-
-
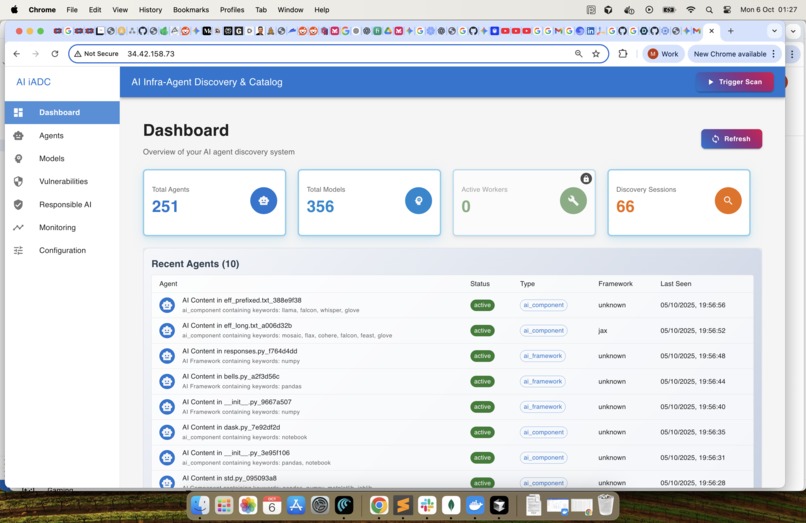
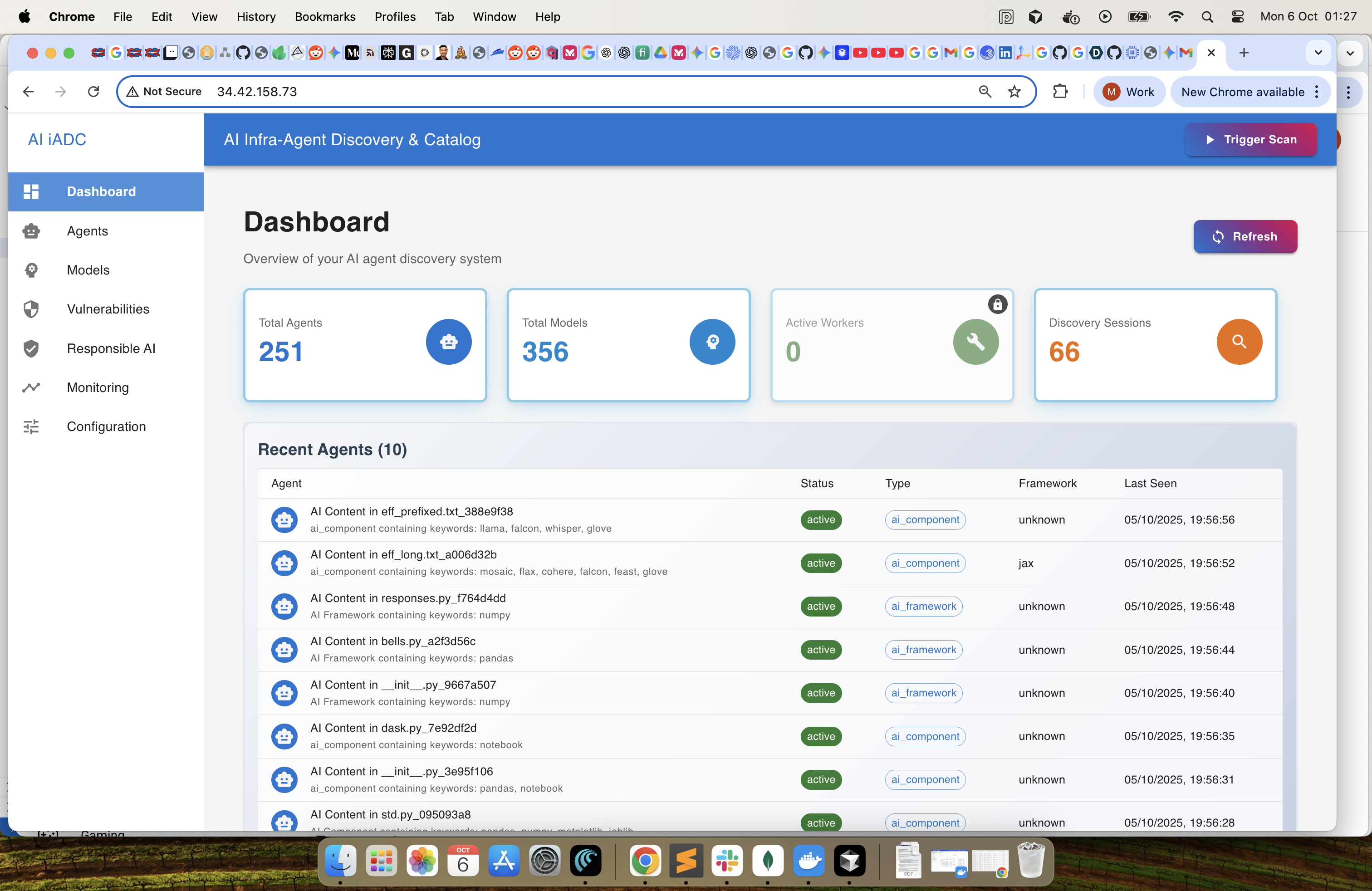
Dashboard Page - Summary Dashboard for Agents and Models. The responsible AI section to be added in future
-
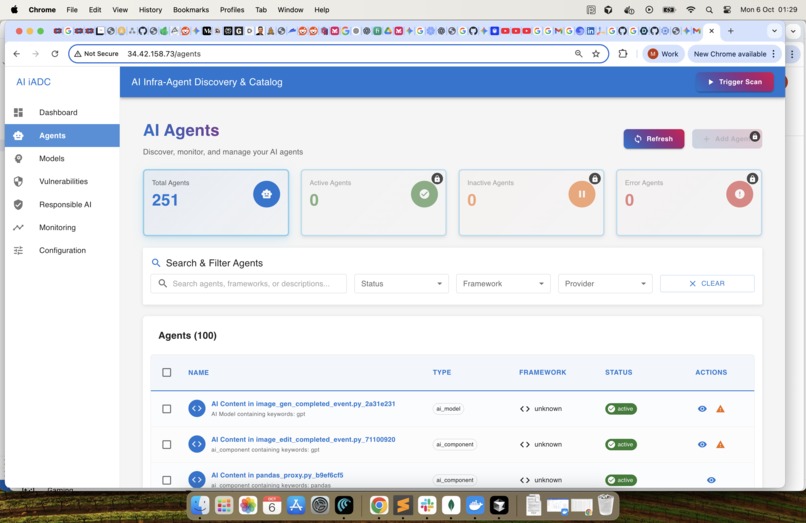
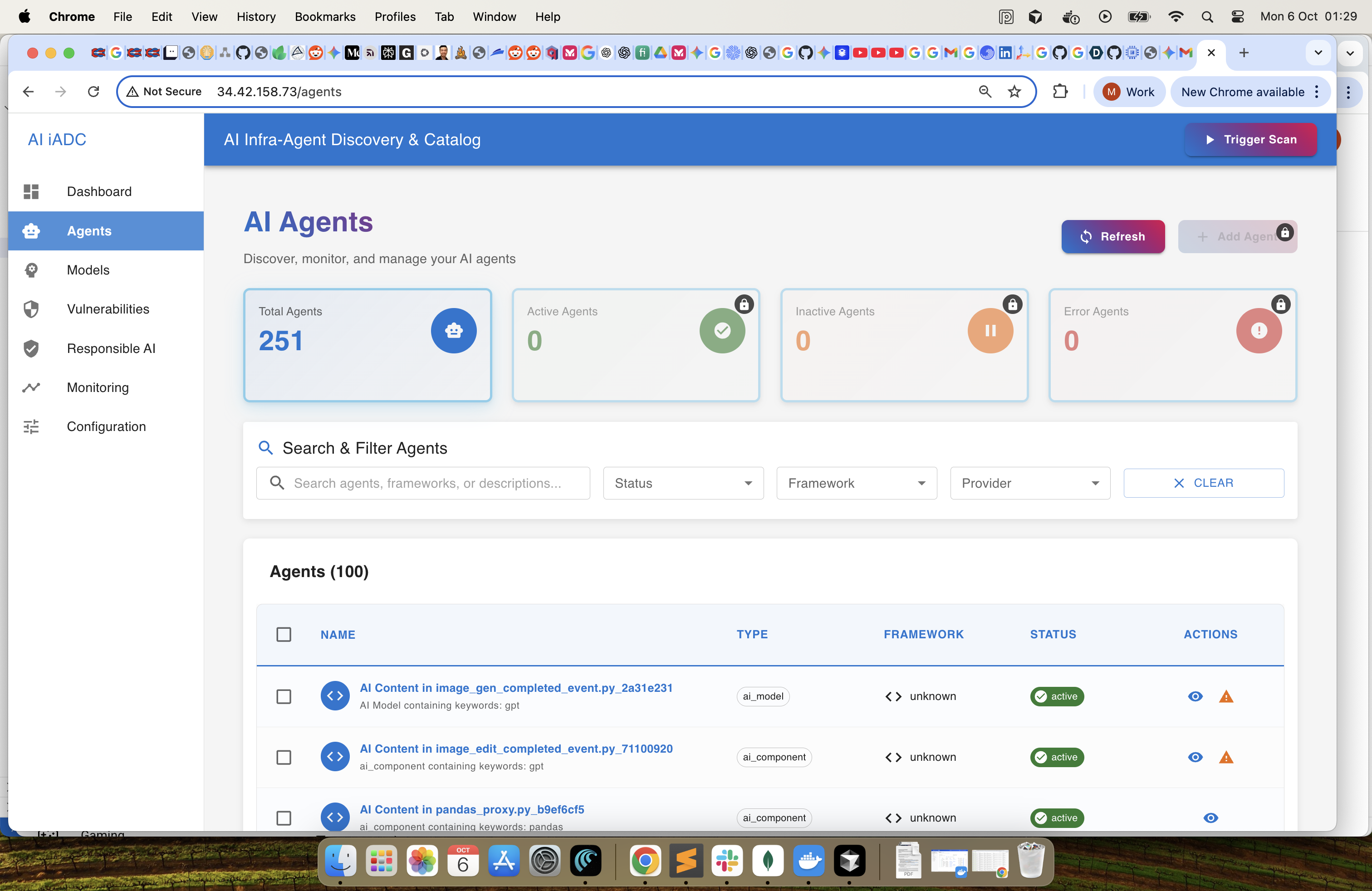
Agents : List the identified agents. In future we will add the exception flow for a user to manually accept or reject an agent
-
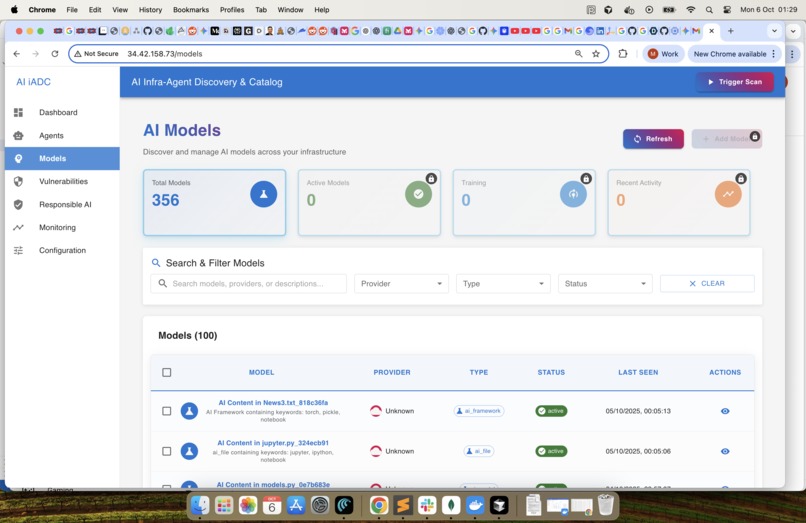
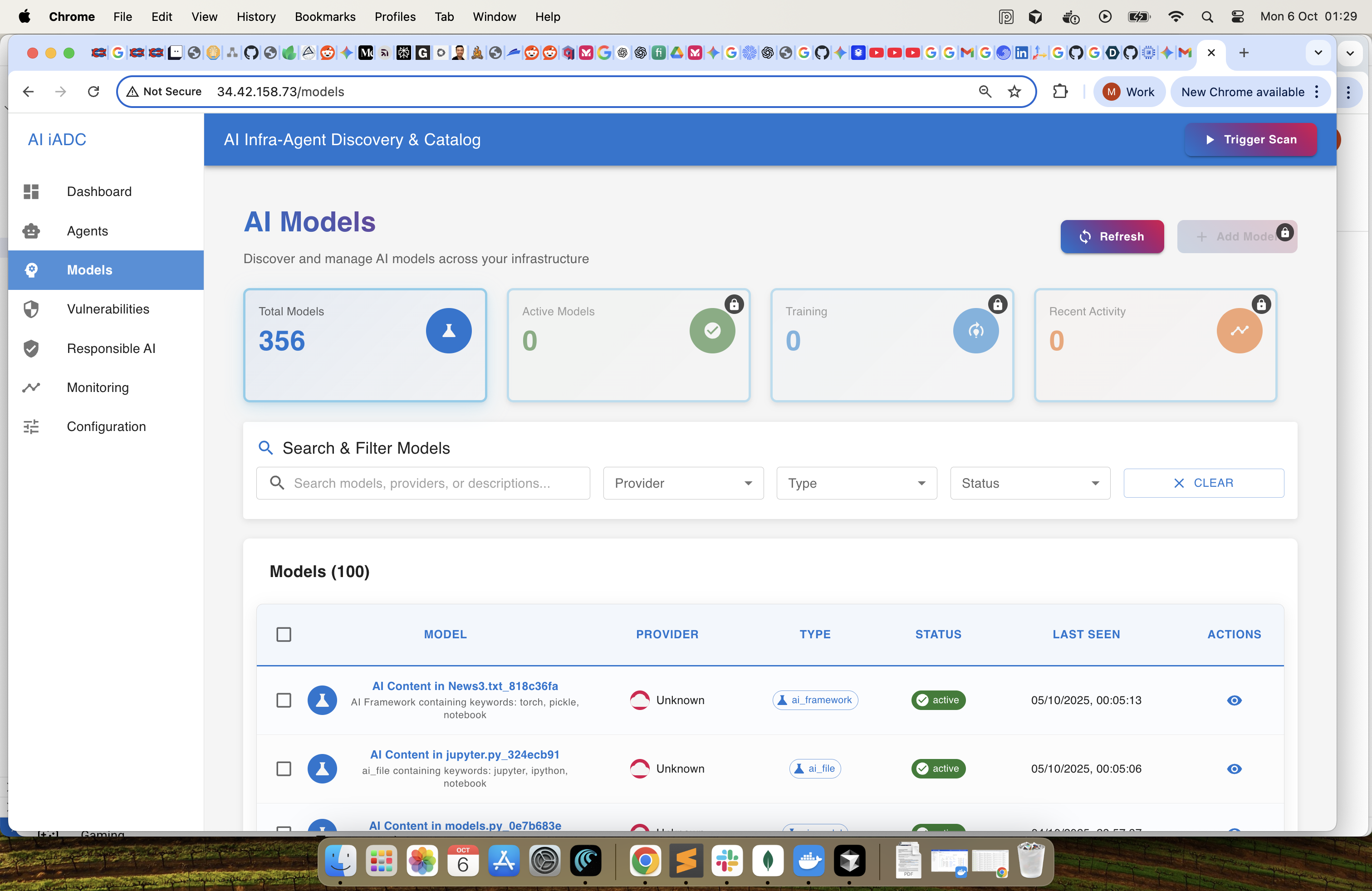
Models : List the identified Models. In future we will add the exception flow for a user to manually accept or reject an Model
-
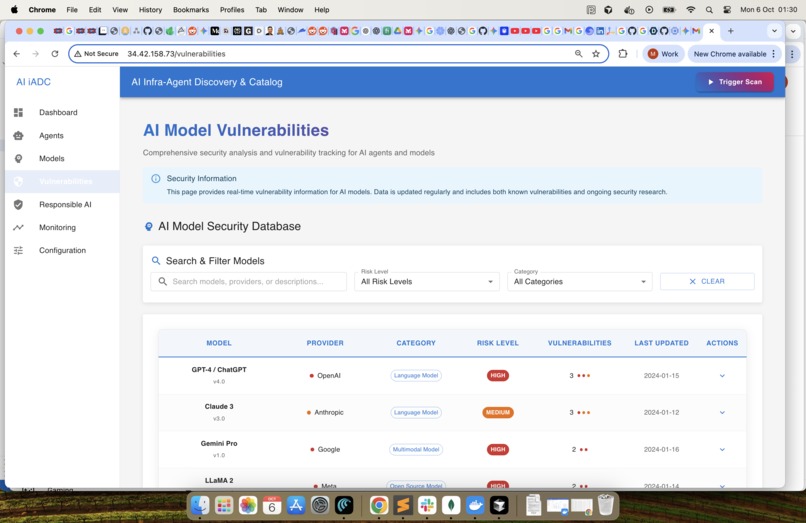
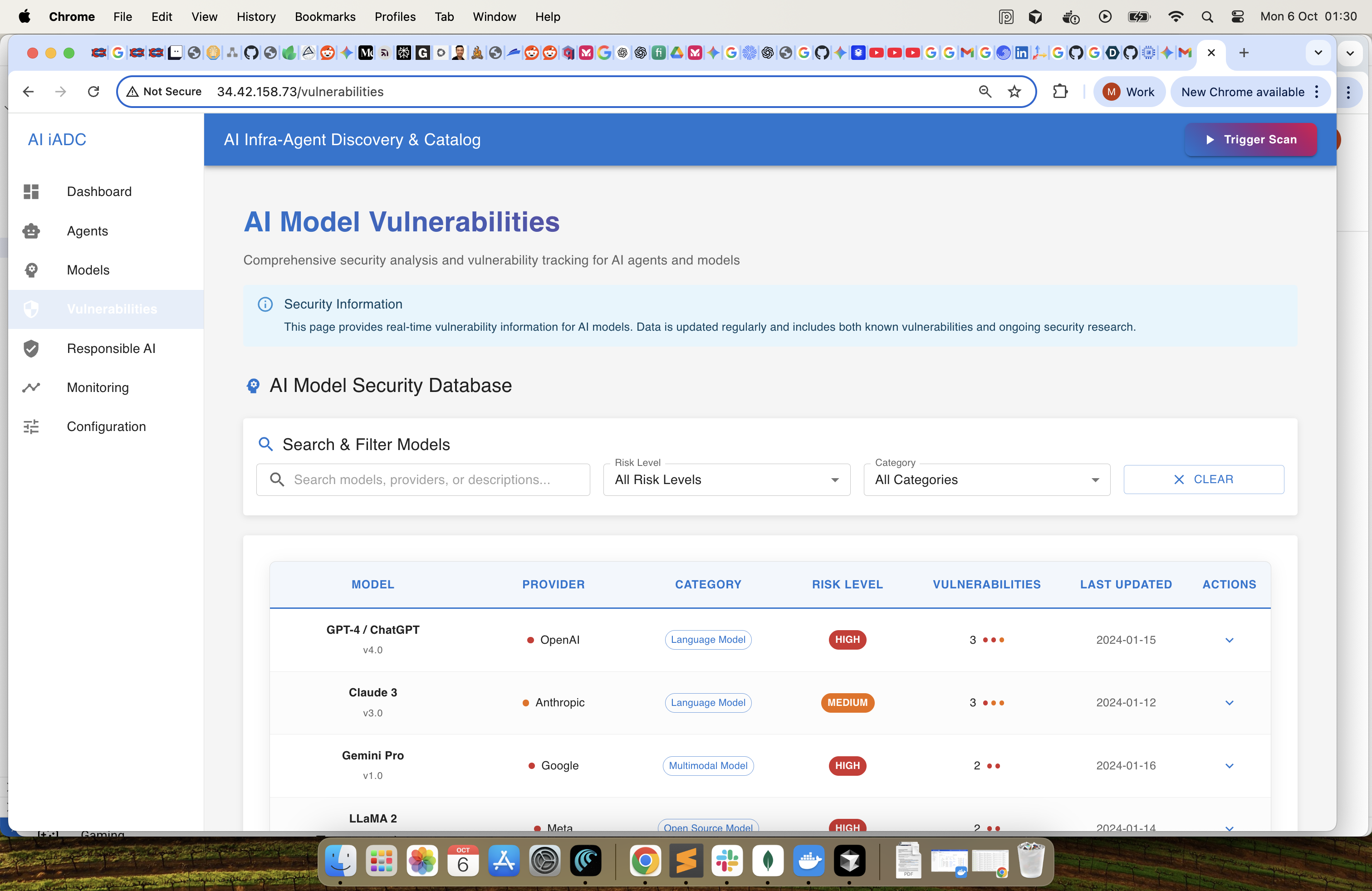
Vulnerabilities : Publicly searchable vulnerabilities from the security databases
-
Responsible AI : Coming Soon
-
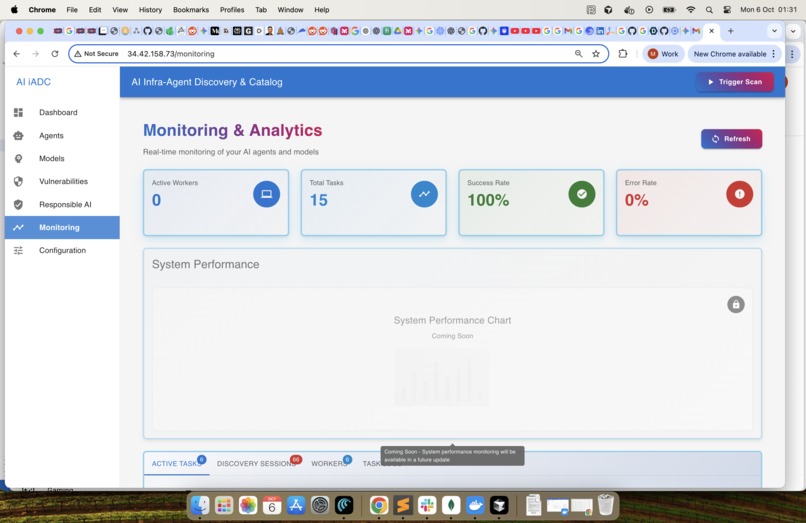
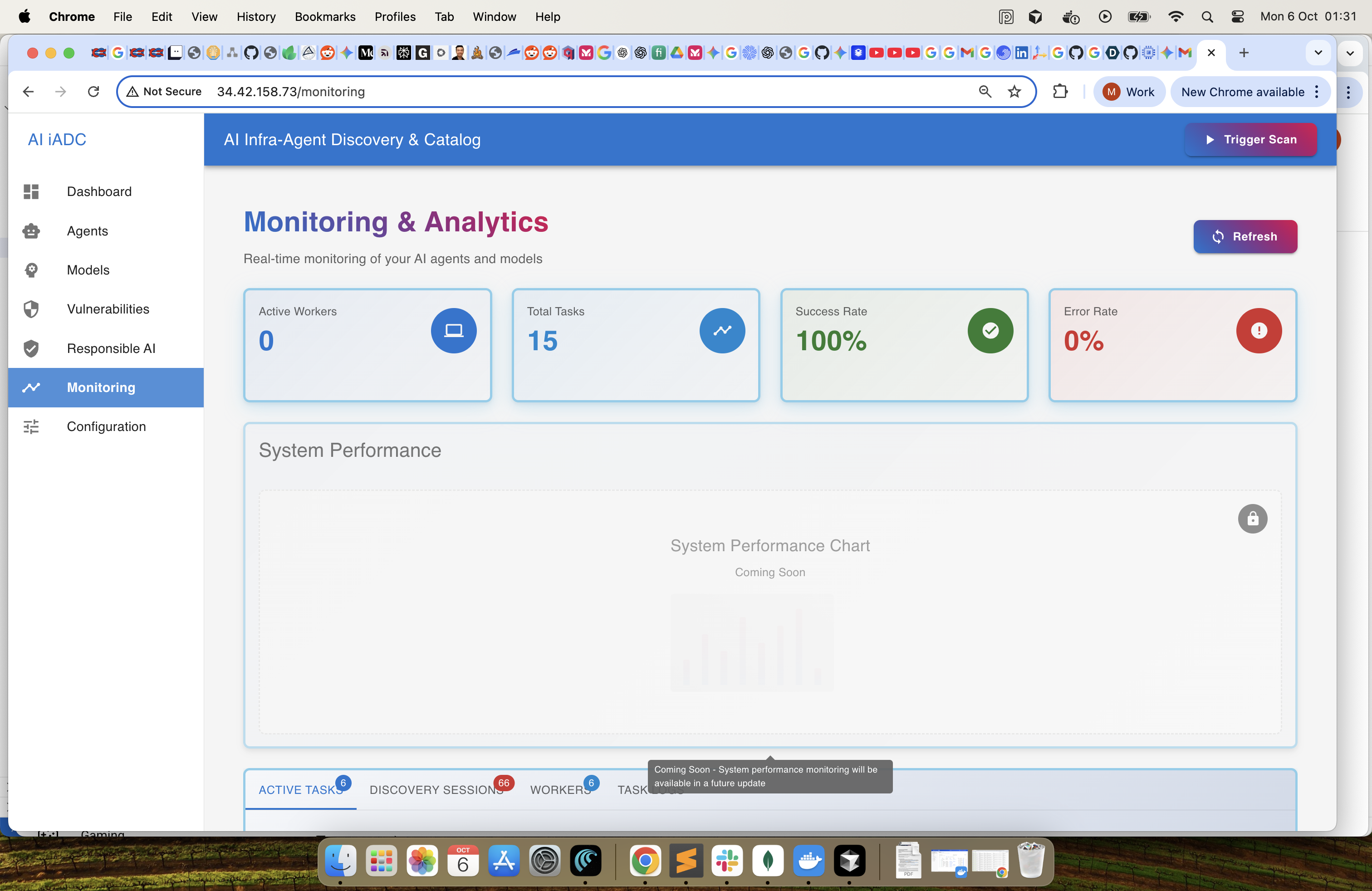
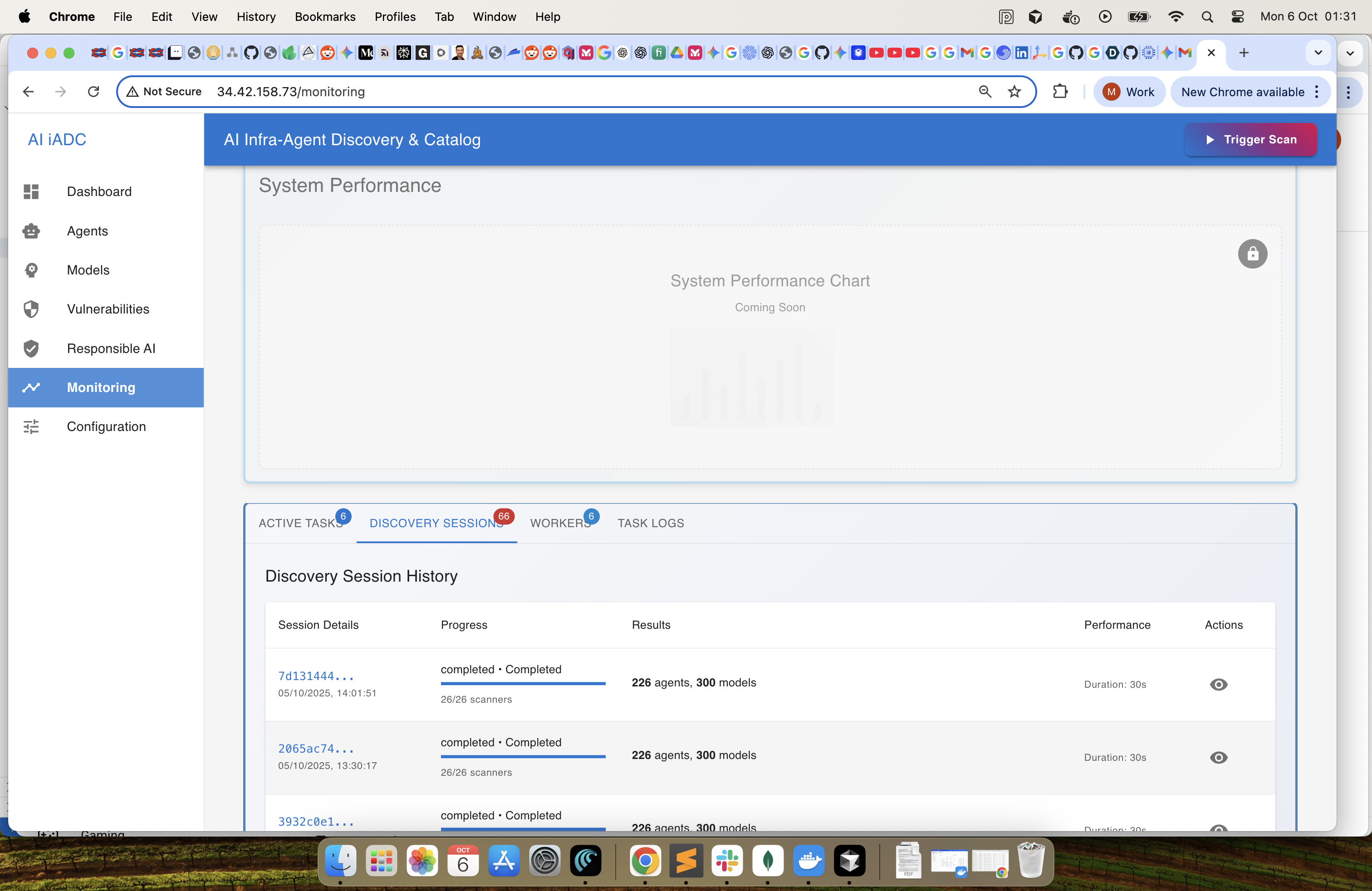
Monitoring & Analytics -1 : Monitor the system performance
-
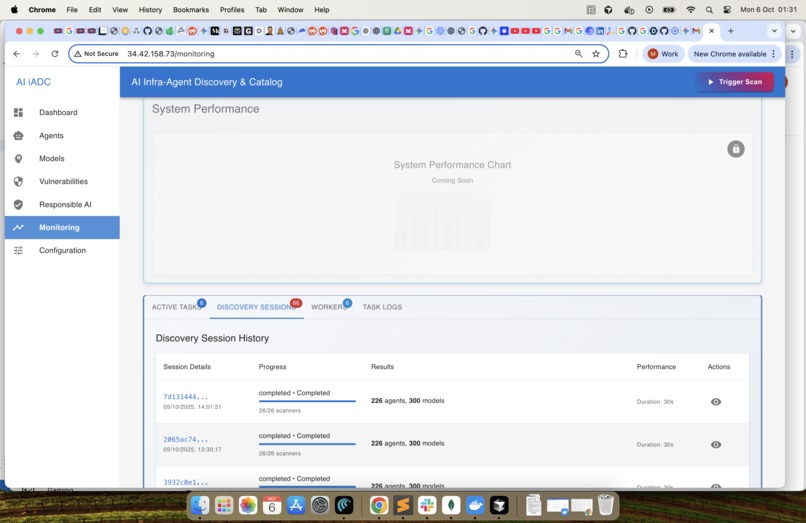
Monitoring & Analytics -2 : Monitor the system performance
-
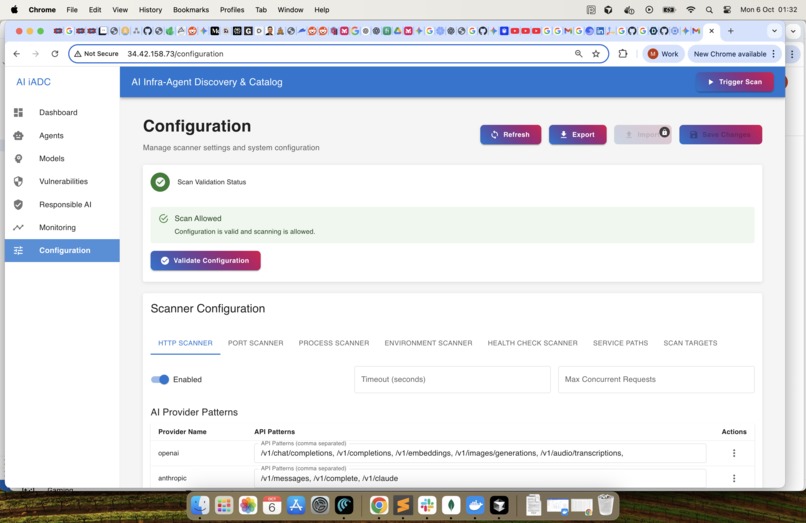
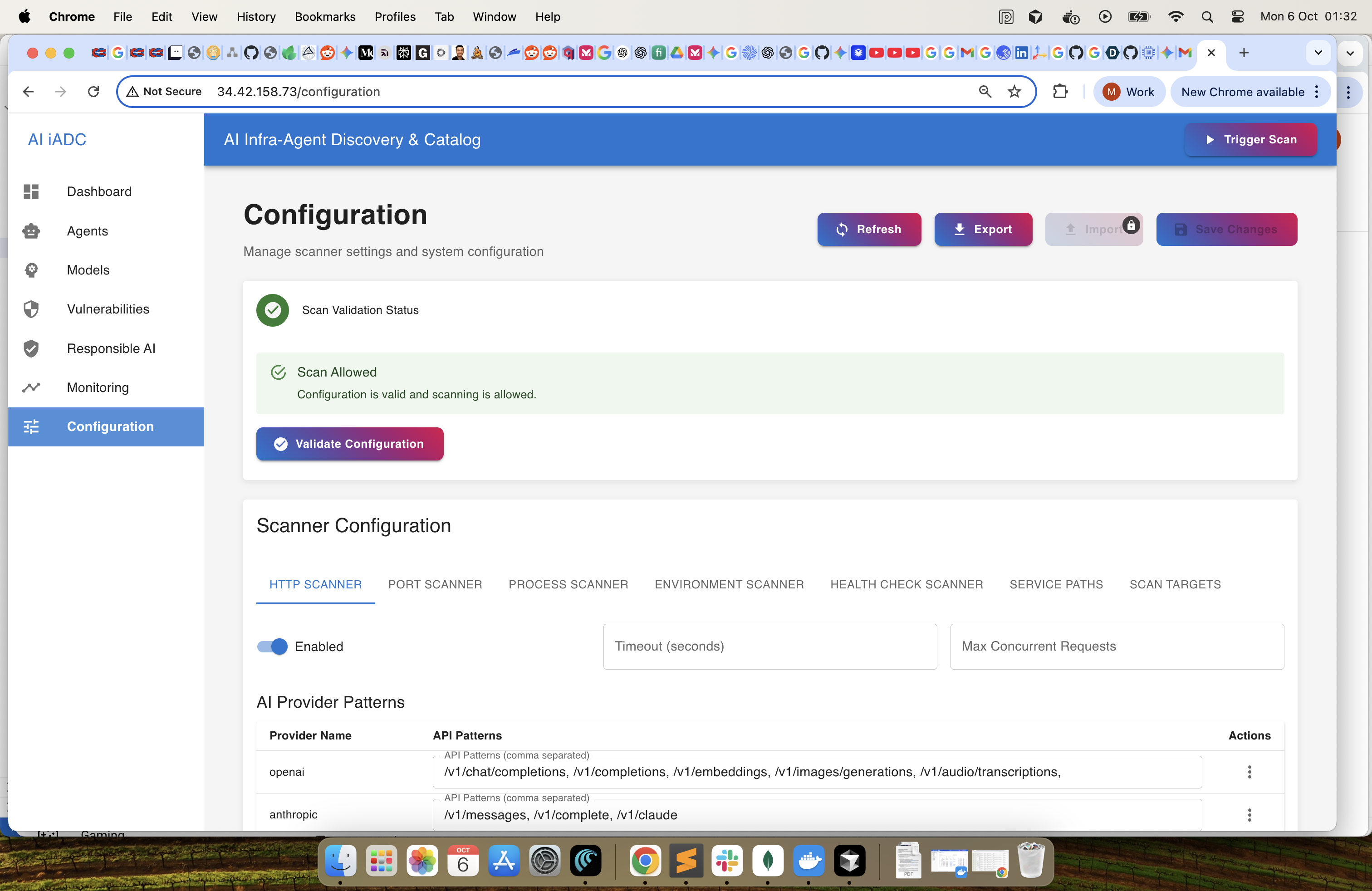
Configuration : Continue to learn and optimise the configuration to identify Agents and Models
What Inspired Me: The speed of autonomous AI adoption sometimes feels like a transformation. Individual now has power of an entire team and the outcome and outcomes produced by single developer is humongous. However, while development is moving super fast, monitoring the infrastructure is unseen and unsecured. My inspiration was simple: we must give organizations the ability to truly see and secure these critical AI assets. This tool isn't just inventory; it’s a foundational step to ensuring visibility, trust, and responsible governance in the age of invisible, autonomous code, ensuring every decision an agent makes is auditable and compliant.
What I Learned: The most critical discovery was the lack of tools that we assume to just exist in this new domain and paradigm. AI agents don't follow standard definitions, forcing us to realize that AI must be used to find AI. This led to our core architectural insight: leveraging the inference power of an LLM—our "AI stack analyst"—to look at configuration context, dependencies, and network chatter to definitively answer: Is this running code an AI model?
How I Built It: We engineered a self-contained, lightweight administrative agent. It begins with a rapid Infrastructure Scanner that harvests metadata. When an artifact is unknown, we structure its context (dependencies, environment variables) and send it to our Inference Pipeline. Here, we evaluated and smarty deployed LLM that analyzes the data, classifies the AI agent, and determines its function. All findings are pushed to a unified catalog, instantly providing both the granular security view needed by admins and the intuitive overview required by managers.
Challenges Faced: The deepest technical challenge wasn't just finding agents, but the fundamental lack of standards. Today, AI agents are opaque black boxes; they don't come with a standardised manifest or file that clearly states what model they are, what data they use, or their version number. This standardisation gap means our discovery tool had to operate with zero prior knowledge. Our clear recommendation for the AI industry is simple: a standard /info endpoint. If every AI product adopted this specification, it would instantly detail the agent's identity (e.g., Llama 3, Fine-tuned, version 2.1). Since this basic interface doesn't exist yet, our immediate technical hurdle was to bypass this deficiency by creating our custom fingerprinting logic (similar to SSL scans) to accurately guess the agent's identity.
Another challenge is shifting governance from security to Responsible AI (RAI) compliance. Since we can't inspect the model's training data, we must infer its risk profile. This involves using the LLM to analyze the agent's environment variables and configuration files for sensitive indicators (e.g., PII storage paths, lack of logging mechanisms, deprecated libraries) to generate an actionable Responsible AI Score. This is key for audits and proactive bias/privacy mitigation.



Log in or sign up for Devpost to join the conversation.