-
-
AICO Eco Dashboard - displaying environmental metrics
-
Interface for prompt optimization
Inspiration As AI tools like ChatGPT, Claude, and Gemini become part of everyday workflows, most users don't think twice about how they phrase their prompts — or what it costs. We started thinking about the hidden toll of AI usage: every token sent to a model consumes electricity, water, and emits CO₂. Poorly written prompts don't just get worse results, they silently waste resources at scale. We wanted to build something that made prompt quality tangible and gave users a reason to care.
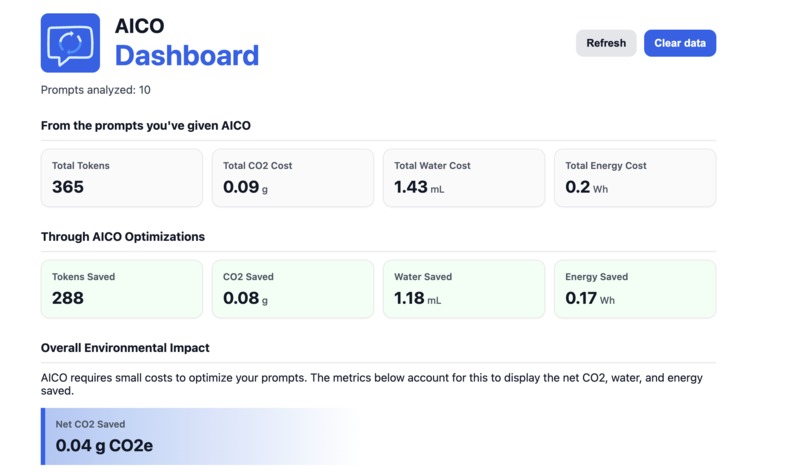
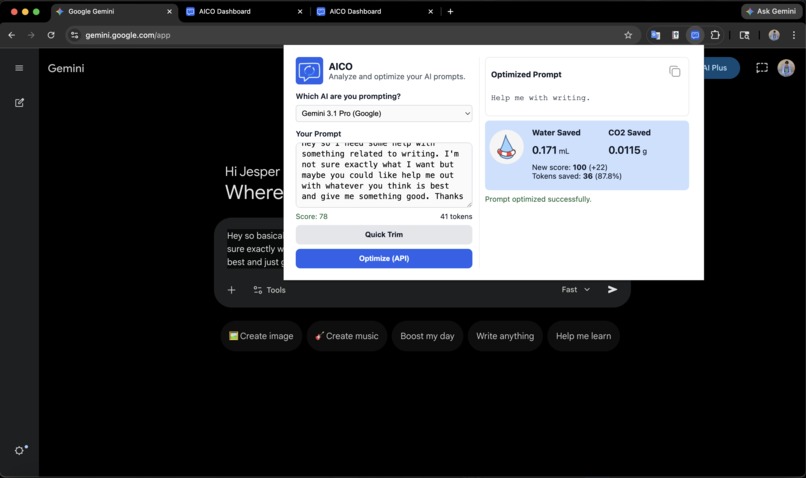
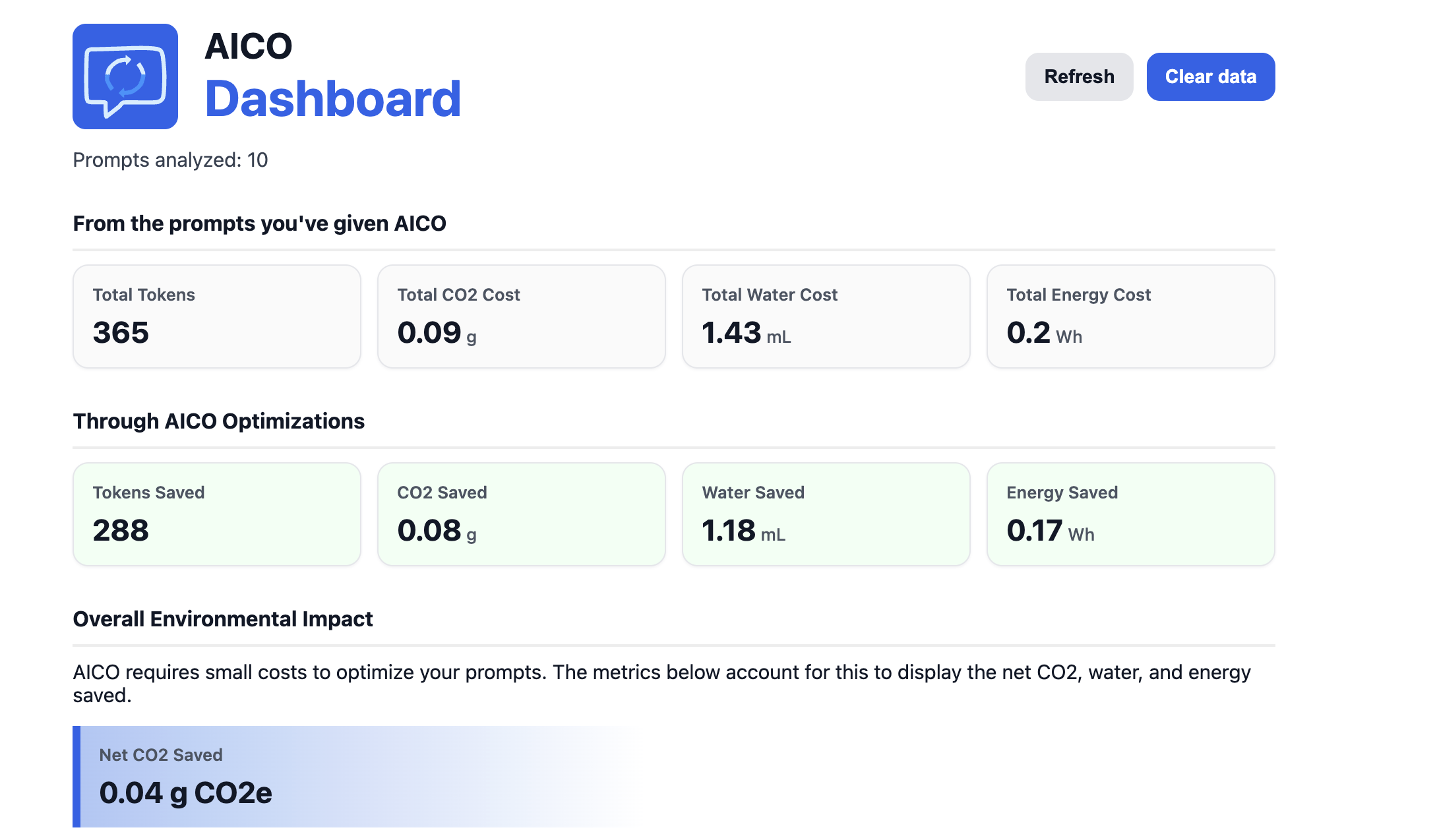
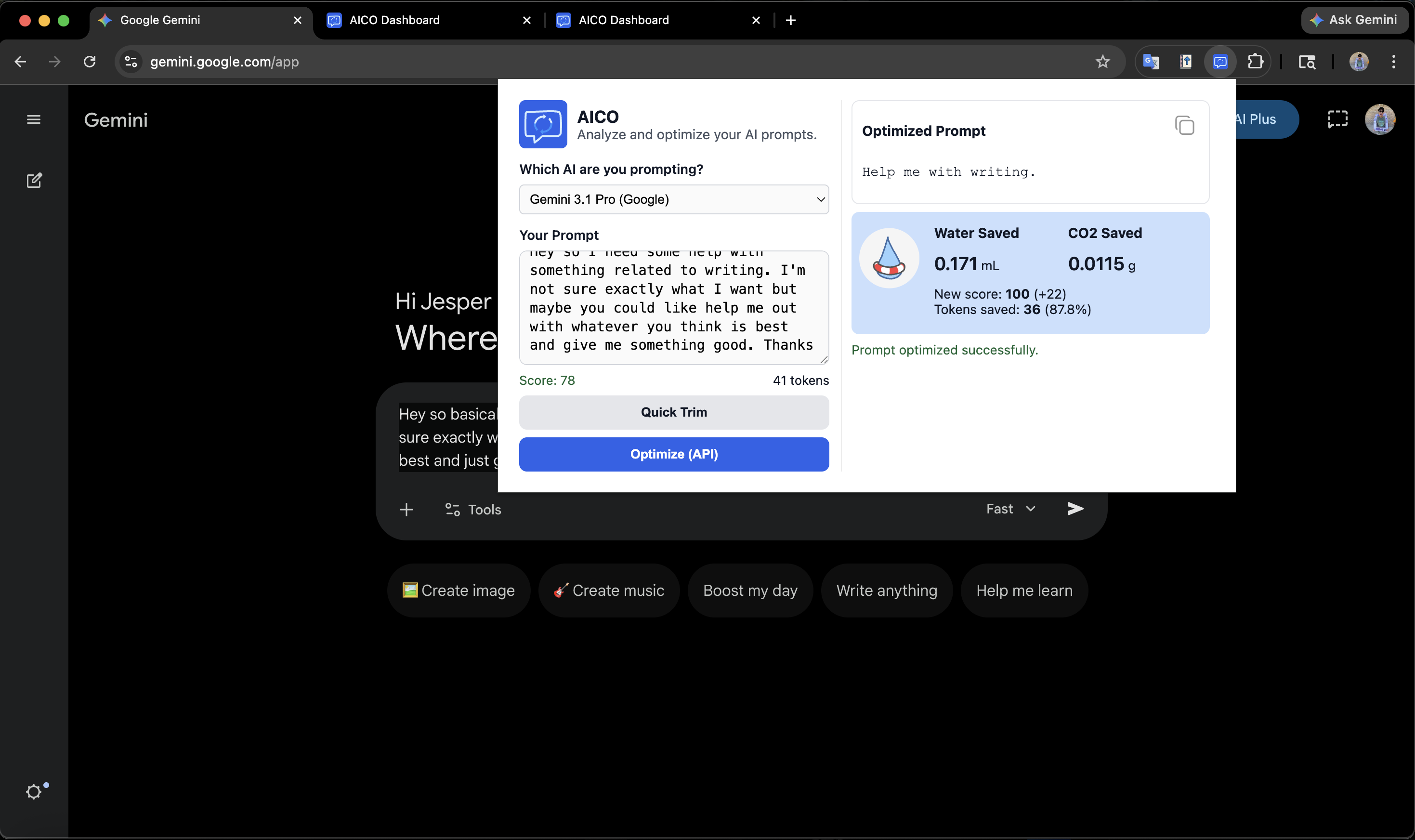
What it does AICO (AI Conversation Optimizer) is a Chrome extension that analyzes and optimizes your AI prompts before you send them. Paste in a prompt and AICO scores it for efficiency by detecting filler words, vagueness, repetition, structural weaknesses, and contradictions. Hit Optimize and it rewrites the prompt using Google's Gemini API. You then see a side-by-side comparison: tokens saved, efficiency gained, and the real-world environmental impact of water usage, CO₂ emissions, and energy consumed based on which AI model you're prompting. A built-in dashboard tracks your cumulative savings over time.
How we built it AICO is a Manifest V3 Chrome extension built with React, TypeScript, and Vite, bundled using the CRXJS plugin. The prompt analysis engine uses compromise for NLP (filler and vagueness detection, part-of-speech tagging) and js-tiktoken for accurate OpenAI-compatible token counting. Environmental and cost metrics are calculated per-model using sourced benchmarks from carbon-llm.com and industry estimates. The Gemini API handles optimization. Chrome's local and sync storage APIs persist history and user preferences across sessions. Recharts powers the dashboard visualizations.
Challenges we ran into Scoring prompt quality is genuinely hard. Simple regex catches obvious cases, but detecting nuanced vagueness or adversarial repetition required tuning NLP rules with calibrated weights. We also had to source per-model environmental data that isn't publicly standardized, so many numbers are proxied from the closest available benchmarks. Getting the Chrome extension architecture right across popup, options page, dashboard, service worker, and shared storage required careful coordination.
Accomplishments that we're proud of We built a prompt scoring algorithm that's genuinely critical: it uses NLP to flag structural gaps (missing context, no output format, undefined audience), catches contradictions like "be concise but very detailed," and detects burst repetition patterns. The per-model breakdown showing that GPT-4o, Claude 3.7, and Llama 4 have meaningfully different environmental footprints makes something abstract feel concrete. The dashboard turning individual saves into cumulative impact numbers was a satisfying moment.
What we learned Prompt engineering is harder to evaluate objectively than it sounds. We learned a lot about Chrome's Manifest V3 constraints (service workers, storage sync limits, CSP rules) and how to build a multi-page extension that feels cohesive. We also deepened our understanding of AI inference costs. The environmental data was eye-opening, and not in the direction we expected: cheaper models aren't always greener.
What's next for AICO Right-click to optimize any selected text on any page (context menu integration is already scaffolded). Support for more models as benchmarks improve. A more granular scoring breakdown so users can see exactly why a prompt scored the way it did. We'd also like to explore local inference support, which involves running a small model on-device to optimize prompts without any network cost at all.
Built With
- claude
- codex
- figma
- gemini
- gemma
- typescript
- vite

Log in or sign up for Devpost to join the conversation.