-
-
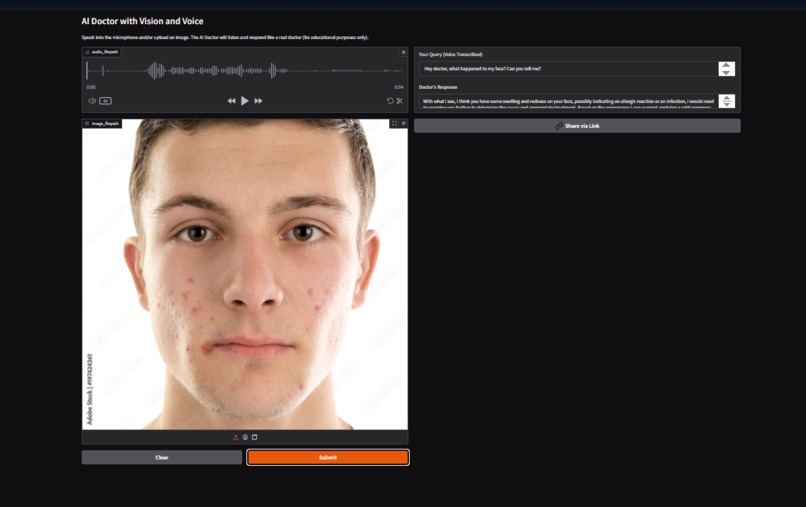
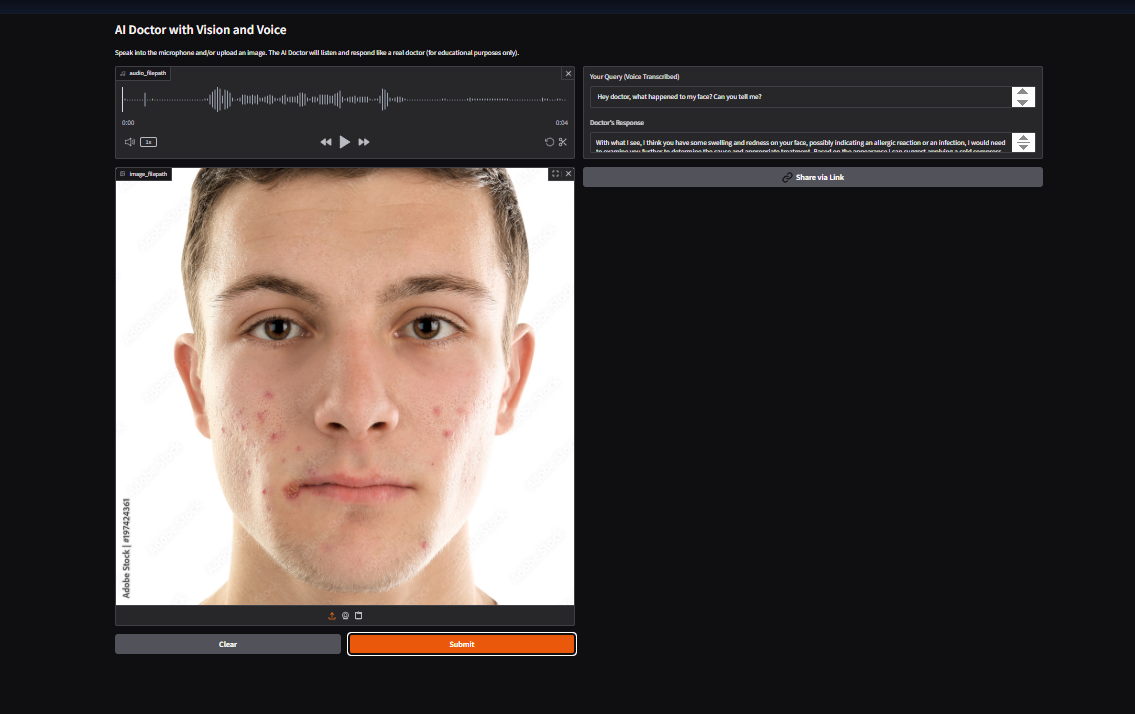
It's a interface of AI_DOCTOR_CHATBOT
💡 Inspiration
The inspiration for AI Doctor came from a simple yet powerful question:
“What if medical advice could be available to anyone, anytime — just by talking?”
In many regions, people face:
Long hospital waiting times
Lack of nearby doctors
Language and literacy barriers
We wanted to create a solution where any person could speak their symptoms, upload an image (like a rash or eye issue), and receive AI-powered medical guidance — all within seconds.
🧠 What We Learned
During this project, our team learned:
How to use Groq Whisper for real-time speech-to-text conversion
How to integrate AI vision models for image-based reasoning
How to build interactive multimodal apps with Gradio
How to securely deploy projects using Hugging Face Spaces
The importance of designing safe, ethical, and human-centered AI in healthcare
We also explored how latency and inference speed can impact real-time AI interactions, and how Groq’s accelerated LLMs solve that challenge.
🛠️ How We Built It
Frontend: Built using Gradio to capture audio and image inputs.
Audio Pipeline:
User speaks into the mic 🎙️
Audio is recorded and processed with pydub
Transcribed using Whisper-large-v3 via Groq API
Image + Text Processing:
Uploaded image encoded into base64 format
Text and image passed into LLaMA 4 instruct model for reasoning
Doctor’s Response:
AI generates a natural medical-style answer
(Optional) Converted to voice with text-to-speech (gTTS / ElevenLabs)
Deployment:
Hosted on Hugging Face Spaces using gradio deploy
Mathematically, we represent the multimodal input as:
𝑓 ( voice , image
)
LLM ( Transcribe ( voice ) , Encode ( image ) ) f(voice,image)=LLM(Transcribe(voice),Encode(image))
where 𝑓 f is the AI Doctor’s response function combining audio and visual understanding.
🚧 Challenges We Faced
Audio Processing on Cloud:
pyaudio failed on Hugging Face (no mic device), so we redesigned the pipeline to use browser-based mic recording via Gradio.
Groq API Integration:
Parsing responses from the chat completion API required handling new response formats.
Model Latency:
Managing large models for image reasoning while keeping inference time low.
Deployment Issues:
Handling environment variables and file paths on Hugging Face Spaces correctly.
🚀 Future Scope
🌍 Multi-language support
📱 Mobile app version
🧩 Integration with hospital databases (EHR)
⚡ Offline lightweight version for low-connectivity regions
👨💻 Tech Stack
Python, Gradio, Groq API (Whisper + LLaMA), Hugging Face Spaces, pydub, dotenv, GitHub
Built With
- dotenv
- gradio
- groq-api-(whisper-+-llama)
- hugging-face-spaces
- pydub
- python

Log in or sign up for Devpost to join the conversation.