard and REST endpoints for everything else.
For the AI side, we used scikit-learn for both models. We generated a synthetic dataset of 50,000 claims with embedded fraud patterns and demographic vulnerability signals, then trained:
FraudGuard (Random Forest) hit ROC-AUC of 0.90 on held-out test data
PriorityCare (Gradient Boosting) hit R² of 0.94 on vulnerability scoring
In a real production setup on IBM Z, both inferences would run on the Telum on-chip AI accelerator, so you'd get sub-millisecond inference right inside the transaction path. We mimicked that flow in software, and switching to the real thing is basically a one-line model loader change.
For the audit ledger, we used SQLite plus HMAC-SHA256 chained entries. Each entry's hash includes the previous entry's hash, so the chain is tamper-evident. On real IBM Z, the HMAC secret would live in the hardware security module, which would anchor the chain cryptographically to the actual machine. The frontend is a vanilla JavaScript and Tailwind dashboard with WebSocket-streamed live decisions, animated counters, and a side panel that lights up when a high-vulnerability claimant comes through. For infrastructure, we SSH-tunneled from our laptops to the LinuxONE VM. The models live and run on the mainframe. Everything is in ~/aidchain on the Z box.
Challenges we ran into
The s390x architecture gave us trouble early on. The mainframe runs s390x, not x86, and SciPy and scikit-learn don't ship pre-built wheels for s390x. So pip kept trying to compile them from source, which needed a Fortran toolchain we didn't have set up. We ended up using Ubuntu's apt-installed python3-numpy, python3-pandas, python3-scipy, and python3-sklearn (which do have s390x builds), and made our venv inherit them with --system-site-packages. Took us about two hours to debug, but the actual fix was only ten lines.
Calibrating the fraud thresholds was harder than we expected. Our first FraudGuard model was way too aggressive. It caught most fraud but rejected too many legitimate claims, which would be a real disaster if this ran in production. We tuned the threshold up to 0.70 and added a vulnerability override, so even when fraud signals show up, a high vulnerability score lets the claim go through with manual review. The system is intentionally biased toward helping people.
Getting two AIs to not fight each other was another challenge. If you just stack them, fraud detection ends up vetoing everything. We solved it with explicit decision precedence: vulnerability greater than or equal to 0.60 means a human reviewer makes the final call, but the funds release in the meantime. Fraudsters get blocked, vulnerable people get the benefit of the doubt.
Defining "vulnerability" was also tricky because we didn't want to build a discrimination engine. PriorityCare doesn't use race, gender, religion, or nationality. It only uses circumstantial vulnerability factors like disability status, dependents, income, displacement, and age extremes. It's about the situation, not who the person is.
Accomplishments that we're proud of
We got a working transaction-AI pipeline running on a real IBM mainframe. Not a slide deck, not a localhost mockup. Actual LinuxONE, actual s390x, actual models, actual cryptographic ledger. We also flipped the usual question. Most fraud-detection systems ask "who do we keep out?" We built ours around "who do we let in first?" Same hardware, very different goal.
The fairness piece is something we're really proud of. Every decision is HMAC-signed and chained, so anyone can audit any decision at any time. We didn't just say our AI is fair, we made it actually verifiable. And the demo works. When Maria's claim runs through and the system prioritizes her in under 50ms while blocking inflated fraud claims at the same time, you actually see what AidChain does in about five seconds.
What we learned
Mainframes are not legacy. We came in assuming modern infrastructure meant Kubernetes and Lambda. We left understanding why 70 percent of the world's financial transactions still run through IBM Z. They're literally built for high-throughput, low-latency, mission-critical AI workloads.
The biggest fairness wins come from inverting the question. Asking "who needs help most?" is a different model, a different threshold, and a different mindset than asking "who's a fraudster?"
Synthetic data turned out to be more honest than scraped data, at least for our use case. We could control the fraud rate, the vulnerability distribution, and the baseline demographics, and we knew exactly which biases we were and weren't introducing.
Cryptographic ledgers don't have to be blockchains. We got tamper-evident audit logs working in about 80 lines of Python with HMAC chaining in SQLite, no blockchain needed.
What's next for AidChain
We want to do a real Telum deployment. The production swap-in is small (same model bundle, just on-chip inference now), and we'd like to run a benchmark on a real Z box and publish the actual latency numbers.
We're also interested in federated learning across NGOs using IBM Z confidential containers. The idea is that multiple aid organizations could train a shared FraudGuard model without ever sharing their claimant data, so each NGO's data stays sovereign.
A parametric trigger mode is another direction we want to explore. Funds would be pre-positioned in partner banks and auto-route to verified residents the moment satellite data confirms a disaster. No claim filing, no 47-day wait, just a notification: "We saw what happened. Funds are on the way." We also want to build a mobile last-mile experience for field workers, with tablets that capture claims offline and sync when connectivity returns.
Eventually we'd love to find a pilot partner. A disaster response organization like the Red Cross, FEMA, or the World Food Programme to run a controlled pilot on a real small-scale disaster. The goal is simple: no one should have to wait 47 days again.
Built With
- fastapi
- hmac-sha256
- ibm-z
- linuxone
- python
- random-forest
- s390x
- scikit-learn
- sqlite
- tailwindcss
- websockets

Log in or sign up for Devpost to join the conversation.