Inspiration
I had already built the Virality Predictor, a tool that scores how a short form video will perform before you post it. Watching people use it taught me something I did not expect. They would upload a finished clip, learn that the hook was weak or that attention fell off at the four second mark, and then have no fast way to act on it. The fix lived in a different tool, or in a video editor, or in a re-shoot. The loop never closed.
At the same time, every text to video generator I tried had the same spending problem. You pay credits up front, you see the render only after it finishes, and then you re-prompt and pay again until the budget is gone. The average creator burns fifty to two hundred dollars before getting one clip worth posting, and there is no quality signal until after the money is spent. On top of that, TikTok and YouTube Shorts started throttling mass-generated low quality AI in early 2026, so even the clips that render can quietly die on arrival.
So I set out to build the other half of the loop. A generator where the conversation is cheap, the render is the only expensive step, and the same model that scores uploads can score anything the generator produces. Describe an idea, approve a storyboard, render it, score it, and iterate, all from one account.
What it does
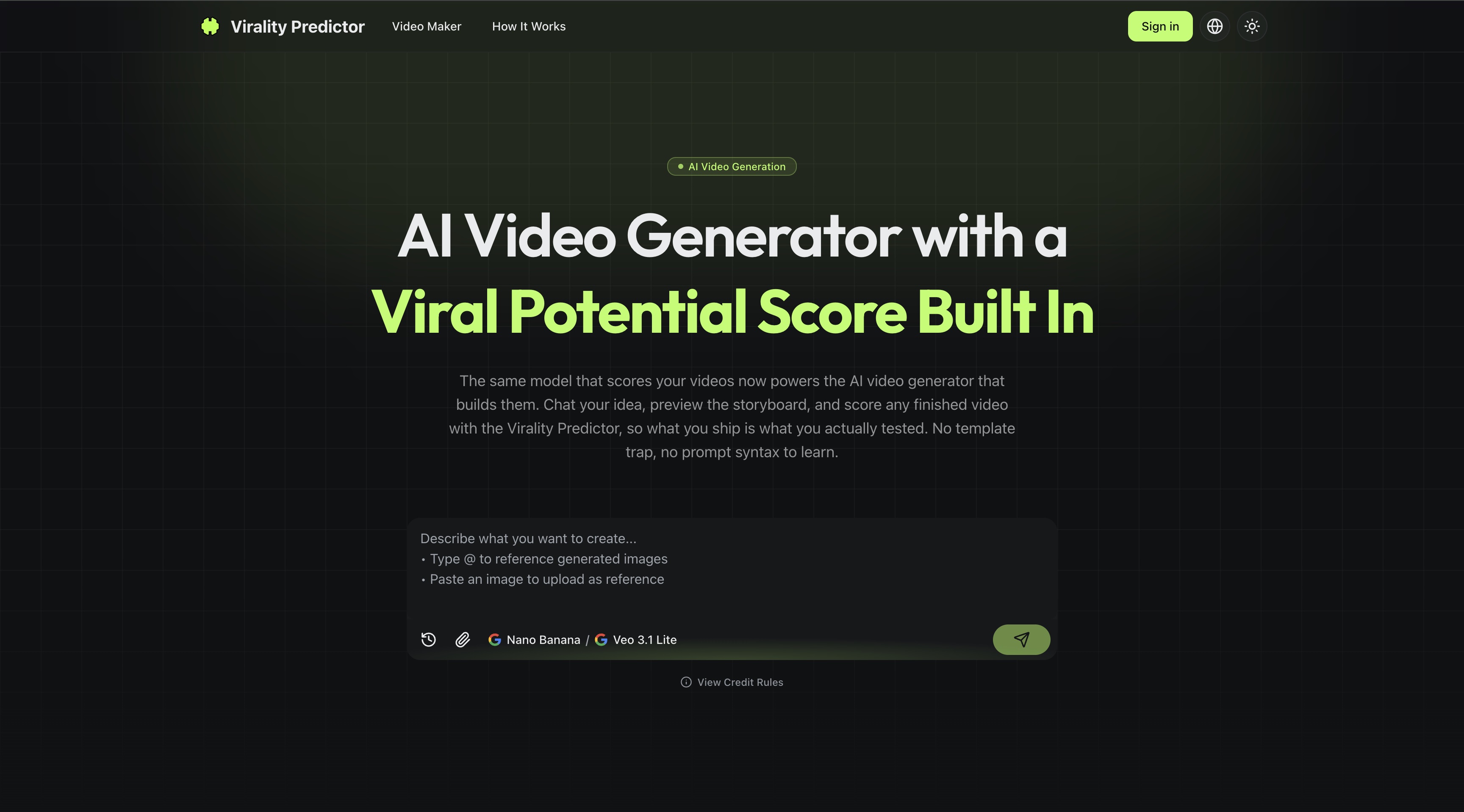
The Video Maker is a chat based AI video generator with a Viral Potential score built into the workflow. You describe the video you want in plain English, or you upload a reference image to start an image to video flow. The agent asks one or two clarifying questions if it needs them, then returns a storyboard of four to six frames that you approve before anything renders.
The storyboard is the key idea. Chatting and editing the story cost about one credit per turn, while the render-sized cost only lands on a sequence you have already approved. You explore the story for pennies and commit real spend once, on a sequence you already believe in. When you hit render, the video model you picked produces the final cut from the exact frames you signed off on.
Then you can score the finished video on request. The same multimodal model behind the Virality Predictor homepage tool grades the cut on Hook Score, Hold Rate, and overall Viral Potential, and it points you to the single weakest second. If the video lands below seventy, you know exactly where attention drops, so you can iterate cheaply and render again. Output runs nine to sixty seconds in vertical or horizontal format, and presets adapt tone and pacing for solo UGC creators, Shopify and Amazon sellers, performance marketers, and writers turning a post into a no-camera Short.
How I built it
The frontend is Next.js 15 with Tailwind CSS v4, Shadcn UI, and Magic UI v4 components, deployed to Cloudflare Workers through OpenNext. The chat experience is a stateful agent built on Cloudflare's agents framework. Each session lives inside a Durable Object that holds the conversation and the evolving storyboard across many turns and tool calls, which is what makes multi-turn refinement feel coherent.
User data and credit accounting sit in Cloudflare D1 through Drizzle ORM. Images and rendered videos land in Cloudflare R2, short-lived state goes in Cloudflare KV, and async work runs through Cloudflare Queues. Auth is NextAuth v5 with Google OAuth.
The generation side calls frontier video models, including Veo 3.1 and Seedance 2.0, through the Vercel AI SDK. The scoring side is a dedicated agent tool. When a user asks for a score, the tool reserves credits, calls a multimodal model synchronously through OpenRouter, applies the exact same scoring rubric as the standalone Predictor, and returns structured metrics back into the chat. Because the rubric is shared, a score inside the Maker means the same thing as a score on the homepage. The whole product is internationalized with next-intl and ships in English, Italian, and Japanese, including the chat interface.
Challenges I ran into
Running a long synchronous score inside an agent tool. Scoring a finished video is a heavy multimodal call that can take up to about three minutes. I had to run it synchronously inside a tool call, hold the wait without blocking the rest of the agent, and broadcast progress to the UI so the user is not staring at a frozen screen. My first attempt used a Replicate path that turned out to be flaky on uploaded-video analysis, so I switched to a synchronous OpenRouter primitive that reuses the Predictor scoring logic.
Getting the credit lifecycle exactly right. A score reserves credits up front, confirms the deduction on success, and cancels the reservation on failure. The subtle bug was confirm-after-success. If I cancelled on a confirm failure, a user could get a real result without being charged. I had to separate prediction failure, which should refund, from a post-result bookkeeping failure, which should never hand out a free score. Getting reserve, confirm, and cancel to never double charge and never leak a free ride took careful sequencing.
Protecting the prompt cache while injecting coaching. I wanted the agent's system prompt to carry the full virality coaching rubric reverse-engineered from the Predictor, but the system prompt also has to stay static so the prompt cache keeps hitting. The only value allowed to vary is the user's plan tier. Keeping the rubric rich and the prompt cache intact at the same time meant being disciplined about what is static text and what is interpolated.
Designing the economics so cheap exploration is real. It is easy to say chat is cheap and render is expensive. Making it true required pricing each chat turn and storyboard edit at roughly one credit, gating the render-sized cost behind explicit storyboard approval, and making all of that legible in the UI so people trust that they will not get surprised by a charge.
Accomplishments that I'm proud of
Closing the loop. The same model now does three jobs: it guides generation, it scores the finished cut, and it tells you which second to fix. The Predictor and the Maker stopped being two separate tools and became one workflow on one account with one shared credit balance.
The storyboard safety gate. Flipping the pay-first economics of text to video is the thing I am most proud of. You see every shot and lock the story for pennies, and the heavy render cost only arrives on a sequence you already approved and can already predict the score of.
A coherent multi-turn video agent. Building a chat agent that keeps a live storyboard in context across many turns, calls generation and scoring tools, and stays responsive, all inside a Cloudflare Durable Object, was a real systems challenge and it works.
Shipping it multilingual. The page and the chat UI ship in English, Italian, and Japanese, with the scoring labels and credit rules localized, not just the marketing copy.
What I learned
I learned how to design a stateful agent for the edge. Durable Objects are a great fit for per-session chat state, but you have to think hard about what lives in the object, what lives in D1, and how a long-running tool call behaves while the user waits.
I learned that prompt cache discipline is a real engineering constraint, not a nice to have. The moment you let dynamic content leak into a system prompt, your cache hit rate and your costs move in the wrong direction. Keeping the coaching rubric static paid for itself.
On the product side, I learned that people do not just want a score. They want to act on it. The standalone Predictor told creators their hook was weak. The Maker is the answer to the obvious next question, which is what do I do about it. Pairing the diagnosis with a cheap way to fix and re-score is what makes the score feel useful instead of discouraging.
What's next for AI Video Generator with Virality Prediction
Optional auto-score after render. Today scoring is on request, which keeps it cheap and intentional. The next step is an opt-in setting that scores every finished render automatically and surfaces the weakest second before you even ask.
Variant batch mode. Sellers and marketers want several hook variations from one chat, each one cheap, with a predicted Hook Score per variant so they can commit the render only on the winner. Building comparative scoring across a lineup is the natural next feature.
A public API. The same request that early users made of the Predictor applies here. Teams want to drop a brief in and get back a scored, render-ready storyboard programmatically, so they can wire generation and scoring into their own content pipelines.
More models and longer formats. Adding more render models at different cost and quality tiers, and extending output beyond the current short form window, will open the Maker up to YouTube creators and longer ad formats.
Tighter handoff between the two tools. Right now the Predictor and the Maker share an account and a model. The next version will let an insight from a scored upload flow directly into a new Maker session, so a diagnosis on one video becomes the starting brief for the next one.
Built With
- cloudflare
- next.js
- typescript

Log in or sign up for Devpost to join the conversation.