-

BEWARE (credit: Kaseya.com)
-
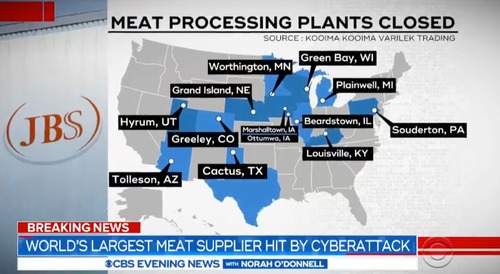
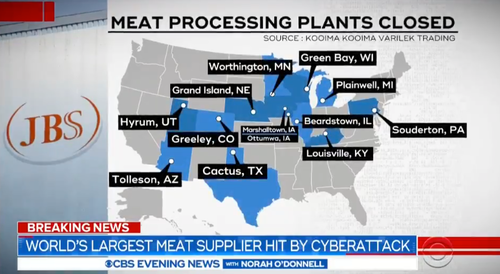
JBS attack (credit: Everchem Specialty Chemicals & CBS)
-

Home Depot (credit: Dave Granlund)
-

Colonial Pipeline (credit: The Verge)



With the rise in cybersecurity incidents, there is a need for easy and effective cybersecurity tools that can quickly flag malware that can harm computers.
What's inspired you:
The need to make cyber safer and easier. We explained below our personal experiences that inspired us to do this.
Carl's inspiration:
With the Colonial Pipeline, JBS, and other major cybersecurity incidents last May, there is a major demand for easy and effective Cybersecurity solutions. The Colonial Pipeline incident was especially damaging since a large quantity of the oil supply for the East Coast was affected with this ransomware attack. Even where I was living in Virginia, I had to be careful on how much driving I was doing to minimize how much gas I was using. As a result, this experience framed my purpose in the Philly Codefest to make an easy and effective Cybersecurity solution that can detect malware and mitigate the possibility of a cyberattack occurring.
Aisha's inspiration:
As an undergraduate pursuing a major in Computing Security and Technology, I am always motivated to build products centering security and the need for it. When we are online, most of our private data is at risk so I want to make sure that people are comfortable going online without worrying about their privacy or their information being stolen. This project is meant to detect and flag suspicious activities like malware to better help people stay secure and alert. Now more than ever we are experiencing data breaches within small and big companies, so creating this product will be a game changer!
Animish’s inspiration:
I would hear about data breaches with Microsoft, Facebook, and other companies every month since I started following the news (as I became a Computer Science Major at Temple). I guess I was just taking it in like I would read facts from history books (like death toll of world war 2). I didn’t realize how dangerous these data breaches were until yesterday when I talked to a peer at the train station. He said he works at Home Depot and there was a data breach last week where his banking information was leaked, and 60,000 dollars were withdrawn. My jaw dropped; I can’t imagine your life changing like that overnight. Because the severity and increasing frequency of data breaches now, I want to learn on how to help mitigate them as much as possible.
Jack’s inspiration:
Everybody impacts the world through their jobs in unique ways. I’m personally an automation tester at Infosys, and my daily work involves making sure the Vanguard retirement website works according to specification. This website contain personalized nudges for the users, motivating them to save money in personalized ways. It's rewarding being able to help others positively manage their financial well-being, even in the smallest of ways. Combining this with my lifelong interest in mathematics and my experience being in the machine learning club in college, I’m even more inspired to create and test this program. Last but not least, a family member of mine was hurt by a bank data breach, so I know the work I’m putting in for this project is impactful.
Project methodology:
Our project was built using Python on Google Colabs utilizing the tensorflow, numpy, random, pickle, and os libraries. We used the Dike Dataset consisting of benign and malware file samples for the training and testing data for our project. The file samples were converted into 256x256 matrices in order to be properly utilized as features. Combining these features with the corresponding labels (benign and malware, 0 and 1 respectively), we were able to construct the training data. The features and labels had to be reshaped and converted into numpy arrays in order to be successfully placed into the neural network. To avoid constantly having to repeat the process of generating the training data (which could take up to 2 minutes, even after truncating the amount of data we were going to use), we have stored the features and labels into a file within Colabs using the pickle library. After loading the features and labels from the pickle file, we then normalized the data and then placed it into a sequential model. From there, we have utilized a convolutional neural network for the training process. Max pooling was used for feature detection with a 3x3 filter in order to reduce the amount of computation used in the process and to eliminate the possibility of overfitting the data. The activation functions that were used for the CNN was the relu function to add non-linearity to the model, and the sigmoid activation function was used because our model only has two possible classifications. After passing the data through two layers of convolution and pooling, we then flattened the data so that it could pass into two dense, fully connected layers to complete the process of classifying the files into benign and dangerous files.
What you learned:
We learned how to utilize Google Colabs to run the Python code that was required for our project and to store the dataset from an outside GitHub repository. We have learned how to clean and interact with the dataset in order to eventually pass it into the convolutional neural network that was required to distinguish the benign files from the ones infected with malware. To use the executable file samples as training data, they had to be converted from their raw forms into large square matrices. In order to accomplish this, we had to learn how to read a Python binary file byte by byte and convert each byte into an integer. These integers would then be stored in the previously mentioned square matrices. We also had to learn how to properly utilize the keras and tensorflow libraries in Python in order to properly build the neural network, along with figuring out the difference between the "softmax" and "sigmoid" activation functions which would eventually prove to be instrumental towards properly finishing our project and obtaining the desired training results.
Challenges we faced:
Google Colabs was being a bit slow with creating the training data (i.e. converting the images into matrices with thousands of files), so we decided to truncate our training and testing data to 1,000 benign files and 1,000 malware files instead of using all 10,000+ files found within the dataset we found on GitHub. The results of the machine learning process weren't looking very promising at first because the accuracy wasn't improving with each epoch of the learning process. However, it turned out that we had to change the activation function before the dense neural network layer from "softmax" to "sigmoid," the proper activation function to be used for two-class classifications (which was correct for our case because we were only determining benign vs. malware files, we weren't concerned with the exact type of malware). Instead of the accuracy being stuck at 50% even after ten epochs, the machine learning network was then finally able to accurately and consistently determine the difference between benign files and malware over 95% of the time after just a few epochs.
Built With
- codelabs
- kaggle
- neuralnetwork
- python

Log in or sign up for Devpost to join the conversation.