AI TrustGate
Inspiration
We live in an era where a single misleading YouTube video can reach millions before fact-checkers even notice it. A clickbait headline can shape public opinion. An AI-generated deepfake can fabricate reality. The scale of the problem is staggering according to MIT research, false news stories are 70% more likely to be retweeted than true stories, and they reach their first 1,500 people six times faster.
When we saw the Siren's Call track focused on combating misinformation, verifying social media content, and detecting deceptive AI, we knew exactly what we wanted to build. Existing fact-checking tools are slow, manual, and limited to text. They cannot analyze a YouTube video's thumbnail against its actual content. They cannot detect if an article uses emotional manipulation tactics to bypass critical thinking. They cannot tell you whether the images in a news article were AI-generated.
We asked ourselves: What if you could paste any URL and get an instant, comprehensive trust assessment, not just for text claims, but across every modality: video, audio, images, and language?
That question became AI TrustGate.
What It Does
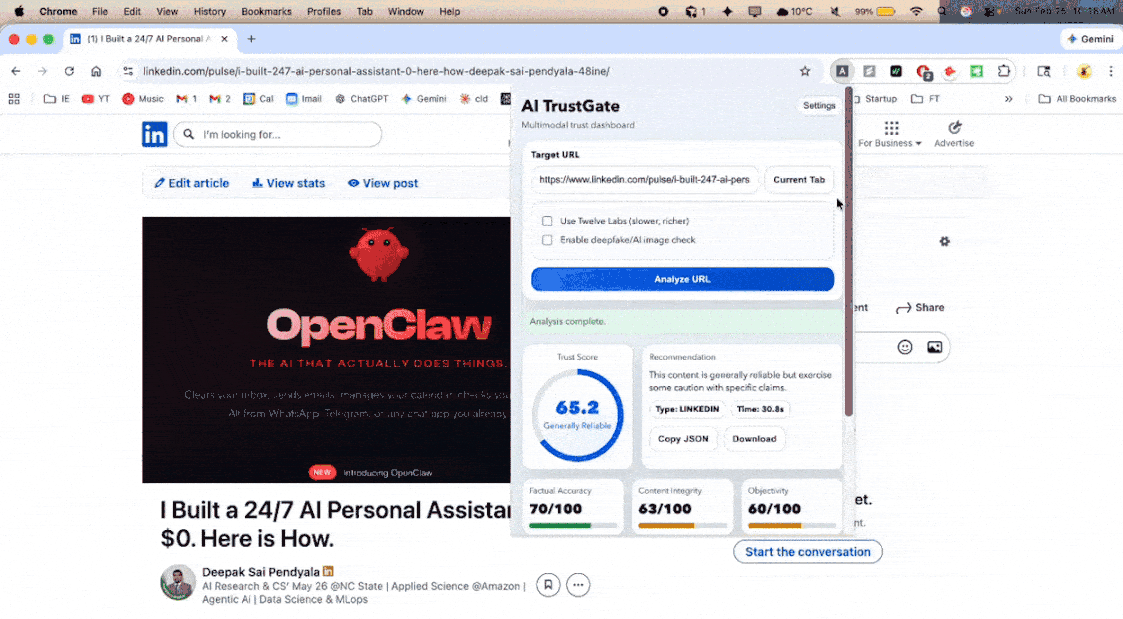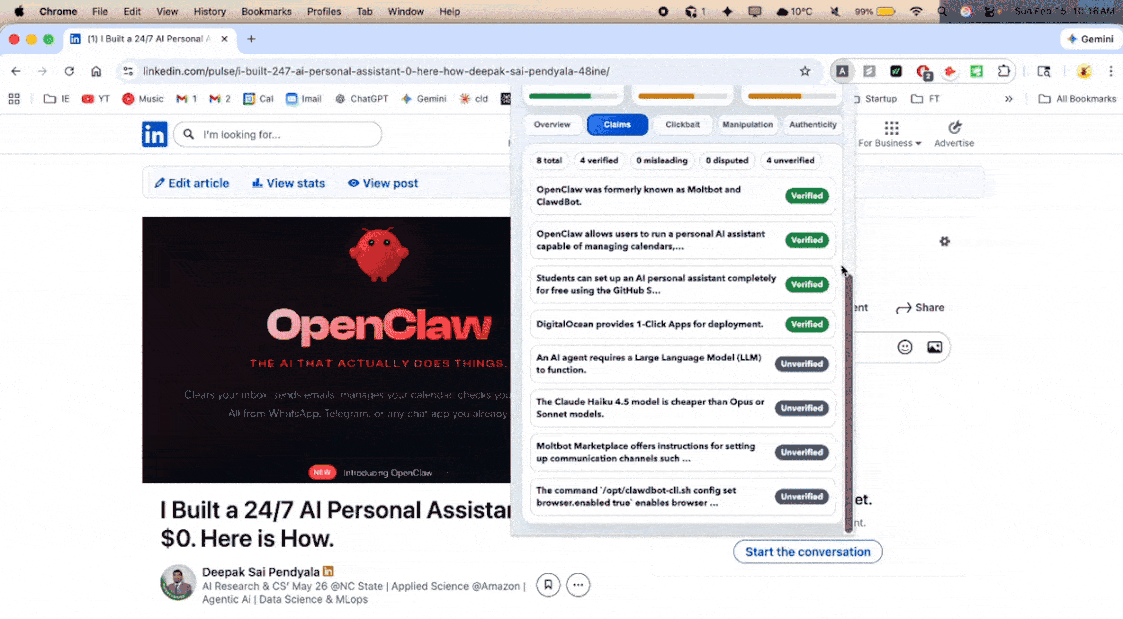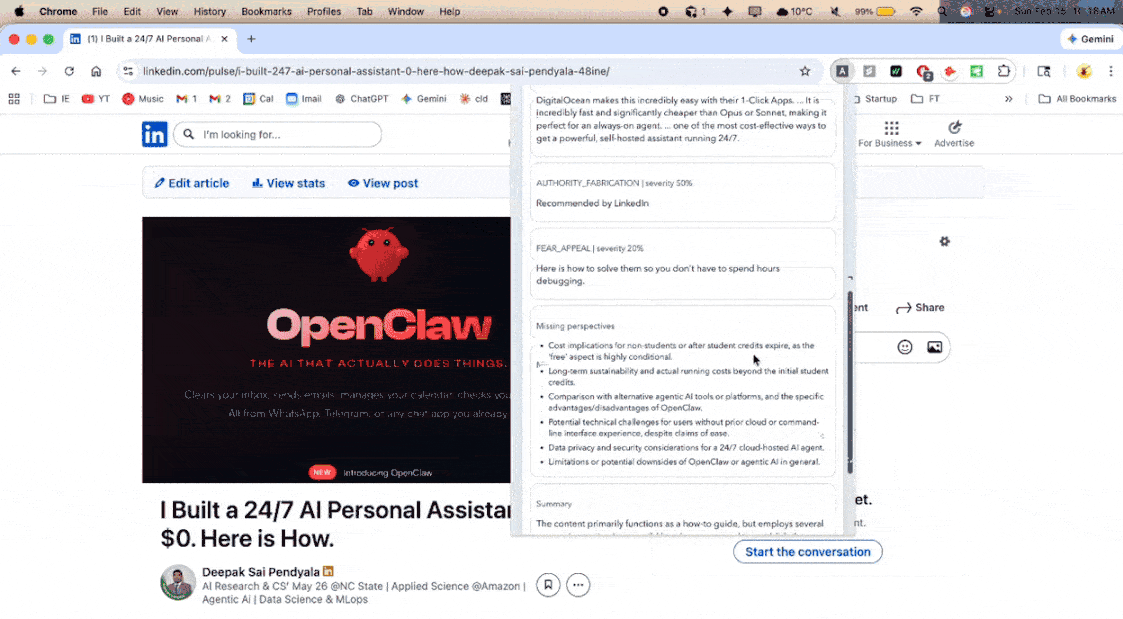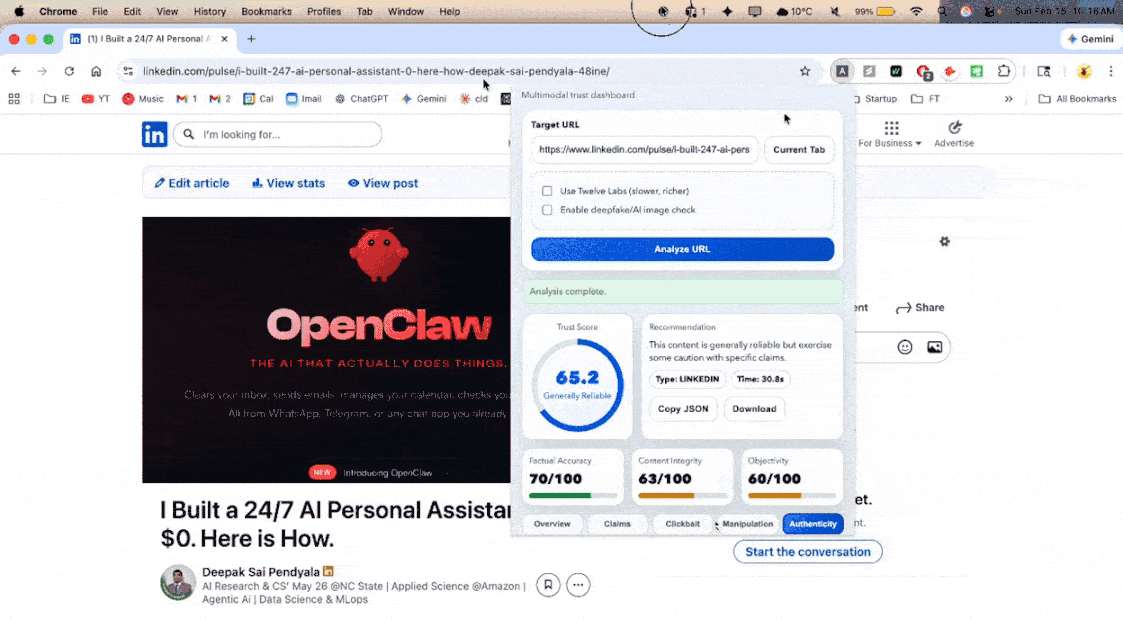
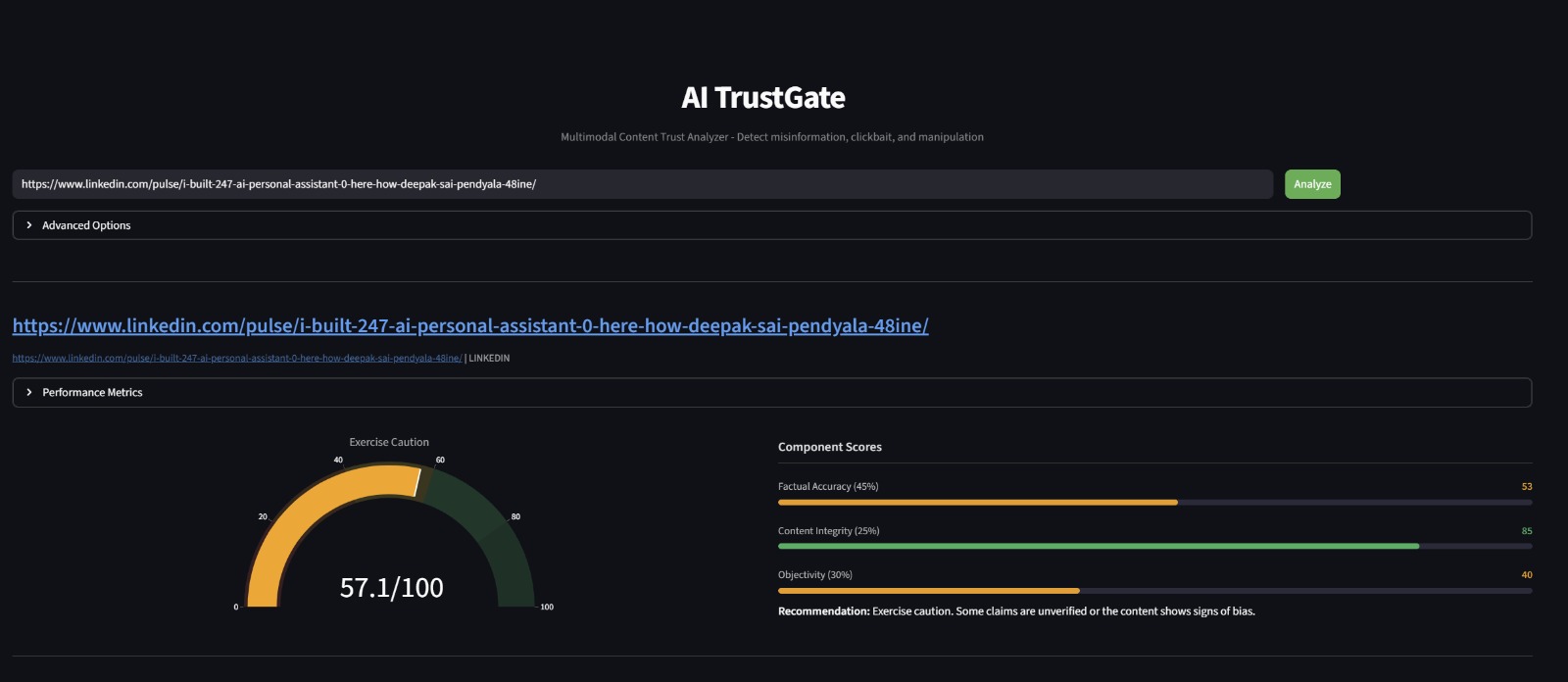
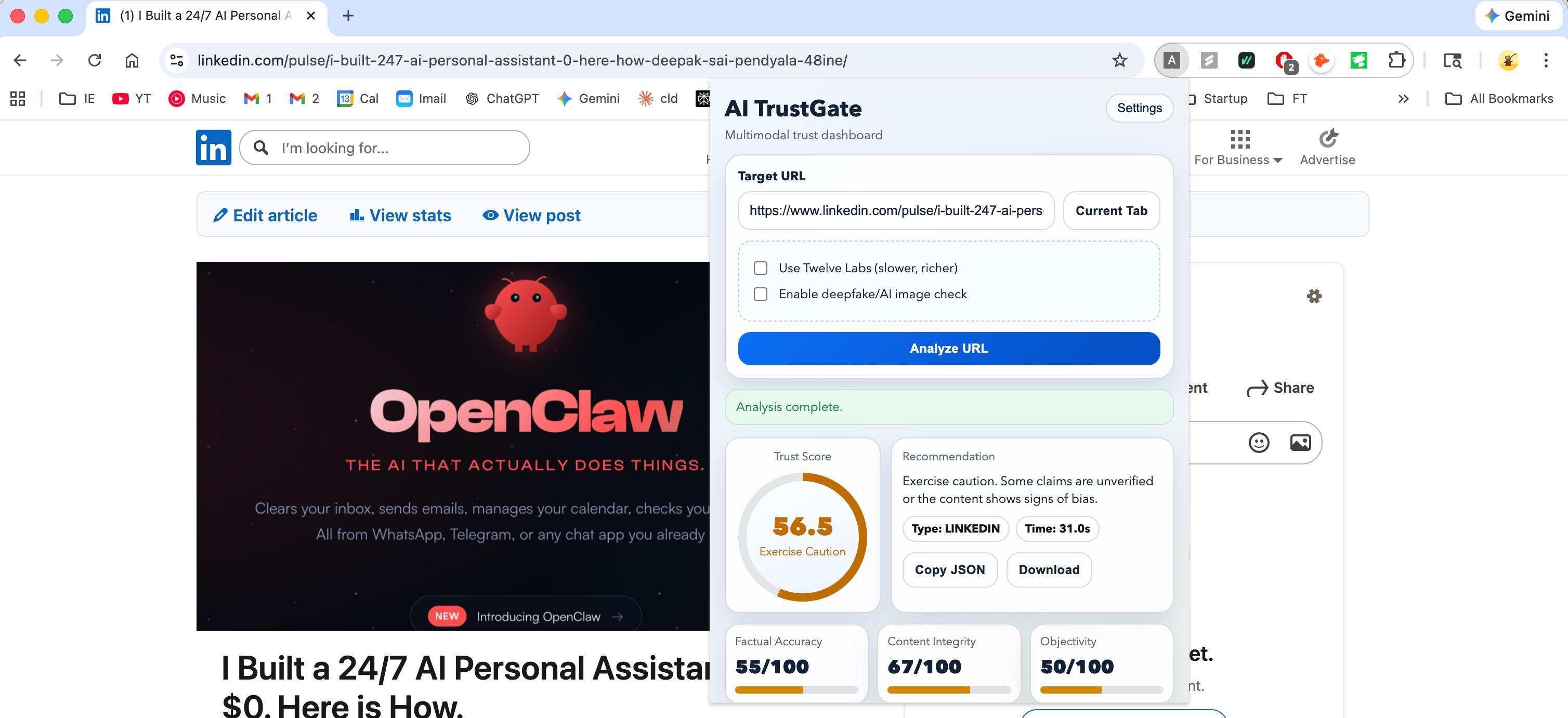
AI TrustGate is a multimodal content trust analyzer. Users paste a URL (YouTube video, news article, blog post, LinkedIn post) and receive a Trust Report with a composite score from 0 to 100, broken down across three dimensions:
The composite trust score is computed as:
$$ [ \text{Trust Score} = 0.45 \times \text{Factual Accuracy} + 0.25 \times \text{Content Integrity} + 0.30 \times \text{Objectivity} ] $$
where:
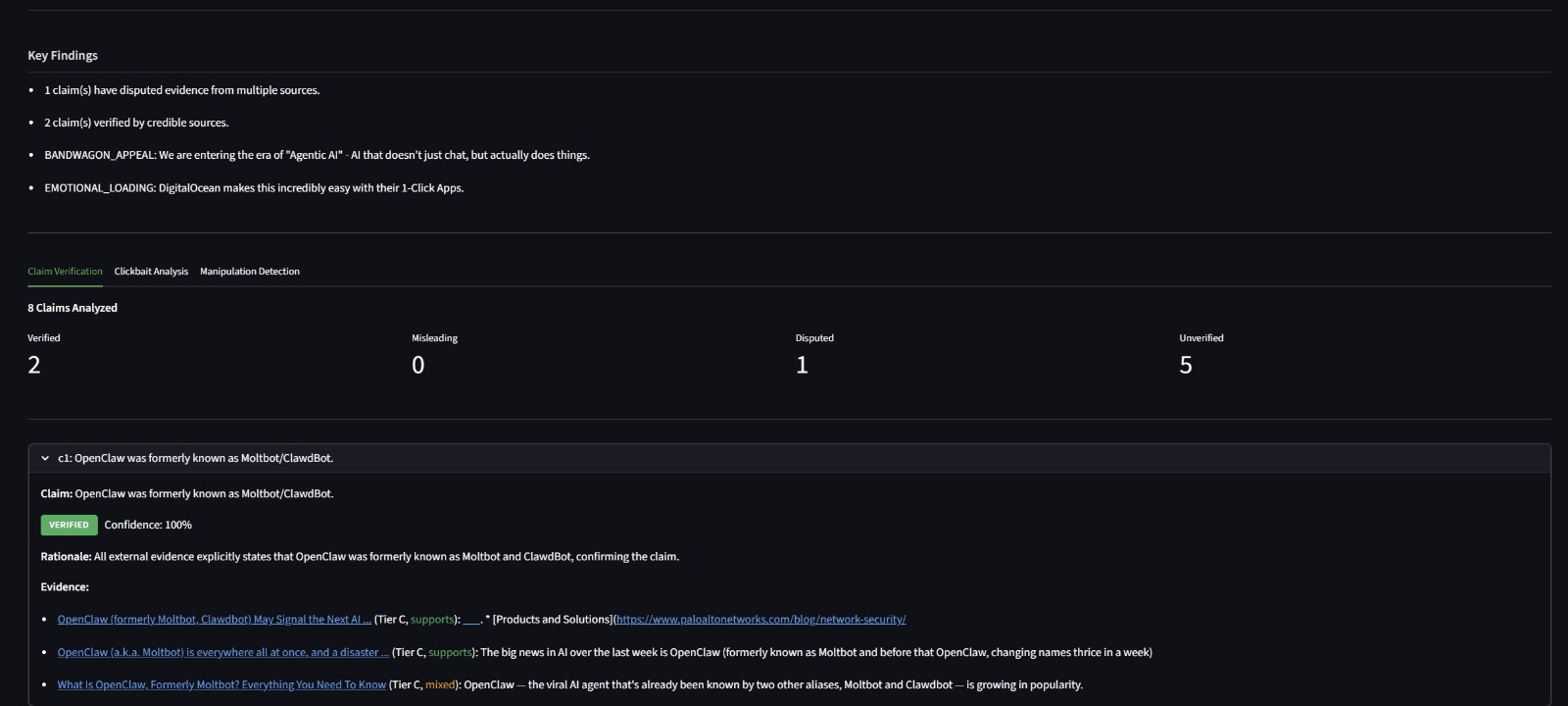
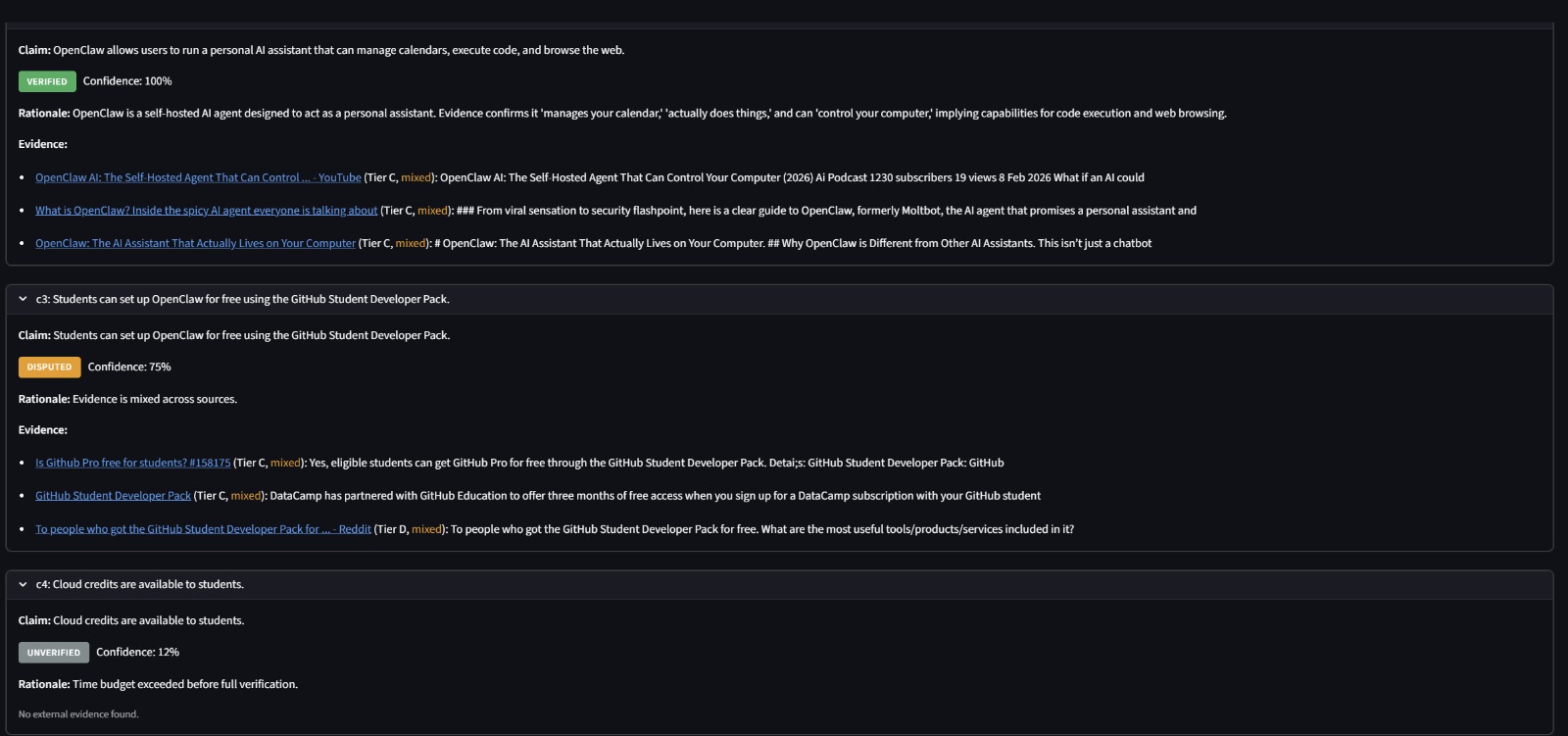
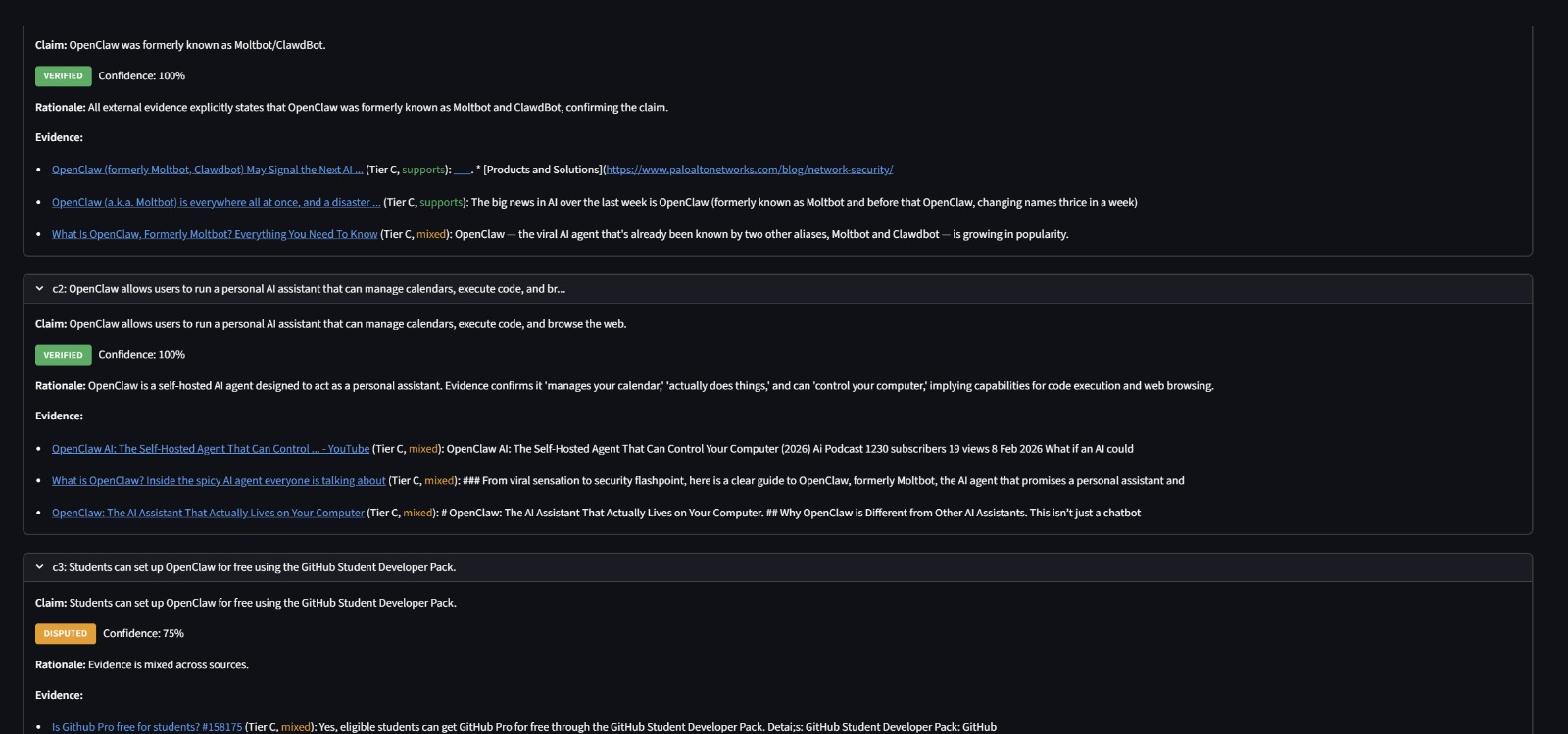
- Factual Accuracy (45%): Are the claims in the content verifiable and true? Each claim is extracted, cross-referenced against web sources, and verified using LLM synthesis.
- Content Integrity (25%): Does the title deliver on its promise? Is the thumbnail representative? Are sensationalism and clickbait tactics being used?
- Objectivity (30%): Is the content balanced? Does it use emotional manipulation, fear appeals, false urgency, or one-sided framing?
Beyond scoring, the system also runs deepfake and AI-generated content detection on thumbnails and article images, and provides a Chrome extension for one-click analysis from the browser.
How We Built It
Pipeline
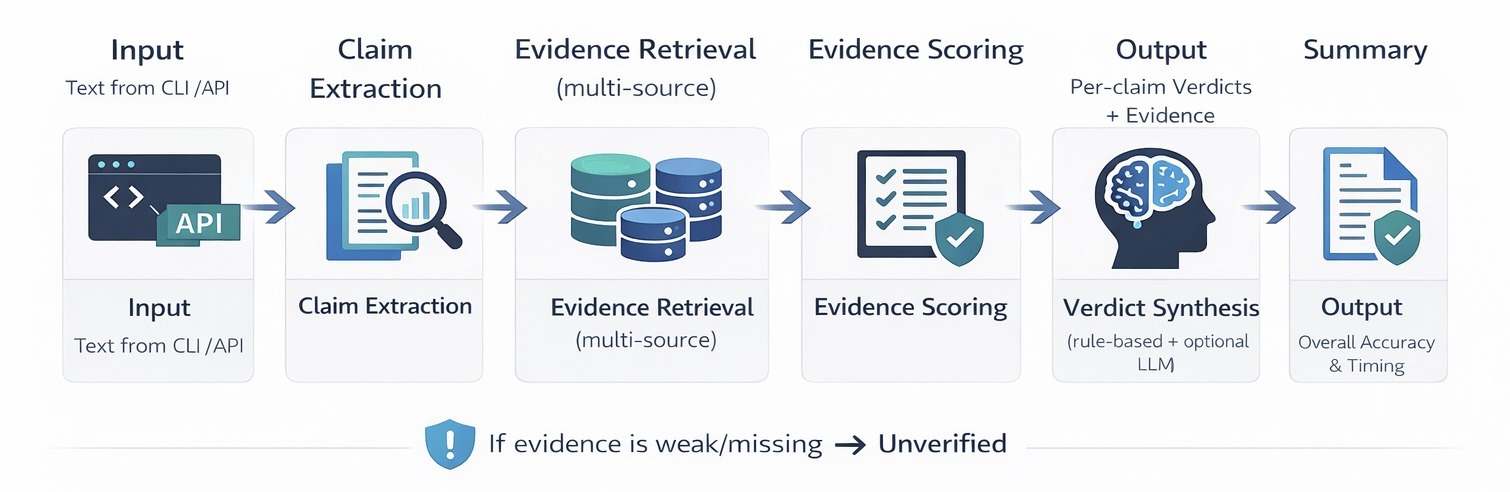
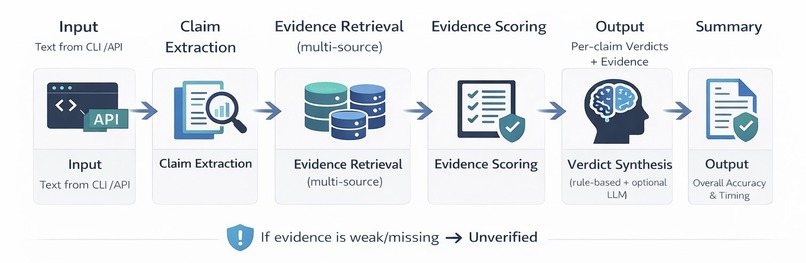
We designed a three-phase pipeline:
Architecture
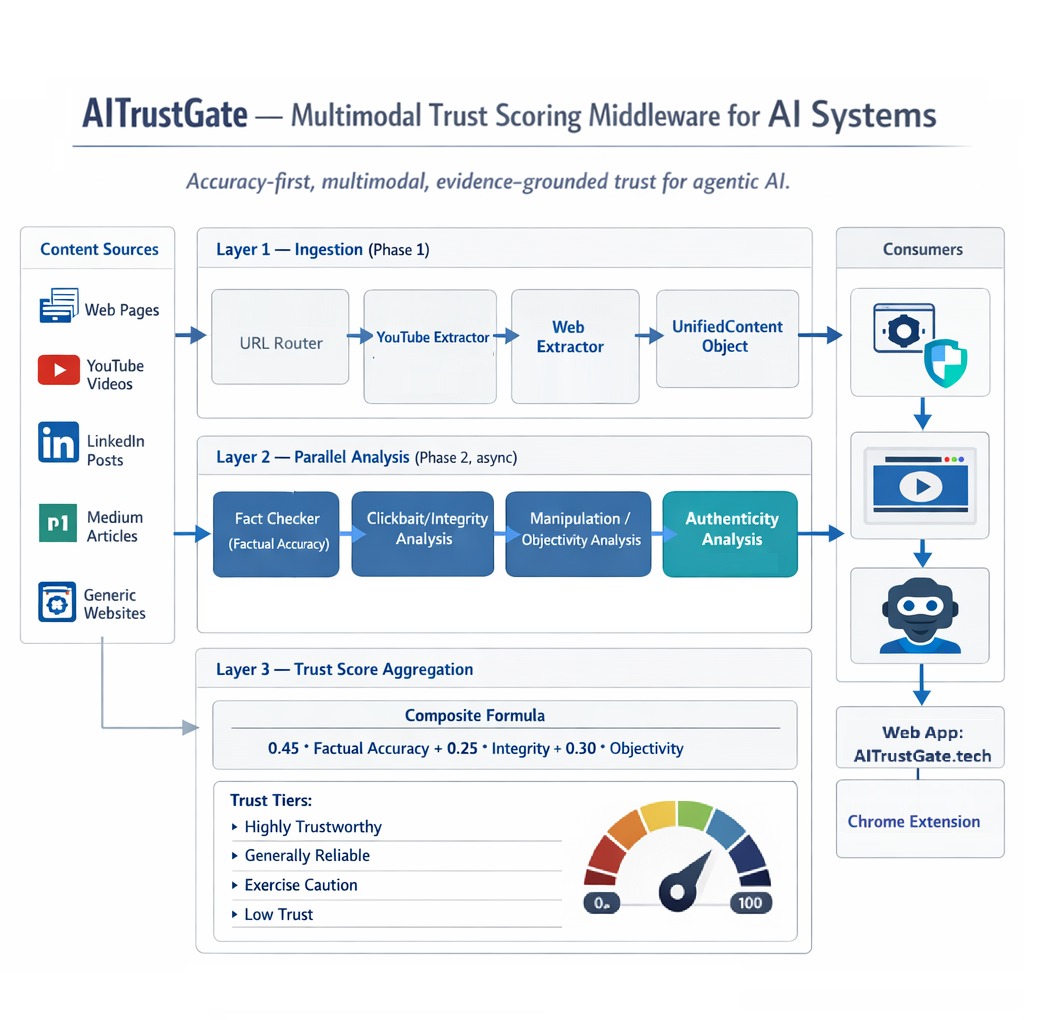
Phase 1 - Content Extraction. A URL router detects the content type (YouTube, LinkedIn, Medium, generic webpage) and dispatches to the appropriate extractor. For YouTube, we extract the full transcript via youtube-transcript-api, pull metadata and thumbnails via oEmbed and yt-dlp. For web articles, we use trafilatura with a BeautifulSoup fallback to extract text, images, author, and publication metadata.
Phase 2 - Parallel Analysis. Four analysis engines run concurrently using asyncio.gather:
Fact Checker - LLM-driven claim extraction identifies verifiable statements (no hardcoded regex). Each claim is verified against multiple evidence sources (Tavily web search, Google Fact Check Tools API, ClaimReview markup) with source credibility scoring (Tier A/B/C/D). An LLM synthesizes evidence into a final verdict: Supported, Contradicted, Disputed, or Unverifiable.
Clickbait Detector - Heuristic title analysis detects ALL-CAPS, power words, and clickbait phrases. For deeper analysis, Twelve Labs Marengo embeddings compute semantic similarity between the title, thumbnail, and actual video/article content. The cosine similarity between the title embedding (\vec{t}) and the content embedding (\vec{c}) quantifies the promise-delivery gap:
$$ \text{gap} = 1 - \frac{\vec{t} \cdot \vec{c}}{\lVert \vec{t} \rVert \, \lVert \vec{c} \rVert} $$
Manipulation Analyzer - An LLM scans for nine manipulation tactics (fear appeal, false urgency, authority fabrication, bandwagon appeal, emotional loading, cherry-picking, one-sided framing, and more), each scored by severity. Missing perspectives are explicitly identified.
Authenticity Checker - Sightengine API analyzes thumbnails and article images for AI-generated content probability and deepfake/face manipulation detection.
Phase 3 Score Aggregation. Sub-scores are weighted into the composite trust score, key findings are ranked by severity, and a recommendation is generated.
Tech Stack
- Python 3.12+ with fully async pipeline
- Google Gemini as the primary LLM for claim extraction, verification, and manipulation detection
- Twelve Labs (Marengo 3.0 for embeddings, Pegasus 1.2 for video analysis), our hackathon sponsor integration
- Sightengine for deepfake and AI-generated image detection
- Tavily for real-time web search evidence retrieval
- Streamlit + Plotly for the interactive frontend with live trust gauges
- FastAPI backend powering the Chrome extension API
- trafilatura + BeautifulSoup for web content extraction
- youtube-transcript-api + yt-dlp for YouTube content extraction
Frontend
The Streamlit app provides an interactive dashboard with:
- A color-coded trust gauge (0-100)
- Sub-score breakdowns with visual bars
- Expandable claim cards showing verdict, evidence, and confidence
- Clickbait analysis with sensationalism metrics
- Manipulation tactics display with severity indicators
- Authenticity results for AI/deepfake detection
- Timing information showing extraction vs. analysis performance
- Passkey protection for deployed instances
Chrome Extension
A companion Chrome extension lets users analyze any page with one click, communicating with the FastAPI backend for real-time trust assessment directly in the browser.
AI Trust Layer
Beyond the web dashboard and Chrome extension, AI TrustGate also exposes a Fast API that can serve as a trust middleware layer for LLM systems. AI agents with web access can call the API before incorporating retrieved content into their reasoning, ensuring every piece of external information carries a trust score before it influences downstream decisions.
Challenges We Faced
LLM output reliability. Getting consistent, parseable JSON from LLMs was our biggest challenge. Gemini would return markdown code blocks around JSON, use smart quotes, add trailing commas, or return arrays where we expected objects. We built a robust multi-layer JSON parser with fallback strategies: strip markdown fences, extract JSON arrays from surrounding text, fix trailing commas, normalize quotes, remove control characters, and a final regex-based object extraction fallback.
Decisive verdict synthesis. Early versions of our fact-checker returned "Disputed" or "Unverified" for almost every claim. The LLM was hedging. We reworked the synthesis prompts to empower the model to be decisive, use "Supported" when the facts check out, "Contradicted" when they don't and only fall back to "Disputed" for genuinely controversial topics. We also increased rationale length limits and added pre-validation truncation to prevent Pydantic validation errors.
YouTube extraction timeouts. yt-dlp metadata extraction was consistently timing out at 30 seconds on deployed instances. We implemented a two-stage approach: first try the lightweight oEmbed API (sub-second), then fall back to yt-dlp only if needed, with reduced timeout and playlist exclusion flags.
Claim extraction completeness. Our initial regex-based claim extractor was cutting claims mid-sentence and missing context-dependent statements. We replaced the entire approach with LLM-first dynamic extraction, where Gemini semantically identifies complete, self-contained claims, no hardcoded patterns, fully content-agnostic.
Async orchestration complexity. Running four analysis engines in parallel while handling partial failures, different timeout profiles, and optional features (Twelve Labs, Sightengine) required careful asyncio.gather management with individual exception handling per task, so one engine failing does not bring down the entire analysis.
What We Learned
- LLMs are powerful but messy. Every LLM integration needed defensive parsing and fallback strategies. Structured output promises consistency but falls back to free-form text more often than expected.
- Embeddings are the bridge between modalities. Twelve Labs' semantic embeddings let us compare a video title to a 20-minute transcript in a single cosine similarity computation. That is a powerful abstraction.
- Async-first design pays off. Running fact-checking, clickbait detection, manipulation analysis, and authenticity checks in parallel cut total analysis time by roughly 3x compared to sequential execution.
- Prompt engineering is iterative engineering. Getting an LLM to reliably output a specific JSON schema with decisive verdicts took dozens of iterations. The system prompt is as much a part of the codebase as the Python code.
- Defense in depth for trust. No single signal is sufficient. A high factual accuracy score means nothing if the content uses emotional manipulation. The weighted composite score across multiple dimensions provides a far more robust trust signal than any individual check.
What's Next
- Real-time browser-native analysis without requiring a backend server
- Multilingual content support
- Historical trust tracking per publisher/channel
- Community-driven source credibility database
- Fine-tuned models specifically trained on misinformation detection benchmarks







Log in or sign up for Devpost to join the conversation.